LLMの出力スピードを高速化できるライブラリ「vLLM」について紹介します。
このライブラリは半年前に公開されて、処理速度が速いので私もよく使っています。最近中身について調べて、ある程度理解できましたので、共有したいと思います。
vllmの最大な特徴は"バッチ処理際の待機時間を減す"ことです。
LLMがoutputを生成する際に、プロンプト文に基づいてtokenを生成し、ストップtokenやtokenの最大数に達すと生成は停止します。この過程をbatchingとも呼ばれ、batchingの手法はstatic batchingとcontinues batching二種類があります。
static batching
一般的に、LLMがoutputを生成する際に、プロンプト文に基づいてtokenを生成し、ストップtokenやtokenの最大数に達すると生成を停止します。
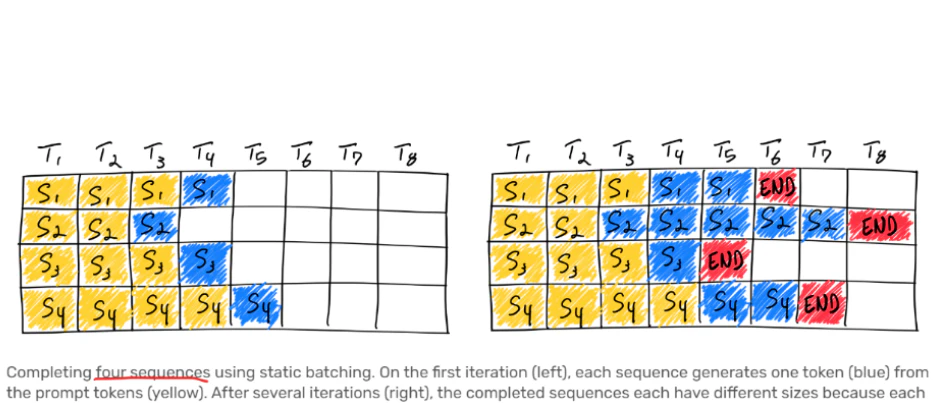
通常の処理手法(static batching)では、早く生成を終えた列(seq)が、他のまだ完了していない列を待つ必要があります。以下の図のように、seq1、3、4がseq2の完成を待っています。なので、GPUの利用効率は最大には達しません。
continues batching
vLLMはこの待機時間を削減するために、「continues batching」という手法を採用しています。continues batchingは一つのseqの生成が完了すると、バッチ内の次の空きスペースに新しいseqを追加し、生成を続けるというものです。
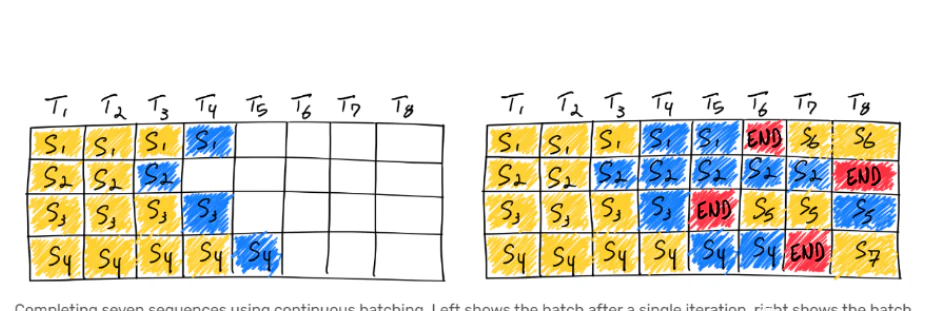
一部の記事では24倍速くなったとされていますが、私が実際に試したところ、およそ2倍速くなったと感しました。(比較対象はhuggingface、特にリクエストを複数個投げる際に)
興味ある方: