CGAN/CTGAN (Categorical-Generative Adversarial Network : 条件付き敵対的生成ネットワーク) は、 指定した条件 (カテゴリ) とノイズに基づいて、そのカテゴリの特徴を備えたコンテンツを生成することのできるニューラルネットワークを実現する ための手法です。本記事では、 生成する画像のカテゴリを指定する情報(りんご、飛行機、自転車)とノイズに基づいて、それぞれの特徴を持った手書き風イメージを生成することの出来るCGAN/CTGAN (以降:CGAN)の実現方法を紹介します。

本記事の定義するCGANの入出力と構造
本記事で構築するCGANは下記の構造を持ちます。左端が入力となるノイズとカテゴリを指定する情報であり、これに基づいて生成器 (Generator) がカテゴリの特徴を備えているであろう画像を生成します。ここでは、生成器により出力された画像をFake Imagesと呼びます。 本記事の定義するFake Imagesは28px x 28pxのグレースケール画像 (1ch) に加えて、画像のカテゴリを示す「追加のチャネル」を有しています。このチャネルはOne-Hot Encoding値であり、カテゴリIDに対応したチャネルが 1.0 、それ以外のチャネルが 0.0 を保持 します。
そして判別器(Discriminator)はFake Imagesまたはデータセットから採取したReal Imagesを入力として、 対象の画像がいずれのカテゴリの画像であるか、または生成器が生成したFake Imagesなのかを判別し、One-Hot Encodingの配列(カテゴリ0の確率、カテゴリ1の確率、カテゴリ2の確率、 ... Fake Imagesである確率)を出力 します。CGANは学習を通して、Fake Imagesと見破られない精度の画像を出力できる生成器を定義することを目標とします。
ここで補足ですが、多くのCGANの実装では、判別器の出力を各カテゴリの確率とせず、Fake or Realとしているようです。今回の実装ではカテゴリ指定の影響をCGAN全体の学習に効率的に取り込みたかったことから、One-Hot Encodingの出力を選択しました。
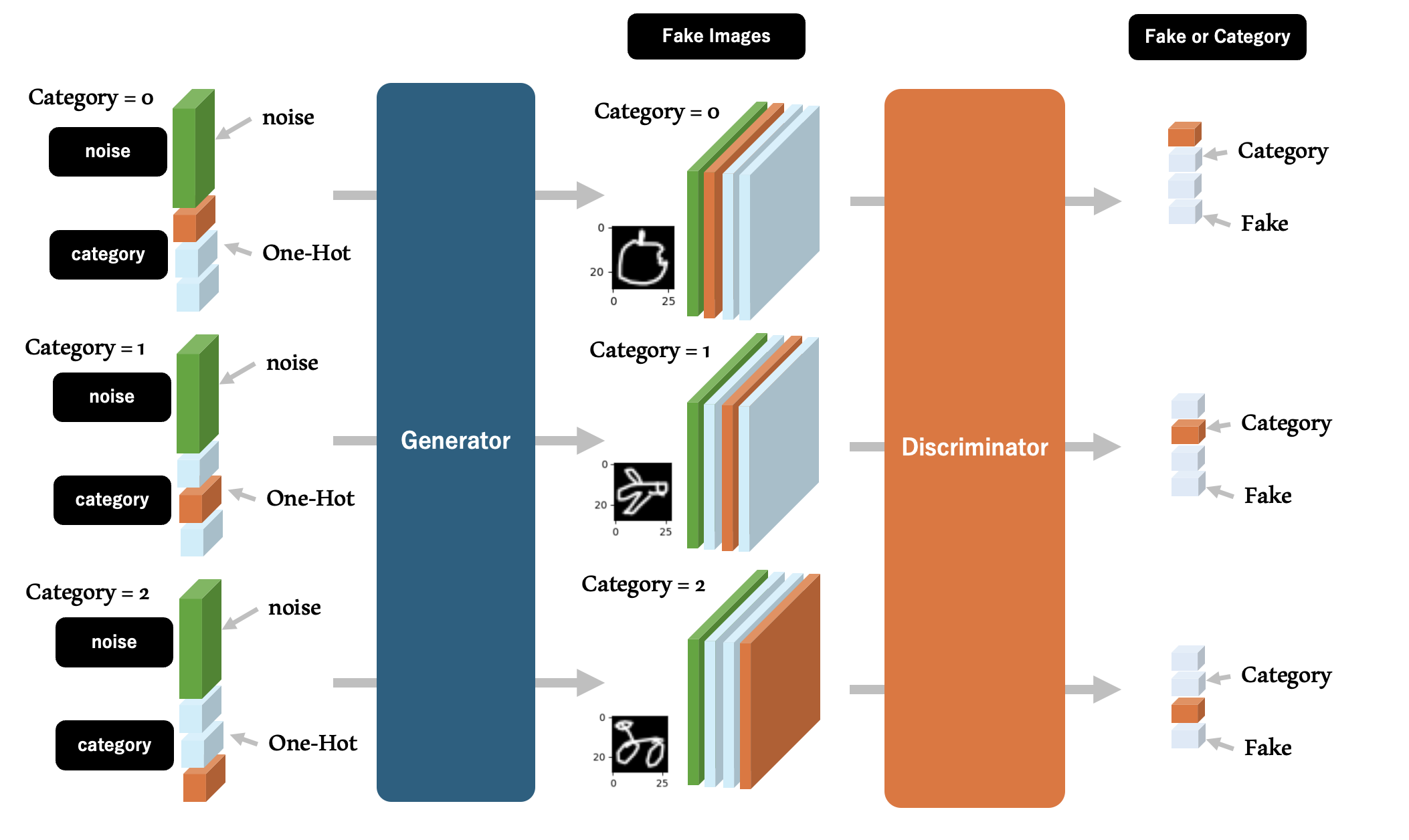
なお、本実装では、データセットから採取した Real Imagesにも、その画像のカテゴリに従ったOne-Hot Encodingのチャネルを付与してラベル付きの画像データとして扱います。 ラベルの付与方法は、以降の節で解説します。
はじめてGAN (Generative Adversarial Network : 敵対的生成ネットワーク) を実装される方は、下記の記事を一旦確認されることをオススメします
はじめてGAN (Generative Adversarial Network : 敵対的生成ネットワーク) について学ばれる方に向けて、まずカテゴリを含まず、 基本的なGANの構造と、生成器と判別器の意味を理解できるシンプルなGANを紹介する 下記の記事を準備しました。学習度にあわせてご利用ください。
はじめてTensorFlowを扱われる方へ
また、TensorFlowではじめてニューラルネットワークを実装される方にむけては、TensorFlowの基本的な使い方を以下の記事にて紹介しております。
CGAN (Categorical-Generative Adversarial Network : 敵対的生成ネットワーク) を使って、複数の種類の手書き風イラストを生成するまでのステップ
事前準備
まず、学習の前準備として、以下の記事に含まれている 「開発用のディレクトリを準備する」 を参考に開発環境と学習に利用するデータセットをご準備ください。
準備後、以下のように 作業ディレクトリ以下の「datasetディレクトリ」に「numpy形式 (.npy)」のファイルが格納されている ことを確認してください。
$ ls ./dataset/
# 'The Eiffel Tower.npy' ant.npy barn.npy beard.npy blackberry.npy bridge.npy
# 'The Great Wall of China.npy' anvil.npy 'baseball bat.npy' bed.npy blueberry.npy broccoli.npy
# 'The Mona Lisa.npy' apple.npy baseball.npy bee.npy book.npy broom.npy
# 'aircraft carrier.npy' arm.npy basket.npy belt.npy boomerang.npy bucket.npy
# airplane.npy asparagus.npy basketball.npy bench.npy bottlecap.npy bulldozer.npy
# 'alarm clock.npy' axe.npy bat.npy bicycle.npy bowtie.npy download.py
# ambulance.npy backpack.npy bathtub.npy binoculars.npy bracelet.npy
# angel.npy banana.npy beach.npy bird.npy brain.npy
# 'animal migration.npy' bandage.npy bear.npy 'birthday cake.npy' bread.npy
以上で、開発の事前準備は完了です。
TensorFlow.kerasでCGAN (Contditional-Generative Adversarial Network : 条件付き敵対的生成ネットワーク)を定義する
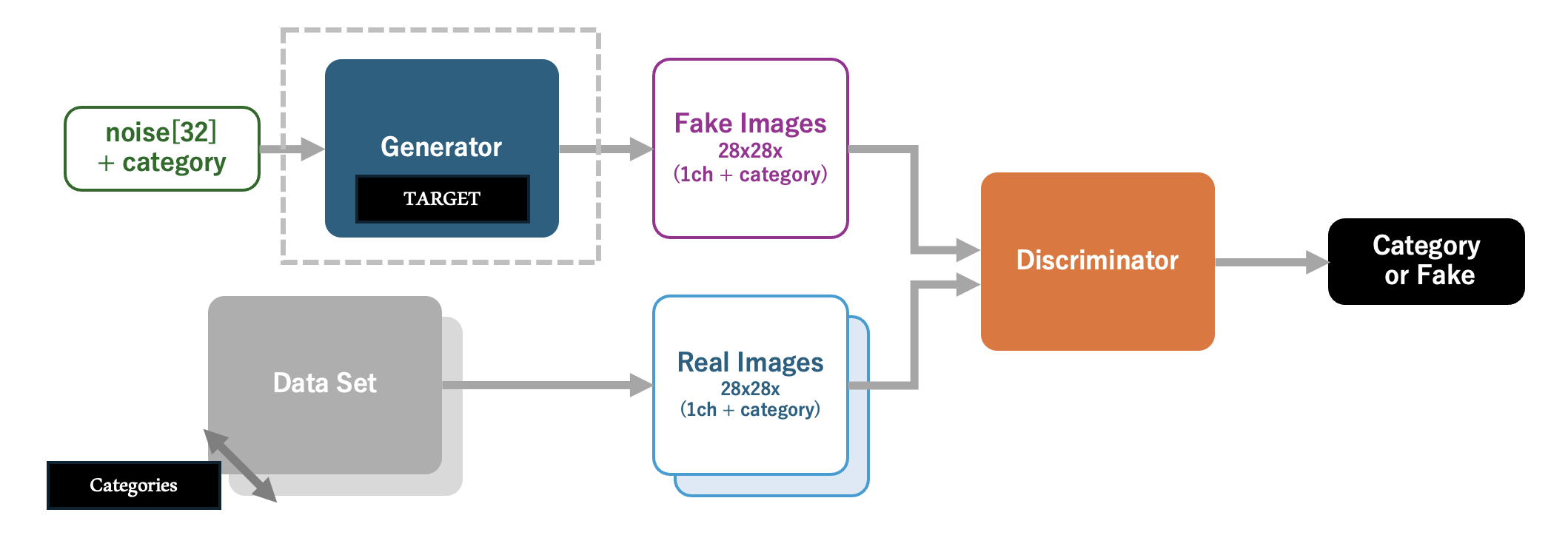
モデルの概要
今回実装するAIモデルを以下に示します。最終的に 入手したいのは、高い精度で指定したカテゴリ (りんご、飛行機、自転車) の手書き風イラストを生成できる生成器(Generator) です。 これを学習するためにAIが生成した画像(Fake Images)であるか、データセットからの画像(Real Images)であればどのカテゴリの画像であるかを識別する判別器(Discriminator)を定義します。 本モデルの学習を推進し、結果として 判別器(Discriminator)が本物と間違えるようなイラストを生成器が出力できるようになれば、学習成功 と言えます。
学習用データを準備する
今回の生成AIは、Quick Draw!の提供する3つのカテゴリに対応する手描きイラストを生成できることを目的としています。そのため apple.npy airplane.npy bicycle.npy を読み込んだ後、28px x 28px x 1ch(グレースケール画像)へと変形し、これを vstack で結合して、カテゴリごとに1000枚の画像を含む学習用データセットを構築 します。以下のプログラムは学習用データセットを準備し、先頭の8要素を画像へ出力するものです。
# 学習用データセットのnumpyファイル
INPUT_IMAGE_PATH = [
'./dataset/apple.npy',
'./dataset/airplane.npy',
'./dataset/bicycle.npy',
]
# 学習のカテゴリ数
NUM_OF_CATEGORYS = len(INPUT_IMAGE_PATH)
# データセットの長さ
LEN_OF_SINGLE_DATASET = 1000
# ...
######
### Numpy配列の先頭8要素を画像へ書き出す
######
def image_plot(imgs, path_savefig):
output_imgs = imgs[:8,:,:,:]
# 横長の4x2で画像を保存する
plt.figure(figsize=(5, 3))
for k in range(output_imgs.shape[0]):
plt.subplot(2, 4, k+1)
plt.imshow(output_imgs[k, :, :, 0], cmap='gray')
plt.tight_layout()
# 画像保存先のディレクトリを作成する
path_savefig = os.path.join(EXPORT_DIR_FOR_CGAN, path_savefig)
os.makedirs(os.path.dirname(path_savefig), exist_ok=True)
# 画像を保存する
plt.savefig(path_savefig)
print("Save images to :", path_savefig)
plt.clf()
plt.close()
# 画像の幅と高さ
img_w = 0
img_h = 0
# 学習用データセット
dataset = []
# 学習用データセットを読み込む
for cat_id in range(NUM_OF_CATEGORYS):
# データセットを読み込み、先頭"LEN_OF_SINGLE_DATASET"個を切り出す
data = np.load(INPUT_IMAGE_PATH[cat_id])
data = data[:LEN_OF_SINGLE_DATASET,]
# 0.0 - 1.0 へ正規化する
data = data / 255
# 28px x 28px の2次元データに変形する
data = np.reshape(data, [data.shape[0], 28, 28, 1])
# 画像の縦横サイズを取得する
img_w, img_h = data.shape[1:3]
# 学習用データの末尾に追加する
data = data[np.newaxis,:]
if cat_id == 0:
dataset = data
else:
dataset = np.vstack((dataset, data))
# 学習用データセットの一部を画像に出力する
for cat_id in range(NUM_OF_CATEGORYS):
# 学習用データセットを画像化する
image_plot(dataset[cat_id], INPUT_IMAGE_SAVEFIG.format(cat_id))
以下の画像がAIの学習用データセットとなります。

判別器の入力とするOne-Hot-Encodingラベル付きのデータを作成する
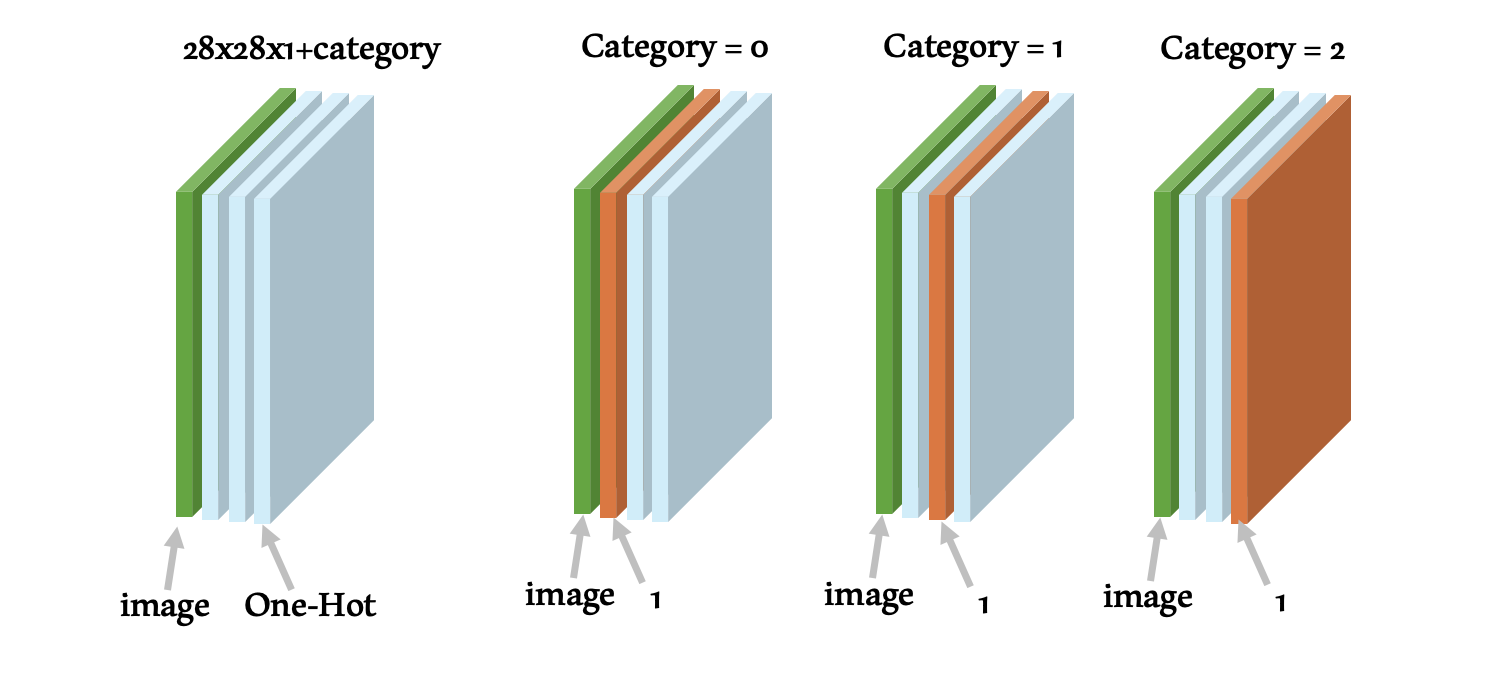
本記事のCGANで扱う画像は、28px x 28px x 1ch に、カテゴリ数分のチャネルを追加し、追加したチャネルにOne-Hot Encodingの値を格納したもの となります。そのため、前の手順で読み込んだ学習用データセットを加工し、カテゴリを示すチャネルを含んだ画像データを構築します。
カテゴリを含む学習用データセットの画像は以下のような構造になります。 Generatorを学習する前に生成できる「完全にランダムな画像」の場合は、全てのチャネルの値が乱数 となります。カテゴリを示すチャネルのOne-Hot Encodingは保証されません。
######
### 識別器に入力する画像のカテゴリを示すOne-Hotデータを生成する
######
def gen_category_for_disctiminator(set_dataset, category_id, img_w=28, img_h=28, categories=NUM_OF_CATEGORYS):
# カテゴリを示すOne-Hotデータを作成する
category_map = np.zeros((categories, 28, 28))
category_map[category_id,:,:] = 1.0
# 空のデータセットを作成
output_image_set = []
# 全ての画像にラベルをつける
for idx in range(set_dataset.shape[0]):
# 画像にひとつ軸を追加する
set_image = set_dataset[idx]
set_image = set_image.transpose((2, 0, 1))
set_image = np.vstack((set_image, category_map))
set_image = set_image.transpose((1, 2, 0))
# カテゴリ付きの画像を統合する
set_image = set_image[np.newaxis,:]
if idx == 0:
output_image_set = set_image
else:
output_image_set = np.vstack((output_image_set, set_image))
# 再構築したデータセットを返す
return output_image_set
data_with_category = []
for cat_id in range(NUM_OF_CATEGORYS):
print("Start Building Input Data (category id = {})".format(cat_id))
data_category_set = gen_category_for_disctiminator(set_dataset=dataset[cat_id], category_id=cat_id)
data_category_set = data_category_set[np.newaxis,:]
if cat_id == 0:
data_with_category = data_category_set
else:
data_with_category = np.vstack((data_with_category, data_category_set))
One-Hot-Encodingラベル付きのデータを画像に戻す処理を定義する
One-Hot Encodingを含む画像を、グレースケール画像として出力するためには、カテゴリを示すチャネルを除去するに必要があります。カテゴリは下記のコードで除去できます。
######
### ラベル付きの画像データからラベルを除去し、画像フォーマットにする
######
def strip_labels_in_image(labeling_images):
return labeling_images[:,:,:,0:1]
判別器を定義してコンパイルする
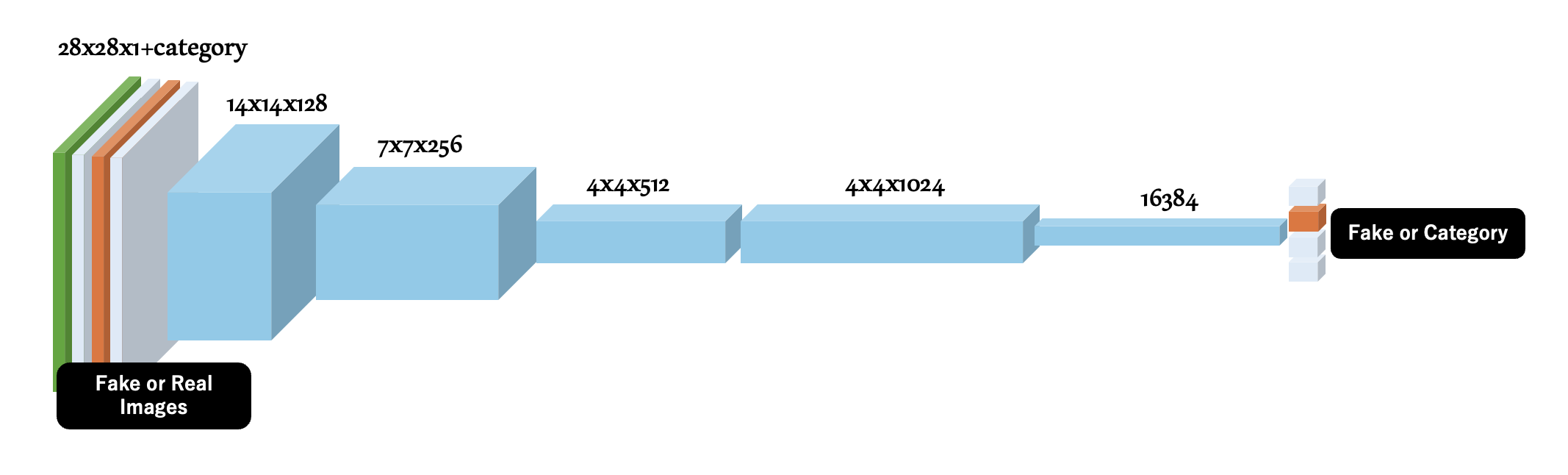
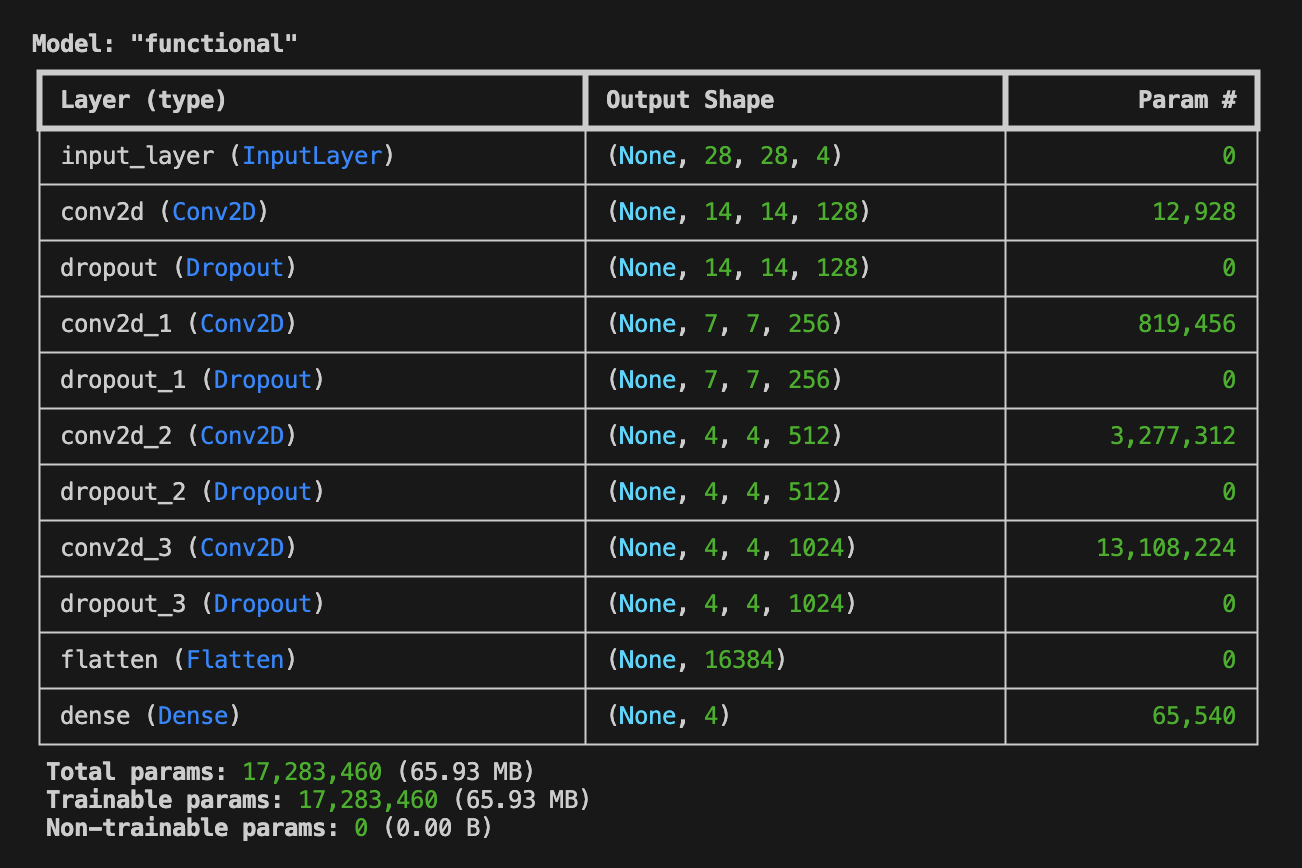
続いて判別器(Discriminator)を定義します。 判別器は、1枚の画像 (ここでは28px x 28px x 1ch(Gray-Scale) + カテゴリを示すチャネル)を入力とし、それがFake ImagesであるかReal Imagesのうちのいずれのカテゴリであるかを判別し、それぞれである確率を含むOne-Hot Encodingのリストを出力します。 画像を扱い、単純なGANよりも多くのチャネルを扱いますので、畳み込み層 (Conv2D) を利用し、28px x 28pxの画像を14x14x128、7x7x256、4x4x512、4x4x1024、1x1x16384にダウンサンプリングし、最終的に全結合層を用いて、確率を含むリストを求めます。 確率は合計1.0となるべきなので、全結合層のActivationにはSoftmaxを指定します(単純なGANでは出力が Fake(0) or Real(1) であったためActivationはsigmoidとなっていました)。
######
### 画像がAI生成のものか学習用データセットのものかを識別する
### 判別器(discriminator)を生成する関数を定義する
######
def build_discriminator(img_w=28, img_h=28, category=NUM_OF_CATEGORYS, depth=128, dropout_p=0.4):
# 入力は1枚の画像 + カテゴリーを示すOne-Hotデータ
input = Input((img_w, img_h, 1+category))
# 28x28に対する5x5で深さdepthの畳み込み層 -> 14x14
x = Conv2D(depth*1, 5, strides=2, padding='same', activation='relu')(input)
# Dropout
x = Dropout(dropout_p)(x)
# 14x14に対する5x5で深さdepthx2の畳み込み層 -> 7x7
x = Conv2D(depth*2, 5, strides=2, padding='same', activation='relu')(x)
# Dropout
x = Dropout(dropout_p)(x)
# 7x7に対する5x5で深さdepthx4の畳み込み層 -> 4x4
x = Conv2D(depth*4, 5, strides=2, padding='same', activation='relu')(x)
# Dropout
x = Dropout(dropout_p)(x)
# 4x4に対する3x3で深さdepthx8の畳み込み層 -> 4x4
x = Conv2D(depth*8, 5, strides=1, padding='same', activation='relu')(x)
# Dropout
x = Dropout(dropout_p)(x)
# 1次元配列に展開する
x = Flatten()(x)
# 全結合して結果を出力する
output = Dense(1 + category, activation='softmax')(x)
# モデルを生成する
model = Model(inputs=input, outputs=output)
# モデルを返す
return model
# 判別器を取得する
D_model = build_discriminator()
# 判別器の学習に使うLearning Rateを算出する関数を定義する
D_lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=8e-4,
decay_steps=20000,
decay_rate=6e-8)
# 判別器をコンパイルする
D_model.compile(loss='binary_crossentropy',
optimizer=RMSprop(learning_rate=D_lr_schedule),
metrics=['accuracy'])
# modelを表示する
D_model.summary()
構築されたネットワークを model.summary() により表示すると、以下のような出力を得ることができます。このとき、 Trainable param と Total params が一致している ことを確認しておいてください。
生成器を定義する
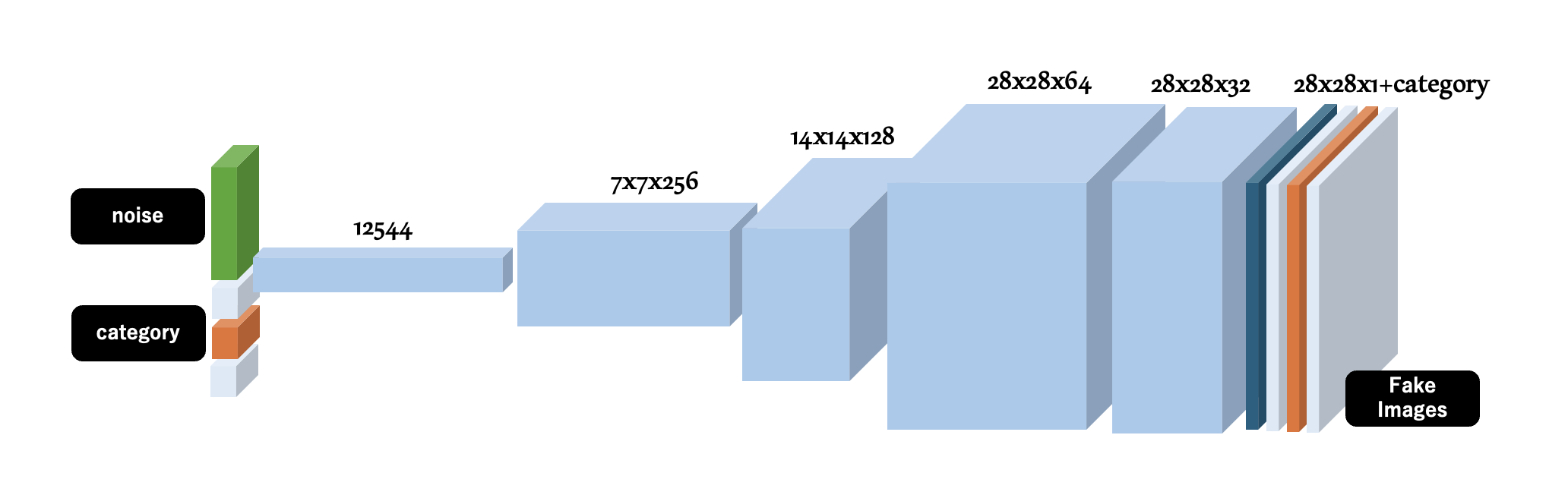
次に生成器(Generator)を定義します。 Generatorはランダムな値を含んだ「ノイズ (出力画像のバリエーションを決めるためのランダムな値)」とそれに続く「カテゴリ値(One-Hot Encoding)」を入力 として、UpSamplingとConv2DTransposeにより、1x12544、7x7x256、14x14x128、28x28x64、28x28x32といったアップサンプリングを経て、 28px x 28px x 1ch(Gray-Scale) + カテゴリを示すチャネルを保持した画像を生成 します。生成器が出力する画像は、Fake Imagesと呼ばれ、前に定義した判別器によりFakeと判断されるはずです。しかし、これを見事に Fakeでない(いずれかのカテゴリに属する画像である) と判定させることができれば、人の力を借りず 指定したカテゴリの手書き風画像をノイズから生成することのできる生成器 を実現できるというわけです。
######
### 乱数とラベルから学習用データと見分けの付かない画像を生成する
### 生成器(generator)を生成する関数を定義する
######
Z_DEMENSIONS = 32
def build_generator(img_w=28, img_h=28, category=NUM_OF_CATEGORYS, latent_dim=Z_DEMENSIONS, depth=256, dropout_p=0.4):
# 入力は複数要素を持ったノイズデータとする
input_noise = Input((latent_dim + category,))
# 全結合層に展開する
x = Dense(int(img_w / 4) * int(img_h / 4) * depth)(input_noise)
x = BatchNormalization(momentum=0.9)(x)
x = Activation(activation='relu')(x)
x = Reshape((int(img_w / 4), int(img_h / 4), depth))(x)
x = Dropout(dropout_p)(x)
# アップサンプリングと逆畳み込みを適用する
# 7x7xdepthに対するアップサンプリングと逆畳み込み -> 14x14
x = UpSampling2D()(x)
x = Conv2DTranspose(int(depth/2), kernel_size=5, padding='same', activation=None,)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation(activation='relu')(x)
# 14x14xdepth/2 に対するアップサンプリングと逆畳み込み -> 28x28
x = UpSampling2D()(x)
x = Conv2DTranspose(int(depth/4), kernel_size=5, padding='same', activation=None,)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation(activation='relu')(x)
# 28x28xdepth/4 に対する逆畳み込み -> 28x28
x = Conv2DTranspose(int(depth/8), kernel_size=5, padding='same', activation=None,)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation(activation='relu')(x)
# 出力層
output_img = Conv2D(1 + category, kernel_size=5, padding='same', activation='sigmoid')(x)
# モデルを生成する
model = Model(inputs=input_noise, outputs=output_img)
# モデルを返す
return model
# 生成器を取得する
G_model = build_generator()
# modelを表示する
G_model.summary()
構築されたネットワークを model.summary() により表示すると、以下のような出力を得ることができます。このとき、 Trainable param が 1,555,748 であること を確認しておいてください。この値は後の説明で登場します。
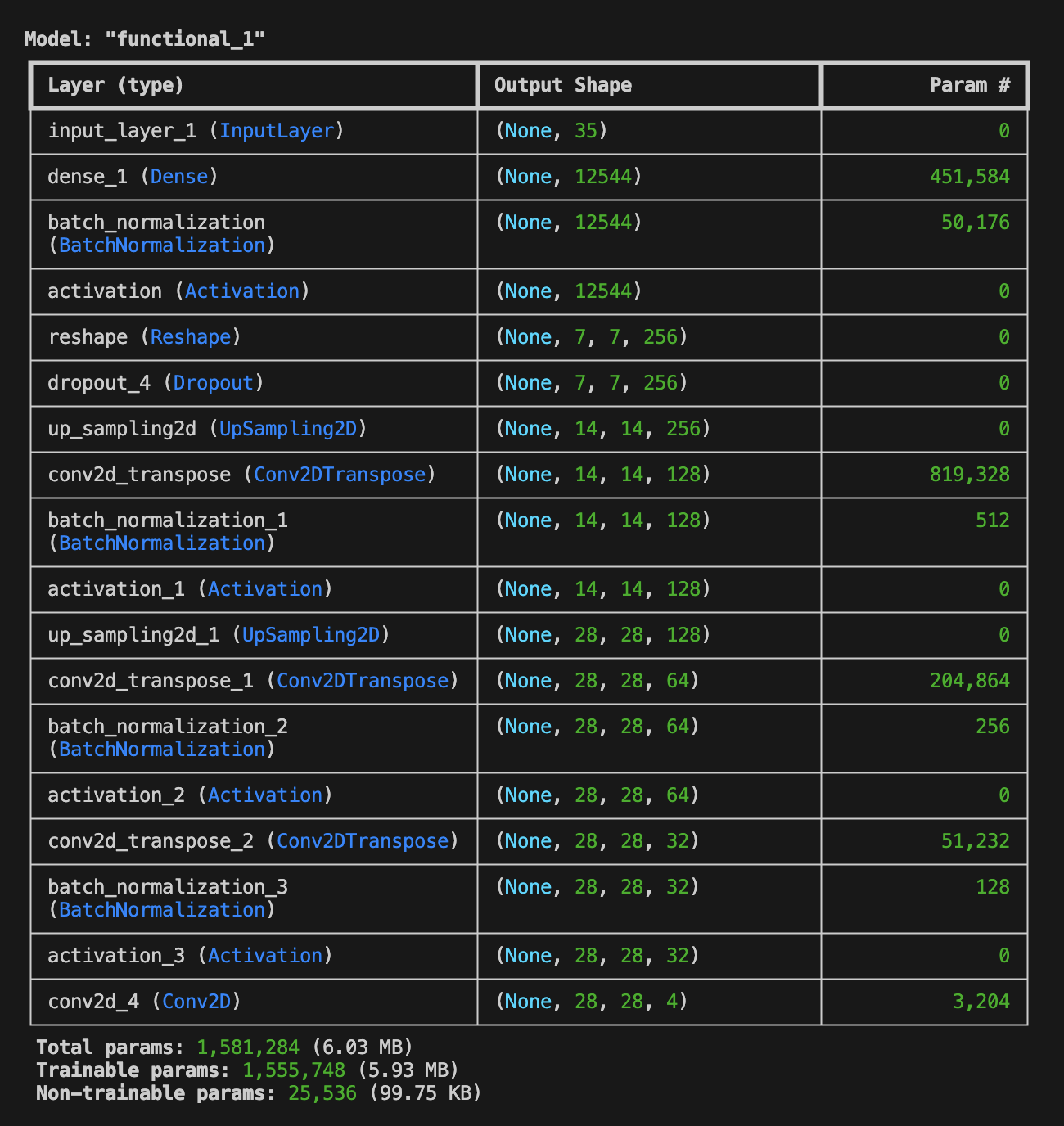
敵対的ネットワークを定義する
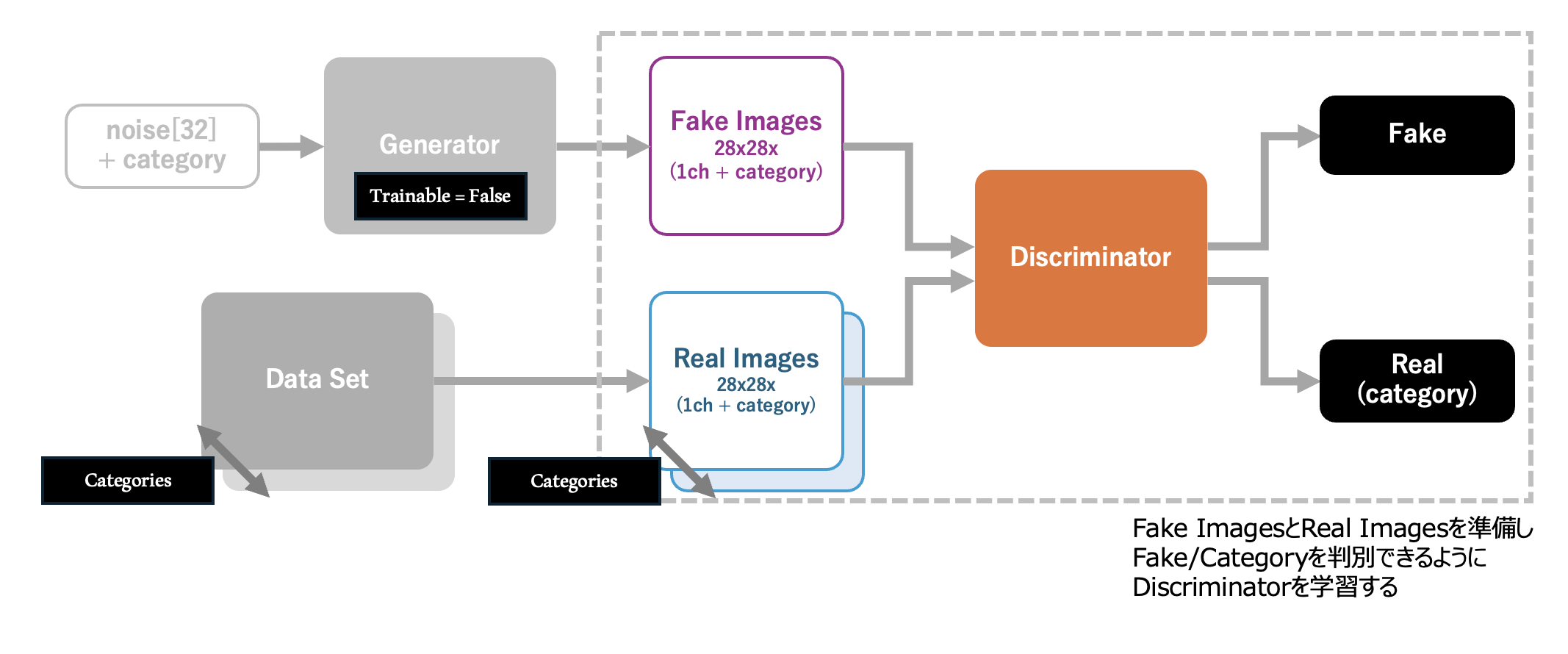
生成器と判別器を定義できたので、これらを組み合わせてGANを構築します。 GANは、生成器の入力である「ノイズ」と「カテゴリを指定するOne-Hot Encodingの配列」を入力とし、Generatorにより生成されたFake Imagesを、Discriminatorへと入力、結果、それがFakeであるかいずれかのカテゴリに属する画像であるかを判別 する、といった構造になっています。
判別器(Discriminator)は、GANとは別に学習を行うものとし、 GANを学習する際には判別器の trainable 属性を False (学習によりモデルのパラメータを更新しない設定)に設定 しておきます。GANの学習は、このモデルが入力に対して 生成器(Generator)の学習を促し、データセットと見分けが付かないレベルの画像を生成できる生成器を実現し、判別器が生成器の出力をReal (データセットからの画像である) と誤認できること を目的とします。
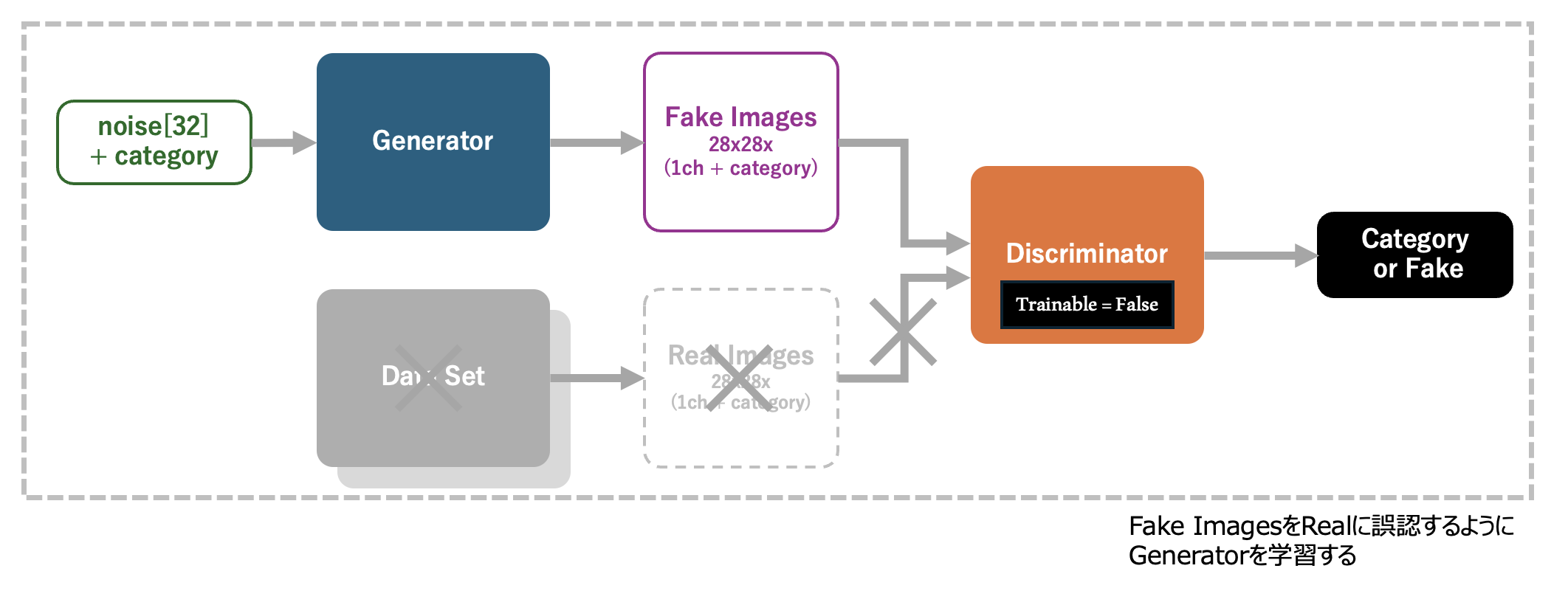
データフロー全体は下記のようになります。 「ノイズ」と「カテゴリを指定するOne-Hot Encodingの配列」の入力が全て、判別器により「指定されたカテゴリのデータセットからの画像である(Fakeでない)」と判断されることがゴール となります。
######
### D_model と G_model を組み合わせて
### 敵対的ネットワークを構築する
######
# 入力はZ要素のノイズ
input_noise = Input(shape=(Z_DEMENSIONS + NUM_OF_CATEGORYS,))
# ノイズからFake画像を生成する
imgs_fake = G_model(input_noise)
# 判別器の学習を止めておく
D_model.trainable = False
# 判別器でFake画像を判定する
output_pred = D_model(imgs_fake)
# ノイズを入力として、Fake判定を出力とするネットワークを構築する
A_model = Model(input_noise, output_pred)
# 判別器の学習に使うLearning Rateを算出する関数を定義する
A_lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=4e-4,
decay_steps=20000,
decay_rate=3e-8)
# modelをコンパイルする
A_model.compile(loss='binary_crossentropy',
optimizer=RMSprop(learning_rate=A_lr_schedule),
metrics=['accuracy'])
# modelを表示する
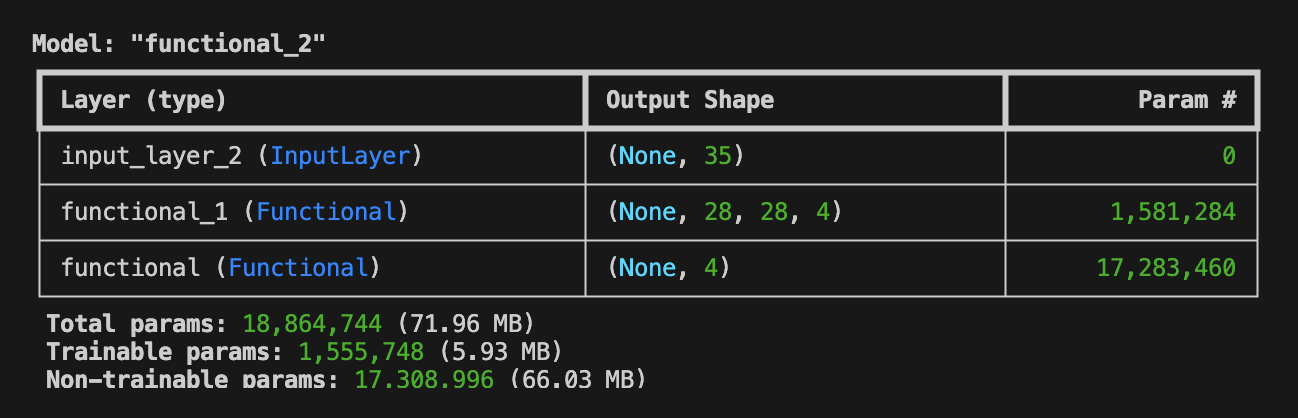
A_model.summary()
構築されたネットワークを model.summary() により表示すると、以下のような出力を得ることができます。 このとき、 Trainable param が 1,555,748 であること に注目してください。この値は生成器の Trainable param と一致 しており、このAIモデルの一部となっている判別器のパラメータは Non-trainable prams として学習時に更新されないものとして扱われます。
モデルの学習処理を定義する
GANの学習は2つのフェーズから構成されます。
まず最初のフェーズでは判別器(Discriminator)の学習を行います。 学習を停止させた生成器(Generator)から生成した「batchサイズ」の画像 (Fake Images) を準備し、データセットから「batchサイズ × カテゴリ数」の画像 (Real Images) を準備します。 Fake ImagesとReal Imagesを連結し、対象のデータが Fake Images / Real Images のいずれのラベルであるかを示す「期待する出力値」を付与し、学習用データセットとします。 このデータセットにより学習を行うことで、 判別器は対象とする画像がQuick Draw! から入手した画像の品質に達しているかどうかを識別できる ようになります。
次のフェーズの学習では、 前のフェーズで Fake Images / Real Images を判別できるようになった判別器の学習を停止 し、入力であるノイズとカテゴリの指定値から、生成器が適当な画像を出力し、これが「本物である (いずれかのカテゴリに属している)」と誤認 するようにGAN全体の学習を行います。この学習により、生成器のパラメータが更新され、よりデータセットに近い画像を生成できるようになります。
以上に基づいたCGANの学習処理は、以下のようになります。
######
### これ以降にGANを学習するプログラムを実装します
######
def train(real, g_model, d_model, a_model, category=NUM_OF_CATEGORYS, epochs=2000, batch=128, z_dim=Z_DEMENSIONS):
# 学習結果を出力するためのリスト
d_metrics = []
a_metrics = []
# Accuracyと損失を記録する
running_d_loss = 0
running_d_acc = 0
running_a_loss = 0
running_a_acc = 0
for epoch in range(epochs):
######
### 判別器の学習
imgs_real = []
# 本物の手描きイラストをbatchサイズ分集める
for cat_id in range(category):
imgs_real_in_cat = np.reshape(
real[cat_id][np.random.choice(real[cat_id].shape[0], batch, replace=False)],
(batch, 28, 28, 1 + category)
)
if cat_id == 0:
imgs_real = imgs_real_in_cat
else:
imgs_real = np.concatenate((imgs_real, imgs_real_in_cat), 0)
# 生成器の入力は乱数
input_noise = np.random.uniform(-1.0, 1.0, size=[batch, z_dim + category])
imgs_fake = g_model.predict(input_noise)
# 本物と偽物の画像をセットにする
x = np.concatenate((imgs_real, imgs_fake))
# 本物と偽物のラベルを作る(本物=1, 偽物=0)
y = np.zeros([(category + 1) * batch, 1 + category])
for cat_id in range(category):
y[batch * cat_id : batch * (cat_id+1), cat_id] = 1.0
y[batch * category:, category] = 1.0
# 判別器の学習を止めておく
d_model.trainable = True
# 判別器のパラメータを確認する
if epoch == 0:
d_model.summary()
# 判別器の学習を実行する
d_metrics.append(
d_model.train_on_batch(x, y)
)
# 損失は終端要素の[0]に格納されている
running_d_loss += d_metrics[-1][0]
# Accuracyは終端要素の[1]に格納されている
running_d_acc += d_metrics[-1][1]
######
### 生成器の学習
# 生成器の入力は乱数 + カテゴリ
# -->> 生成するカテゴリに1を立てる(One-Hot)
input_noise = np.random.uniform(-1.0, 1.0, size=[batch * category, z_dim + category])
input_noise[:batch * category, z_dim:] = 0.0
for cat_id in range(category):
input_noise[batch * cat_id : batch * (cat_id+1), z_dim + cat_id] = 1.0
# 本物の画像を識別できるように学習する
# -->> 本物と誤認した場合のラベルを作る
y = np.zeros([category * batch, 1 + category])
for cat_id in range(category):
y[batch * cat_id : batch * (cat_id+1), cat_id] = 1.0
# 判別器の学習を止めておく
d_model.trainable = False
# GANのパラメータを確認する
if epoch == 0:
a_model.summary()
# GANの学習を実行する
a_metrics.append(
a_model.train_on_batch(input_noise, y)
)
# 損失は終端要素の[0]に格納されている
running_a_loss += a_metrics[-1][0]
# Accuracyは終端要素の[1]に格納されている
running_a_acc += a_metrics[-1][1]
# 100epochs毎に進捗状況と生成画像を出力する
if (epoch + 1) % 100 == 0:
print('Epoch #{}'.format(epoch+1))
### 損失とAccuracyを表示する
log_msg = "%d: [D loss: %f, acc: %f]" % (epoch+1, running_d_loss / (epoch+1), running_d_acc / (epoch+1))
log_msg = "%s [A loss: %f, acc: %f]" % (log_msg, running_a_loss / (epoch+1), running_a_acc / (epoch+1))
print(log_msg)
### 学習で利用した画像を記録する
for cat_id in range(category):
images = strip_labels_in_image(imgs_real[cat_id * batch : (cat_id+1) * batch])
save_path = os.path.join(EPOCH_INPUT_IMAGE_DIR, EPOCH_INPUT_IMAGE_SAVEFIG.format(cat_id, epoch + 1))
image_plot(images, save_path)
### 生成器が生成した画像を記録する
for cat_id in range(category):
input_noise = np.random.uniform(-1.0, 1.0, size=[16, z_dim + category])
input_noise[:,z_dim:] = 0.0
input_noise[:,z_dim + cat_id] = 1.0
imgs_gen = G_model.predict(input_noise)
save_path = os.path.join(EPOCH_OUTPUT_IMAGE_DIR, EPOCH_OUTPUT_IMAGE_SAVEFIG.format(cat_id, epoch + 1))
image_plot(imgs_gen, save_path)
return a_metrics, d_metrics
a_metrics_complete, d_metrics_complete = train(real=data_with_category, g_model=G_model, d_model=D_model, a_model=A_model,
category=NUM_OF_CATEGORYS,
epochs=6000, batch=128, z_dim=Z_DEMENSIONS)
学習中のAccuracyと損失を可視化する
最後にTensorFlowの学習メソッド train_on_batch 実行時に出力された Accuracy と Loss(損失) をグラフにまとめます。
# 損失のグラフを生成する
column_a = [metric[0] for metric in a_metrics_complete]
column_d = [metric[0] for metric in d_metrics_complete]
plt.plot(column_a)
plt.plot(column_d)
plt.yscale('log')
plt.savefig(GRAPH_IMAGE_LOSS)
plt.clf()
plt.close()
# Accracyのグラフを生成する
column_a = [metric[1] for metric in a_metrics_complete]
column_d = [metric[1] for metric in d_metrics_complete]
plt.plot(column_a)
plt.plot(column_d)
plt.savefig(GRAPH_IMAGE_ACCURACY)
plt.clf()
plt.close()
AccuracyとLossのグラフは以下のようになります。
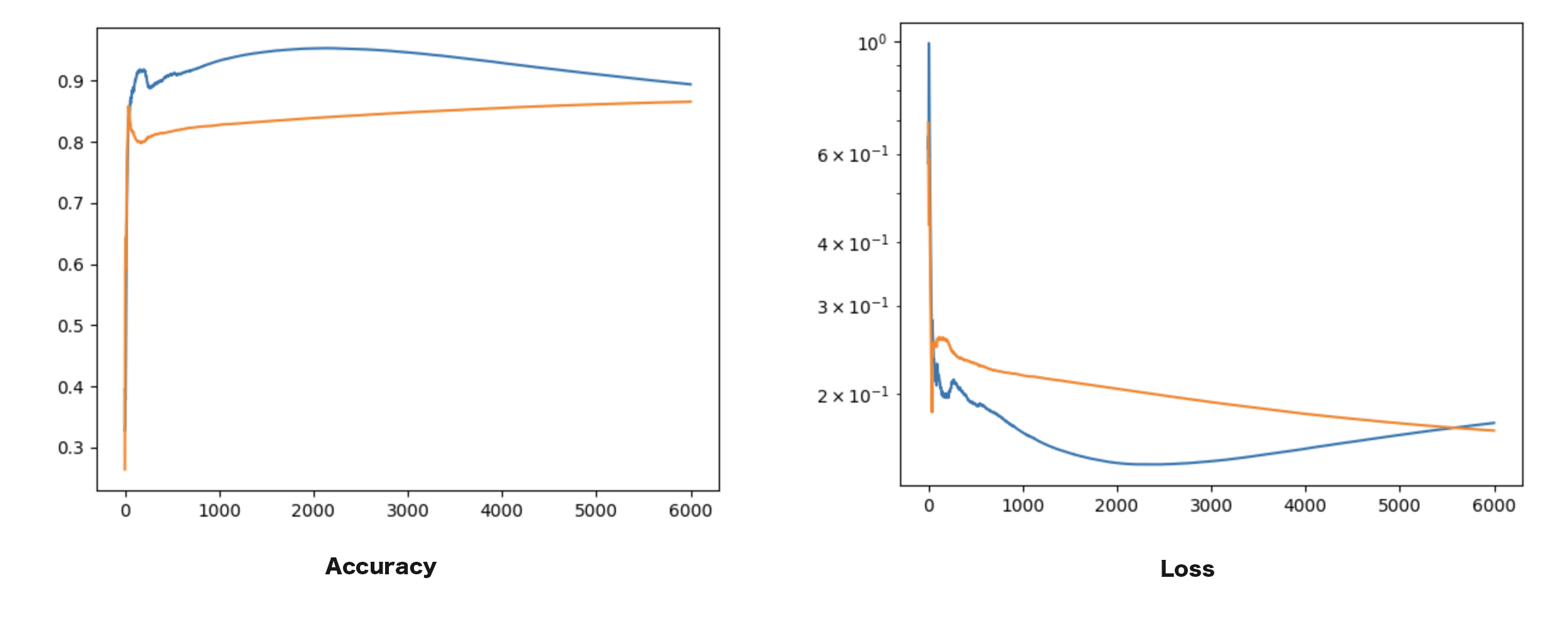
学習結果
判別器(Discriminator)と生成器(Generator)を定義し、これを統合したCGANを学習することにより、 生成器は以下のように指定したカテゴリ(りんご、飛行機、自転車)の画像を生成できるようになりました。 各2行が、それぞれのepoch毎の出力結果であり、学習を進めるにつれて、生成器はぼやけた画像から はっきりと特徴のわかる画像を生成できる ようになっている様子を見ることができます。
りんごのカテゴリを指定した場合の生成機の出力

飛行機のカテゴリを指定した場合の生成機の出力

自転車のカテゴリを指定した場合の生成機の出力
学習中のリソース消費量
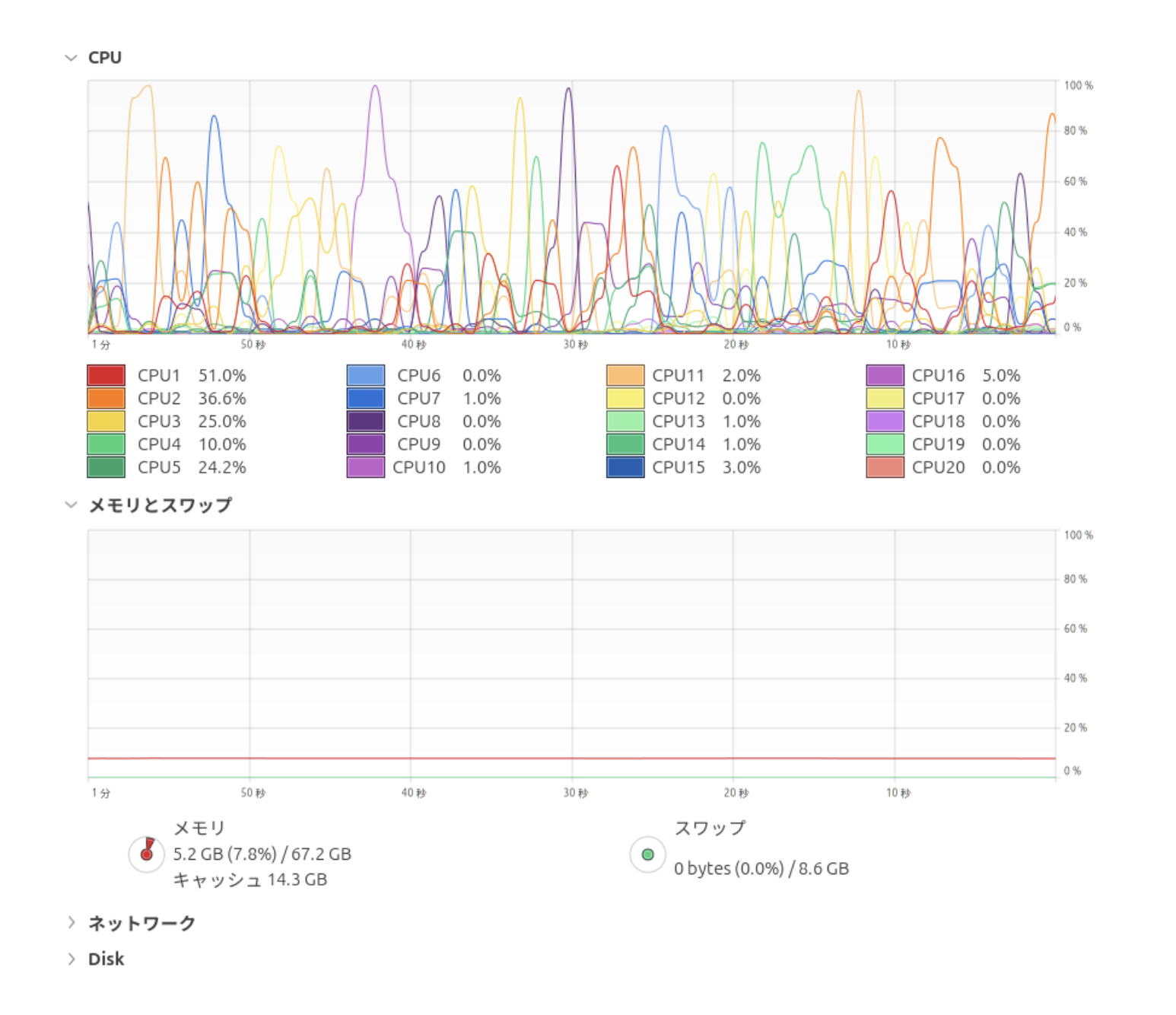
CGANを カテゴリ数を3種類とし、batch sizeを128として実行したところ、GPUのメモリ消費量は6112MiB となりました。より多くのカテゴリに対応したCGANの学習を行う場合には、カテゴリ情報を保持するためにモデルを構成する各層の深さを深くしないといけませんので、より多くのメモリが求められます。そのため、GPUのメモリに乗るように、batch sizeをはじめとするハイパーパラメータを調整する必要があります。
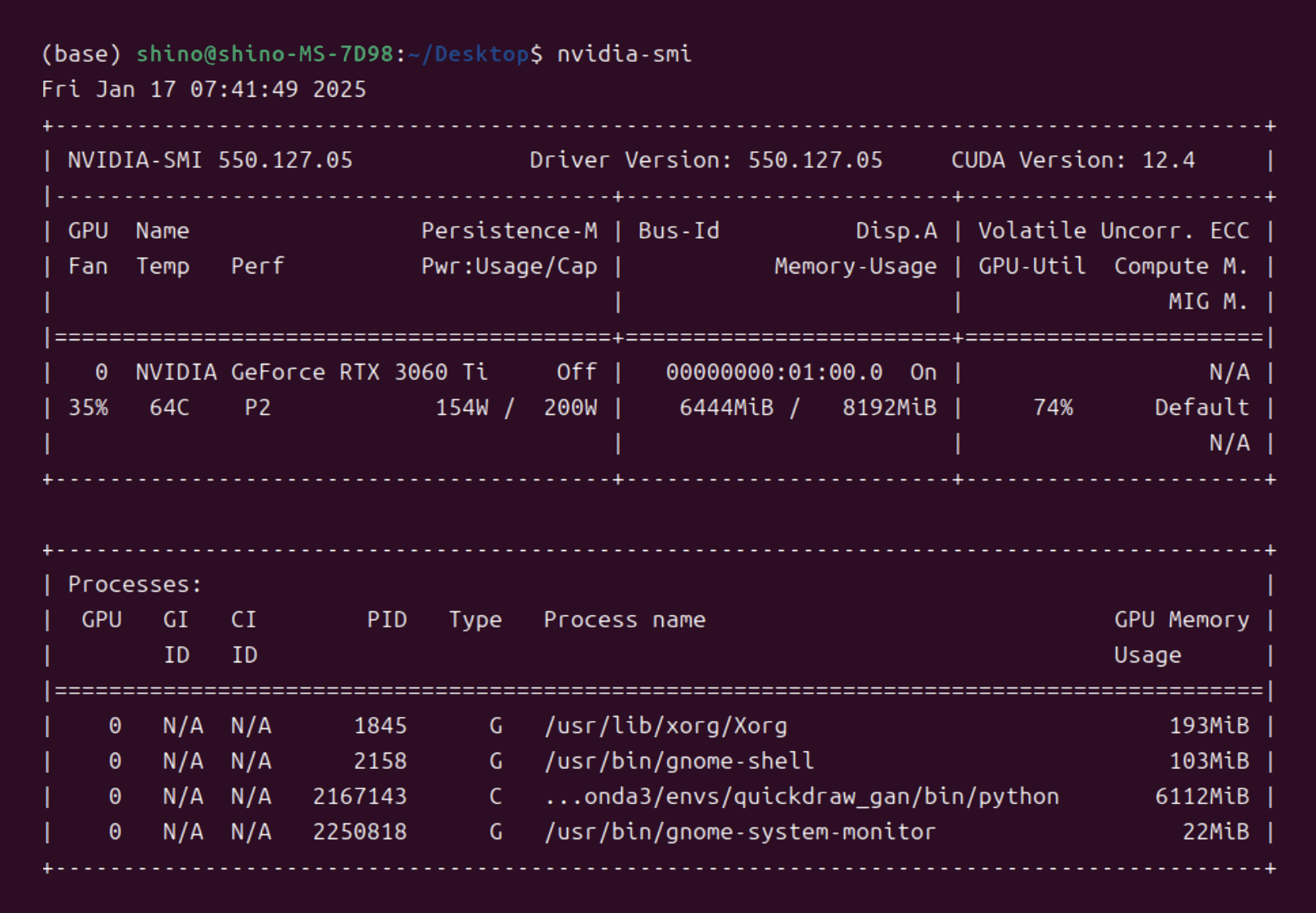
CPUとメインメモリへの負荷はそれほど高くありませんでした。
以上が、TensorFlow.kerasのフレームワークを使ってCGAN/CTGAN (Categorical-Generative Adversarial Network : 条件付き敵対的生成ネットワーク) を実装する流れとなります。 CGANを使うことにより、簡単にバリエーションに富んだ出力を生成できるAI(Generative AI)を定義できます。 是非参考にしてみてください。
ありがとうございました。
ソースコード全文
以下に今回実装したソースコード全文を掲載します。
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Dense, Conv2D, Dropout
from tensorflow.keras.layers import BatchNormalization, Flatten
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Reshape
from tensorflow.keras.layers import Conv2DTranspose
from tensorflow.keras.layers import UpSampling2D
from tensorflow.keras.optimizers import RMSprop
from matplotlib import pyplot as plt
import numpy as np
import os
# 学習用データセットのnumpyファイル
INPUT_IMAGE_PATH = [
'./dataset/apple.npy',
'./dataset/airplane.npy',
'./dataset/bicycle.npy',
]
# 学習のカテゴリ数
NUM_OF_CATEGORYS = len(INPUT_IMAGE_PATH)
# データセットの長さ
LEN_OF_SINGLE_DATASET = 1000
# CGANの実行結果を格納するディレクトリ
EXPORT_DIR_FOR_CGAN = 'cgan_out'
# 学習用データセットを画像化して保存するファイルパス
INPUT_IMAGE_SAVEFIG = 'inputs_cat{}.png'
# 生成する画像を格納するフォルダ
EPOCH_INPUT_IMAGE_DIR = 'gen/input'
EPOCH_OUTPUT_IMAGE_DIR = 'gen/output'
# 100epochs単位で生成される画像を格納するファイルパス
EPOCH_INPUT_IMAGE_SAVEFIG = 'input_cat{}_{}epochs.png'
EPOCH_OUTPUT_IMAGE_SAVEFIG = 'output_cat{}_{}epochs.png'
# 損失グラフの出力先
GRAPH_IMAGE_LOSS = 'graph_loss.png'
# Accuracyグラフの出力先
GRAPH_IMAGE_ACCURACY = 'graph_acc.png'
######
### Numpy配列の先頭8要素を画像へ書き出す
######
def image_plot(imgs, path_savefig):
output_imgs = imgs[:8,:,:,:]
# 横長の4x2で画像を保存する
plt.figure(figsize=(5, 3))
for k in range(output_imgs.shape[0]):
plt.subplot(2, 4, k+1)
plt.imshow(output_imgs[k, :, :, 0], cmap='gray')
plt.tight_layout()
# 画像保存先のディレクトリを作成する
path_savefig = os.path.join(EXPORT_DIR_FOR_CGAN, path_savefig)
os.makedirs(os.path.dirname(path_savefig), exist_ok=True)
# 画像を保存する
plt.savefig(path_savefig)
print("Save images to :", path_savefig)
plt.clf()
plt.close()
# 画像の幅と高さ
img_w = 0
img_h = 0
# 学習用データセット
dataset = []
# 学習用データセットを読み込む
for cat_id in range(NUM_OF_CATEGORYS):
# データセットを読み込み、先頭"LEN_OF_SINGLE_DATASET"個を切り出す
data = np.load(INPUT_IMAGE_PATH[cat_id])
data = data[:LEN_OF_SINGLE_DATASET,]
# 0.0 - 1.0 へ正規化する
data = data / 255
# 28px x 28px の2次元データに変形する
data = np.reshape(data, [data.shape[0], 28, 28, 1])
# 画像の縦横サイズを取得する
img_w, img_h = data.shape[1:3]
# 学習用データの末尾に追加する
data = data[np.newaxis,:]
if cat_id == 0:
dataset = data
else:
dataset = np.vstack((dataset, data))
# 学習用データセットの一部を画像に出力する
for cat_id in range(NUM_OF_CATEGORYS):
# 学習用データセットを画像化する
image_plot(dataset[cat_id], INPUT_IMAGE_SAVEFIG.format(cat_id))
######
### これ以降に学習用データセットを利用するGANを実装します
######
######
### 画像がAI生成のものか学習用データセットのものかを識別する
### 判別器(discriminator)を生成する関数を定義する
######
def build_discriminator(img_w=28, img_h=28, category=NUM_OF_CATEGORYS, depth=128, dropout_p=0.4):
# 入力は1枚の画像 + カテゴリーを示すOne-Hotデータ
input = Input((img_w, img_h, 1+category))
# 28x28に対する5x5で深さdepthの畳み込み層 -> 14x14
x = Conv2D(depth*1, 5, strides=2, padding='same', activation='relu')(input)
# Dropout
x = Dropout(dropout_p)(x)
# 14x14に対する5x5で深さdepthx2の畳み込み層 -> 7x7
x = Conv2D(depth*2, 5, strides=2, padding='same', activation='relu')(x)
# Dropout
x = Dropout(dropout_p)(x)
# 7x7に対する5x5で深さdepthx4の畳み込み層 -> 4x4
x = Conv2D(depth*4, 5, strides=2, padding='same', activation='relu')(x)
# Dropout
x = Dropout(dropout_p)(x)
# 4x4に対する3x3で深さdepthx8の畳み込み層 -> 4x4
x = Conv2D(depth*8, 5, strides=1, padding='same', activation='relu')(x)
# Dropout
x = Dropout(dropout_p)(x)
# 1次元配列に展開する
x = Flatten()(x)
# 全結合して結果を出力する
output = Dense(1 + category, activation='softmax')(x)
# モデルを生成する
model = Model(inputs=input, outputs=output)
# モデルを返す
return model
######
### 識別器に入力する画像のカテゴリを示すOne-Hotデータを生成する
######
def gen_category_for_disctiminator(set_dataset, category_id, img_w=28, img_h=28, categories=NUM_OF_CATEGORYS):
# カテゴリを示すOne-Hotデータを作成する
category_map = np.zeros((categories, 28, 28))
category_map[category_id,:,:] = 1.0
# 空のデータセットを作成
output_image_set = []
# 全ての画像にラベルをつける
for idx in range(set_dataset.shape[0]):
# 画像にひとつ軸を追加する
set_image = set_dataset[idx]
set_image = set_image.transpose((2, 0, 1))
set_image = np.vstack((set_image, category_map))
set_image = set_image.transpose((1, 2, 0))
# カテゴリ付きの画像を統合する
set_image = set_image[np.newaxis,:]
if idx == 0:
output_image_set = set_image
else:
output_image_set = np.vstack((output_image_set, set_image))
# 再構築したデータセットを返す
return output_image_set
data_with_category = []
for cat_id in range(NUM_OF_CATEGORYS):
print("Start Building Input Data (category id = {})".format(cat_id))
data_category_set = gen_category_for_disctiminator(set_dataset=dataset[cat_id], category_id=cat_id)
data_category_set = data_category_set[np.newaxis,:]
if cat_id == 0:
data_with_category = data_category_set
else:
data_with_category = np.vstack((data_with_category, data_category_set))
# 判別器を取得する
D_model = build_discriminator()
# 判別器の学習に使うLearning Rateを算出する関数を定義する
D_lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=8e-4,
decay_steps=20000,
decay_rate=6e-8)
# 判別器をコンパイルする
D_model.compile(loss='binary_crossentropy',
optimizer=RMSprop(learning_rate=D_lr_schedule),
metrics=['accuracy'])
# modelを表示する
D_model.summary()
######
### 乱数とラベルから学習用データと見分けの付かない画像を生成する
### 生成器(generator)を生成する関数を定義する
######
Z_DEMENSIONS = 32
def build_generator(img_w=28, img_h=28, category=NUM_OF_CATEGORYS, latent_dim=Z_DEMENSIONS, depth=256, dropout_p=0.4):
# 入力は複数要素を持ったノイズデータとする
input_noise = Input((latent_dim + category,))
# 全結合層に展開する
x = Dense(int(img_w / 4) * int(img_h / 4) * depth)(input_noise)
x = BatchNormalization(momentum=0.9)(x)
x = Activation(activation='relu')(x)
x = Reshape((int(img_w / 4), int(img_h / 4), depth))(x)
x = Dropout(dropout_p)(x)
# アップサンプリングと逆畳み込みを適用する
# 7x7xdepthに対するアップサンプリングと逆畳み込み -> 14x14
x = UpSampling2D()(x)
x = Conv2DTranspose(int(depth/2), kernel_size=5, padding='same', activation=None,)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation(activation='relu')(x)
# 14x14xdepth/2 に対するアップサンプリングと逆畳み込み -> 28x28
x = UpSampling2D()(x)
x = Conv2DTranspose(int(depth/4), kernel_size=5, padding='same', activation=None,)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation(activation='relu')(x)
# 28x28xdepth/4 に対する逆畳み込み -> 28x28
x = Conv2DTranspose(int(depth/8), kernel_size=5, padding='same', activation=None,)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation(activation='relu')(x)
# 出力層
output_img = Conv2D(1 + category, kernel_size=5, padding='same', activation='sigmoid')(x)
# モデルを生成する
model = Model(inputs=input_noise, outputs=output_img)
# モデルを返す
return model
# 生成器を取得する
G_model = build_generator()
# modelを表示する
G_model.summary()
######
### D_model と G_model を組み合わせて
### 敵対的ネットワークを構築する
######
# 入力はZ要素のノイズ
input_noise = Input(shape=(Z_DEMENSIONS + NUM_OF_CATEGORYS,))
# ノイズからFake画像を生成する
imgs_fake = G_model(input_noise)
# 判別器の学習を止めておく
D_model.trainable = False
# 判別器でFake画像を判定する
output_pred = D_model(imgs_fake)
# ノイズを入力として、Fake判定を出力とするネットワークを構築する
A_model = Model(input_noise, output_pred)
# 判別器の学習に使うLearning Rateを算出する関数を定義する
A_lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=4e-4,
decay_steps=20000,
decay_rate=3e-8)
# modelをコンパイルする
A_model.compile(loss='binary_crossentropy',
optimizer=RMSprop(learning_rate=A_lr_schedule),
metrics=['accuracy'])
# modelを表示する
A_model.summary()
######
### ラベル付きの画像データからラベルを除去し、画像フォーマットにする
######
def strip_labels_in_image(labeling_images):
return labeling_images[:,:,:,0:1]
######
### これ以降にGANを学習するプログラムを実装します
######
def train(real, g_model, d_model, a_model, category=NUM_OF_CATEGORYS, epochs=2000, batch=128, z_dim=Z_DEMENSIONS):
# 学習結果を出力するためのリスト
d_metrics = []
a_metrics = []
# Accuracyと損失を記録する
running_d_loss = 0
running_d_acc = 0
running_a_loss = 0
running_a_acc = 0
for epoch in range(epochs):
######
### 判別器の学習
imgs_real = []
# 本物の手描きイラストをbatchサイズ分集める
for cat_id in range(category):
imgs_real_in_cat = np.reshape(
real[cat_id][np.random.choice(real[cat_id].shape[0], batch, replace=False)],
(batch, 28, 28, 1 + category)
)
if cat_id == 0:
imgs_real = imgs_real_in_cat
else:
imgs_real = np.concatenate((imgs_real, imgs_real_in_cat), 0)
# 生成器の入力は乱数
input_noise = np.random.uniform(-1.0, 1.0, size=[batch, z_dim + category])
imgs_fake = g_model.predict(input_noise)
# 本物と偽物の画像をセットにする
x = np.concatenate((imgs_real, imgs_fake))
# 本物と偽物のラベルを作る(本物=1, 偽物=0)
y = np.zeros([(category + 1) * batch, 1 + category])
for cat_id in range(category):
y[batch * cat_id : batch * (cat_id+1), cat_id] = 1.0
y[batch * category:, category] = 1.0
# 判別器の学習を止めておく
d_model.trainable = True
# 判別器のパラメータを確認する
if epoch == 0:
d_model.summary()
# 判別器の学習を実行する
d_metrics.append(
d_model.train_on_batch(x, y)
)
# 損失は終端要素の[0]に格納されている
running_d_loss += d_metrics[-1][0]
# Accuracyは終端要素の[1]に格納されている
running_d_acc += d_metrics[-1][1]
######
### 生成器の学習
# 生成器の入力は乱数 + カテゴリ
# -->> 生成するカテゴリに1を立てる(One-Hot)
input_noise = np.random.uniform(-1.0, 1.0, size=[batch * category, z_dim + category])
input_noise[:batch * category, z_dim:] = 0.0
for cat_id in range(category):
input_noise[batch * cat_id : batch * (cat_id+1), z_dim + cat_id] = 1.0
# 本物の画像を識別できるように学習する
# -->> 本物と誤認した場合のラベルを作る
y = np.zeros([category * batch, 1 + category])
for cat_id in range(category):
y[batch * cat_id : batch * (cat_id+1), cat_id] = 1.0
# 判別器の学習を止めておく
d_model.trainable = False
# GANのパラメータを確認する
if epoch == 0:
a_model.summary()
# GANの学習を実行する
a_metrics.append(
a_model.train_on_batch(input_noise, y)
)
# 損失は終端要素の[0]に格納されている
running_a_loss += a_metrics[-1][0]
# Accuracyは終端要素の[1]に格納されている
running_a_acc += a_metrics[-1][1]
# 100epochs毎に進捗状況と生成画像を出力する
if (epoch + 1) % 100 == 0:
print('Epoch #{}'.format(epoch+1))
### 損失とAccuracyを表示する
log_msg = "%d: [D loss: %f, acc: %f]" % (epoch+1, running_d_loss / (epoch+1), running_d_acc / (epoch+1))
log_msg = "%s [A loss: %f, acc: %f]" % (log_msg, running_a_loss / (epoch+1), running_a_acc / (epoch+1))
print(log_msg)
### 学習で利用した画像を記録する
for cat_id in range(category):
images = strip_labels_in_image(imgs_real[cat_id * batch : (cat_id+1) * batch])
save_path = os.path.join(EPOCH_INPUT_IMAGE_DIR, EPOCH_INPUT_IMAGE_SAVEFIG.format(cat_id, epoch + 1))
image_plot(images, save_path)
### 生成器が生成した画像を記録する
for cat_id in range(category):
input_noise = np.random.uniform(-1.0, 1.0, size=[16, z_dim + category])
input_noise[:,z_dim:] = 0.0
input_noise[:,z_dim + cat_id] = 1.0
imgs_gen = G_model.predict(input_noise)
save_path = os.path.join(EPOCH_OUTPUT_IMAGE_DIR, EPOCH_OUTPUT_IMAGE_SAVEFIG.format(cat_id, epoch + 1))
image_plot(imgs_gen, save_path)
return a_metrics, d_metrics
a_metrics_complete, d_metrics_complete = train(real=data_with_category, g_model=G_model, d_model=D_model, a_model=A_model,
category=NUM_OF_CATEGORYS,
epochs=6000, batch=128, z_dim=Z_DEMENSIONS)
# 損失のグラフを生成する
column_a = [metric[0] for metric in a_metrics_complete]
column_d = [metric[0] for metric in d_metrics_complete]
plt.plot(column_a)
plt.plot(column_d)
plt.yscale('log')
plt.savefig(GRAPH_IMAGE_LOSS)
plt.clf()
plt.close()
# Accracyのグラフを生成する
column_a = [metric[1] for metric in a_metrics_complete]
column_d = [metric[1] for metric in d_metrics_complete]
plt.plot(column_a)
plt.plot(column_d)
plt.savefig(GRAPH_IMAGE_ACCURACY)
plt.clf()
plt.close()
quit()
記事は以上です。