以前の記事にて、PyTorchを利用し、PyTorch内蔵の学習済みresnet101を利用した物体検出を行いました。今回はPyTorchとTensorflowでどれくらい違うのだろう...ということを見ておきたく、同じ推論をTensorflow.keras上で試してみました。今回もMacBook Pro上のVisual Studio Codeを使って実装しています。 今回の実装は、PyTorchと違ってGPUにモデルや入力テンソルを転送する.to("mps")が無いため、本手順はMacBook Proで実行していますがUbuntu等の環境と手順やソースコードは同じになっていると思います。
参考記事
事前準備
事前準備としてMacBook ProにTensorflowの開発環境を作ります。
作業ディレクトリと仮想環境を作成する
まず作業を始めるにあたって、作業ディレクトリと仮想環境を作成し、tensorflow-deps、tensorflow-macos、tensorflow-metalをインストールしMacBook ProのGPUをTensorflowから使えるようにします。
# 作業ディレクトリを作成する
(base) $ pwd
(base) $ mkdir tf_resnet
(base) $ cd tf_resnet
# Python 3.10の仮想環境を作成し、ログインする
(base) $ conda create --prefix ./env python=3.8
(base) $ conda activate /Users/shino/tf_resnet/env
(env) $
# MacBook ProのGPUを利用できるTenserflowをインストールする
(env) $ conda install -c apple tensorflow-deps
(env) $ python -m pip install tensorflow-macos
(env) $ python -m pip install tensorflow-metal
# 科学技術系のパッケージをインストールする
(env) $ conda install jupyter pandas numpy matplotlib scikit-learn
# 画像を扱うOpenCVのパッケージをインストールする
(env) $ pip install opencv-python
Visual Studio Codeで作業ディレクトリを開く
Visual Studio Codeを起動して作業フォルダを開く
続いて、Homebrewなどを利用してインストールしたVisual Studio Codeを起動し【ファイル】-【フォルダを開く】から、先の手順で作成したフォルダを開きましょう。
$ brew --version
# Homebrew 4.4.6
$ brew install --cask visual-studio-code
開いたのち、ターミナルを開いてconda activate ./envを実行し仮想環境に入ります。そして【エクスプローラー(左側のバー)】-【新しいファイル】でtest_detect.pyを作成してください。これが推論を行うメインのソースコードになります。
Tensorflow.keras内蔵のResNetを扱う
kerasに内蔵されているモデルリストを参照する
kerasに内蔵されている学習済みのモデルは下記のコマンドにて参照することができます。今回はこの中からResNet50を利用しました。
$ python
>>> import tensorflow.keras.applications as app
>>> print(dir(app))
# ['ConvNeXtBase', 'ConvNeXtLarge', 'ConvNeXtSmall',
# 'ConvNeXtTiny', 'ConvNeXtXLarge', 'DenseNet121',
# 'DenseNet169', 'DenseNet201', 'EfficientNetB0',
# 'EfficientNetB1', 'EfficientNetB2', 'EfficientNetB3', 'EfficientNetB4',
# ...
# 'NASNetLarge', 'NASNetMobile', 'ResNet101', 'ResNet101V2', 'ResNet152',
# 'ResNet152V2', 'ResNet50', 'ResNet50V2', 'VGG16', 'VGG19', 'Xception',
# ...
# 'resnet_v2', 'vgg16', 'vgg19', 'xception']
OpenCVでWebカメラの画像を採取し、推論する
推論処理を実装する
Tensorflow.kerasで学習済みモデルを使うことはとても簡単です。tensorflow.keras.applications(上記)に含まれているモデルを選択した後にResNet50(weights='imagenet')のように何のデータセットを利用して学習したweightsを使うかを指定するだけです。そして、入力画像をモデルの入力テンソルに変換する処理はpreprocess_inputとして提供されており、モデルから出力されたテンソルを読める状態へと変換する処理はdecode_predictionsとして提供されています。 このあたりはPyTorchと比べると簡単に感じます。
撮影処理を実装する
撮影処理では、MacBook Pro内蔵カメラにcv2.VideoCapture()メソッドでアクセスし、撮影サイズとバッファ深度を指定します。撮影した画像はBGR形式となっていますので、OpenCVを使ってRGB形式へと変換します。モデルへの入力をバッチサイズ=1、縦横224pxのRGB形式とするため、np.expand_dims(img_attr1, axis=0)を行い、Shapeを([1, 224, 224, 3])とします。 PyTorchに含まれているresnetの場合は(1, 3, 224, 224)のため、同じResNetでもONNXなどモデルをエクスポートする際には注意が必要です。
推論を実行し、結果を得る
撮影した画像をpreprocess_inputにより入力テンソルへと変換し、model.predictを使って推論、出力テンソルpredictionsを取得します。出力テンソルには分類クラスそれぞれの確率が含まれており、。decode_predictionsを使うことにより、クラスの名前に加えて、指定した数の上位となっている推論結果を得ることができます。 このあたりはとても便利だと感じました。
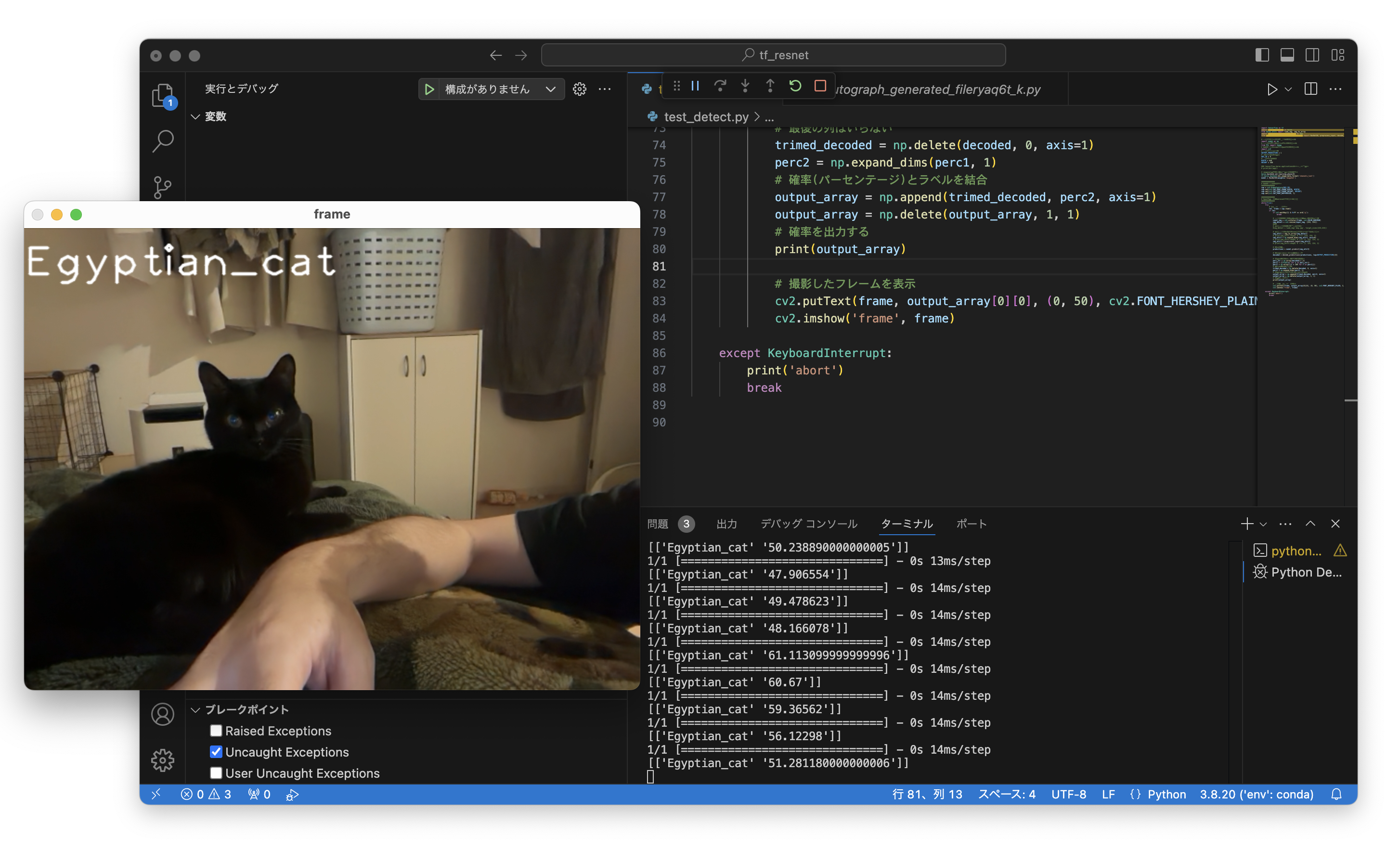
ResNetの出力テンソルに含まれている「確率」は文字列で格納されているため、floatに変換して、推論結果と結合、不要な列を削除して扱いやすいようにテンソルを作り直します。最後に確率が一定以上の場合にcv2.putTextメソッドを利用し出力画像に検出できたクラス名を書き込み、画面に表示すれば無事完了となります。
コード全文
import tensorflow as tf
import tensorflow.keras as keras
from keras.utils import load_img, img_to_array
import tensorflow.keras.applications as app
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input, decode_predictions
# 出力テンソルを扱うためにインポート
import numpy as np
# 画像を扱うライブラリPILをインポート
from PIL import Image
# Webカメラを制御するOpenCVをインポート
import cv2
# 出力するラベル数
OUTPUT_PREDICTION = 1
# 表示する確率の閾値
THRESHOLD = 30
# /dev/video0を指定
DEV_ID = 0
# 撮影するサイズ
WIDTH = 640
HEIGHT = 480
### tensorflow.keras.applicationsに含まれるモデル
# print(dir(app))
# imagenetで学習済みのモデルを取得する
keras.backend.set_learning_phase(0)
tf.keras.backend.set_image_data_format('channels_last')
model = ResNet50(weights='imagenet')
##############
# Webカメラに接続する
##############
cap = cv2.VideoCapture(DEV_ID)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, WIDTH)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, HEIGHT)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
##############
# OpenCVで撮影し、resnetテンソルに変換
##############
while(True):
try:
# 1フレーム撮影する
ret, frame = cap.read()
if ret:
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 画像をBGRからRGBの並びに変換し、中央を切り抜く
input_img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
img_detect = cv2.resize(input_img, (224, 224))
####
# 入力画像を取得(静止画の場合)
#img_detect = load_img('dog.jpg', target_size=(224,224))
# 入力画像をResNet50の入力テンソルの形に合わせる
img_attr1 = img_to_array(img_detect)
# print(img_attr1.shape) # -->> (224, 224, 3)
img_attr2 = np.expand_dims(img_attr1, axis=0)
# print(img_attr2.shape) # -->> (1, 224, 224, 3)
img_attr3 = preprocess_input(img_attr2)
# print(img_attr3.shape) # -->> (1, 224, 224, 3)
# 推論を実行
predictions = model.predict(img_attr3)
# 推論結果の上位1個のみ取り出す
decoded = decode_predictions(predictions, top=OUTPUT_PREDICTION)[0]
# 確率の列を取り出して100をかける
perc_str = np.array(decoded)[:,2]
perc1 = ([float(s) for s in perc_str])
perc1 = np.array(([f * 100 for f in perc1]))
# 最後の列はいらない
trimed_decoded = np.delete(decoded, 0, axis=1)
perc2 = np.expand_dims(perc1, 1)
# 確率(パーセンテージ)とラベルを結合
output_array = np.append(trimed_decoded, perc2, axis=1)
output_array = np.delete(output_array, 1, 1)
# 確率を出力する
print(output_array)
# 撮影したフレームを表示、確率が一定以上ならクラス名を出力する
if (float(output_array[0][1]) > THRESHOLD):
cv2.putText(frame, output_array[0][0], (0, 50), cv2.FONT_HERSHEY_PLAIN, 3, (255, 255, 255), 2, cv2.LINE_AA)
cv2.imshow('frame', frame)
except KeyboardInterrupt:
print('abort')
break
無事動作しました。まだまだPythonのnumpy周りに慣れていないため、出力テンソルの加工に手間取ってしまいました。このあたりは慣れていかないと...
ありがとうございました!
参考にさせていただきましたサイト