一番ラーメンが美味しい街はどこだろう...?
pythonの練習も兼ねて東京23区のラーメンスコアを可視化してみました。
作業フロー
- BeautifulSoupで、ラーメンデータベースから点数データをクローリング
- 取得データとGeoJSONデータを行政区分コードで紐付ける
- foliumによりコロプレスマップを描画
コロプレスマップとは
階級区分図(かいきゅうくぶんず、英: choropleth map)は、主題図の一種であり、国民所得や人口密度など統計数値に合わせて色調を塗り分けた地図である。地域ごとに数値を比較し可視化する際に利用する。
https://ja.wikipedia.org/wiki/階級区分図
1. データの取得
- ラーメンデータベースクローリング範囲

最初に、ラーメンの点数データはwebサイトをクローリングして取得します。
今回はラーメンデータベースを対象サイトとします。
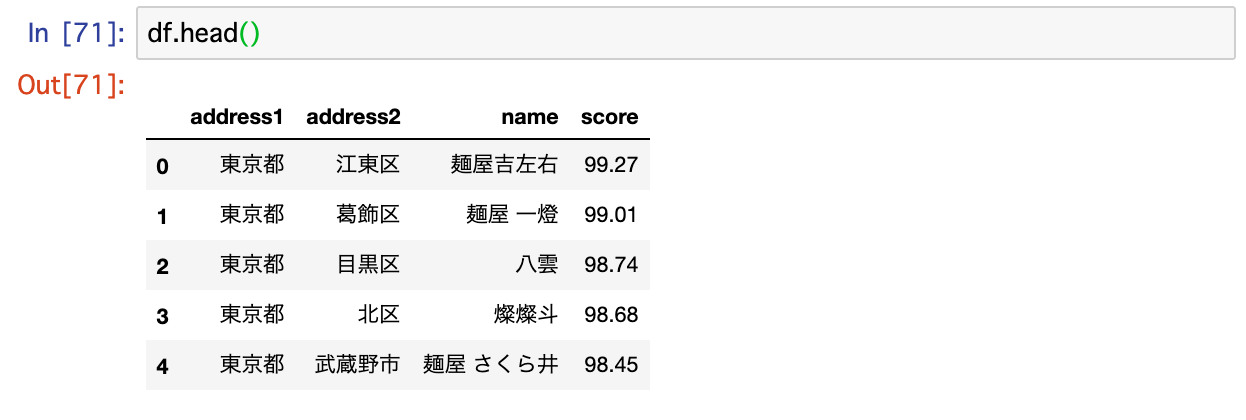
取り出す項目は「店名」「住所(〇〇区)」「点数」の3つです。
クローリングにはBeaturifulSoupを用います。
下記のコードで、東京都内の店舗情報をクローリングします。
sleep_timeを設定し、相手サーバに負荷がかからないよう気をつけましょう。
import requests
import pandas as pd
from bs4 import BeautifulSoup
from tqdm import tqdm
from time import sleep
def scrape_ramen(base_url, pageNum = 1, sleep_time = 5):
info_dict_array = []
for pi in tqdm(range(pageNum)): ## 1ページずつ各店舗の店名、点数、住所を取得する
url = base_url.format(pi+1)
response = requests.get(url, timeout=3.5)
if response.status_code == 404:
print('error:404')
break
soup = BeautifulSoup(response.text, 'html.parser')
shops = soup.find_all('ul', id='searched')[0].find_all('li', class_='border-box')
for shop in shops:
info_dict = {'name':None, 'score':None, 'address1':None, 'address2':None}
info_dict['name'] = shop.find('h4').text
info_dict['score'] = shop.find('div', class_='point-val').text
info_dict['address1'] = shop.find('div', class_='area').find_all('a')[0].text
info_dict['address2'] = shop.find('div', class_='area').find_all('a')[1].text
info_dict_array.append(info_dict)
sleep(sleep_time)
df = pd.DataFrame.from_dict(info_dict_array)
return df
if __name__ == '__main__':
base_url = 'https://hokkaido-ramendb.supleks.jp/search?page={}&state=tokyo'
df = scrape_ramen(base_url, pageNum=400, sleep_time=2)
df.to_csv('out/tokyo.csv')
取得結果はこのような形になります。
点数がない店舗を除いて、8000件前後のデータが取得できました。
2. GeoJsonへのマッピング
今回はfoliumというライブラリを使って地図の可視化を行います。
foliumではGeoJSONという形式のJSONファイルを渡してあげることで、簡単にコロプレスマップを描画することができます。
[追記] foliumのバージョンは最新のものではなぜかうまくいきません。この記事では0.8.3を用いています。
日本のGeoJSONデータはこちら(https://github.com/niiyz/JapanCityGeoJson/tree/master/geojson/) のレポジトリにてまとめて下さっているので、13/tokyo23.jsonというファイルをダウンロードします。このファイルでは、各区ごとに、行政区分コードというコードと、対応する座標情報が含まれています。
ラーメンデータベースから取得した住所の情報に、この行政区分コードをつけてあげます。
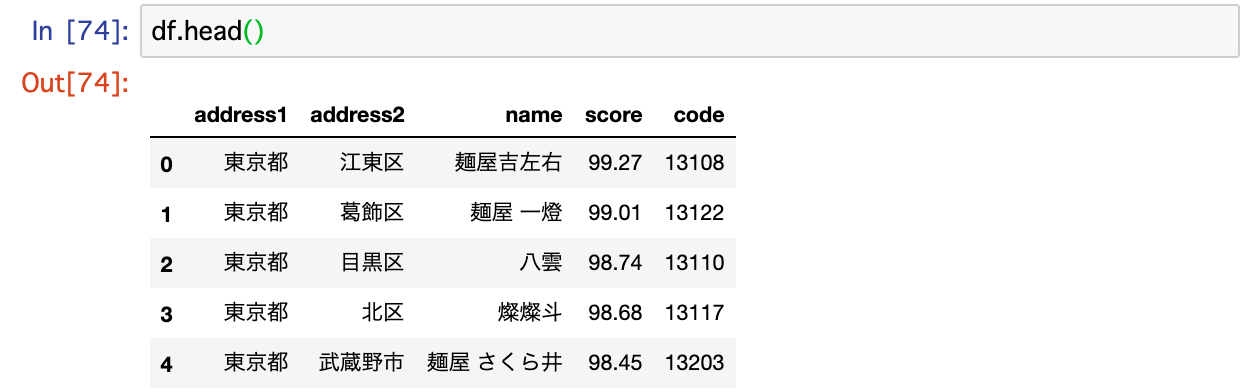
行政区分コードごとに点数の平均値を集計します。
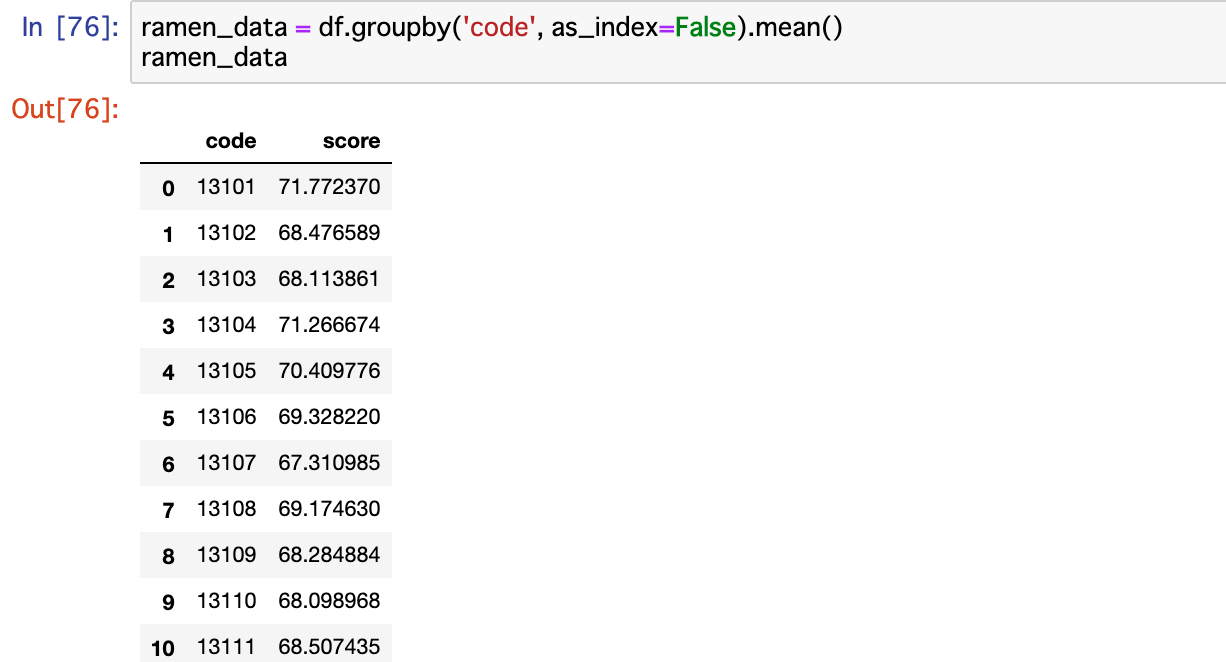
これでラーメンスコアを可視化する準備が整いました。
3. 東京23区コロプレスマップの描画
まず、ベースとなるマップオブジェクトを作成します。
from folium import Map, LayerControl, Choropleth
m = Map(location=[35.658581, 139.745433], # 中心を東京タワーに設定
tiles='cartodbpositron', # 地図のスタイルを設定
zoom_start = 11 # 初期ズーム率を設定
)
次に、GeoJSONファイルと点数データからChoroplethオブジェクトを作成し、mapに付加します。
Choropleth(geo_data='../data/tokyo/tokyo23.json', # GeoJSONファイル
name = 'choropleth', # map名
data = ramen_data, # 点数データ
columns=['code', 'score'], # 点数データのkey列とvalue列を指定
key_on='id', # GeoJSONファイル内のキーを指定
fill_opacity=0.7,
line_opacity=0.2,
line_color='red',
fill_color='BuPu').add_to(m)
LayerControl().add_to(m)
できました!
Jupyter Notebook内で表示することができます。拡大縮小なども快適にできます。
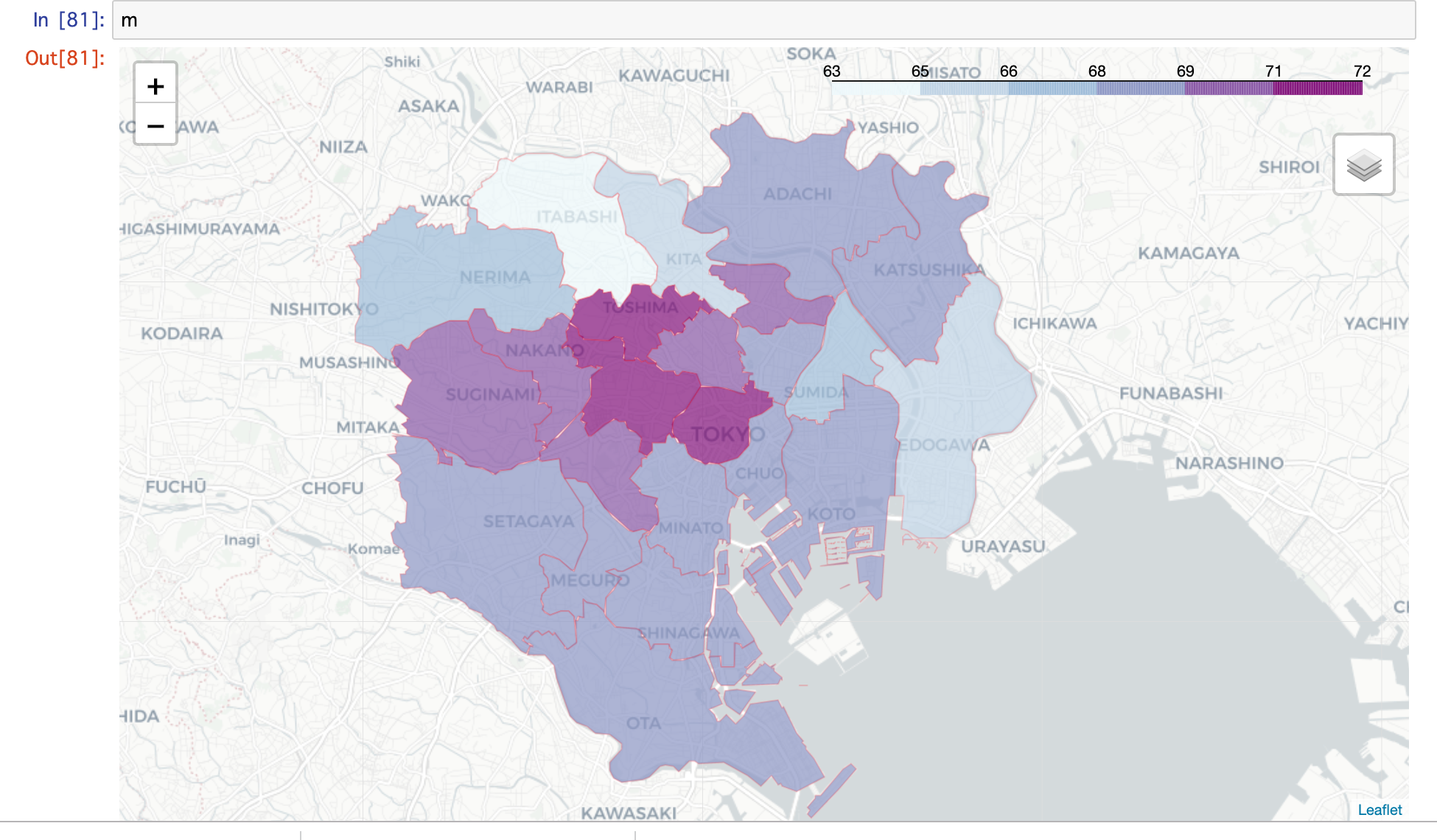
結果としては、千代田区、新宿区、豊島区が23区内トップ、次いで渋谷区、中野区、杉並区、文京区、荒川区といった感じでしょうか。ラーメンが好きな方はこの付近に住むといいかもしれませんね(適当)。
htmlファイルに出力もできます。
m.save('ramen_choropleth.html')
まとめ
foliumを使って、かなり簡単にコロプレスマップが作れました。