1.はじめに
本記事では、ECサイトを対象に、カテゴリ一覧の取得から商品情報の収集、次ページ遷移、csvへの出力までをSeleniumとPandasを使用して一通り実装しました。
スクレイピングにおける一連の処理を技術メモとしてまとめています。
2.実装内容の概要
■ 対象サイト
https://books.toscrape.com/index.html
■ 取得項目
- カテゴリ
- 本の画像URL
- タイトル
- 本の詳細URL
- 価格(ポンド)
- 価格(円)
- 在庫
■ 処理内容
- カテゴリ別で全商品を取得
- 次ページ遷移対応
- 取得データをcsv形式で保存
■ 出力イメージ

3.ソースコード
以下に、使用したソースコード全体を掲載します。
ソースコードの詳細については処理内容ごとに、3-1.~3-4.で説明します。
from webdriver_manager.chrome import ChromeDriverManager
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import pandas as pd
from time import sleep
# スクレイピング対象URL
url = "https://books.toscrape.com/index.html"
service = Service(ChromeDriverManager().install())
chrome = webdriver.Chrome(service = service)
# トップページにアクセス
chrome.get(url)
sleep(1)
# カテゴリ名リスト
category_names = []
# カテゴリURLリスト
category_urls = []
# データフレーム格納用変数
# カテゴリ
books_category = []
# 本の画像のURL
books_img_url = []
# 本のタイトル
books_title = []
# 本の詳細のURL
books_detail_url = []
# 本の値段(ポンド)
books_price_pond = []
# 本の値段(円)
books_price_en = []
# ポンド → 円 換算
rate = 210
# 本の在庫
books_stock = []
# サイドバーのカテゴリリンクを全て取得
books_category_css_tag = chrome.find_elements(by = By.CSS_SELECTOR, value = ".side_categories ul li ul li a")
# カテゴリ名とURLをそれぞれリストに格納
for book_category_css_tag in books_category_css_tag:
category_names.append(book_category_css_tag.text)
category_urls.append(book_category_css_tag.get_attribute("href"))
# 各カテゴリごとに出力するデータを取得
for category_name, category_url in zip(category_names, category_urls):
page_url = category_url
while True:
chrome.get(page_url)
sleep(1)
books_class_tag = chrome.find_elements(by = By.CLASS_NAME, value = "product_pod")
for book_class_tag in books_class_tag:
# 本の画像のURLを取得
book_a_tag = book_class_tag.find_element(by = By.TAG_NAME, value = "a")
books_img_url.append(book_a_tag.get_attribute("href"))
# 本のタイトルを取得
book_h3_tag = book_class_tag.find_element(by = By.CSS_SELECTOR, value = "h3 a")
books_title.append(book_h3_tag.get_attribute("title"))
# 本の詳細のURLを取得
book_img_tag = book_class_tag.find_element(by = By.TAG_NAME, value = "img")
books_detail_url.append(book_img_tag.get_attribute("src"))
# 本の値段(ポンド)を取得
book_price_tag = book_class_tag.find_element(by = By.CLASS_NAME, value = "price_color")
books_price_pond.append(book_price_tag.text)
# 本の値段(ポンド)から本の値段(円)を計算する
books_pond = float(book_price_tag.text.replace("£",""))
books_price_en.append(f"¥{round(books_pond * rate,2)}")
# 本の在庫を取得
book_stock_tag = book_class_tag.find_element(by = By.CLASS_NAME, value = "instock")
books_stock.append(book_stock_tag.text)
# カテゴリを格納
books_category.append(category_name)
try:
# nextボタンがある場合、リンクを取得しリンクに飛ぶ
next_button = chrome.find_element(By.CLASS_NAME, "next")
page_url = next_button.find_element(By.TAG_NAME, "a").get_attribute("href")
except:
break
# DataFrameに変換
books = {"カテゴリ": books_category,
"本の画像URL": books_img_url,
"タイトル": books_title,
"本の詳細URL": books_detail_url,
"価格(ポンド)": books_price_pond,
"価格(円)": books_price_en,
"在庫": books_stock
}
print(books)
df = pd.DataFrame(books)
df.to_csv("Books to Scrape.csv", index = False, encoding = "utf-8-sig")
# ブラウザを終了
chrome.quit()
■ 3-1. 全カテゴリを取得し、各カテゴリの名称とページサイトを取得
# サイドバーのカテゴリリンクを全て取得
books_category_css_tag = chrome.find_elements(by = By.CSS_SELECTOR, value = ".side_categories ul li ul li a")
# カテゴリ名とURLをそれぞれリストに格納
for book_category_css_tag in books_category_css_tag:
category_names.append(book_category_css_tag.text)
category_urls.append(book_category_css_tag.get_attribute("href"))
サイト左側のサイドバーに表示されている全てのカテゴリリンクを取得し、カテゴリ名とカテゴリページのURLをそれぞれリストに格納します。
find_elements と CSS セレクタを使用することで、カテゴリ一覧に該当する a タグのみを一括で取得しており、個別に要素を指定する必要がありません。
取得した要素からは、画面に表示されているカテゴリ名を .text で、リンク先のURLを .get_attribute("href") で取り出しています。これらを別々のリストに格納することで、後続の処理で zip() を用いてカテゴリ名とURLをセットで扱えるようにしています。
■ 3-2. 各カテゴリごとに出力するデータを取得
# 各カテゴリごとに出力するデータを取得
for category_name, category_url in zip(category_names, category_urls):
page_url = category_url
while True:
chrome.get(page_url)
sleep(1)
books_class_tag = chrome.find_elements(by = By.CLASS_NAME, value = "product_pod")
for book_class_tag in books_class_tag:
上記で取得したカテゴリ名とカテゴリURLを zip() でまとめてループし、各カテゴリページを順番にアクセスしながら商品情報を取得します。
カテゴリごとに処理を分けることで、「どのカテゴリの商品か」を明確にした状態でデータを収集できる構成になっています。
カテゴリページ内では、product_pod クラスを持つ要素を取得しています。このクラスは 1 冊分の商品情報をまとめた要素であるため、商品単位でループ処理を行うのに適しています。
各商品要素からは、画像URL、タイトル、詳細ページURL、価格、在庫情報をそれぞれ取得し、リストに追加しています。
■ 3-3. 次ページ遷移処理
try:
# nextボタンがある場合、リンクを取得しリンクに飛ぶ
next_button = chrome.find_element(By.CLASS_NAME, "next")
page_url = next_button.find_element(By.TAG_NAME, "a").get_attribute("href")
except:
break
商品一覧ページに「next」ボタンが存在するかどうかを判定します。
Seleniumでは、要素が存在しない場合に例外が発生するため、この挙動を利用して try / except 構文で処理を分岐しています。
「next」ボタンが存在する場合は、 a タグから次ページのURLを取得し、次のループでそのURLにアクセスします。一方で、「next」ボタンが存在しない場合は例外が発生するため、その時点で break を実行し、次のカテゴリのページのURLにアクセスします。
この処理により、ページ数が固定されていないカテゴリであっても、最終ページまで自動で遷移できます。
■ 3-4. 取得データをcsv形式で保存
# DataFrameに変換
books = {"カテゴリ": books_category,
"本の画像URL": books_img_url,
"タイトル": books_title,
"本の詳細URL": books_detail_url,
"価格(ポンド)": books_price_pond,
"価格(円)": books_price_en,
"在庫": books_stock
}
print(books)
df = pd.DataFrame(books)
df.to_csv("Books to Scrape.csv", index = False, encoding = "utf-8-sig")
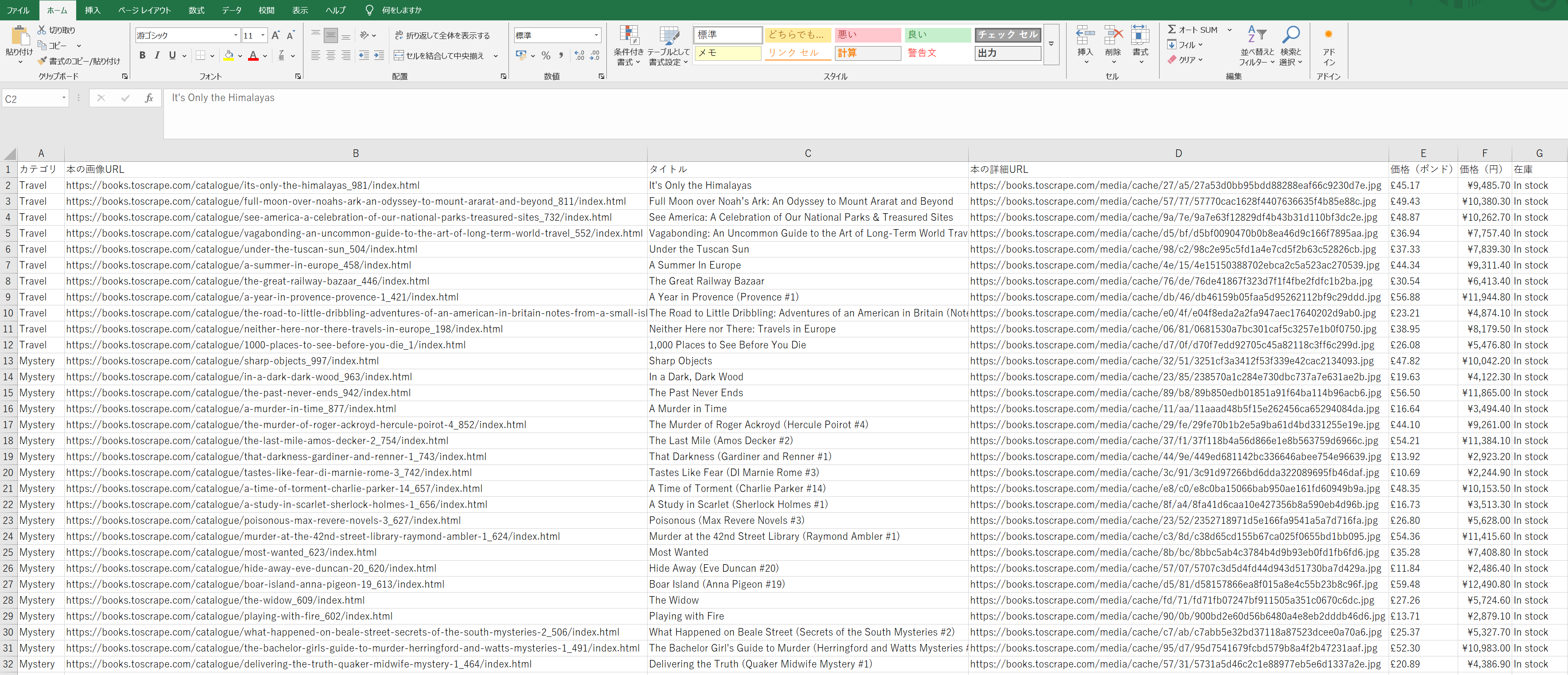
取得した各種データを辞書型にまとめ、DataFrame に変換しています。
各リストは同じ順序・同じ件数でデータが格納されているため、1 行が 1 商品に対応した表形式のデータになります。
DataFrame に変換した後は、to_csv() を使用して CSV ファイルとして保存しています。utf-8-sig を指定して Excel で開いた際の文字化けを防止しています。
4.まとめ
本記事では、ECサイトを対象としたスクレイピング処理について、カテゴリ取得、ページ遷移、データ収集、CSV出力までの一連の流れを整理しました。
サイト構造を確認しながら処理を分割することで、ページ数や商品数、カテゴリなどが変動する場合でも柔軟に対応できる構成を意識して実装しました。
今後も学習した内容について継続的にアウトプットしていきたいと思います。