背景
お客様の要件のため、ROKS上に構築されたアプリに対して、アクセス元のIPアドレスを制限することを検証しました。その際には、@hisato_imanishi(Hisato Imanishi)さんのご記事「Red Hat OpenShift on IBM Cloudでアクセス元IPアドレスを制限する」が大変参考になりました。
その後は、ROKSには IngressがDegradedになったとのエラーがで出ました。
当記事は、このエラーの解消方法、及び、検証時の注意点についてをご説明いたします。
前提環境
Red Hat OpenShift on IBM Cloud (OpenShiftバージョン:4.14.16_1555)(VPC Gen2)
検証環境なのでリソースが限られており、ROKS Clusterが2×ZoneでMulti-zoneの構成になります。
どのようなエラーか、について
このIngress Degradedエラーは、次のように確認できます。
先ず、ROKSのOverview画面でCriticalという状態が表示されています。
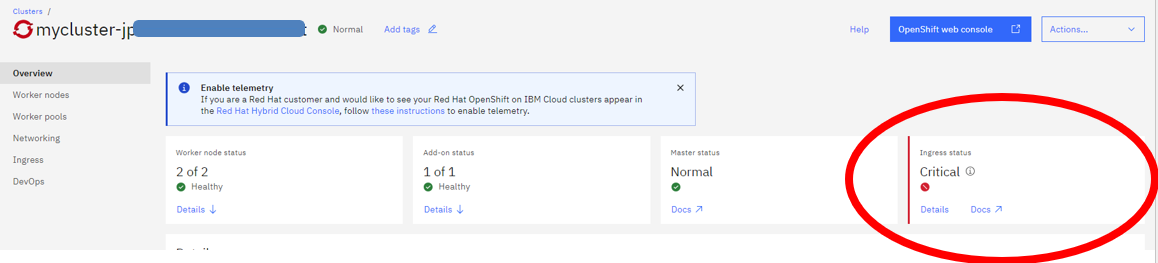
画面に出たDocsのアイコンをクリックすると、リンク先のページでこのエラーの調査方法が説明されます。いくつのコマンドが必要ですが、やはり重要なチェックが以下の通りだと思います。
$ ibmcloud ks ingress status-report get -c co5otmst0gkpvf3b5veg
$ oc get clusteroperator ingress
検証環境での出力のスクショを貼りつきます。
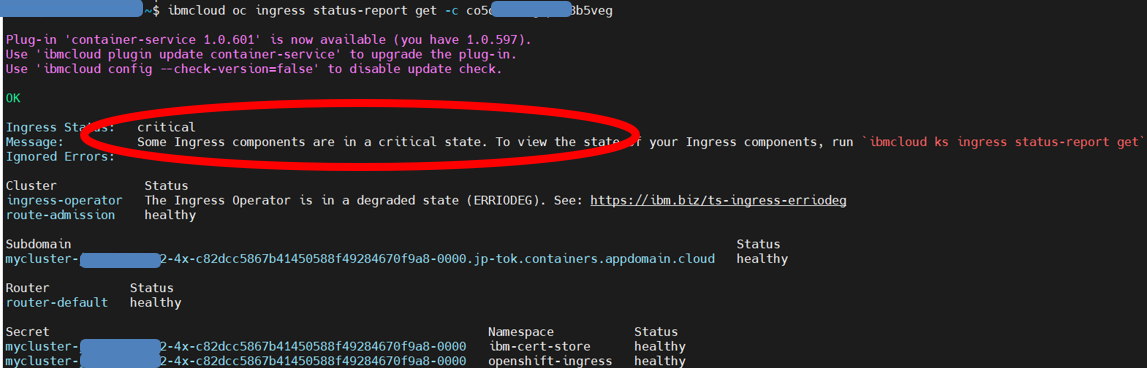

特にoc get clusteroperator ingressのところに、「CanaryChecksRepetitiveFailures: Canary route checks for the default ingress controller are failing」との情報を確認できました。
エラーの原因とは
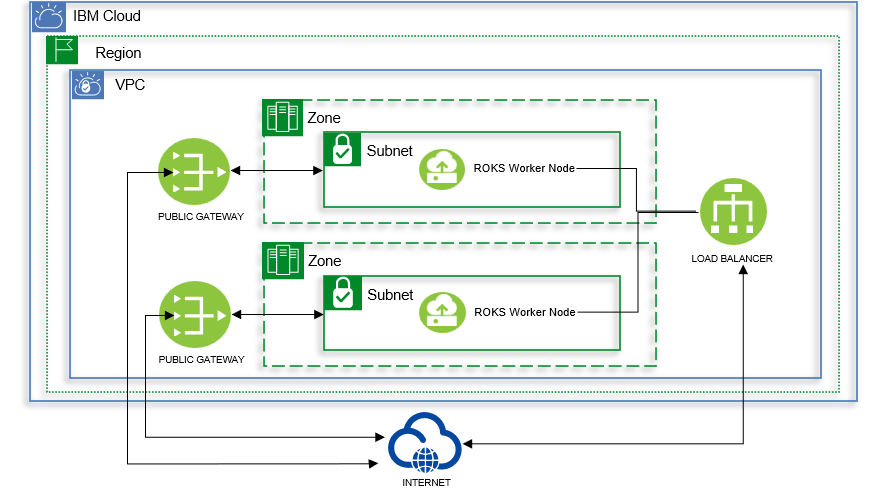
Openshift Clusterには、ingressが正常に稼働しているか、ingress-canaryというDaemonSetより定期的なチェックをしています。そのCanary TrafficがPodから発生し、VPCのPublic Gatewayを通過して、VPCのLoad Balancerのパブリック側に到着するというPathです。
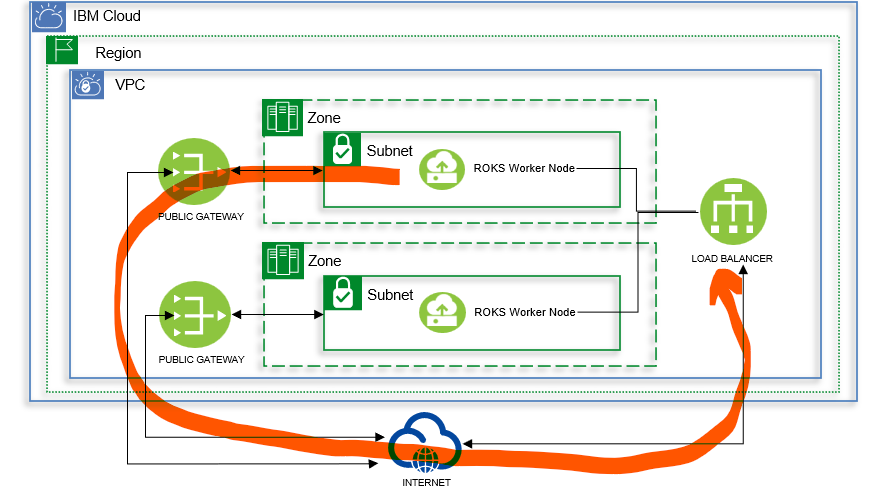
現在は、Load BalancerにSecurity Groupが関連付けられていますので、Public GatewayのPublic IPを許可しないと、Canary TrafficがCluster内に入ることができません。
oc get DaemonSet -n openshift-ingress-canary -o wide
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE CONTAINERS IMAGES SELECTOR
ingress-canary 2 2 2 2 2 kubernetes.io/os=linux 10d serve-healthcheck-canary quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:e8a5842e25ebfbff82540deddc6b592619efb656c93bbc2445ed6a4cbd2e92db ingresscanary.operator.openshift.io/daemonset-ingresscanary=canary_controller
エラーを解消するための手順
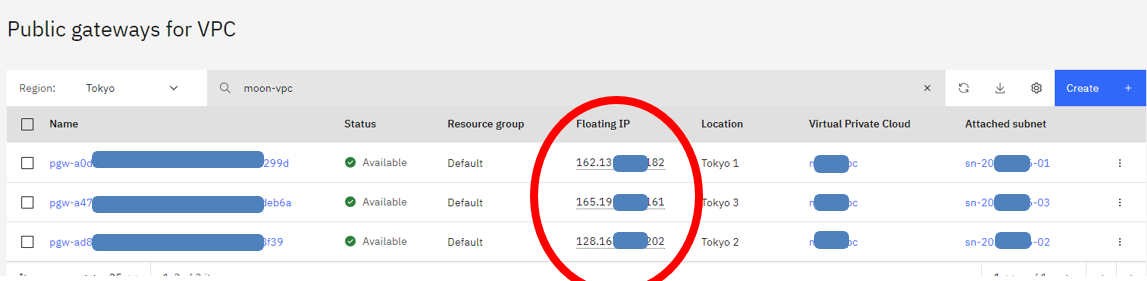
まずは、Public GatewayのPublic Gatewayを確認します。
Public Gatewayの一覧はこちらのURLより確認できます:https://cloud.ibm.com/vpc-ext/network/publicGateways
画面に見えるFloating IPは各Public GatewayのPublic IP.
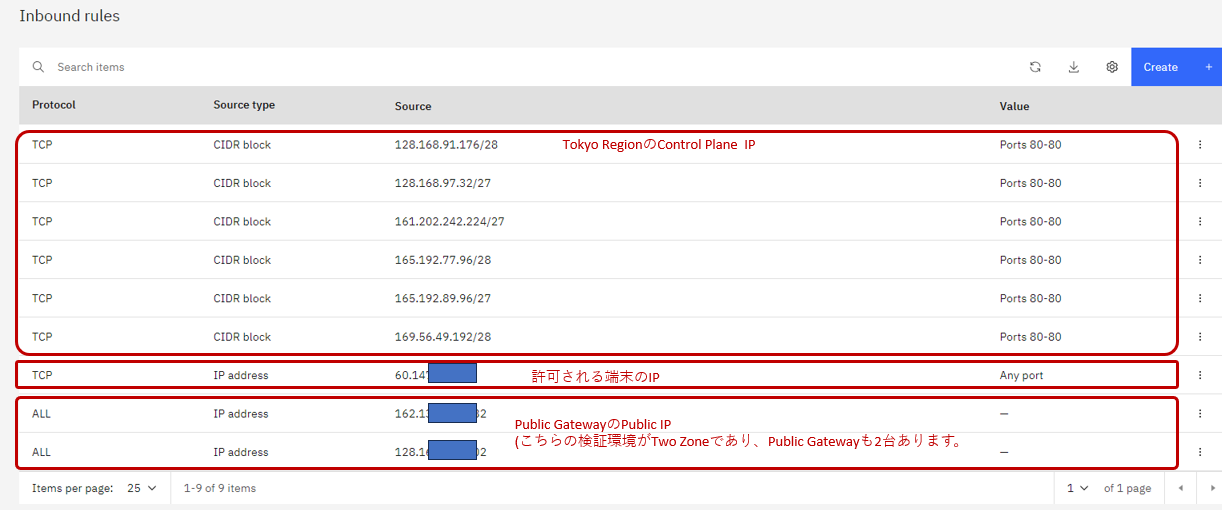
次に、Security GroupのInbound Ruleを追加します。
- Protocol: ALL
- Source Type: IP Address
- Enter the Public IP Address.
私の環境には2台のPublic Gatewayがあり、両方も追加必要です。
最後にできたSecurity GroupのInbound Ruleが以下の図のようになります。
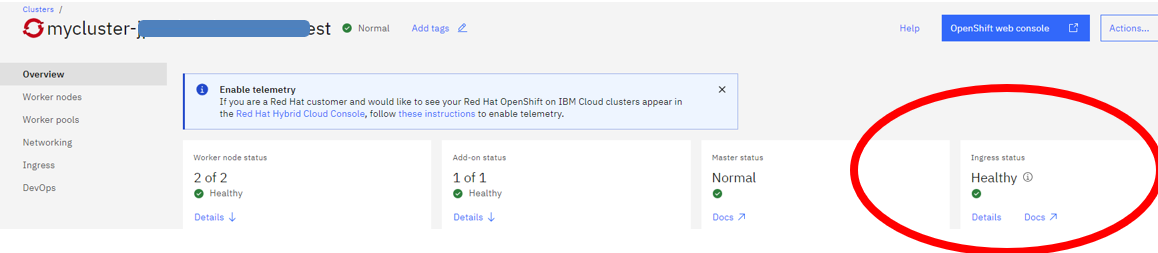
Ingressの状態を再度確認
上の手順が終わったら、10分ぐらいを待ってからIngressのStatusがHealthyに復旧しました。
改めてCMDも確認してみると、エラーメッセージなしで良い状態になりました。
~$ ibmcloud ks ingress status-report get -c co5otmst0gkpvf3b5veg
OK
Ingress Status: healthy
Message: All Ingress components are healthy.
Ignored Errors: -
Cluster Status
ingress-operator healthy
route-admission healthy
Subdomain Status
mycluster-jp-tok-1-bx2-4x-c82dcc5867b41450588f49284670f9a8-0000.jp-tok.containers.appdomain.cloud healthy
Router Status
router-default healthy
Secret Namespace Status
mycluster-jp-tok-1-bx2-4x-c82dcc5867b41450588f49284670f9a8-0000 openshift-ingress healthy
mycluster-jp-tok-1-bx2-4x-c82dcc5867b41450588f49284670f9a8-0000 ibm-cert-store healthy
~$ oc get clusteroperator ingress
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE
ingress 4.14.16 True False False 10d
最後に
この検証の中で、いくつか注意すべきことがあり、説明いたします。
- Multi-zoneの場合、全てのPublic GatewayのPublic IPに対して、Inbound Ruleを追加するのが必要です。
- Security Gatewayの設定を変更すると、有効になるまでには数分かかる場合もあります。
- Security GroupがIngress Degradedの原因であるかどうかを確認するため、自分を作ったWhitelist Security Groupを一旦切り離して、Default Security Gatewayに復旧するとのテスト方法もあります。ただし、その時に間違いDefault Security GatewayをPickupしないようにご注意。kube-との名付けられたSecurity Groupが正解であり、kube-とのSecurity Groupが別です。
以上、少しでもお役に立てれば幸いです。