前回までのあらすじ
鳴き牌の認識をクリア!
これでとりあえず雀魂の画面から、門前牌と鳴き牌を認識することができた。
今回やること
- リファクタリング
- ツモ牌の認識(位置調整)
- 牌の認識情報を画像で表示
- 捨て牌(河)の認識
でお送りします。
リファクタリング
牌の認識がだんだんと形になってきたのは良いのですが、まぁーソースコードが汚い!
趣味なのでそれでもいいんですが、開発を進める前に一度整理しておかないと手のつけられないスパゲッティになることは目に見えているので(前例あり)ここらで一回リファクタリングしておきたいと思います。
将来的に公開するならその方がいいよね!
- リファクタリングとは
プログラムの挙動は変えずに、プログラム内部の仕様を変更すること。
プログラムの可読性やメンテナンスの容易性などを上げるために行われる。
主な変更点は次の3点です!
- 変数名・関数名の変更(スネークケースへ)
- docstringを記載
- 処理の関数化
変数名・関数名の変更(スネークケースへ)
今までjavascriptを触ることが多かったので、変数名や関数名はキャメルケースを使うことが多かったのですが、pythonの公式はスネークケースの利用を推奨しているようです。
関数や変数の名前
関数の名前は小文字のみにすべきです。また、読みやすくするために、必要に応じて単語をアンダースコアで区切るべきです。
変数の名前についても、関数と同じ規約に従います。
pep8-ja(日本語版)より
docstringを記載
javadocみたいなもんですね。
プログラムの用途、引数、返り値などを記載します。
def recog_pai_image(pai_image, pai_list_image, show_matching_image = False):
"""
一枚の牌の画像の種類を認識する
Parameters
----------
pai_image : np.array
認識したい牌の画像イメージ
pai_list_image : np.array
牌全種類の画像イメージ
show_matching_image : bool, default = False
Trueにすると、templateがimageのどこにマッチしたかを示す画像を表示する
return : dictionary
'pai' : str
牌の認識結果。s1なら一索、p5aなら赤五筒など。
'acc' : float
テンプレートマッチングの一致率
"""
# 内容省略
return
docstringについては、下記の記事が非常に分かりやすかったです。
[Python]可読性を上げるための、docstringの書き方を学ぶ(NumPyスタイル)
https://qiita.com/simonritchie/items/49e0813508cad4876b5a
処理の関数化
これは今更ですね。いい感じになるように処理を分けました。
結果
def show_image(img):
def get_window_capture(window_name):
def template_matching(img, template, show_matching_image = False):
def crop_jantama_main_image(browser_image, template_image_list):
def crop_my_hand_image(jantama_main_image, file_name = None):
def crop_my_tsumo_image(jantama_main_image, file_name = None):
def recog_pai_image(pai_image, pai_list_image, show_matching_image = False):
def count_red_pixel(img):
def crop_and_perspective_nakihai_image(jantama_main_image):
def recog_one_nakihai_image(img, pai_list_image, direction, show_matching_image = False):
def recog_nakihai(jantama_main_image, pai_list_image, show_matching_image = False):
def recog_hand(jantama_main_image, pai_list_image):
if __name__ == '__main__':
# 雀魂のブラウザをキャプチャ(「雀魂」で検索すると牌譜屋などもヒットするためこのワード)
img = get_window_capture('麻雀を無料で気軽に')
if img is None:
sys.exit('雀魂の画面をキャプチャ出来ませんでした')
# 点棒と歯車の画像を読み込み
template_images = [cv2.imread('./templ_tenbo.PNG'), cv2.imread('./templ_gear.PNG')]
# 雀魂のメイン画面を切り取り
jantama_main_image = crop_jantama_main_image(img, template_images)
# 牌表画像を読み込み
pai_list_image = cv2.imread('./paiList.png')
# 自分の牌情報を認識
my_hand_info = recog_hand(jantama_main_image, pai_list_image)
print(my_hand_info)
随分見やすくなりました!
関数内容はここでは省略しますが、
crop_XXX系は画像の中から一部を切り抜く関数
recog_XXX系は牌の種類を認識する関数です
これで多少は人様に見せられるソースになったかしら。
ツモ牌の認識(位置調整)
今までツモ牌の認識位置は下記画像の位置で固定していたのですが、

鳴きが入ると、当然ながらツモ牌の位置はズレていきます。

なのでそれを修正します。
def crop_my_tsumo_image(jantama_main_image, menzen_info, file_name = None):
"""
雀魂本体の画像からツモ牌部分の画像を切り取る
Parameters
----------
jantama_main_image : np.array
雀魂のメイン画像イメージ
menzen_info : dictionary
面前牌の情報
'pai' : 認識した牌の種類
'acc' : 認識精度
file_name : str, default None
指定されている場合、ツモ牌の画像をその名前で保存する
return : np.array
ツモ牌部分の画像イメージ(cv2形式)
"""
for i in range(13):
if menzen_info[i]['pai'] == 'unknown' or menzen_info[i]['acc'] < 0.7:
break
my_tsumo_left = 222 + 95*i + 29
my_tsumo_right = 222 + 95*i + 29 + 93
my_tsumo_top = 887
my_tsumo_bottom = 1031
my_tsumo_image = jantama_main_image[my_tsumo_top:my_tsumo_bottom, my_tsumo_left:my_tsumo_right]
my_tsumo_image = cv2.resize(my_tsumo_image, dsize = (81,131))
if file_name:
cv2.imwrite(f'./{file_name}.png', my_tsumo_image)
return my_tsumo_image
面前牌の情報を与えて、そのの数に応じて切り取り位置をズラす仕様にしました。
牌の認識情報を画像で表示
完全に趣味ですが、面前牌、ツモ牌、鳴き牌の認識結果を見やすく表示する関数を作りました。
def output_pai_info_image(pai_info):
# 面前牌を画像化する
menzen_pai_image_list = []
for i in range(13):
# 牌の認識精度が下がるかunkwnonになったら終わり
if pai_info['menzen'][i]['pai'] == 'unknown' or pai_info['menzen'][i]['acc'] < 0.7:
menzen_pai_num = i
break
# 画像の読み込み
img = cv2.imread(f'./image/{pai_info["menzen"][i]["pai"]}.png')
# 画像に精度を挿入
img = put_text_in_image(img, f'{int(pai_info["menzen"][i]["acc"]*100)}%', place = 'bottom-right', size = 0.7, color = 'white', thickness = 2, margin = 10, bordering = {'color' : 'black', 'thickness' : 5})
# リストに追加
menzen_pai_image_list.append(img)
menzen_pai_image = cv2.hconcat(menzen_pai_image_list)
# ツモ牌画像読み込み
tsumo_pai_image = cv2.imread(f'./image/{pai_info["tsumo"]["pai"]}.png')
tsumo_pai_image = put_text_in_image(tsumo_pai_image, f'{int(pai_info["tsumo"]["acc"]*100)}%', place = 'bottom-right', size = 0.7, color = 'white', thickness = 2, margin = 10, bordering = {'color' : 'black', 'thickness' : 5})
# 鳴き牌を画像化する
naki_pai_image_list = []
nakihai_num = 0
for i in range(13-menzen_pai_num+4):
# 精度70%以下かつupper-horizonでは無い牌が来たら終わり
if pai_info['nakihai'][i]['acc'] < 0.7 and pai_info['nakihai'][i]['direction'] == 'upper-horizon' or pai_info['nakihai'][i]['pai'] == 'unknown':
break
# 精度70%以下かつupper-horizonの牌が来たらスキップ
if pai_info['nakihai'][i]['acc'] < 0.7 and pai_info['nakihai'][i]['direction'] != 'upper-horizon':
continue
# 画像の読み込み
img = cv2.imread(f'./image/{pai_info["nakihai"][i]["pai"]}.png')
# 牌の向きがhorizonかupper-horizonであれば画像を回転
if pai_info['nakihai'][i]['direction'] in ['horizon', 'upper-horizon']:
img = img[13:,:]
img = cv2.rotate(img, cv2.ROTATE_90_COUNTERCLOCKWISE)
# 画像に精度を挿入
img = put_text_in_image(img, f'{int(pai_info["nakihai"][i]["acc"]*100)}%', place = 'bottom-right', size = 0.7, color = 'white', thickness = 2, margin = 10, bordering = {'color' : 'black', 'thickness' : 5})
# 牌の向きがupper-horizonなら、一つ前の画像の上に連結させる
if pai_info['nakihai'][i]['direction'] == 'upper-horizon':
index = len(naki_pai_image_list)
naki_pai_image_list[index-1] = cv2.vconcat([img, naki_pai_image_list[index-1]])
else:
# リストに追加
naki_pai_image_list.append(img)
naki_pai_image = hconcat_black_fill(naki_pai_image_list[::-1])
blank = np.full((80, 20, 3), 0, dtype=np.uint8)
hand_image = hconcat_black_fill([menzen_pai_image, blank, tsumo_pai_image, blank, blank, blank, naki_pai_image])
return hand_image
この関数にこれまでの認識結果を入れると
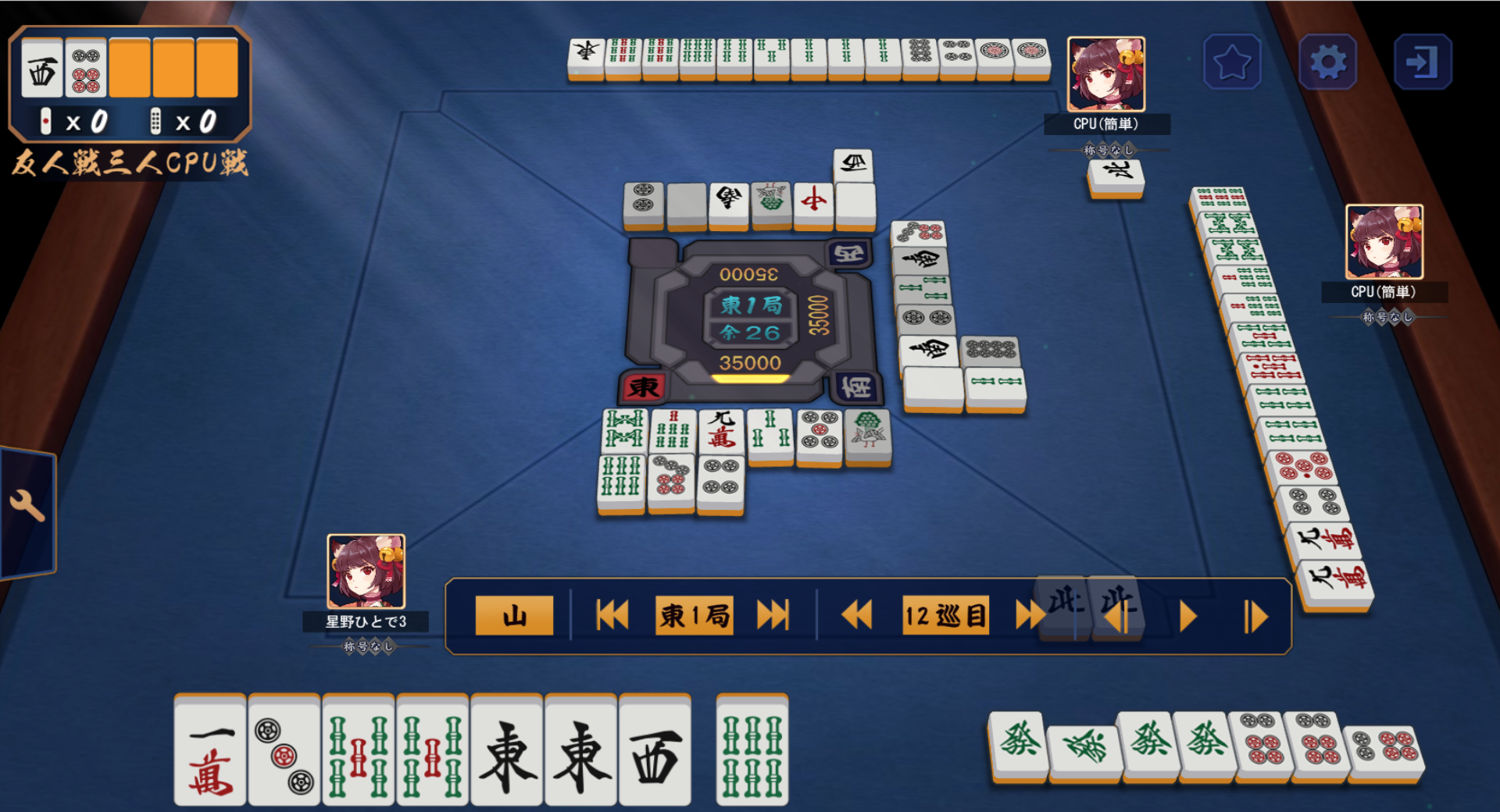

こんな感じの画像を生成できます。
どの牌が何%の精度で何の牌と認識できているかが一目で分かりますね!
ちなみに文字入れに関しては、長くなるので別の記事にまとめました!
【python-OpenCV】画像への文字入れの「位置指定」と「縁取り」を少しだけ便利にする関数作った
https://qiita.com/xenepic/items/06b30b3610823f178091
捨て牌(河)の認識
いよいよ牌認識も大詰めです。
まぁいうて河も自分の前に規則正しく並んでるわけでして、
多少台形補正する必要はありますが、6×3等分すればパリっと認識できそうです。
と思っていたのですが、、、

なんか牌の置き方雑じゃね!?
そうです、雀魂先生はリアリティを追求するため、捨て牌は微妙に揺らして置いていたのです。
いやーん
ここに来てまさかの真打ち登場。
まぁそこまで派手な揺れじゃないので、精度に問題がなければ良いのですが...
とりあえずやってみましょう。
def recog_sutehai(img, pai_list_image, show_matching_image = False):
"""
雀魂メイン画面から、捨て牌を認識する
Parameters
----------
jantama_main_image : np.array
雀魂メイン画面のイメージ(cv2形式)
pai_list_image : np.array
牌全種類の画像イメージ(cv2形式)
show_matching_image : bool, default = False
Trueにすると、templateがimageのどこにマッチしたかを示す画像を表示する
return : list - dictionary
'pai' : str
牌の種類
'acc' : float
認識精度
"""
# 切り出す捨て牌の大きさ
pai_h, pai_w = [57, 53]
# 右隣、下の牌との距離
left_diff = 13
bottom_diff = 5
# 捨て牌情報用リスト
sutehai_info_list = []
# 3×6+1に区切って認識する
for i in range(3):
for j in range(7):
if i < 2 and j == 6:
continue
# 捨て牌1枚部分を切り出し
sutehai_image = img[4 + (pai_h + bottom_diff)*i:4 + (pai_h + bottom_diff)*i + pai_h, 10 + (pai_w + left_diff)*j:10 + (pai_w + left_diff)*j + pai_w]
# テンプレートマッチングに合うようにリサイズ
sutehai_image = cv2.resize(sutehai_image, dsize = (66, 99))
# 牌の種類を認識
sutehai_info = recog_pai_image(sutehai_image, pai_list_image, show_matching_image = False)
# リストに追加
sutehai_info_list.append(sutehai_info)
return sutehai_info_list
やってることは単純です。
二重ループで順繰りに画像を切り抜いていって、それぞれパターンマッチングに掛けているだけ。
問題はその精度ですが...
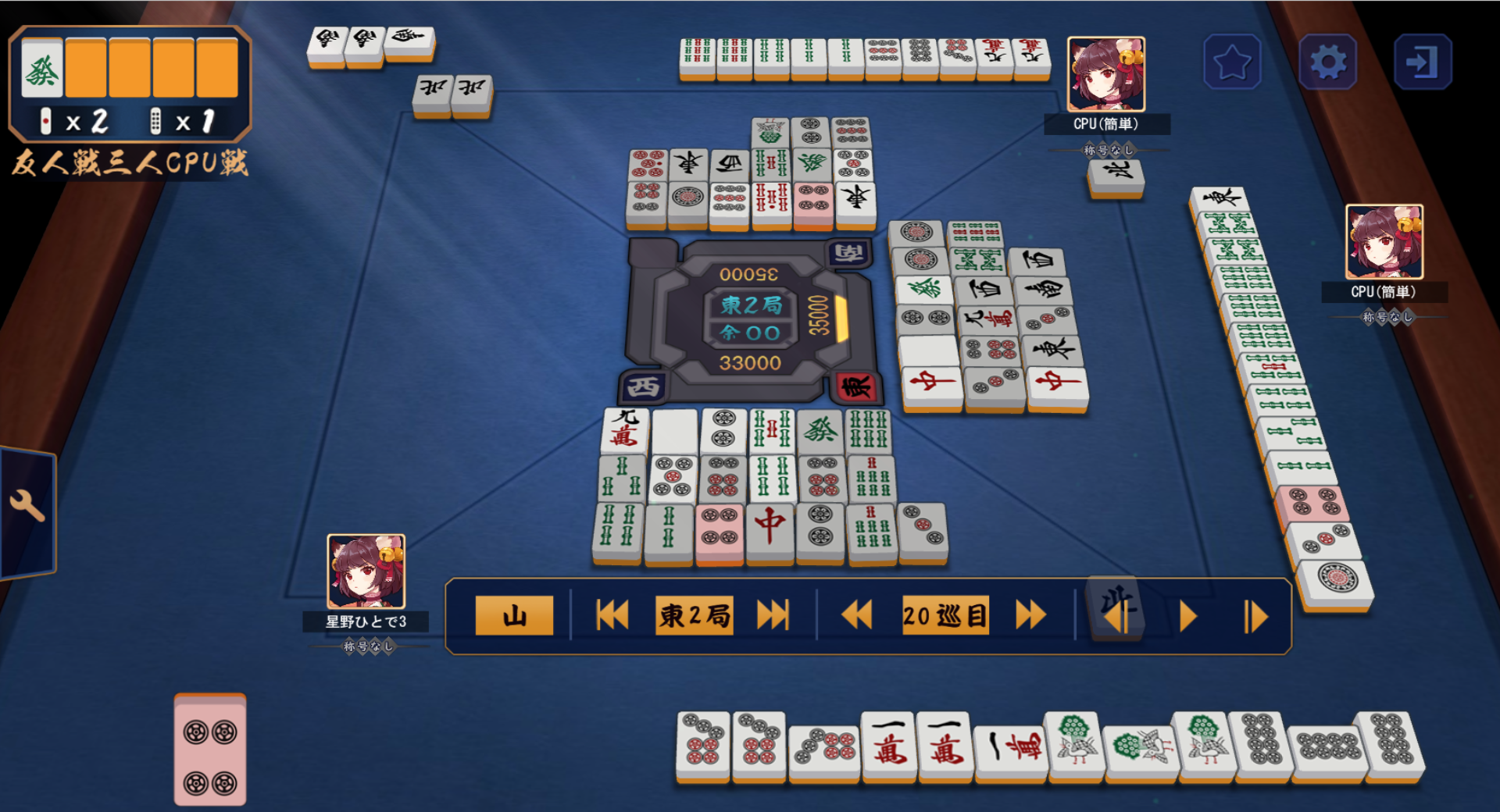


おぉー、惜しい!
右上の6sを9sと間違えてますね。
他の局でもやってみましょう。


またもや惜しい!
右上端の1pを中と勘違いしてます。
ん?6sと9sは分かるけど、1pと中?
もしかして右上の牌の認識がそもそもまずい??
と思ってもう一局試してみたところ、重大な見落としに気が付きました。


リーチ牌横向くやん!!!!
あと右上の3pは認識合ってますね。
代わりに上段の9pと1mが、それぞれ6pと2mになってますが。
他の牌も精度が70%かそれ以下のものも多いので、ちょっと精度としては物足りないんですよね。
泣き牌や捨て牌専用の牌表画像を作っても良いかも知れません。
ではまずリーチ牌への対応を...
といきたい所ですが、記事が長くなってしまったので、一旦次回に持越しです。
まとめ
今回は
- リファクタリング
- ツモ牌の認識(位置調整)
- 牌の認識情報を画像で表示
- 捨て牌(河)の認識
を行いました。
が、捨て牌認識の所で横向きリーチ牌の存在を忘れていたことに気付きました
というわけで次回は
- 捨て牌の認識(横向きリーチ牌への対応)
- 鳴き牌、捨て牌の認識精度向上
をやっていきたいと思います。
相手の牌の認識は、精度をもう少し上げてからですね!
それでは皆様、良い週末を!