皆さんこんにちは!(テンプレ)
SC(非公式) Advent Calendar 2019の二日目です。
アドベントカレンダーも参加3回目なので、もはや自己紹介とかいいですかね。
面倒くさいので去年の記事を見て頂ければと思います。
残念ながら仕事内容も去年とほぼ変わってません。
それでは早速本題に入っていきましょう。
やりたかったこと
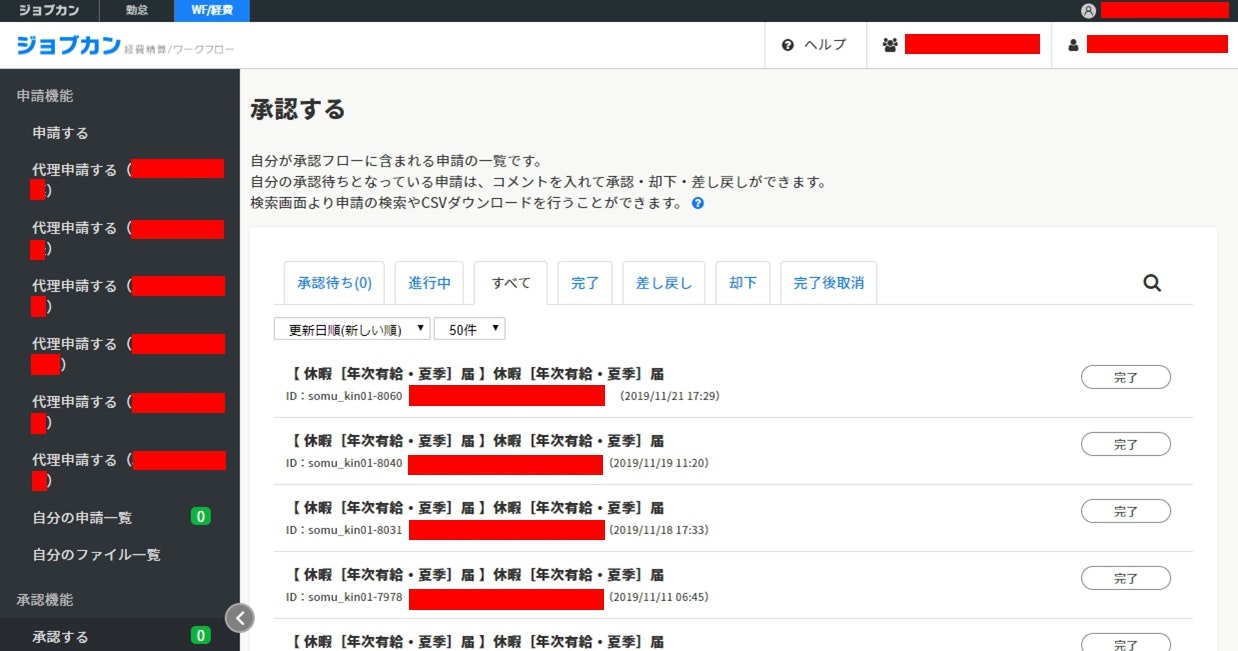
株式会社 Donutsさんが運営しているジョブカンワークフローという、勤怠管理システムがあるのですが、
弊社ではこちらのサービスを利用して、社員の休暇の申請/承認作業を行っています。
(以下、ジョブカンWFと表記します)
ただ、弊社の利用プランが貧弱な為か、もしくは独自にカスタマイズして貰った為か、
申請/承認作業に際しては何ら不自由はないものの、後から個々の申請データの詳細が把握し辛いという問題点があります。
(Grid形式の一覧画面が無い為、休暇申請データを一つ一つチェックしなければなりません...)
その為、月の勤怠締め作業などではマネージャーの方が管轄メンバの勤怠データのチェックの為に、結構面倒臭い思いをしています。
↓こんな感じです
ということで、今回は
ジョブカンWFの個々の申請の詳細情報を取得し、いい感じにファイル出力する
事を今回の作戦の第一ゴールと設定しました。
また、このゴールを達成する為に、何がしかでツールなりAPIなりを作り上げる訳ですが
自身の学習の為に Pythonでスクレイピングする 事を第2ゴールとしていました。
(ちなみにPythonは全くの初見状態でした)
「Python スクレイピング」でググった当初、
Beautiful SoupかSeleniumのどっちかを使ってやる感じね。ふむふむ。
Seleniumは前C#で使ったし、なるべくBeautiful Soupを使いたいなー
と考えていました。
が、タイトルバレしているように、試行錯誤した結果Beautiful SoupではなくSeleniumを使用しました。(後述)
注意事項
大体のスクレイピングの解説ページやブログ記事でも触れられていますが、
ウェブスクレイピングによっていたずらにサーバーに負荷をかけたりすると法律に抵触する場合があります。
スクレイピングを行う際はその辺を考慮し、コーディングしなければなりません。
また、スクレイピングの対象となるページ提供者の利用規約等をよく読んで、事前に規約違反にならないか確認する必要があります。
(といっても書いて無ければOKってものでもないですけどね。あくまで黒からグレーになるくらいだと私は思っています)
という事でジョブカンワークフローの利用規約を読みましたが、
スクレイピングする事で明記されている規約に触れる事はなさそうです。
リクエストを短時間内に多重に発行してしまうような留意点については
今回はSeleniumを使用し、画面操作(クリック)により表示された文字列データを取得していく為、
仮にサーバー不調による応答なし状態(ステータス:400エラー系、500エラー系)になっても、
画面内の項目が取得できなくなり、Selenium系のエラーとなってプログラムが落ちるだけなので
そこまで神経質になる必要はないでは、と考えています。
ちなみにQiitaを含むネット上に、ジョブカン系のスクレイピングの記事が散見されますが、
今のところ運営会社から通達を受けて問題になっているようなものは見当たりませんでした。
また、本ソース または その一部を利用したことによって生じたあらゆる問題について、
私は一切の責任を負いませんので、くれぐれも自己責任でお願い致します。
汎用的な条件が利かない箇所はゴリゴリ文字列情報を取得しているので、取得データが正しいレイアウトで出力されない場合もあります
準備
以下、開発に関係する環境情報です。
| 項目 | 使ったもの |
|---|---|
| OS | Windows8.1 Pro 64bit |
| メモリ | 8GB |
| Python | 3.8.0 |
| ブラウザ | GoogleChrome |
| IDE | VisualStudioCode |
| その他 | 折れない心、GABAを含んだ食品(ストレス緩和用) |
Pythonのインストール手順については特に詰む事もなかったので省きます。
使用したインストール資材はこちらです。
- chromedriver_win32.zip
⇒ChromeをSeleniumで扱う為のドライバ。Windowsは32bit用しかない模様。
- python-3.8.0-amd64-webinstall.exe
⇒Pythonの本体のウェブインストーラー。
あと私個人の知識準備として、Progateで適当にPythonの初学コースを履修しました。
やったこと
という事でPython3でSeleniumを使ってスクレイピングしました。
あくまでスクレイピングが目標だったので、exe化とかはしてません。
そのうちユーザー情報を設定ファイルから読み込ませ、ファイル出力の内容/形式を整えて社内に展開するつもりなので
記事公開後問題等々なければ、こちらのQiita記事でも追記して、GitHubにあげたよ!よ!と通知しようと思います。
ざっくりロジックの流れを説明すると
- ジョブカンWFにログイン
- 承認画面に遷移して、承認済みのものも含めて、全ての申請データを表示する(50件ずつ)
- 申請データ一件一件の情報を取得
(ページを跨いでデータが取れなくなるまで&検索対象日時を過ぎているデータに当たるまで) - 3で取得したデータをテキストファイルで出力
といった感じです。
見てお分かり頂けるように全く大した事はやっていません。
ただ、ジョブカンWFのページが動的にコンテンツが生成されるような作りになっている為、
すこぶるスクレイピングと相性が悪く、割と早い段階でBeautiful SoupからSeleniumに乗り換えました。
成果物
可能な限り英語(生のソース)だけで分かるように実装していますが、
暗黙知的な部分や今回の要件を達成する為の環境に応じた調整があまりにも多いのでコメントも多めになっています。
また私自身Python初学者ですので、誤ったコーディングスタイルや良くない実装をしている可能性が多分にあります。何卒ご容赦下さい![]()
以下、ソースです。(長いので折り畳んでいます)
from time import sleep
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.select import Select
from datetime import datetime
import codecs
# 処理関数 #####################################################################
def login():
# ユーザーID、パスワードを入力してログイン
user_id_box = driver.find_element_by_id("user_email")
user_id_box.send_keys("【ユーザーのメールアドレス】")
password_box = driver.find_element_by_id("user_password")
password_box.send_keys("【ユーザーのパスワード】")
password_box.submit()
wait_until_elements_loaded()
sleep(2)
def output_data_into_textfile(approval_data_list):
# 適当にファイル出力
f = open('test.txt','w',encoding="utf-8_sig")
for target_list in approval_data_list:
outputString = ""
for one_data in target_list:
outputString += one_data[:one_data.rfind("\n")].replace("\n",":")
f.write(outputString)
f.close()
print("ファイル出力完了@" + str(datetime.now()))
# Util系関数 ###################################################################
# 要素の存在チェック_再試行関数
def existcheck_target_element_by_id(target_element_id,retry_count=1,premise_element=None):
max_retry = 250 # 試行回数上限は100でも足りない場合があったので250くらいに
try:
element = driver.find_element_by_id(target_element_id).click()
wait_until_elements_loaded()
# 無事成功したら試行回数を出力
print("試行回数:" + str(retry_count))
except Exception:
# 試行回数上限を過ぎたら諦める
if(retry_count > max_retry): return
#前提となる要素が設定されていればそれをクリック
if(premise_element):
# 前提のやつもコケる可能性があるのでハンドリング
try:
premise_element.click()
except Exception:
# 前提要素のチェックも再試行する
sleep(0.1)
existcheck_target_element_by_id(premise_element.get_attribute("id"),1)
# 間を置いて再試行
sleep(0.1)
existcheck_target_element_by_id(target_element_id,retry_count + 1)
# ページロードを待つ関数
def wait_until_elements_loaded():
# ページ上のすべての要素が読み込まれるまで待機(15秒でタイムアウト判定)
WebDriverWait(driver, 15).until(EC.presence_of_all_elements_located)
# 要素をクリックしてちょっと待つ関数
def click_then_subtly_wait(target_object,wait_sec):
# .click()では上手く行かない時に座標を以て慎重にクリックする
action = webdriver.common.action_chains.ActionChains(driver)
action.move_to_element_with_offset(target_object, 1, 1)
action.click()
action.perform()
wait_until_elements_loaded()
if(wait_sec > 0): sleep(wait_sec)
#################################################################################
# driverの設定_exeのパスを指定
# ChromeWevDriverとインストールされているChromeのバージョンが違うと動作しないので気を付ける
options = Options()
options.add_argument('--headless') #ヘッドレス(=画面を出さない)のが嫌ならこの行をコメントアウト
driver = webdriver.Chrome(executable_path=r'.\chromedriver_win32\chromedriver.exe',options=options)
# ジョブカンWFのログイン画面に遷移
driver.get('https://id.jobcan.jp/users/sign_in?app_key=wf')
# ログイン
login()
# WFメイン画面⇒承認画面に遷移
approval_panel = driver.find_element_by_xpath("//a[contains(text(), '承認する')]")
click_then_subtly_wait(approval_panel, wait_sec=2)
# 承認画面の「すべて」パネル押下
all_data_panel = driver.find_element_by_xpath("//a[contains(text(), 'すべて')]")
click_then_subtly_wait(all_data_panel, wait_sec=2)
# 件数ドロップダウンで表示データ件数を最大に設定
display_data_num_list = driver.find_element_by_name("req_per_page")
Select(display_data_num_list).select_by_visible_text("50件")
wait_until_elements_loaded()
sleep(3)
# 最終出力用申請データリスト
approval_data_list = []
# 今期分のデータを取る為に今期を設定_データ取得ロジックの終了条件となる
current_term = datetime(year=datetime.now().year, month=4, day=1, hour=0)
# ループ脱出フラグ
is_break = False
# 数字のページこれ以上ないよフラグ
is_no_page_anymore = False
# コンソール出力用データカウント
data_count = 1
for page_count in range(1000):
# 申請データ毎にループしてデータを取得
target_approval_data_element = driver.find_elements_by_class_name("one-request")
for one_approval_data_element in target_approval_data_element:
# クリックして申請データを展開
# _Click時にエラーになる場合があるので強引にキャッチ(なぜかクリック自体はできているので続行)
try:
# _要素が重なっている為か、座標ベースのクリックだと違うところを押してしまうので、ここでは単純にclick
existcheck_target_element_by_id(one_approval_data_element.get_attribute("id"))
one_approval_data_element.click()
except Exception:
print("申請データクリックで何故かエラー")
# ヘッダとして出ている情報を取得申請者情報は別領域にあるので追加で取得
one_data_applyer = driver.find_element_by_xpath("//*[@id='" + one_approval_data_element.get_attribute("id") + "']/ng-include/div/ul").text
# 申請日が前期ならば処理終了
target_date = datetime.strptime(one_data_applyer[one_data_applyer.rfind("("):one_data_applyer.rfind(")")].replace('(','').replace(')',''),'%Y/%m/%d %H:%M') #ヘッダ情報の最後にある全角()
if(target_date < current_term) :
is_break = True
break
# 詳細データを取得_詳細情報の全ての文字列が取得できてしまうので、必要部分まで切り捨て
existcheck_target_element_by_id(one_approval_data_element.get_attribute("id") + "_content",retry_count=1,premise_element=one_approval_data_element)
one_data_raw_string = driver.find_element_by_id(one_approval_data_element.get_attribute("id") + "_content").text
one_data = one_data_raw_string[0:one_data_raw_string.find("\n承認状況")]
# 項目毎に文字列を追加
one_approval_details = []
crlf = "\r\n"
one_approval_details.append("========================================================================" + crlf) # 申請の区切りをわかりやすくする為のヘッダ
one_approval_details.append(one_data_applyer[one_data_applyer.find(" ")+1:one_data_applyer.find(")")+1] + crlf) #申請者(最初の空白から最初の半角括弧まで)
# ちゃんと取得出来た時のみ各値を設定
if(one_data):
one_approval_details.append(one_data[one_data.find("休暇種別"):one_data.find("申請種別")-1] + crlf) #休暇種別
# 取消の場合は項目が変わるので分ける
if("取消" in one_data[one_data.find("申請種別"):one_data.find("申請(取消)事由")-1]):
one_approval_details.append(one_data[one_data.find("申請種別"):one_data.find("取消日(自)")-1] + crlf) #申請種別
one_approval_details.append(one_data[one_data.find("取消日(自)"):one_data.find("取消日(至)")-1] + crlf) #取得日(自)
one_approval_details.append(one_data[one_data.find("取消日(至)"):one_data.find("申請(取消)事由")-1] + crlf) #取得日(至)
else:
one_approval_details.append(one_data[one_data.find("申請種別"):one_data.find("取得日(自)")-1] + crlf) #申請種別
one_approval_details.append(one_data[one_data.find("取得日(自)"):one_data.find("取得日(至)")-1] + crlf) #取得日(自)
one_approval_details.append(one_data[one_data.find("取得日(至)"):one_data.find("取得日数")-1] + crlf) #取得日(至)
one_approval_details.append(one_data[one_data.find("取得日数"):one_data.find("取得後残日数")-1] + crlf) #取得日数
one_approval_details.append(one_data[one_data.find("取得後残日数"):one_data.find("申請(取消)事由")-1] + crlf) #取得後残日数
one_approval_details.append(one_data[one_data.find("申請(取消)事由"):one_data.find("備考")-1] + crlf) #申請(取消)事由
one_approval_details.append(one_data[one_data.find("備考"):] + crlf) #備考
else:
one_approval_details.append("詳細情報を取得できませんでした。" + crlf)
# 一申請データをリストに入れる
approval_data_list.append(one_approval_details)
print(str(page_count+1) + "ページ_"+ str(data_count) + "データ目")
data_count += 1
# 大きなループも同条件で抜ける為にもっかいここで判定
if(is_break): break
# 次のページへ
# _Click時にエラーになる場合があるので強引にキャッチ(なぜかクリック自体はできているので続行)
try:
# 対象オブジェクトが画面外にあるとクリックできないらしいので、下までスクロールする
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
# 次のページへ_0始まり&次のページを考慮し、カウンタに+2
page_panel = driver.find_element_by_xpath("//a[text() = '" + str(page_count + 1 + 1) + "']/..")
click_then_subtly_wait(page_panel, wait_sec=0)
except Exception:
print("ページ遷移で何故かエラー")
# マジで何故かエラーになった時を考慮し、2回続けてページがなかったら「...」パネルで次の5ページ分を読み込む
if(is_no_page_anymore):
try:
# 対象オブジェクトが画面外にあるとクリックできないらしいので、下までスクロールする
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
# 次の5ページを読み込む
page_panel = driver.find_element_by_xpath("//a[text() = '...']/..")
click_then_subtly_wait(page_panel, wait_sec=0)
except Exception:
# 「...」パネルもないならマジでページがないので終了
break
is_no_page_anymore = True
# 適当にファイル出力
output_data_into_textfile(approval_data_list)
sleep(1)
driver.quit()
また、できあがるファイルは以下のようになります。
出力されるファイル(例) (長いので折り畳んでいます)
========================================================================
【社員番号】 【社員名】 (【所属組織】)
休暇種別:年次有給休
申請種別:取得
取得日(自):2019/11/22
取得日(至):2019/11/22
取得日数:1 日
取得後残日数:16 日
申請(取消)事由:休養の為
備考
========================================================================
【社員番号】 【社員名】 (【所属組織】)
休暇種別:年次有給休
申請種別:取消
取消日(自):2019/11/19
取消日(至):2019/11/19
申請(取消)事由:体調回復のため
備考
========================================================================
【社員番号】 【社員名】 (【所属組織】)
休暇種別:年次有給休
申請種別:取得
取得日(自):2019/11/19
取得日(至):2019/11/19
取得日数:1 日
取得後残日数:5 日
申請(取消)事由:体調不良のため
備考
========================================================================
【社員番号】 【社員名】 (【所属組織】)
詳細情報を項目を取得できませんでした。
========================================================================
【社員番号】 【社員名】 (【所属組織】)
休暇種別:年次有給休
申請種別:取得
取得日(自):2019/11/09
取得日(至):2019/11/09
取得日数:1 日
取得後残日数:6 日
申請(取消)事由:所用のため。
備考
========================================================================
【社員番号】 【社員名】 (【所属組織】)
休暇種別:年次有給休
申請種別:取得
取得日(自):2019/11/09
取得日(至):2019/11/09
取得日数:1 日
取得後残日数:6 日
申請(取消)事由:私用のため
備考
ハマったとこ
基本的にハマった箇所はソース上にコメントとして追記しているので、そこまで補足する事もないのですが
全体を通して とにかくSeleniumの機嫌に依る という事をお伝えしたいです。
そもそもSeleniumの前提として
ブラウザ上で画面の挙動を再現する = 画面描画ではネットワークの調子や実行環境のメモリリソース等に依存する
というようになっていますので、
- セレクタの記述は間違っていないのに「要素がない」って言われる!
- ソースは何処も変えていないのに、描画の状況によって「要素がない」って言われて落ちる!
とか日常茶飯事です。
ある程度「こういうもんなんだ」と諦めていないと、ストレスマッハで毛根か胃がやられます。
ちなみに私は以下のエラーを高速詠唱できるくらいには見ました。
Selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element
では気を取り直して、ポイントポイントで、ハマったとこを挙げていきたいと思います。
1. ヘッドレスモードのゴミプロセス
Pythonでの記述やスクレイピングに限らず、違うプログラムを呼び出すコードを書いたことがある人はお分かりかと思いますが、
Seleniumを起動すると対象ブラウザのプロセスが立ち上がります。
コードの終了、つまり driver.quit() によってプロセスがkillされる訳ですが、
途中でエラーが発生したりするとPCのメモリ上にゴミプロセスが残ります。
通常モードではウィンドウを伴って画面に表示されますので、抜け殻のようなウィンドウが出っ放しになる為分かりやすいのですが
ヘッドレスモードだと画面に出ない為、タスクマネージャなどでプロセスを気にかけないと
裏っ側にプロセスが残りまくってメモリが重い~なんてことになります。気を付けましょう。
開発作業中であれば、仮としてコードの始まりにtryして 最後らへんでExceptionをhandlingしてプロセスをkillしてあげるようにするとgoodだと思います。
2. 要素がクリックできなくて落ちる_「待ち」
先程の説明でも記述したように、Seleniumの画面描画の調子によってはコード自体が正しくても
no such element~エラーになって落ちます。
その為、「動かしていて落ちやすい挙動の部分はエラーハンドリングを仕込む」 「何かアクションを起こしたら、適宜待つ」 が基本の動きになります。
また、待つ際にはsleep()でも良いのですが、なるべく要素が描画されるまで待つ
WebDriverWait(driver, xx).until(xxx)
を使いましょう。
そちらの方が機能面でも最適ですし、トライアンドエラーで秒数を計測して設定するよりも体に優しいです。
ただやっかいなことに、WebDriverWait()も万能ではありません。この関数を走り終えてもまだ落ちる事があります。
WebDriverwaitじゃまだ足りないな、と感じたら素直にsleep()で秒数を指定して待った方が良いでしょう。
ちなみに本ソース上で各所で置かれているsleepは、私の環境での最適な値になります。
ですので、回線ビュンビュンのCPUツヨツヨな環境であればもうちょっと縮められると思います。たぶん。
3. 要素がクリックできなくて落ちる_「ハンドリング」
2.の「待ち」を行えばある程度解決できるのですが、「待ったところで一向に要素が出て来ない」ということも往々にしてあります。
そこで本ソースでは再帰的な関数を利用して、落ちやすい挙動をエラーハンドリングして
再試行するように実装しました。existcheck_target_element_by_id()がそれに当たります。
本当はExceptionで何でも拾うのではなくて
「Selenium.common.exceptions.NoSuchElementExceptionに限定する~」
といった実装の方が良いのですが、私の身をストレスから守る為にそのままにしました。
ゆるして。
4. 各種項目(Element)の指定
これはSeleniumやPythonの技術どうこうではなくて、
「ジョブカンWFの欲しいデータが、テンプレート部品を基に動的に生成される」
為に苦労しました。
ページ内の項目で一意となるようなidやclassがあてがわれている事が稀で、
開発者モードでページ上の要素を嘗め尽くしながら、トライアンドエラーで乗り切りました。
その為クラス指定やID指定、Xpath指定などがごちゃごちゃに使われていますが、
決して気まぐれで使っている訳ではありません。これが私の局所最適解なのです。
5. Window + Pythonでのファイル出力
調べたところ、よくあるハマり事項のようですが、Windowsの標準の文字コードと
Pythonの標準文字コードが異なる為、改行コードとか特殊文字に当たった時に
デフォルトのファイル作成関数では変換エラーが出て落ちてしまうことがありました。
幸い、下記の参考ページ様の方法でそのまま解決することができました。
終わりに
やったこと欄で書いたように、まだ各所に展開できるほど成果物が整えられていませんが、
うっかりアドベントカレンダーの2日目に登録してしまったので、この辺で区切りとしたいと思います。
(普通に自分自身が使いたい機能要件なので、そのうち整えます)
未知の言語へのチャレンジしたこと、そして久しぶりにゴリゴリソースを書いたので個人的にはとても楽しかったです。
あとジョブカンスクレイピングは弊社内でもちょこちょこやっている人がいるのですが、
猫も杓子も打刻データの取得ばっかりで辟易していたので「俺が本物のスクレイピングを見せてやるよ(挑発)」という気持ちで頑張りました。
とりあえずは形になったので、しばらくは心地よい疲労感と達成感を以て気持ちよく眠れそうです。
ではでは、(私の気が向いたら)次のアドベントカレンダー記事でお会いしましょう。
参考
勢いでゴリゴリ開発していたのでメモの取りこぼしがあるかもしれませんが、
今回の開発、またその最中に発生した問題の解決に際して参考にさせて頂いたページ様です。
Pythonで文字列を置換(replace, translate, re.sub, re.subn) | note.nkmk.me
【Python】SeleniumでHeadless Chromeを使おう - Qiita
seleniumにてButtonがクリックできない時の対処法 - Qiita
XPath で自分自身の親ノードを指定する方法 - 約束の地
Linuxで使える、エンコーディングと改行コードの変換コマンド - kakurasan
Pythonでファイルにデータを書き込んでいく方法 | CodeCampus
Python命名規則一覧 - Qiita
WindowsでCP932(Shift-JIS)エンコード以外のファイルを開くのに苦労した話 - Qiita
WindowsでPythonがLookupError: unknown encoding: cp65001 - Qiita
Pythonで文字列を検索(〜を含むか判定、位置取得、カウント) | note.nkmk.me
【Python】便利なsleepの使い方と実験
Python 文字を検索し値を返す(find/index) | ITSakura