やりたいこと
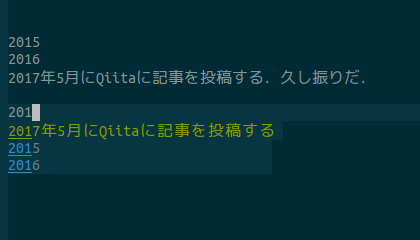
日本語文字と英数字(特に日付,人名)が混ざった文章を書いているときにcompany-dabbrevにより動的補完をすると,画像のように日本語部分まで補完候補に入れられてしまいます.
(ちょっと分かりにくいですが、201が現在入力している文字で、その下の3行が補完候補です)
これを下図のように、日本語文字が補完候補に含まれないように修正します。
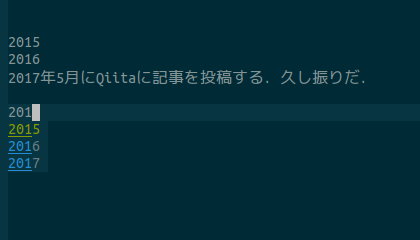
(候補の順番が変わっていますが,多分これは補完履歴の影響なので気にしないで下さい.)
結論
init.elなどの設定ファイルに以下のような記述をすれば,ASCII文字のみが補完候補に含まれるようになります.
init.el
(defun edit-category-table-for-company-dabbrev (&optional table)
(define-category ?s "word constituents for company-dabbrev" table)
(let ((i 0))
(while (< i 128)
(if (equal ?w (char-syntax i))
(modify-category-entry i ?s table)
(modify-category-entry i ?s table t))
(setq i (1+ i)))))
(edit-category-table-for-company-dabbrev)
;; (add-hook 'TeX-mode-hook 'edit-category-table-for-company-dabbrev) ; 下の追記参照
(setq company-dabbrev-char-regexp "\\cs")
(2017/10/30 追記)
edit-category-table-for-company-dabbrev をEmacs起動時に実行してしまうと,ドル記号$にもcategorysが設定されてしまうようです.TeXモードで使用する場合にはこれでは色々と不都合があるので,add-hookを用いてTeXモード開始後に実行します.(当然ですが,モード名については各々の環境に合わせて修正して下さい)
解説
変数 comapny-dabbrev-char-regexp は,company-dabbrevで補完対象となる文字(文字列ではないことに注意)を指定する正規表現.
デフォルト値は "\\sw" で,これは「単語構成文字」にマッチする.
問題なのは,アルファベットだけでなくひらがなや漢字もこれにマッチしてしまうこと.
というわけで,ASCII文字でかつ単語構成文字のみにマッチするようなcategoryを自作して,それを正規表現で指定しました1.
コメント
- company-dabbrev-code の方はちょっと仕組みが違うようで,今のところは上手くいっていませんが,
僕はこちらについては必要性を感じていないのでひとまず保留とします. - 別の方法や,より良い方法などがあれば,教えてもらえると嬉しいです.