課題
XGBoostは変数重要度を示してくれて便利ですが変数名が'f0'とか適当な値になってしまう!
そこで、なんとかdatafrmeのcolumn名のままに表示してくれる方法はないか!と探してみました。
※matplotlib周りの使い方で困ってるんでアドバイスください!
現状
まず、xgboostの変数重要度グラフは次のように表示します。
# clfはfit済みのモデル
xgb.plot_importance(clf)
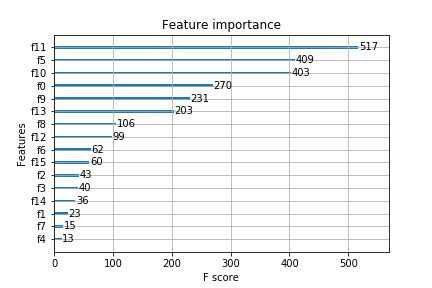
これで↑の画像の用に表示されるのですがはっきり言って
どれがどれだよ!!
ってかんじです。
そこで検索を開始したところ
Xgboostのto_graphvizメソッドで変数名を表示 @hand10ryo
2018年06月29日に投稿
(@hand10ryoさんありがとう!!) には
plot_importanceには変数名をkey、そのfeature_importanceをvalueにもつ辞書を渡せば
"f1"などと表示されてしまう問題は解決できた
と書いてありました。
なのですこし考えてみました。
回答(※簡潔なものも追加したので追記参照)
# dfは元データフレーム
# clfは訓練済みモデル
features =df.columns[df.any()]
fscore = clf.feature_importances_
plt.figure(figsize=(10,10))
plt.barh(features,fscore)
これで横軸グラフがだせます。
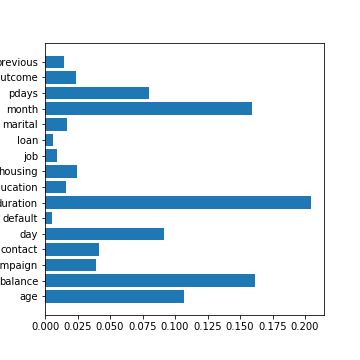
しかし、これだとグラフのソートがされていません。
そこで(features:fscore)の辞書をつくろうと次のようなものを考えました。
dict={}
for f,s in zip(features,fscore):
dict[f]=s
dict=sorted(dict.items(), key=lambda x: -x[1])
これでvalueでのソート済み辞書ができました。
しかし、辞書のままだとうまくplt.barh()に突っ込めなかったので……
features=[]
fscore=[]
for (k,v) in dict:
features[i]=k
fscore[i]=v
plt.barh(range(len(features)), fscore, tick_label=features, align="center")
plt.show()
これで下から大きい順に詰みあがるグラフができます。
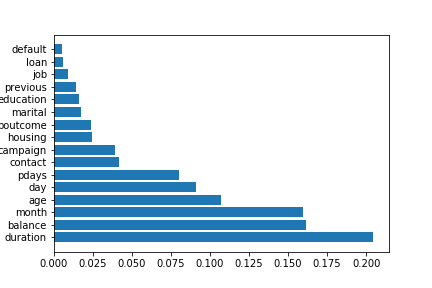
※matplotlibで降順にする方法が分かってないので知ってる方はコメントなどで教えてください!
@hand10ryoさんからのコメントにより改善(2018/09/12更新)
モデルのfitが終えた段階で次のような操作により、重要度の降順に表示してくれるようです。
@hand10ryoさん重ねてありがとうございます!
features =df.columns[df.any()]
mapper = {'f{0}'.format(i): v for i, v in enumerate(features)}
mapped = {mapper[k]: v for k, v in clf._Booster.get_fscore().items()}
xgb.plot_importance(mapped)