はじめに
この記事から得られる知識
この記事を読むことで,以下を知ることができます.
- PyTorchモデルの一部をC++/CUDAで書き直して並列化する方法
- GPUプログラミングの全体像(スレッド・ブロックの分割方法含む)
「CUDAを書く」ということはなんとなく難しそうと感じていましたが、PyTorchが提供するAPIのおかげで思った以上に簡単と感じましたので,実際に自分で実装をしてみて詰まってしまった点(次回記事)などまとめて少しでもこれからやる人の御役に立てれば幸いです.
PyTorchのC++/CUDA APIの公式チュートリアルと公式実装を参考にしていますが,そちらを読んだ上で説明が不足していると感じた部分を補えるような記事にしました.全体の見通しを良くするため,この記事では極めて簡単な並列計算(行列の足し算)を例に説明をしていきます.
この記事を読むにあたって、ある程度PyTorchとPyTorch C++ APIを知っているとより理解が捗ると思います.以下のリンクをご参考にしてください.
GPUプログラミングの基礎知識
基本用語
こちらの記事が大変わかりやすいので,あまりGPUに詳しくない方はまずはそちらをご参照ください.以下,この記事を読むにあたっては,最低限以下の単語を知る必要があります.
- ホスト:処理を呼び出す側.CPU
- デバイス:処理の依頼を受け取る側・GPU
- カーネル:デバイス上で行われる処理
- スレッド:処理を実行する最小単位
- ブロック:スレッドの集まり
- グリッド:ブロックの集まり
GPUプログラミングのイメージ
まずはGPUをつかった並列計算の仕組みのイメージを持ちましょう.
大雑把に言ってしまえば,GPUはCPUからカーネルと呼ばれる計算の処理をする依頼をうけ,GPUにある膨大な数のコアが依頼された計算を並列にし,その結果をCPUに返す(正確にはCPUはGPUの処理が完了するのを待たない)ことで並列計算を行います.
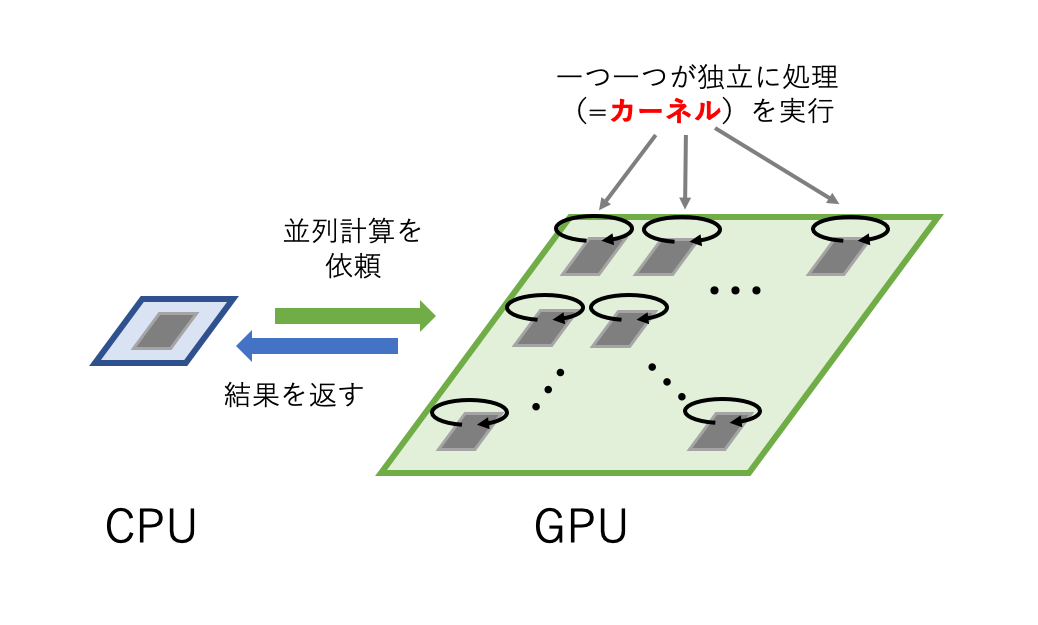
データの転送や待機などの面倒な処理はCUDAが提供するAPIが行ってくれますので,**実際にプログラマがコードするものはカーネルが主になります.**後述しますが,カーネルの関数をかくときにはコアの位置のような情報を含む変数を使用することができますので,その変数を使用することですべてのコアに対して適用可能な抽象的な処理を記述することができます.
PyTorch C++/CUDA APIで行列の足し算をする
行列の足し算は,2つの行列を同じ成分の要素ごとに足し算をするだけなので,並列計算が可能です.C++/CUDAで行列の足し算をGPUで行うモジュールmy_addをビルドし,Pythonからそのモジュールを呼び出し実行することを最終目標とします.
環境準備
PyTorchのC++版をこちらよりインストールしてください.今回はGPUが手元にあるという想定なので,computer platformでCUDAを選択します.
次に,gccのバージョンを適切なものにします.ターミナルで
gcc -v
としてバージョンを確認します.筆者のOSはUbuntu20.04LTSですが,Ubuntu20はgccの9系が標準となります.CUDAをコンパイルする際、gcc8系までしかサポートしていないとエラーが吐かれるかと思いますので,Ubuntu20ユーザーは以下を参考に8系のgccを用意するとよいでしょう.
CUDAファイルの作成
まずはCUDAファイルmy_add_kernel.cuというCUDAファイルを用意し,以下のように大きさが100x100テンソルA,Bを受け取って足し算の結果であるテンソルoutを返す関数my_add_cuda_forwardを記述します.この関数my_add_cuda_forwardはまだカーネルではなく,カーネルを起動するための関数になります.
# include <torch/extension.h>
# include <cuda.h>
# include <cuda_runtime.h>
# include <vector>
std::vector<torch::Tensor> my_add_cuda_forward(
torch::Tensor A,
torch::Tensor B
){
// 返り値のplaceholderを先に宣言しておく
torch::Tensor out = torch::zeros_like(A);
// blockとthreadの分割設定
int n_row = 100; // 行列の行数
int n_col = 100; // 行列の列数
const int threads = 1024; //これが最大値, number of threads per block
const dim3 blocks((n_col + threads - 1) / threads, n_row); // number of blocks per girid
// カーネルをGPUに依頼
AT_DISPATCH_FLOATING_TYPES(A.type(), "my_add_forward_cuda", ([&] {
my_add_cuda_forward_kernel<scalar_t><<<blocks, threads>>>(
A.packed_accessor<scalar_t, 2, torch::RestrictPtrTraits, size_t>(),
B.packed_accessor<scalar_t, 2, torch::RestrictPtrTraits, size_t>(),
out.packed_accessor<scalar_t, 2, torch::RestrictPtrTraits, size_t>()
);
}));
return {out};
}
基本的にPyTorch C++ APIと同じ記述ができます.
まず最初に返り値となるテンソルoutを生成しています.計算結果はこのテンソルoutに格納されていきます.以降はカーネルを起動していく部分になります.
使用するスレッド・ブロックの分割設定
n_rowを行列の行数(縦方向の大きさ),n_colを列数(横方向の大きさ)としました.続く部分では起動するスレッド, ブロックの設定に必要な変数を設定しています.
const int threads = 1024; //これが最大値, nubmer of threads per block
const dim3 blocks((n_col + threads - 1) / threads, n_row); // number of blocks per girid
ここでは一つのブロックを(x方向に)1024個のスレッドに分割し,さらにグリッドをx方向に(n_col + threads - 1)/threads,y方向にn_row個のblockに分割するという設定をしています.x方向の数の設定方法がややこしいですが,これはn_colが0のときは0を返し,1以上のときは「n_colの数のスレッドをカバーできる最小ブロック数」を返させるためです.
このようにthreadsとblocksを設定するのが最適というわけではありませんが,いわゆるテンソルの「バッチ方向」をブロックのy方向に対応させることで各カーネルが担当すべき行列の要素のインデックスが明快になる(後述)ため,無難な書き方と言えます.
カーネルの起動
次の以下の部分でCUDAカーネルに行ってほしい処理の依頼・実行が行われます.
AT_DISPATCH_FLOATING_TYPES(A.type(), "my_add_forward_cuda", ([&] {
my_add_cuda_forward_kernel<scalar_t><<<blocks, threads>>>(
A.packed_accessor<scalar_t, 2, torch::RestrictPtrTraits, size_t>(),
B.packed_accessor<scalar_t, 2, torch::RestrictPtrTraits, size_t>(),
out.packed_accessor<scalar_t, 2, torch::RestrictPtrTraits, size_t>()
);
}));
少しややこしく見えるので,以下で簡単に解説していきます.AT_DISPATCH_FLOATING_TYPESの引数には順番に扱うテンソルの型,関数名(エラーメッセージのため),ラムダ式を渡します.参考までにC++でのラムダ式は[キャプチャリスト](パラメータリスト){処理;}という形をとり、例えば2つの整数の和を返すラムダ式は
auto sum = [](int a, int b){return a + b;}
のように書くことができます.[&]というキャプチャ記法が指定されるとラムダ式の外にある変数を参照して(コピーではなく)ラムダ式の中で使用することができます.また、パラメータリストは省略することもできます.
そして,ラムダ式の中で呼ばれている関数my_add_cuda_forward_kernelがこれから定義していくカーネルになります.カーネルを呼ぶときには(関数名)<型エイリアス><<<(blockとthreadを設定する変数)>>>(引数)という特殊な形をとります.
引数にはテンソルオブジェクトそのものではなく,ポインタのように参照渡しで変数を渡す必要があります.普通にポインタを渡すのも可能なようですが,PyTorch APIが提供する.packed_accessorメソッドを使ってアクセッサーオブジェクトを渡してやることで,カーネル定義時によりテンソルが扱いやすくなります.アクセッサの<>の中の数字はテンソルの次元です.
カーネルの定義
以下はカーネルの定義部分です.カーネルはtemplate関数を用いて定義します.__global__修飾子を関数の型の前につける必要がありますが,これはCUDA特有のもので,この関数がカーネルでありデバイスとホスト上の両方で実行される関数であることを示しています.また,カーネルでは基本的にポインタ操作をするため返り値がなく,故にvoid型となります.引数としてアクセッサオブジェクトを受け取るので,以下のようにして引数の型宣言をしましょう.
template <typename scalar_t>
__global__ void my_add_cuda_forward_kernel(
const torch::PackedTensorAccessor<scalar_t, 2, torch::RestrictPtrTraits, size_t> A,
const torch::PackedTensorAccessor<scalar_t, 2, torch::RestrictPtrTraits, size_t> B,
torch::PackedTensorAccessor<scalar_t, 2, torch::RestrictPtrTraits, size_t> out
){
const int n = blockIdx.y; // y方向インデックス
const int c = blockIdx.x * blockDim.x + threadIdx.x; // x方向インデックス
if (c < A.size(1)){
out[n][c] = A[n][c] + B[n][c];
}
}
前述の通り,カーネル(正確には__global__,__device__がつく関数)は以下の変数が自動定義されます.
| 型 変数名 | 意味 |
|---|---|
dim3 gridDim |
グリッドがそれぞれの方向に何個のブロックに分割されているか |
dim3 blockDim |
ブロックがそれぞれの方向に何個のスレッドに分割されているか |
dim3 blockIdx |
グリッド内のブロックのインデックス |
dim3 threadIdx |
ブロック内のスレッドのインデックス |
これらの変数を使うことで,各スレッドのGPU内での位置のようなものを以下のように分かりやすい形で取得することができます.
const int n = blockIdx.y; // y方向インデックス
const int c = blockIdx.x * blockDim.x + threadIdx.x; // x方向インデックス
スレッド位置の計算方法が納得できない,という方はGPUが以下のような構造をしているというイメージを持つと分かりやすいです.こちらの図は実際のGPUのアーキテクチャからはかけ離れた(こんな単純じゃない)ものですが,今回のようなブロック・スレッド分割方法を指定しておけば,プログラマーからはこのようなイメージでthreadの位置を捉えることができます.

実はスレッドは3次元方向に分割可能ですが,今回は1024とだけ指定したので定義時に(x,y,z)=(1024, 1, 1)と分割されました.よって,各ブロックはx方向に多数のスレッドに分割されていると思えばよく,X方向の位置をblockIdx.x * blockDim.x + threadIdx.xと表すことができます.この表現方法はよく使われるので,とりあえずx位置をこれで計算しておく,くらいの気持ちでいると良いでしょう.また,y方向には単純にブロックのy方向のインデックスを返せばいいことが上の図より分かります.
ここで各スレッドは行列の[n, c]成分の足し算のみを行えばよいので,以下のように記述します.
if (c < A.size(1)){
out[n][c] = A[n][c] + B[n][c];
}
if文によって,x位置が行列の横方向のサイズより大きいスレッドが処理を行わないようにしています.以上が行列の各成分の足し算を並列に行うカーネルの定義方法になります.
Backward関数の定義とC++ファイルの作成
以上まででCUDAのPyTorch APIを使った基本的なカーネルの書き方について解説しました.あとは以下をすることでPyTorchから呼び出せるモジュールを作成することができます.
- CUDAファイル
my_add_kernel.cuにbackward関数も定義する - C++ファイル
my_add.cppを作成し,C++からCUDAで定義した関数を呼びだす - Pythonファイル
setup.pyを作成し,実行してPythonにC++/CUDAで作成したモジュールをバインドする
基本的にはお決まりの記述をするだけなので,残りはファイル全体と簡単な解説をつけるのみとします.参考リンクも貼りましたので,不明な点はリンク先を参照してもらればと思います.
以下のように3つのファイル全てを同じディレクトリmy_add上にファイルを置きます.
./my_add
├── my_add.cpp
├── my_add_kernel.cu
└── setup.py
CUDAファイルmy_add_kernel.cuの全体
行列の足し算のbackward用の関数my_add_cuda_backwardを用意します.行列の足し算A + B = outにおいて勾配計算時,AとBの勾配は共にoutの勾配に一致します.backward関数の定義をしたことがない,そもそも自動微分の仕組みが分からないという方は,PyTorchでの自動微分の解説をしている以下の記事を参照してください.
# include <torch/extension.h>
# include <cuda.h>
# include <cuda_runtime.h>
# include <vector>
template <typename scalar_t>
__global__ void my_add_cuda_forward_kernel(
const torch::PackedTensorAccessor<scalar_t, 2, torch::RestrictPtrTraits, size_t> A,
const torch::PackedTensorAccessor<scalar_t, 2, torch::RestrictPtrTraits, size_t> B,
torch::PackedTensorAccessor<scalar_t, 2, torch::RestrictPtrTraits, size_t> out
){
//batch index
const int n = blockIdx.y;
//column index
const int c = blockIdx.x * blockDim.x + threadIdx.x;
if (c < A.size(1)){
out[n][c] = A[n][c] + B[n][c];
}
}
/************************************
FORWARD関数、BACKWARD関数を書く
*************************************/
std::vector<torch::Tensor> my_add_cuda_forward(
torch::Tensor A,
torch::Tensor B
){
// 返り値のplaceholderを先に宣言しておく
torch::Tensor out = torch::zeros_like(A);
// blockとthreadの分割設定
int n_row = 100;
int n_col = 100;
const int threads = 1024; //これが最大値, nubmer of threads per block
const dim3 blocks((n_col + threads - 1) / threads, n_row); // number of blocks per girid
// カーネルをGPUに依頼
AT_DISPATCH_FLOATING_TYPES(A.type(), "my_add_forward_cuda", ([&] {
my_add_cuda_forward_kernel<scalar_t><<<blocks, threads>>>(
A.packed_accessor<scalar_t, 2, torch::RestrictPtrTraits, size_t>(),
B.packed_accessor<scalar_t, 2, torch::RestrictPtrTraits, size_t>(),
out.packed_accessor<scalar_t, 2, torch::RestrictPtrTraits, size_t>()
);
}));
return {out};
}
std::vector<torch::Tensor> my_add_cuda_backward(
torch::Tensor grad_out
){
// grad_A, grad_Bともにgrad_outに一致する
return {grad_out, grad_out};
}
C++ファイルmy_add.cppの全体
C++ファイルはPythonとCUDAをつなぐような役割をし,CUDA関数を呼び込んだC++関数をビルドして生成したモジュールをPythonから呼ぶといった流れになります.このC++関数をビルドしてPythonのPyTorchモデルでよびこむ方法はPyTochカスタムC++エクステンションと呼ばれます.
ここではC++ファイルの書き方の詳細については触れませんが,C++エクステンションの使用方法が頭に入っているとここでの各関数の意味がより分かると思うので,本記事冒頭で紹介したC++エクステンションに関するリンクも是非参考にしてください.
# include <torch/extension.h>
# include <iostream>
# include <vector>
// テンソルをチェックするためのマクロを定義
# define CHECK_CUDA(x) TORCH_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
# define CHECK_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
# define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
/***************************
CUDAの関数の名前だけ宣言しておく
****************************/
std::vector<torch::Tensor> my_add_cuda_forward(
torch::Tensor A,
torch::Tensor B);
std::vector<torch::Tensor> my_add_cuda_backward(
torch::Tensor grad_out);
/***********************************************
FORWARD, BACKWARD関数の定義
それぞれPythonでのmy_add.forward(), my_add.backward()で呼び出される
*************************************************/
std::vector<at::Tensor> my_add_forward(
torch::Tensor A,
torch::Tensor B
){
CHECK_INPUT(A);
CHECK_INPUT(B);
return my_add_cuda_forward(A, B);
}
std::vector<torch::Tensor> my_add_backward(
torch::Tensor grad_out
){
grad_out = grad_out.contiguous();
CHECK_INPUT(grad_out);
return my_add_cuda_backward(grad_out);
}
/*********************************************
以下はPythonから呼び出せるモジュールにするために必要
********************************************/
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("forward", &my_add_forward, "myadd forward (CUDA)");
m.def("backward", &my_add_backward, "myadd backward (CUDA)");
}
はじめにCUDA関数の名前だけ宣言をし,その後,関数my_add_forward,my_add_backwardでそれぞれ対応するCUDA関数を呼び出しています.引数となるテンソルはCHECK_INPUT()によりCUDA関数に渡す前に,1. GPUに転送されているか 2. contiguousかを確認し,条件が満たされない場合にエラーを返します.
Pythonファイルsetup.pyでC++/CUDA関数をビルド & Pythonにbindする
以下のように記述してください.
from setuptools import setup
from torch.utils.cpp_extension import BuildExtension, CUDAExtension
setup(
name='my_add',
ext_modules=[
CUDAExtension('my_add', [
'my_add.cpp',
'my_add_kernel.cu',
])
],
cmdclass={
'build_ext': BuildExtension
})
以上で準備は完了です.my_addディレクトリ上で以下を実行し,長いwarningの後にFinished processing dependencies for ...の言葉が出たら成功です.
python setup.py install
実際にテストする
以下のようなpythonファイルを用意します.例によって他の記事で解説済みなので不明点はそちらを参照してください.
import torch
import torch.nn as nn
import my_add
from pdb import set_trace as db
class MyaddFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, A, B):
output = my_add.forward(A, B)
ctx.save_for_backward(*output[1:], A, B)
return output[0]
@staticmethod
def backward(ctx, d_out):
saved_tensors = ctx.saved_tensors
d_input = my_add.backward(d_out)
dA, dB = d_input
return dA, dB
class Myadd(nn.Module):
def __init__(self):
super(Myadd, self).__init__()
pass
def forward(self, A, B):
return MyaddFunction.apply(A, B)
if __name__=='__main__':
use_cuda = torch.cuda.is_available()
if use_cuda:
device = torch.device('cuda')
else:
raise ValueError("CUDA is not available!!")
model = Myadd()
model.to(device)
_A = torch.rand(100, 100).requires_grad_()
A = _A.to(device)
B = torch.rand(100, 100).to(device)
out = model(A, B)
print('model out: ', out)
loss = torch.sum(out)
loss.backward()
print("_A.grad: ", _A.grad) # None --> tensor([1., ...])に変わっている!!
正しく実行できました.
終わりに
PyTorch CUDA APIの使い方を簡単な例を用いて紹介しました.ただ,実際にCUDAを書こうとしている方はただの足し算のような簡単な演算ではなく,より複雑な処理を並列計算させたい人が多いのではないでしょうか?次回,if文や型変換などより複雑な並列計算をさせるために知っておきたいことなどをまとめて紹介します.