CUDAを使ったプログラミングに触れる機会があるため、下記、ざっと学んだことを記します。
細かいところは端折って、ざっとCUDAを使ったGPUプログラミングがどういったものを理解します。
GPUとは
-
Graphics Processing Unitの略で、描画処理用のCPUのこと - AMD社とNVidia社が有名
- GPGPUは
General Purpose Graphics Processing Unitの略で、GPUを画像処理ではなく他の用途(ex. 暗号解読、音声処理)に使用するときに使用される。
GPUの特徴
- CPUより並列処理の長けており演算性能が高い
| 種類 | 処理速度 |
|---|---|
| Corei7(4コア) | 100G FLOPS |
| GeForce GTX 285 | 1T FLOPS |
[ゼロから始めるGPU Computing] (http://www.gdep.jp/page/index/market)

一般的に数倍~100倍以上の速度と言われている
補足:なぜ演算性能が高いのか?
GPUでは、CPUに搭載されている分岐予測・投機実行 アウトオブオーダーが簡素化されており、その分、コア数を増やすことができる。
- 分岐予測・投機実行とは?
条件分岐した際の処理を前もって実行しておくこと。
過去の実行履歴から実行される可能性の高い命令を実行しておく。
[イメージ]
arr = [1, 3, 5, 7, 8];
for (elm as arr){
if(elm % 2 == 1){
echo "odd"; //奇数が続くためCPUは事前にこの処理を予測し実行しておく
}else{
echo "even"; //偶数が来た時にはoddの結果を破棄してこちらを実行する
}
}
こうすることで命令処理全体の実行時間を短縮できる。
>
* アウトオブオーダーとは?
プログラムに記述された命令の順番に関係なく処理が行われる仕組みのこと。
処理に必要なデータが揃った命令から実行するようにする。
>```
[イメージ]
----------------------------------------------------
x = 1 + 1;
y = x + 1; //→yはxに依存しているためxの計算の後に処理が行われないといけない
z = 1 + 1; //→zは独立して計算できるため、yの処理でxのメモリを並行して行うことができる
----------------------------------------------------
こうすることで命令処理全体の実行時間を短縮できる。
CUDAとは
- NVIDIAが提供するGPU向けのC/C++言語の統合開発環境
- SPMD方式をとる
SPMD方式・・・同一のプログラムがで並列に実行される仕組みのこと。
(↔︎MPMD・・・複数のプログラムが協調的に動作する並列処理のこと)
http://h50146.www5.hp.com/solutions/hpc/stc/soft/pdfs/mpi_training.pdf
CUDAの基礎的な用語
| 用語 | 意味 |
|---|---|
| ホスト | 呼び出し側のこと |
| デバイス | GPU側のこと |
| カーネル | デバイス上で実行される処理のこと。ホスト上のソースコードに定義する |
| スレッド | カーネルを実行する最小単位のプロセスのこと。各々のスレッドは3次元で管理される |
| ブロック | スレッドのかたまり。 |
| グリッド | ブロックの塊 |
| SM(ストリーミングマルチプロセッサ) | ストリームを管理するプロセッサ |
| ストリーム | 実際にCUDAコアが逐次的に処理実行するための処理の流れ |
| CUDAコア | 実際に処理を行う演算装置 |
| ウォープ | スレッドのかたまり(スレッド単位で見た時、CUDAが処理で切る最大並列数はCUDAコアの数分だけで、その数をウォープという) |
CUDAのアーキテクチャ
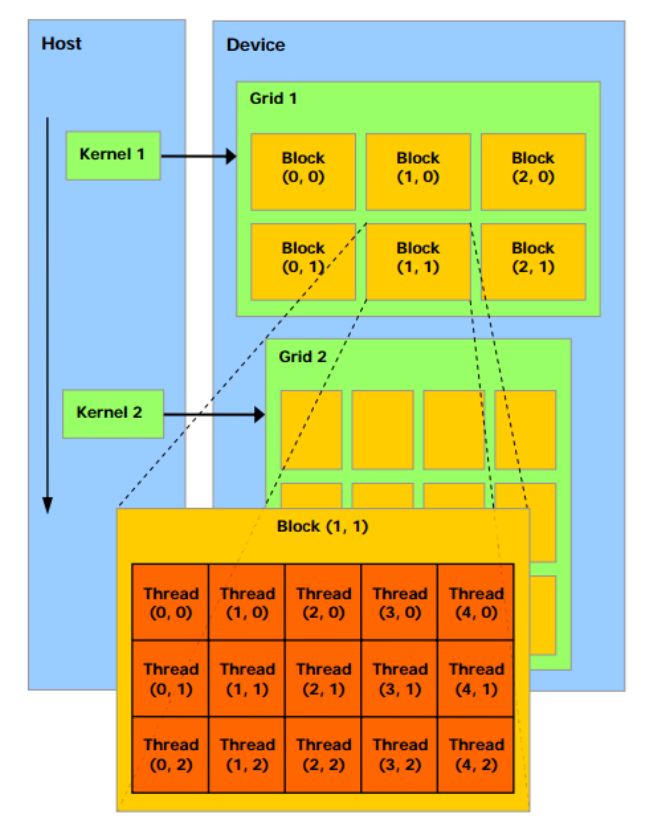
http://www.nvidia.co.jp/docs/IO/51174/NVIDIA_CUDA_Programming_Guide_1.1_JPN.pdf
補足:
- 上図はThreadも2次元で管理されているが、実際は3次元である
- ブロックは、
65535*65535*1の3次元で管理されている - スレッドは
5*5*5の3次元で管理されている - 最大スレッド実行数は
65535 * 65535 * 512
CUDAの仕組み
# include <stdio.h>
__device__ void device_strcpy(char *dst, const char *src) {
while (*dst++ = *src++);
}
__global__ void kernel(char *A) {
device_strcpy(A, "Hello, World!");
}
int main() {
char *d_hello;
char hello[32];
cudaMalloc((void**)&d_hello, 32);
kernel<<<1,1>>>(d_hello);
cudaMemcpy(hello, d_hello, 32, cudaMemcpyDeviceToHost);
cudaFree(d_hello);
puts(hello);
}
基本的な流れとして、
デバイス用のソースを定義する
↓
デバイスとホストの各々でデータのやり取りのためにポインターを定義する
↓
カーネルを呼ぶ
↓
先に定義したポインターを介してデータのやり取りを行う
だけである。
なお、kernel<<<1,1>>>(d_hello);では、カーネルを実行するときに使用するリソースの数(ブロック数、スレッド数)を定義している。
分かりやすいアニメーション

CUDAを使った開発時の注意点
- デバイスはホストメモリにはアクセスできない
- カーネルからの戻り値の型はvoid型(※)
- 可変引数は使用不可
- 再帰処理は不可
- static変数は使えない
(※)cudaMemCpyなどのCUDAのAPIに関しては、cudaError_t型の構造体が返ってくる