ゼロから始めるPythonの5回目になります。
四回目はこちら
おさらい
前回は主に制御部分と関数の定義についてまとめていました。
引き続き、分割の投稿となります。
チュートリアル
7. データ構造
7.1. リスト型の詳細
三回目でもまとめており、重複する内容もあります。
7.1.1. append
list.append(x)
リストの末尾に要素を1つ追加します。
>>> l = []
>>> l.append(1)
>>> l
[1]
また、次の式と等価になります。
l[len(l):] = [x]
>>> l = []
>>> l[len(l):] = [1]
>>> l
[1]
7.1.2. extend
list.extend(iterable)
イテレータブル(反復処理が可能)なオブジェクトの全ての要素を対象のリストに追加し、対象のリストを拡張します。
この時、同じ値を持つ要素があっても重複して存在できることに注意しましょう。
>>> l = [1,2,3]
>>> l.extend([4,5,6])
>>> l
[1, 2, 3, 4, 5, 6]
>>> l.extend([1,3,5,7])
>>> l
[1, 2, 3, 4, 5, 6, 1, 3, 5, 7]
また、対象のリストを「拡張」しているので、オブジェクトID自体は変わらないことにも注意が必要です。
>>> l = [1, 2, 3]
>>> id(l)
139860095859016
>>> l.extend([4, 5, 6])
>>> id(l)
139860095859016 # 拡張前とIDが同じ
7.1.3. insert
list.insert(i, x)
位置iの直前に要素xを挿入します。
>>> l = [1, 2]
>>> l.insert(1, 3)
>>> l
[1, 3, 2]
また、次の動作は等価です。
list.insert(len(i), x) = list.append(x)
>>> l = [1, 3, 2]
>>> l.insert(len(l),4)
>>> l
[1, 3, 2, 4]
7.1.4. remove
list.remove(x)
要素xをリストから削除します。
ただし、要素がリストに存在しない場合はValueErrorが発生します。
>>> l = [1, 2, 3]
>>> l.remove(1)
>>> l.remove(4)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: list.remove(x): x not in list
7.1.5. pop
list.pop([i])
位置iに指定された要素をリストから削除してその要素を返します。
位置を指定しない場合は末尾の要素をリストから削除して返します。
※引数の「角括弧」はリスト型を示すものではありません。ここではオプションを示すものなのでご注意下さい。
>>> l = [1, 2, 3]
>>> l.pop(1)
2
>>> l
[1, 3]
7.1.6. clear
list.clear()
言わずもがな、リストのすべての要素を削除します。
>>> l = [1, 2, 3]
>>> l.clear()
>>> l
[]
また、次の式と等価です。
del list[:]
>>> l = [1, 2, 3]
>>> del l[:]
>>> l
[]
7.1.7. index
list.index(x[,start[,end]])
リスト中の要素xの要素位置をゼロから始まる添字で返します。
同じ要素がある場合は最初にヒットした要素位置を返します。
またこの時、xの後にスライスを用いてリストの探索範囲を指定することができます。
(ただし、返却される添字はリスト全体の先頭からの位置)
>>> l = list('helloWorld')
>>> l.index('l')
2
>>> l.index('W',2,6) #要素位置[2~5]が探索範囲
5
>>> l.index('W',2,5) # 探索範囲に存在しない
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: 'W' is not in list
7.1.8. count
list.count(x)
リスト内での要素xの件数を返します。
>> values = [1, 2, 2, 3, 3, 3, 4, 4, 4, 4]
>>> values.count(1)
1
>>> values.count(4)
4
7.1.9. sort
list.sort(key(=None), reverse(=False))
リストの項目をインプレース演算(対象のリストがミュータブル(状態の変更が可能)な場合は新しいオブジェクトを生成せず元のオブジェクトを置き換える)によってソートします。
(結構ここの仕様は落とし穴になりそう)
以下、検証してみました。
>>> print([1,5,3,4,2].sort()) # sortを実行した結果、ソートされたリストを返すわけではない
None # だから戻り値も当然ない
>>> l = [1,5,3,4,2]
>>> l.sort() # 一度ソートしてリストデータを変更し
>>> l #出力するとソートされた結果を返す
[1, 2, 3, 4, 5]
また、公式チュートリアルには次のような記述もあります。
sorted(iterable, *, key=None, reverse=False)
iterable の要素を並べ替えた新たなリストを返します
こちらは、リストをソートした上で新しいオブジェクトを返します。
>>> l = [1,5,3,4,2]
>>> id(l)
140087708991112
>>> id(sorted(l))
140087649958536 # 異なるID
>>> print(sorted(l))
[1, 2, 3, 4, 5] # sortedによって得られたオブジェクト
>>> l
[1, 5, 3, 4, 2] # 元のリストオブジェクト
7.1.10. reverse
list.reverse()
リストの要素をインプレース演算で逆順にします。
sort()と同様、注意しましょう。
>>> l = [1,5,3,4,2]
>>> id(l)
140087649978824 # 元のリストオブジェクト
>>> l.sort()
>>> l.reverse()
>>> id(l)
140087649978824 # IDが一致している
7.1.11. copy
list.copy()
リストの浅い(シャロー)コピーを返却します。
list_to = list[:]
と等価です。
Pythonに限った話ではありませんが、浅いコピーとはコピー元とコピー先が同じメモリ上のデータを参照した状態のコピーを指します。
下記で検証してみます。
まずは浅いコピーの想定できる動作について。
>>> list_a = [1, 2, 3]
>>> list_b = [4, 5, 6]
>>> list_c = [7, 8, 9]
>>> merge_list = [list_a, list_b, list_c]
>>>
>>> list_ref = merge_list # merge_listへの参照
>>> merge_list[0] = [10, 11, 12] # merge_listを変更すると
>>> merge_list
[[10, 11, 12], [4, 5, 6], [7, 8, 9]] # 当然変更されており
>>> list_ref
[[10, 11, 12], [4, 5, 6], [7, 8, 9]] # 参照しているだけなので変わっている
>>>
>>> copy_list = merge_list.copy() # 次に浅いコピー
>>> merge_list[0] = [1, 2, 3] # 1つ目の要素を変更すると
>>> merge_list
[[1, 2, 3], [4, 5, 6], [7, 8, 9]] # コピー元は変更されているが
>>> copy_list
[[10, 11, 12], [4, 5, 6], [7, 8, 9]] # コピー先は変更されない
ここまではなんとなく想像できますね。
ですが、次は我々が普段からイメージする「コピー」とは少し異なってくると思います。
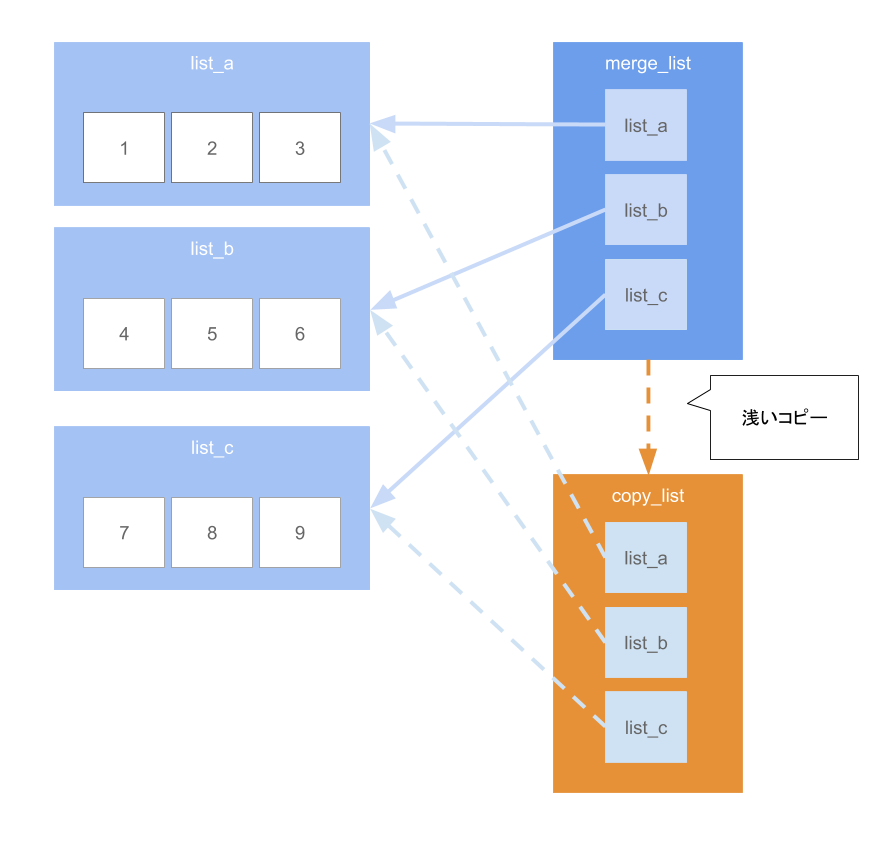
↓

>>> list_a = [1, 2, 3]
>>> list_b = [4, 5, 6]
>>> list_c = [7, 8, 9]
>>> merge_list = [list_a, list_b, list_c]
>>> copy_list = merge_list.copy() # 浅いコピー
>>> list_a = [10,2,3] # 参照先の1つを変更すると
>>> copy_list
[[10, 2, 3], [4, 5, 6], [7, 8, 9]] # 浅いコピーの方も変更される
>>> merge_list
[[10, 2, 3], [4, 5, 6], [7, 8, 9]] # コピー元も参照先の値が変わるので変更される
あくまで、元のmerge_listはlist_a,list_b,list_cの参照をもつリストになります。
>>> id(list_a)
139718526679752 # IDは同じ
>>> id(merge_list[0])
139718526564872 # IDは同じ
今回、ここでは触れませんが「深い(deep)コピー」というのもあります。
こちらは我々の馴染みのある「コピー」という概念と等しいでしょう。
コピー元のオブジェクトを「複製」してコピーを生成します。
7.1.12. スタック、キュー
これまでで説明した機能を使用することで、リストをスタックやキューとして扱うことが出来ます。
スタック:後入れ先出し方式(last-in first-out)
キュー:先入れ先出し方式(first-in first-out)
>>> stack = []
>>> stack.append(1) # データ格納
>>> stack.append(2) # データ格納
>>> stack.append(3) # データ格納
>>> stack
[1, 2, 3]
>>> stack.pop() # 最後のデータ取り出し ([1, 2])
3
>>> stack.pop() # 最後のデータ取り出し([1])
2
# 結果 [1]
>>> from collections import deque # importは後々説明
>>> queue = deque([1, 2, 3])
>>> queue.popleft() # 先頭データ取り出し
1
>>> queue.popleft() # 戦闘データ取り出し
2
# 結果 [3](厳密にはdeque([3])
8. 内包表記
チュートリアルにはさらっと書いてありましたが、詳しく取り上げたいので今回は概要だけ。
内包表記では、リストやタプルなどのイテラブル(反復可能)なオブジェクト内の要素を1つずつ変数名に格納し、指定した式で評価した結果の要素リストを返却します。
[式 for 要素名 in イテラブルオブジェクト]
例として、
「0から9までの値を全て倍にしたリストを取得する」
とします。
for文で行うと
>>>> results = []
>>> for d in range(10) :
... results.append(d * 2)
...
>>> results
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
内包表記で行うと
>>> results = [d * 2 for d in range(10)]
>>> results
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
このように、それぞれの要素に対して式を適用する場合などに便利です。
また、細かい説明は別途記事で取り上げたいと思います。
9. del文
指定したインデックスiのリストの要素、または変数全体を削除します。
del list[i]
この時、pop()のように削除する対象の要素を返さないことに注意しましょう。
>>> value = [1,2,3,4,5]
>>> value.pop(1)
2
>>> value = [1,2,3,4,5]
>>> del value[1]
>>> del value
>>> value
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'value' is not defined
10. タプル、シーケンス
シーケンスとは要素の順番を保持するオブジェクトで、list,tupleなどがあります。
また、strも「テキストシーケンス」と呼ばれていることを覚えておきましょう。
(三回目(4.1.3.)に検証しましたが、もう一度)
word = 'Python'
word[0] # P
word[5] # n
word[-1] # n
word[-6] # P
そして、タプルに関しても三回目(4.4.3)で説明しています。
(要素, 要素, ...)
※必ずしも括弧で囲むことによって定義するわけではありません
タプルは要素を変更できない、と説明しましたね。
ただし、タプル内のミュータブルなオブジェクトの場合はその限りではありません。
>>> t = ({'apple':'りんご','grape':'ぶどう','peach':'もも'},{'one':'イチ','two':'ニ','three':'サン'})
>>> t[0]['banana'] = 'ばなな' # タプルに格納されたミュータブルオブジェクトの中では変更可能
>>> t
({'apple': 'りんご', 'grape': 'ぶどう', 'peach': 'もも', 'banana': 'ばなな'}, {'one': 'イチ', 'two': 'ニ', 'three': 'サン'})
>>> t[2] = dict() # タプルそのものの変更は不可
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
またtupleはイミュータブルオブジェクトで、複数の型の要素から成ることがあるため、
アンパックやインデックスでアクセスすることが多いです。
アンパック: リストやタプルの要素を展開し、複数の変数に代入すること
>>> data = (1, 2, 3) # tupleの要素を
>>> a, b, c = data # 変数にアンパック
>>> a
1
>>> b
2
>>> c
3
11. 辞書型
辞書型はキーと値のペアの集合です。
この時、キーは辞書内でユニークである必要があります。
辞書型は主に「ある値に何らかのキーを付与して記憶、キーを指定して値を取得する」ことを目的に使用されます。
{key : value, key : value, ....}
>>> d = {'one':'いち','two':'に','three':'さん'}
また、dictコンストラクタを用いることで、キーと値のペアのタプルから成るリストから辞書を生成できます。
dict()
>>> d = dict([('one','いち'),('two','に'),('three','さん')])
キーが単純な文字列の場合は、キーワード引数でも定義できます。
>>> d = dict(one='いち',two='に',three='さん')
12.ループテクニック
12.1. items()
辞書に対しては、items()メソッドを用いることでキーと値のペアを同時に取得できます。
>>> d = dict([('one','いち'),('two','に'),('three','さん')])
>>> for key, value in d.items():
... print(key, value)
...
one いち
two に
three さん
12.2. enumerate()
シーケンス型に対しては、enumerate()メソッドを用いることで要素のインデックスと要素を同時に取得できます。
>>> l = ['apple','grape','peach']
>>> for idx, value in enumerate(l):
... print(idx, value)
...
0 apple
1 grape
2 peach
12.3. zip()
2つ以上のシーケンス型に対して同時にループする場合、zip()メソッドを用いて各要素をペアに出来ます。
>>> english = ['one','two','three']
>>> japanese = ['いち','に','さん']
>>> for eng, jpn in zip(english, japanese):
... print(eng, jpn)
...
one いち
two に
three さん
12.4. reversed()
シーケンスを逆方向にループする場合、reversed()メソッドを用います。
>>> names = ['たろう','じろう','さぶろう']
>>> for name in reversed(names):
... print(name)
...
さぶろう
じろう
たろう
まとめ
ようやくチュートリアルの折り返しくらいまで進みました。
次はモジュールについてまとめます。