ゼロから始めるPythonの3回目になります。
二回目はこちら
おさらい
前回は、対話モードではなくスクリプトを作成して実行してみました。
おそらく今後スクリプト作成がベースになっていくと思います。
(といいながら対話モードで検証しています)
チュートリアル
Pythonは、ドキュメントにチュートリアルが用意されています。
とても親切で初学者にとっては嬉しい限りです。
必要そうな部分のみをピックアップしてご説明したいと思います。
1. 演算子
1.1. 数値演算子
| 演算子 | 例 | 説明 |
|---|---|---|
| + | a + b | aとbを加算する |
| - | a - b | aからbを減算する |
| * | a * b | aにbを乗算する |
| / | a / b | aをbで除算する |
| // | a // b | aをbで除算した商の整数値 |
| % | a % b | aをbで除算した余り |
| ** | a ** b | aをb回乗算する(べき乗) |
変数に代入するとき、[=]の前に演算子をつけると変数値に対して演算を行えます。
temp = 1
temp += 2
print(temp)
# 3
また、文字列と数値を結合して出力したい場合もあるかと思います。
この場合、数値は明示的に文字列として変換して結合しなければなりません。
~$ python3
Python 3.7.0 (default, Sep 8 2018, 19:52:13)
[GCC 7.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> temp = 5 + "回繰り返す"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for +: 'int' and 'str'
>>> temp = str(5) + "回繰り返す"
>>> print(temp)
5回繰り返す
1.2. 比較演算子
| 演算子 | 例 | 説明 |
|---|---|---|
| < | a < b | aはbより小さいときにtrue |
| > | a > b | aはbより大きいときにtrue |
| <= | a <= b | aはb以下のときにtrue |
| >= | a >= b | aはb以上のときにtrue |
| == | a == b | aとbは等価のときにtrue |
| != | a != b | aとbが不等価のときにtrue |
| is | a is b | aとbが「同一のオブジェクト」のときにtrue |
| is not | a is not b | aとbが「異なるオブジェクト」のときにtrue |
注意したいのは[ is ]と[ is not ]ですね。
演算子 [ == ]は値の等価の際に用います。
(@shiracamus 様よりご指摘)
一方で、演算子[ is ]はオブジェクト(インスタンス)の等価同一の際に用います。
>>> A = ['a', 'b', 'c']
>>> B = A
>>> C = ['a', 'b', 'c']
>>> A == B
True
>>> A == C
True
>>> A = ['a', 'b', 'c']
>>> B = A
>>> C = ['a', 'b', 'c']
>>> A is B
True
>>> A is C
False
違いがわかりましたでしょうか?
演算子[ == ]はそれぞれA, B, Cの値が同じなので、比較した結果すべてTrueが返されます。
演算子[ is ]はA, B, Cの値は同じですが、インスタンスはAとBのみが同じでCが異なります。
1.3. 論理演算子
| 演算子 | 例 | 意味 |
|---|---|---|
| and | a and b | 論理積 |
| or | a or b | 論理和 |
| not | a not b | 否定 |
説明するまでもないですね。
Pythonの論理演算子は短絡評価です。
短絡評価とは、Javaでいうところの[ && ]や[ || ]演算子のことですね。
(@shiracamus 様ご指摘)
左項で結果が得られた場合、右項は評価しません。>>> def left_func(): ... print("left function is true") ... return True ... >>> def right_func(): ... print("right function is false") ... return False ... >>> left_func() and right_func() left function is true right function is false False >>> right_func() and left_func() right function is false False >>> left_func() or right_func() left function is true True >>> right_func() or left_func() right function is false left function is true True
1.4. ビット演算子
| 演算子 | 例 | 意味 |
|---|---|---|
| & | a & b | 論理積。aとbが1のとき1を返す |
| | | a | b | 論理和。aもしくはbが1のとき1を返す |
| ^ | a ^ b | 排他的論理和。aかbのどちらかのみ1のとき1を返す |
| - | -a | 否定。aのビットを反転する |
| << | a << 1 | 左にシフト。値を倍にする |
| >> | a >> 1 | 右にシフト。値を半分にする |
2. インデント
プログラミング言語によって、スコープ範囲を示すブロック構文が異なります。
{ . . . }はよくみかけます。
Pythonでは、インデントを使用してブロック構文を表現します。
インデントには半角スペースとタブが用いられます。
スペース4つが標準(正確にはPEP8での規約)らしいです。
実は、インデントを使用せずにスコープ範囲を定義する方法もあります。
>>>if(True): print('a'); print('b');
(@shiracamus 様ご指摘)
ですが、インデントしない記法はご法度だそうです。
PEP8では禁止していませんでした。
3. コメント
3.1. 行単位のコメント
# コメント
行単位のコメントは、先頭に「#」を付与することにより行末までをコメントとします。
3.2. 行末のコメント
a = 123 #コメント
行末のコメントは、行の途中に書いた「#」から行末までをコメントとします。
3.3. 複数行単位のコメント
'''
コメント1
コメント2
'''
"""
コメント3
コメント4
"""
複数行単位のコメントは、
「'''(シングルクォーテーション3つ)」もしくは
「"""(ダブルクォーテーション3つ)」で囲まれた部分をコメントとします。
ただし、複数行単位のコメントの場合は直前のインデントと合わせてください。
エラーになってしまいます。
4. 変数
Pythonは、動的型付け言語です。
(@shiracamus 様ご指摘)
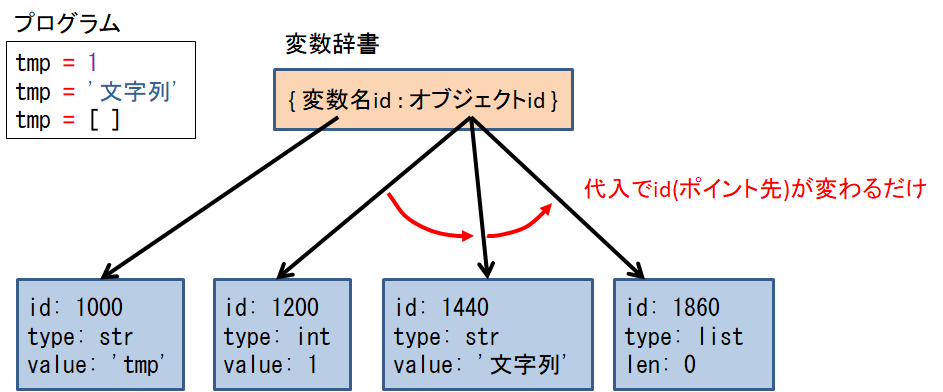
ということは、変数の型は代入された時点で決まるんですね。
具体的には、Pythonの変数はC言語で言うところの「ポインタ」です。
Pythonのインタプリタが変数に代入する値や文字を解釈した時点で型を特定し、オブジェクトを生成します。
そして、変数名とオブジェクトのポイント先を保持した変数辞書に登録されます。
このとき、同じ値を持つ変数情報がすでに存在する場合は新しくオブジェクトを生成しません。
あくまでポイント先を変数辞書に登録します。
>>> tmp = 1
>>> id(tmp)
140436504368896
>>> tmp = '文字列'
>>> id(tmp)
140436477036464
>>> tmp = []
>>> id(tmp)
140436478439368
4.1. 文字列
4.1.1. 文字列のエスケープ
文字列をエスケープさせる場合は''を使用します。
また、単引用符、二重引用符の前に'r'を付与することで、
エスケープを解釈させない文字列として認識させることができます。
ファイルパスなどにはこちらのほうが良いですね。
4.1.2. 文字列の結合
文字列を結合したい場合、'+'演算子を用いて結合できます。
また、演算子を用いなくても引用符で囲まれた文字列が連続して並んでいる場合も結合できます。
temp = 'a' + 'b' #ab
temp = 'a' 'b' 'c' #abc
4.1.3. 文字列のインデックスによる取得
文字列を1文字ずつ格納したリストとして使用したい場合、インデックスを用いることで
実現できます。
(いちいちリストに変換する処理をしなくてもいい!!)
なお、インデックスを負の数で指定すると文字列の末尾からのインデックスにできるんです。
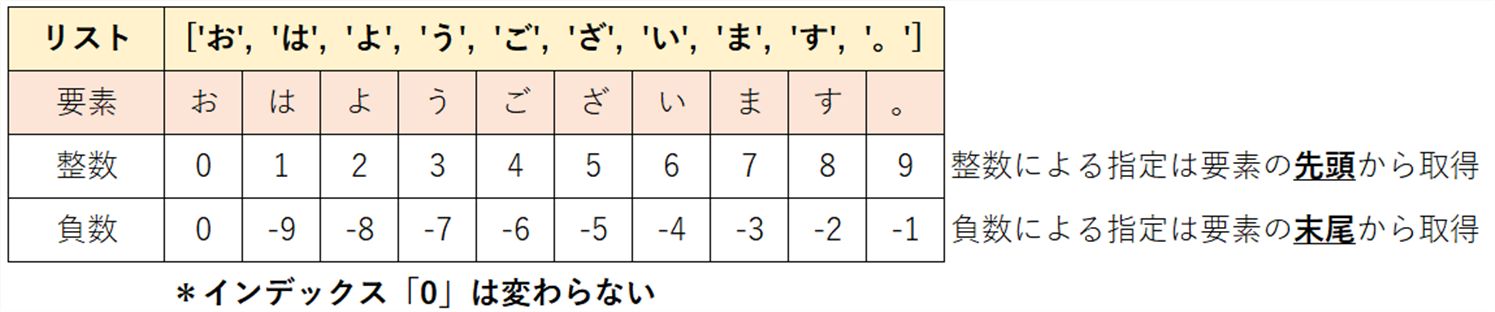
word = 'Python'
word[0] # P
word[5] # n
word[-1] # n
word[-6] # P
4.2. 数値
標準ドキュメント曰く、数値型には
・整数(長整数)
・浮動小数点数
・複素数
があるそうです。
4.2.1. 数値リテラル
上記のとおり、Pythonでは数値型にも複数種類あることがわかります。
これらを適切に表現してみます。
・整数:int型
Python2までは整数(int)と長整数(long)がわかれていましたが、
Python3より統合されました。
# 全てint
>>> num = 1
>>> type(num)
<class 'int'>
>>> num = 123456789012345678901234567890
>>> type(num)
<class 'int'>
>>> num = -10000
>>> type(num)
<class 'int'>
また、進数は次のように記述します。
0b~: 2進数
0o~: 8進数
0x~: 16進数
>>> num = 0b1110
>>> num
14
>>> num = 0o7077
>>> num
3647
>>> num = 0xffff
>>> num
65535
・浮動小数点数:float型
「e(E)」を用いてべき乗の指数を示すことができます。
>>> num = 1.234
>>> type(num)
<class 'float'>
>>> num = 1.2E-3
>>> type(num)
<class 'float'>
・虚数:complex型
虚数は末尾に「j(J)」をつけて表現します。
>>> num = 3.14j
>>> type(num)
<class 'complex'>
4.3. ブール型
Pythonのブール型は真偽値を持ちます。
>>> type(True)
<class 'bool'>
>>> type(False)
<class 'bool'>
また、Pythonのブール型はint型のサブタイプになります。
(親として数値型を持つ派生タイプ)
つまり、真偽値を整数にすることができます。
(Trueを1に、Falseを0に)
>>> issubclass(bool, int)
True
>>> int(True)
1
>>> int(False)
0
更にPythonでは、全てのオブジェクトに対して真偽値を判定することができます。
>>> bool()
False
>>> bool(None)
False
>>> bool(False)
False
>>> bool(1)
True
>>> bool(0)
False
>>> bool(-1)
True
>>> bool('a')
True
>>> bool(a)
True
>>> bool([])
False
>>> bool([1, 2, 3])
True
>>>
主な「偽」の値として判定されるのは次の状態のものです。
・偽の値として定義済みである定数:[None], [False]
・数値型のゼロ
・空のシーケンスやコレクション
4.4. イテラブル(iterable)
後述の辞書型やリスト型のように、反復が可能なオブジェクトを指します。
具体的には「__iter__」というメソッドを持つオブジェクトのことを言います。
イテラブルとイテレータは別物であることに注意しましょう。
次の例ではイテラブルとイテレータの挙動を確認しています。
イテレータとイテラブルの違い>>> data = [1,2,3] >>> for i in data: ... print(i) ... 1 2 3 >>> for i in data : ... print(i) ... 1 2 3 # iterableオブジェクトはfor文開始前に__iter__()メソッドを呼び出している # このときの戻り値は新しいイテレータ。 >>> >>> data = iter(data) >>> for i in data: ... print(i) ... 1 2 3 >>> for i in data : ... print(i) ... # iteratorはfor文開始前に__iter__()メソッドを呼び出している # このときの戻り値は自分自身。 # 一度呼び出された際に自分自身の位置を記憶しているのですでに最後の位置に来ている。 >>>
4.4.1. リスト型(list)
要素に様々なオブジェクトを格納することができるオブジェクトです。
文字列のときは異なり、リストは可変であるので要素の入れ替えや追加、削除ができます。
(=ミュータブル)
>>> example = [1, 2, "a", "b"]
>>> example[1] = "c"
>>> example.append("d")
>>> example.remove(0)
>>> example.remove(1)
>>> example
['c', 'a', 'b', 'd']
4.4.2. 辞書型(dict)
keyとvalueの組み合わせを持つオブジェクトです。
基本的に、各要素へのアクセスは[key]を指定して行います。
注意が必要なのは、バージョンによって辞書型に要素の順序を持たないことがあります。
(Python3.5で順序を持たないことを確認)
$ python3.7
Python 3.7.0 (default, Sep 8 2018, 19:52:13)
[GCC 7.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> data = {"1":"a","2":"b","3":"c"}
>>> data
{'1' : 'a', '2' : 'b', '3' : 'c'}
>>> data = {"1":"a","2":"b","3":"c"} #もう一度
>>> data
{'1' : 'a', '2' : 'b', '3' : 'c'}
# coding: utf-8
# Your code here!
import sys
print(sys.version_info)
data = {"1":"a","2":"b","3":"c"}
data
# 結果(1回目)
sys.version_info(major=3, minor=5, micro=2, releaselevel='final', serial=0)
{'1' : 'a', '3' : 'c', '2' : 'b'}
# 結果(2回目)
sys.version_info(major=3, minor=5, micro=2, releaselevel='final', serial=0)
{'2' : 'b', '1' : 'a', '3' : 'c'}
4.4.3. タプル型
リスト型と同様、複数の要素から構成されるオブジェクトです。
リスト型と異なるのは、「オブジェクトの要素を変更できない」(=イミュータブル)点です。
また、メソッドが用意されていません。
厳密には、オブジェクトIDを変更せずに要素の変更ができないことを意味します。
次のような操作はイミュータブルなオブジェクトでも実行できます。
#####a. タプルを参照している変数に再代入
次の例では、変数[tuple]が参照しているタプルが変わっていることと、タプル内の要素を変更しようとした際に例外が出力されていることが確認できます。
a.$ python3.7 Python 3.7.0 (default, Sep 8 2018, 19:52:13) [GCC 7.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> tuple = (1, 2, 3) >>> tuple = (4, 5) # 1:true >>> tuple[0] = 1 # 2:false Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment >>> tuple += (1, 2, 3) #3:true混同しやすい動作ですが、最後のコード(#3)を見てください。
tupleに値いれてますやん!!!!!って思いましたが、
ここで返る結果は新しいタプルオブジェクトを生成して返すので、エラーが発生しません。
難しいですね。。。#####b. タプルの中の要素がミュータブルの場合に、要素そのものを変更する
例えば、タプルの要素の中に辞書型オブジェクト(ミュータブル)がある場合、
この辞書型オブジェクトの要素を追加した場合はエラーが発生しません。>>> tuple1 = (1, {"a":1}, 3) >>> tuple1[1]["b"] = 2 # (1, {"a":1,"b":2}, 3)
4.4.4. セット型
セット型は集合を扱うオブジェクトです。
複数の値を格納できることはこれまでのもの変わりませんが、次の点が大きく異なります。
a. 重複した要素がない
set型に複数の要素からなるリストオブジェクトを格納すると、
重複がないリストとして生成されていることがわかります。
>>> sets = {1, 2, 3, 1, 3}
>>> sets
{1, 2, 3}
この時注意しなければならないのは、要素が「ミュータブル」オブジェクトである場合です。
要素のユニークさを判定する際、要素をハッシュ化させているので、
ミュータブルオブジェクトを要素として生成すると・・・
>>> sets = {1, [1, 2, 3]}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
このように、ハッシュ化できませんよ、というTypeErrorがスローされます。
しかし、場合によってはリストのデータなど既存のリストオブジェクトの要素を利用したい場合がありますね。
この時、組み込み関数[set]を使用します。
>>> l = [1, 2, 3]
>>> sets = set(l)
>>> sets
{1, 2, 3}
b. 要素の順番を持たない
set型は要素の順番を持ちません。
挿入の順序や要素の位置を持たないので、当然インデックスによる参照もエラーになります。
$ python3.7
Python 3.7.0 (default, Sep 8 2018, 19:52:13)
[GCC 7.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> sets = {1, 5, 2, 4, 3}
>>> sets
{1, 2, 3, 4, 5} # 順序は保持されていない
>>> sets = set([1, 3, 5, 4, 2])
>>> sets
{1, 2, 3, 4, 5} # 順序は保持されていない
>>> sets[0] = 1
>>> sets[1]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'set' object does not support indexing
また、2つのset型によって簡単に集合演算が行なえます。
和(union)
2つの集合のいずれかに含まれる
演算子: |
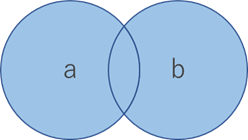
>>> a = {1, 2, 3, 4, 5}
>>> b = {1, 3, 5, 7, 9}
>>> a | b
{1, 2, 3, 4, 5, 7, 9}
積(intersection)
2つの集合の両方に含まれる
演算子: &
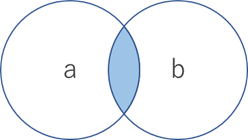
>>> a = {1, 2, 3}
>>> b = {1, 3, 5}
>>> a & b
{1, 3}
差(difference)
(aを対象とした時)aにのみ含まれる
演算子: -
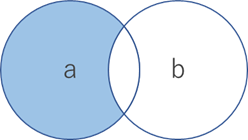
>>> a = {1, 2, 3, 4, 5}
>>> b = {1, 3, 5}
>>> a - b
{2, 4}
対象差(symmetric difference)
aもしくはbにのみ含まれる
演算子: ^
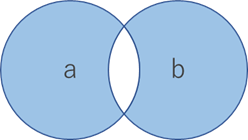
>>> a = {1, 2, 3, 4, 5}
>>> b = {3, 4, 5, 6, 7}
>>> a ^ b
{1, 2, 6, 7}
部分集合(subset, superset)判定
演算子:< ,<= , > , >=
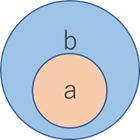
>>> a = {1, 3, 5}
>>> b = {1, 2, 3, 4, 5}
>>> a <= b
True
>>> a < b
True
>>> b = {1, 3, 5}
>>> a < b
False
>>> a >= b
True
>>> a > b
False
最後に、集合型(set)は変更可能な値コレクションになります。
一方、変更不可能な集合型にする場合、[frozenset]を用います。
変更操作の可否以外はsetと同じです。
$ python3.7
Python 3.7.0 (default, Sep 8 2018, 19:52:13)
[GCC 7.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> a = set([1, 2, 3])
>>> a.add(4)
>>> a = frozenset([1, 2, 3])
>>> a.add(4)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'frozenset' object has no attribute 'add'
4.4.5. スライス
シーケンス型のオブジェクト(listなど)に部分的にアクセスして新しいオブジェクトを生成する機能になります。
構文: 変数名[開始位置:終了位置:増分](この時、開始位置は「0」から始まります)
範囲外のインデックスが指定された場合、Python側で対応してくれます。
また、スライスによって生成されたオブジェクトは、インデックスの指定を行って上書きを行うことができません。
>>> sample = 'おはようございます。'
>>> sample[1:]
'はようございます。'
>>> sample[:1]
'お'
>>> sample[::1]
'おはようございます。'
>>> sample[2::2]
'よごいす'
>>> sample[::2]
'およごいす'
>>> sample[-5::2]
'ざま。'
>>> sample[1:-2]
'はようございま'
また、スライスは組み込み関数「slice」によってスライスオブジェクトを生成できます。
スライスオブジェクトを使うことで、複数のリストに同じ処理を行うことができます。
>>> a = 'YNYNYNYNYNY'
>>> b = 'NYNYNYNYNYN'
>>> sl = slice(0, 5, 2)
>>> a[sl]
'YYY'
>>> b[sl]
'NNN'
>>> sl = slice(0, None, 2) # 引数にNoneを使用すると省略できる
>>> a[sl]
'YYYYYY'
>>> b[sl]
'NNNNNN'
4.4.6. アンパック
Pythonでは、リスト型や辞書型に格納されたデータを複数の変数に一括して代入できます。
>>> l = [1, 2, 3]
>>> a, b, c = l
>>> print(a)
1
>>> print(b)
2
>>> print(c)
3
まとめ
Pythonの仕様が少しずつ見えてきたような気がします。
ボリュームが多いので、分割してまた投稿します。