6日目の記事で一旦挫折した @9wick です。
他の人の記事読んだり、中の人に質問したりしてだいぶ理解が進んだので、
リベンジとしてアウトプットしていきます。
そもそもの全体像
時系列解析 といっても2種類あります。
- 分類:特定の時系列データがどのカテゴリのものなのか判定する
- 予測:時系列データの未知の部分(未来部分?)を予測して補完する
1日目や2日目の記事で出てきたのは「分類」の方です。
「分類」をするときのながれについて
この部分、めっちゃ中の人にきいて教えてもらいました。
- 短い時間にデータを区切る(これが少時系列)
- 区切ったデータを分析にかける :特徴抽出(この時点ではまだ分類はできない)
- 分析して出てきた特徴を何個か合わせてまとめる
- まとめたデータに対して、分類を実施する
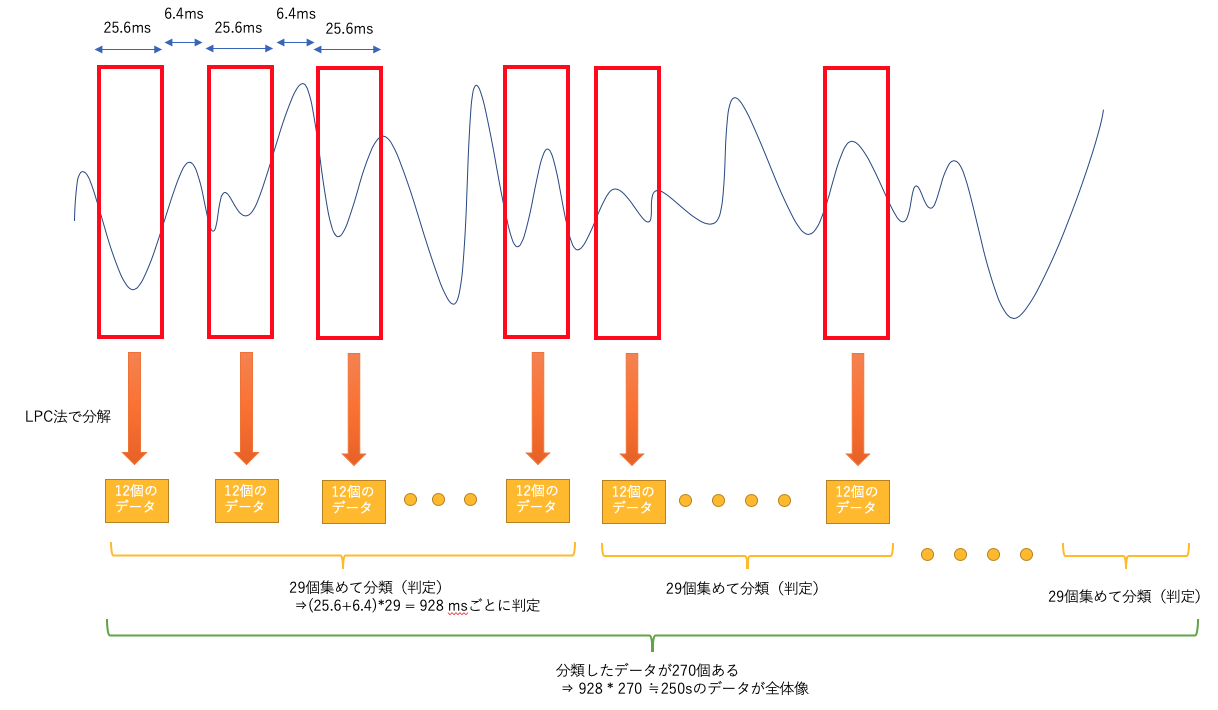
このフローに従って1日目の記事を図にするとこんな感じですね。
-
短い時間にデータを区切る(これが少時系列)
25.6msの単位で時間を区切っています。区切りの間に6.4msの間隔があるようです。(この間はあってもなくてもよい) -
区切ったデータを分析にかける :特徴抽出(この時点ではまだ分類はできない)
LCP法という方法で分析をしています。FFTとか、他の方法でも大丈夫なようです。
(たくさんありすぎて初心者的にはどれ選べばいいかわからない)
LCP法を実行した結果、12このデータが結果として出てきます。 -
分析して出てきた特徴を何個か合わせてまとめる
LCP方の結果を29個集めてます -
まとめたデータに対して、分類を実施する
あつめた29個のデータに対して分類を行います。なので、結果としては(25.6 + 6.4)*29=928msごとに分類を行っていることになります。
試してみる
だいぶ理解が深まったぞ!!! と思ったのですが、まだ自分で全部組み立てれるぐらいの理解はできていなかったので(トライしてまた挫折しました)、他の方のを見ながらやってみます。
具体的な手法が一番まとまってたのが13日目の記事 QoreSDKを使って筋トレ推定アプリを作っただったので、これを使って試してみます。
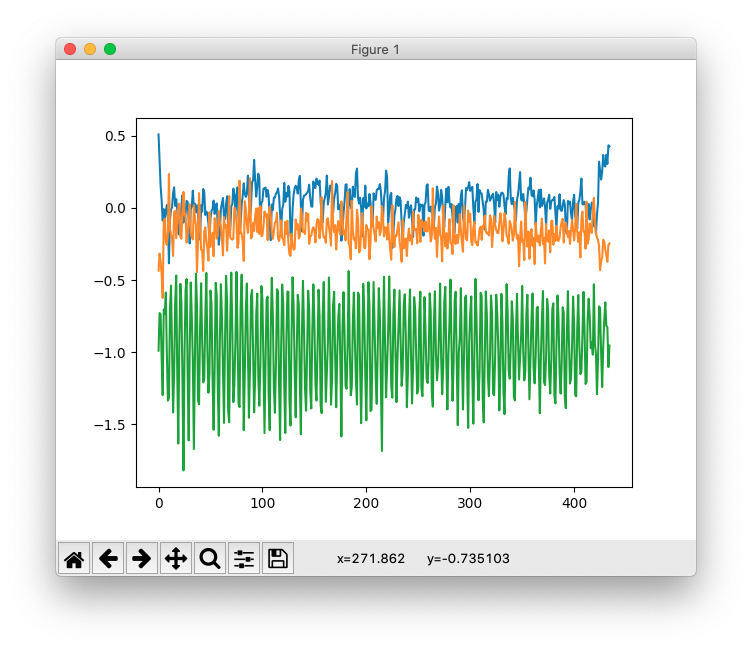
加速度をiPhoneアプリで撮っていたので、せっかくなので電車/歩きの加速度を撮ってみます。
歩いているとき
電車に乗っているとき
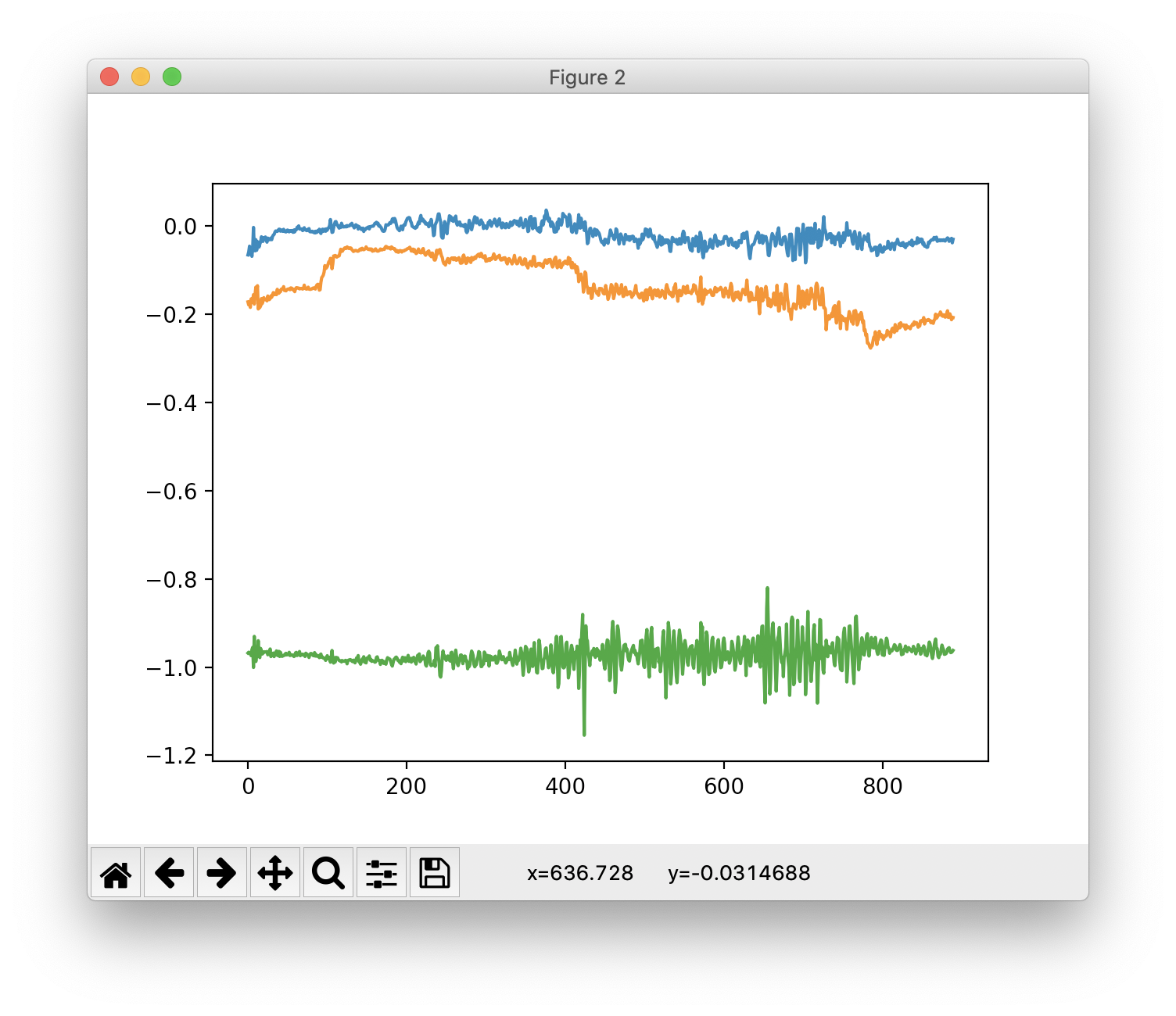
・・・・ちょっと明らかすぎますかね?
とりあえず、これでやってみました。
13日目の記事のgithubを多分に参考にさせてもらっています。
https://github.com/hnishi/muscle_QoreSDK_AdvCal2019/blob/master/muscle_QoreSDK.ipynb
上記githubのlist_dataのみ変更してやってみました
ぞれぞれのところのコード
他人のコードの解説になりますが、自分の頭で整理しないと絶対にわからなくなるので、
さっきの流れに沿って書いてみます。
1. 短い時間にデータを区切る(これが少時系列)
↓こんなイメージのデータが元データです。
array_loaded = [
[x1, y1, z1],
[x2, y2, z2],
[x3, y3, z3],
[x4, y4, z4],
.
.
.
]
array_label = [
1,
1,
1,
1,
.
.
.
] //array_loadedと同じ長さ
これを短い時間にデータを区切ります
X, y = qore_sdk.utils.sliding_window(array_loaded, width=100, stepsize=1, axis=0, y=array_label, y_def='mode')
widthやstepsizeによってサイズを変えれるようです
結果出てくるデータが下のようになります
X = [
[ [x1, y1, z1], [x2, y2, z2], [x3, y3, z3], .... (合計100個) ],
[ [x2, y2, z2], [x3, y3, z3], [x4, y4, z4], .... (合計100個) ],
[ [x3, y3, z3], [x4, y4, z4], [x5, y5, z5], .... (合計100個) ],
.
.
.
]
widthが100なので合計100個、stepsizeが1なので1こずつずれたデータができます。
2. 区切ったデータを分析にかける :特徴抽出(この時点ではまだ分類はできない)
n_filters = 40
featurizer = Featurizer(n_filters)
X = featurizer.featurize(X, axis=2)
n_filtersとaxisはよくわかってないのでそのままにしています。
おそらくaxis=2は2次元目のところがデータだよ ってことでしょうか?
これを実行すると下記のようなデータになります。
xyz3次元だったのが特徴データに変わってました。
X = [
[ [特徴データ(n_filters個分ある)], [特徴データ(n_filters個分ある)], .... (合計100個) ],
[ [特徴データ(n_filters個分ある)], [特徴データ(n_filters個分ある)], .... (合計100個) ],
[ [特徴データ(n_filters個分ある)], [特徴データ(n_filters個分ある)], .... (合計100個) ],
.
.
.
]
※ちょっと予想と違う動きでした。100*3個のデータで1この特徴データが出てくると思ってたら3個のデータに付き1個・・・。理解が足りないようなので後で調べます。
3. 分析して出てきた特徴を何個か合わせてまとめる
上のとおり、100この特徴データが配列に既になっているので、そのまま使います。
4. まとめたデータに対して、分類を実施する
SDKの使い方通りで、1関数なので問題なく実行します。
client = WebQoreClient(username=username,
password=password,
endpoint=endpoint)
start = time.time()
res = client.classifier_train(X=X_train, Y=y_train)
print(res)
実行結果
{'res': 'ok', 'train_time': 3.1520798206329346}
{'accuracy': 1.0, 'f1': 1.0, 'res': 'ok'}
100%判定!!
・・・そりゃわかるよねって気がしてちょっとひどかったので、電車の種類を当ててみます。
先程のやつは山手線に乗った時のデータだったので、こちらの東西線のデータを追加して試してみます。
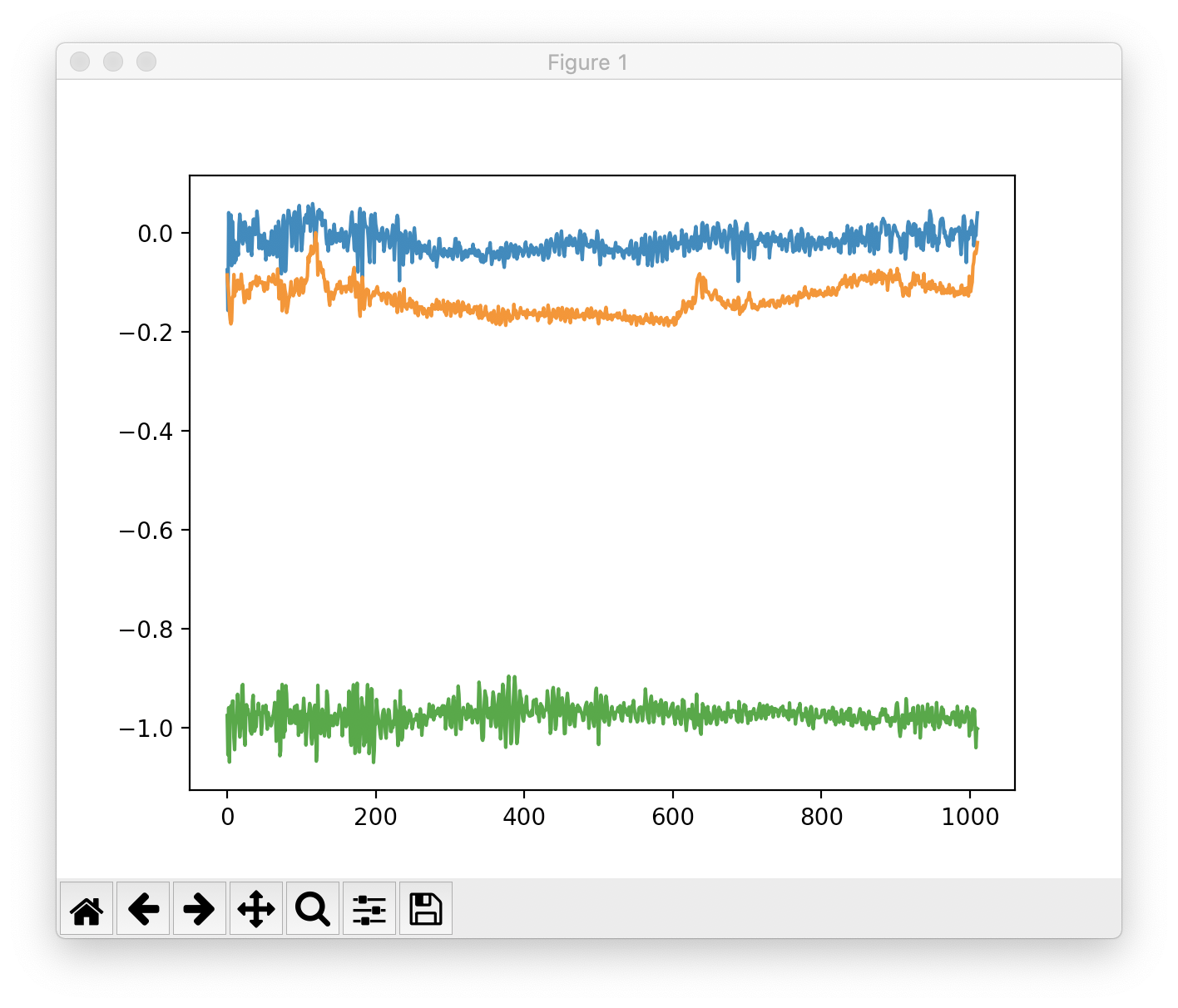
これなら人には判別できなそうですね。
QoreSDKでやってみると・・・
{'res': 'ok', 'train_time': 8.435135126113892}
{'accuracy': 0.7634069400630915, 'f1': 0.76461854436244, 'res': 'ok'}
76%
うーん、これが良いのか悪いのかはよくわかりませんが、素人が調整せず真似だけの割には高い気がします。Featurizerの設定を変えるか、もしくは違う特徴抽出手法にしたらもっと良くなるんだと思います。
まとめ
pythonできる機械学習系の人すごい