はじめに
AWS Athena を使用すると、Amazon S3 に格納したデータを対象に、
サーバーを一切構築することなく SQL による分析を行うことができます。
Athena はそのようなケースに最適なサービスで、
S3 上のデータに対して直接 SQL を実行できるため、
手軽にデータ分析を始めることができます。
本記事では、e-Stat が公開している人口データ(CSV)を例に
Athenaを使ったテーブル作成からクエリ実行までの基本操作 を解説します。
1.AWS Athenaとは
AWSが提供するサーバーレスの対話型クエリサービス。
Amazon S3上のデータを対象に標準SQLで直接分析でき、インフラ管理が不要なうえ
クエリ実行時のみ課金される従量課金制のサービスです。
ログ分析やBIツールとの連携に最適で、高速かつ簡単にデータ活用が可能となります。
2.事前準備
Atenaの操作の前に、以下のものを準備してください。
・S3バケット
・今回の作業に必要なIAMユーザー
・分析対象のCSVファイル
※CSVファイルですが、以下サイトより、男女別人口-全国,都道府県(大正9年~平成27年)のオープンデータを使用
https://www.e-stat.go.jp/stat-search/files?page=1&layout=datalist&toukei=00200521&tstat=000001011777&cycle=0&tclass1=000001094741&stat_infid=000031524010&tclass2val=0
3.データの格納
事前に準備したデータをS3バケットに格納する。
CSVの文字コードはUTF-8に指定しないとクエリの出力結果が、文字化けしてしまう恐れがあります。
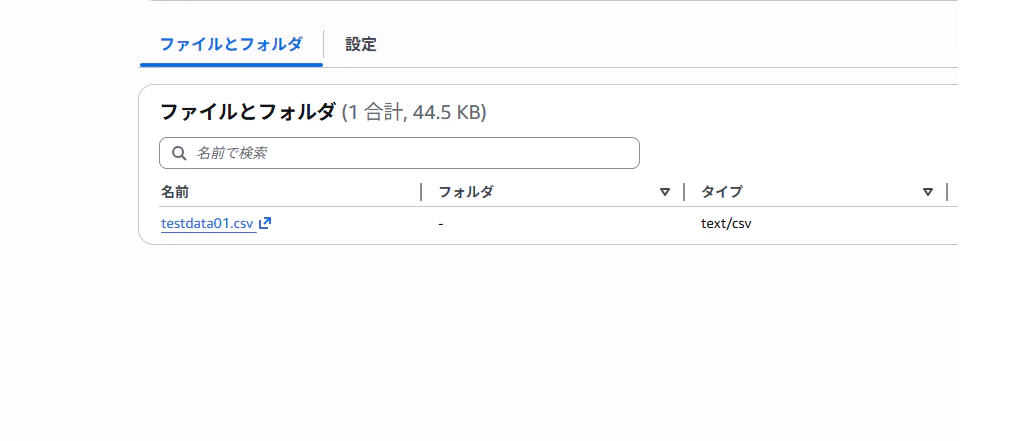
e-Stat のデータは様々なオープンデータが存在するため、Athena の練習用データとして非常におすすめです。
4.テーブルの作成
4-1.Athenaへ移動
AWSコンソールから、Athenaを検索し、「クエリエディタを選択」を押下してください。
「エディタ」タブを指定すると「クエリ」タブが確認できますので、そこにSQLを入力しますします。
4-2.SQLの入力
以下のSQLを入力して「実行」を押下します。
CREATE EXTERNAL TABLE population_by_prefecture (
prefecture_code string,
prefecture_name string,
era string,
wareki_year int,
year int,
population_total bigint,
population_male bigint,
population_female bigint
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
STORED AS TEXTFILE
LOCATION 's3://S3バケット名/パス/'
TBLPROPERTIES (
'skip.header.line.count'='1'
);
LOCATIONでは、CSV ファイルそのものではなく、CSV が格納されているフォルダ(S3 パス) を指定します。
クエリのステータスが「完了済み」になれば、テーブル作成は成功です。
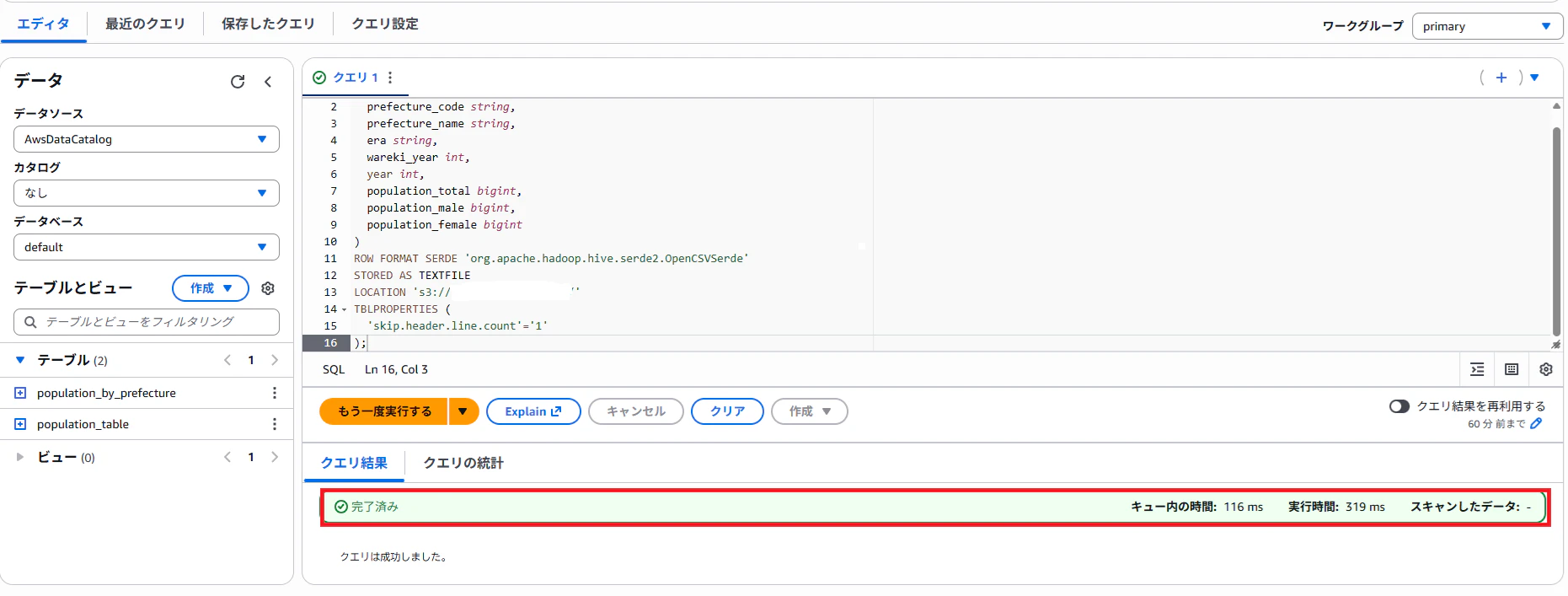
Athena の CREATE EXTERNAL TABLE は、S3 上のデータを「どのような構造で読むか」を定義しているだけであり、S3 上のデータ自体は変更されません。
5.クエリの作成
作成したテーブルに対し、いくつかクエリを実行します
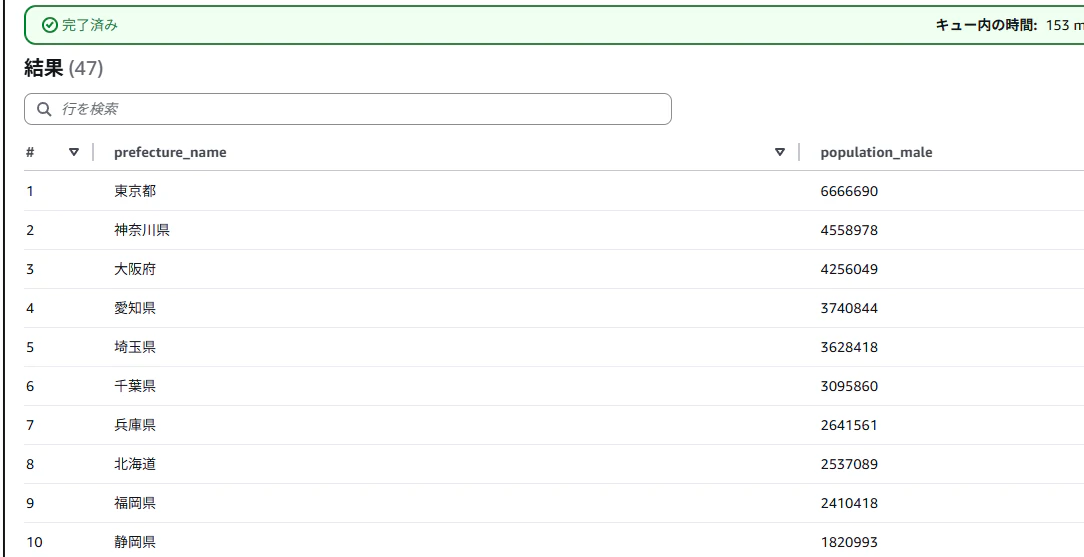
5-1.平成27年における各都道府県の男性人口を一覧表示
以下のSQLを実行します。
SELECT
prefecture_name,
population_male
FROM population_by_prefecture
WHERE era = '平成'
AND wareki_year = 27
AND prefecture_name NOT IN (
'全国',
'人口集中地区',
'人口集中地区以外の地区'
)
ORDER BY population_male DESC;
このクエリでは、下記の条件を元に男性人口が多い順に並べています。
・元号が 平成
・和暦年が 27 年
・都道府県以外の集計行(全国・人口集中地区など)を除外
正常に実行できると、都道府県別の男性人口ランキングが一覧で表示されます。
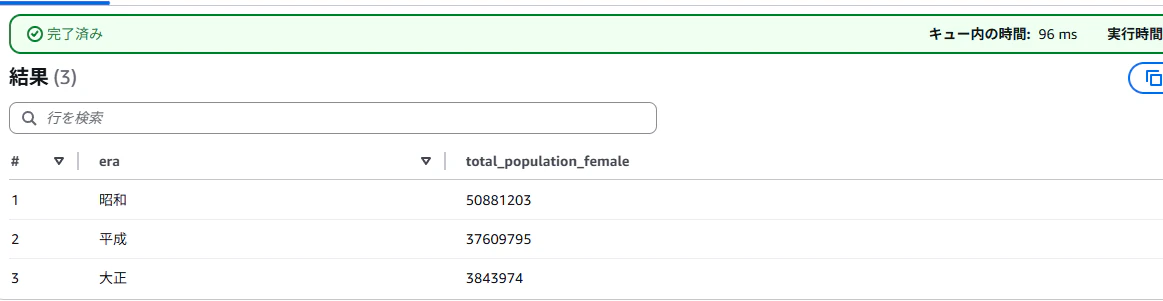
5-2.大正・昭和・平成ごとの東京の女性人口合計を表示
次に、東京都に限定し、元号ごとの女性人口の合計を確認します。
SELECT
era,
SUM(population_female) AS total_population_female
FROM population_by_prefecture
WHERE prefecture_name = '東京都'
AND era IN ('大正', '昭和', '平成')
GROUP BY era
ORDER BY total_population_female DESC;
正常な場合、「完了済み」のステータスが出力されます。
5-3.作成したテーブルの削除
4.テーブルの作成で作成したテーブルを削除します。
テーブル削除を実施
DROP TABLE population_by_prefecture;
正常な場合、「完了済み」のステータスが出力されます。
作成したテーブルを放置したままでも料金は発生しません。
ただし AWS は従量課金のサービスであるため、不要になったリソースは削除するよう心がけることが安全です。
6.おわりに
本記事では、AWS Athena を使って、以下の一連を実行しました。
・S3上に格納されたCSVデータを読み込み
・テーブルの作成
・SQL でデータ分析を行う
・テーブルの削除
Athena は設定がシンプルでポリシーの付与もいらないため、「とりあえず分析してみる」 という用途に非常に向いています。
※ただしS3に対してのポリシーは必要です
さらに、Athena のクエリ結果は、QuickSight などの BI ツールと連携して可視化することも可能です。
まずは今回のような CSV データを使って、Athena の操作に慣れてみてください。