はじめに
Azure上でデータのパイプラインを構築したい場合は Data Factory が真っ先に候補としてあがる。PaaSとして提供しているので管理が容易だし、実装もGUIベースで非常に簡単にできる。一方で Airflow は人気のOSSプロジェクトであり世界で広く使われている。Pythonでワークフローを構築していくという、Pythonに慣れている人にはたまらない一面もあるし、カスタムプラグインを書くことも可能なので、柔軟性も高い。
それぞれできることが似ているが、今のところ以下のような印象を持っている (違ってたらご指摘いただけるとありがたいです)。
- Data Factory・・・データのオーケストレーションやETL/ELTに主軸を置いている
- Airflow・・・汎用的なジョブスケジューラーのような印象がある
今回はApache Airflowを使って Azure Databricks のNotebookを実行する方法ついて調べてみた。
Apache Airflowとは
Airflowはワークフローを作ってスケジュール実行してモニタリングするためのプラットフォームで、ワークフローはPythonで記述する。Web UIを持っていてジョブの管理をグラフィカルな画面で行うことができるのも利点の一つ。実行エンジンをスケールアウトさせることができて、スケーラビリティが高い仕組みになっている。分散実行には Celery Executor というのが使用される。処理を実行するExecutorの役割を Kubernetes のpodで動かすこともできる。また、Providers packages を見ると多くのサードパーティとの統合が可能なのがわかる。今回はその中でも Databricks 用のOperatorを使ってジョブを実行するところを確認している。
Architecture
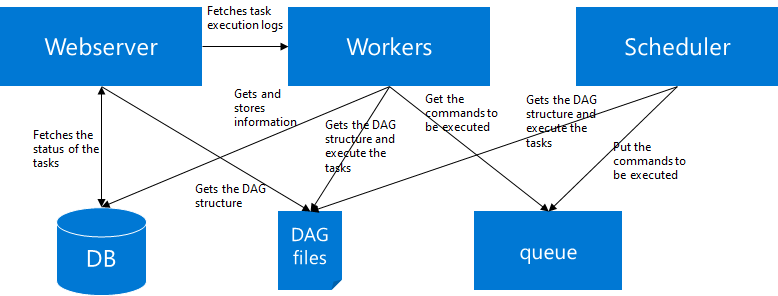
Airflowのアーキテクチャは下図のようになっている。各コンポーネントは役割を意味しており、実際のノードを意味していない。すべての役割を一つのノードで実行することもできるし、分けて実行することもできる。この図を描いた後にv2.0.0のドキュメントに Basic Airflow architecture としてダイアグラムが掲載されているのに気づいたが、おおよそ合っていると思う。
- Webserver
- いわゆる管理ポータル
- DAGの管理、スケジューリングやステータスの管理、接続の管理、トリガー実行などなど
- Scheduler
- DAGを監視してトリガーする。DAGファイルを書いて追加したり変更したときにSchedulerが動いていないと変更が反映されない
- Worker
- Schedulerがキューに入れたタスクを取り出して実行する。
- DB
- メタデータを格納するDB。デフォルトではSQLiteが使用されるが、MySQLやPostgreSQLを使用することもできる
DAG
DAG (Directed acyclic graph)
- 実行するタスクのコレクション。それらの依存関係を反映するように構成される
- Pythonでタスクとその依存関係を定義する
- airflow.cfgのDAG_FOLDERに指定されたフォルダ配下にDAGを記述したPythonスクリプトを置くとschedulerがそのDAGを登録する
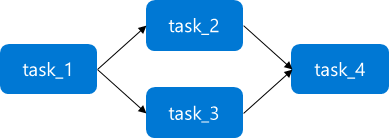
- 依存関係の表現は例えば以下のようになる (詳細はドキュメントに記載された DAGの概念 を参照
with DAG('my_dag', start_date=datetime(2016, 1, 1)) as dag:
task_1 = DummyOperator('task_1')
task_2 = DummyOperator('task_2')
task_3 = DummyOperator('task_3')
task_4 = DummyOperator('task_4')
task_1 >> [task_2, task_3] >> task_4 # Define dependencies
このように記述すると、タスクは下図のように編成される。
Azure上でAirflowを動かす方法
Azure上でAirflowを動かすためにはどのような方法があるだろうか。調べてみたところどうやら少なくとも下記の4つの方法がありそうだという事がわかった。
-
仮想マシンにマニュアルインストールして利用する
https://airflow.apache.org/docs/apache-airflow/stable/installation.html -
MarketplaceからBitnamiのソリューションをデプロイする
https://azure.microsoft.com/en-us/blog/bitnami-apache-airflow-multi-tier-now-available-in-azure-marketplace/ -
Azure QuickStart Templateを使ってContainer image on Linux Web AppとPostgreSQLにデプロイする
https://azure.microsoft.com/ja-jp/blog/deploying-apache-airflow-in-azure-to-build-and-run-data-pipelines/ -
BitnamiのHelm chartでAzure Kubernetesにデプロイする
https://docs.bitnami.com/tutorials/deploy-apache-airflow-azure-postgresql-redis/
今回試した環境は こちらの公式ドキュメント に従ってAzure VM (Standard D2s v3 (2 vcpus, 8 GiB memory), Ubuntu 18.04-LTS)にセットアップした。
VMへのセットアップ
セットアップは公式ドキュメントのとおり、シンプルにそのまま実行すれば完了する。
パッケージなどを最新にする
sudo apt-get update
sudo apt-get install build-essential
Airflowに必要なパッケージをインストールする
sudo apt-get install -y --no-install-recommends \
freetds-bin \
krb5-user \
ldap-utils \
libffi6 \
libsasl2-2 \
libsasl2-modules \
libssl1.1 \
locales \
lsb-release \
sasl2-bin \
sqlite3 \
unixodbc
この記事を書くちょっと前くらいに2.0.0がリリースされたが、試したのは1.10.14なのでこちらのバージョンで指定する
AIRFLOW_VERSION=1.10.14
PYTHON_VERSION="$(python3 --version | cut -d " " -f 2 | cut -d "." -f 1-2)"
CONSTRAINT_URL="https://raw.githubusercontent.com/apache/airflow/constraints-${AIRFLOW_VERSION}/constraints-${PYTHON_VERSION}.txt"
Airflowをインストールする
pip3 install "apache-airflow[azure]==${AIRFLOW_VERSION}" --constraint "${CONSTRAINT_URL}"
DBを初期化する。今回はローカルのSQLiteを使用。
# Set path in ~/.bashrc
PATH=$PATH:~/.local/bin
# Initialize DB (SQLite)
airflow db init
WebserverとSchedulerを起動する
airflow webserver -p 8080
airflow scheduler
Azure Databricksのジョブを実行する
これで準備が整ったので、いよいよAzure Databricksに接続してNotebookのジョブを実行してみる。
Azure Databricksユーザートークンの発行
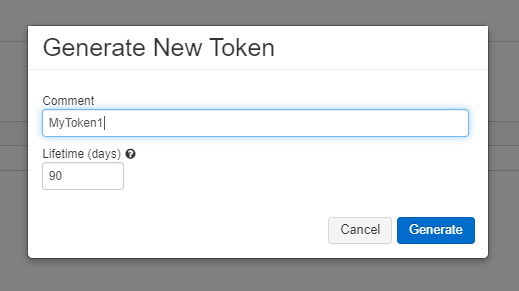
まずDatabricksに接続するために認証の情報を準備する。Databricksにアクセスして、ユーザートークンを発行する。
[User Settings] -> [Generate New Token] と進み、トークンを発行する。発行したトークンのキーは忘れずにメモすること。以下のドキュメントの通りの方法で実施している。
https://docs.microsoft.com/ja-jp/azure/databricks/dev-tools/api/latest/authentication
Airflowにトークンをセット
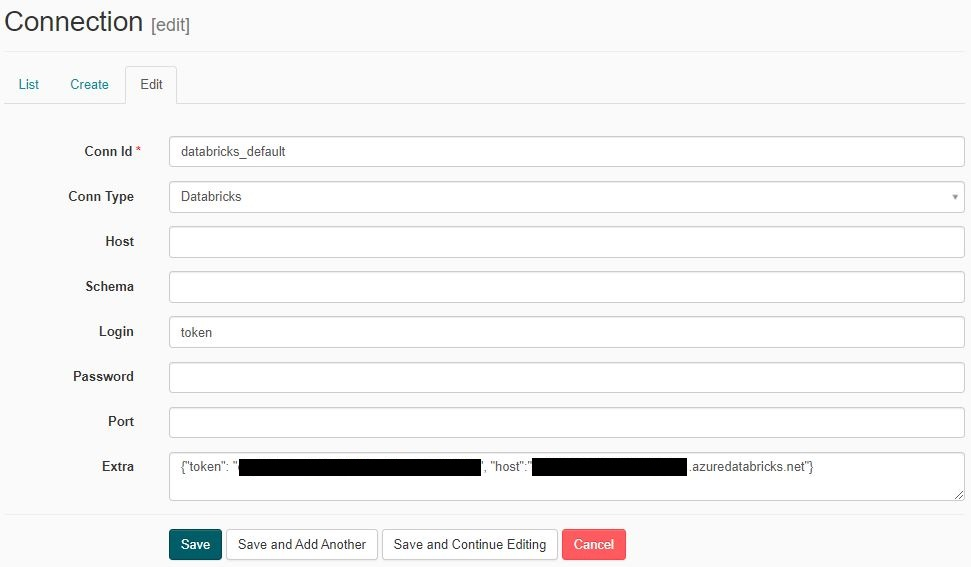
AirflowのWebserverにアクセスして、[Admin] -> [Connections] とたどるとその中に databricks_default という接続設定が見つかる。
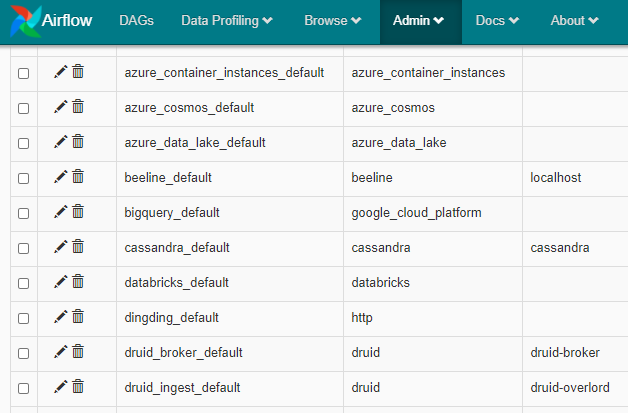
'databricks_default' の左側のペンのマークをクリックしてトークンを追加する。
Login 欄に "token", Extra 欄に {"token": "User token", "host": "Your Databricks host"} を入力してSaveする。下図を参照。
Data Lake Storage Gen2へのアクセス設定
Airflowとしては上記まででDatabricksアクセスの設定は完了だが、Notebookの中でData Lake Storage Gen2にアクセスしてデータを取得する処理を入れたかったので、その設定を追加する。
Databricksは Azure ADの資格情報のパススルーを使って簡単にADLSにアクセス することができるが、ジョブ実行の際にはこれがサポートされないため、サービスプリンシパルを使用する必要がある。
https://docs.microsoft.com/ja-jp/azure/databricks/data/data-sources/azure/azure-datalake-gen2#create-and-grant-permissions-to-service-principal
これには複数のステップを要するため、順を追ってメモする。
1. サービスプリンシパルを作成する
下記のドキュメントに従ってサービスプリンシパルを作成する。
https://docs.microsoft.com/ja-jp/azure/active-directory/develop/howto-create-service-principal-portal
※以前の記事に同様のものがあるのでこちらの通りに実施してもOK
Azure DatabricksからData Lake Storage Gen2をマウントする
下記が必要となる情報なので、メモしておく。
- Application ID
- Directory ID (Tenant ID)
- Client Secret
2. Databricksのsecretのscopeとsecretを作成する
以前の記事に同様のものがあるので、こちらに従って実施してもOK。今回はファイルシステムがすでに作成されているものとし、ファイルシステムのマウントも行わない方法で実施する。
Azure DatabricksからData Lake Storage Gen2をマウントする
databricks-cliがインストールされていない場合は下記コマンドでインストールする
pip3 install databricks-cli
Databricksホストとトークンを設定する。これを実行するとDatabricksのホスト(https://japaneast.azuredatabricks.net 等)とユーザートークンを聞かれるので入力する。
databricks configure --token
SecretのScopeを作成する
databricks secrets create-scope --scope <scope name> --initial-manage-principal users
Secretを作成する
databricks secrets put --scope <scope name> --key <key name>
3. Databricks Notebookを準備する
ADLSにサービスプリンシパルとOAuth 2.0を使用して直接アクセスするようにコードを記述。
dbutils.secrets.get(scope = "<scope-name>", key = "<key-name>")) の部分は先に作成したストレージ用のsecret情報を使う。
spark.conf.set("fs.azure.account.auth.type.<storage-account-name>.dfs.core.windows.net", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type.<storage-account-name>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id.<storage-account-name>.dfs.core.windows.net", "<application-id>")
spark.conf.set("fs.azure.account.oauth2.client.secret.<storage-account-name>.dfs.core.windows.net", dbutils.secrets.get(scope="<scope-name>",key="<service-credential-key-name>"))
spark.conf.set("fs.azure.account.oauth2.client.endpoint.<storage-account-name>.dfs.core.windows.net", "https://login.microsoftonline.com/<directory-id>/oauth2/token")
これで、DatabricksからADLSへのアクセスの準備完了となる。
AirflowのDAGを準備する
Databricks Integrationを使用するには、まずは下記のコマンドを使用してインストールする必要がある。
pip3 install "apache-airflow[databricks]"
airflow.cfgのDAG_FOLDERにしていされたフォルダにDAGファイルを作成する。標準だとdagsという名前のフォルダ名が設定されている。
今回はDatabricksジョブを実行するために以下のDAGを用意した。Databricks用には DatabricksRunNowOperator (Jobs APIの Run now に該当) と DatabricksSubmitRunOperator (Jobs APIの Runs submit に該当) がある。
example_databricks_runnow_operator.py
import airflow
from airflow import DAG
from airflow.contrib.operators.databricks_operator import DatabricksRunNowOperator
from datetime import datetime
# Default args
args = {
"owner": "airflow",
"email": ["airflow@example.com"],
"depends_on_past": False,
"start_date": airflow.utils.dates.days_ago(1)
}
# Databricksのジョブの結果をADLSに書き込むときのPATHとして使用する時間を取得
def get_hour (ts_nodash):
dt = datetime.strptime(ts_nodash, "%Y%m%dT%H%M%S")
hour = dt.hour
return str(hour)
# Create DAG
dag = DAG(dag_id="example_databricks_runnow_operator", default_args=args, user_defined_macros={'get_hour': get_hour}, schedule_interval="@hourly")
# DatabricksのJob ID 1番を実行する。Junja2テンプレートを使ってパラメータとしてcontextからYYYY-MM-DD形式の実行日と時間を渡す。
job_id=1
notebook_params = {
"date": "{{ ds }}" + "/" + "{{ get_hour(ts_nodash) }}"
}
# Create task with DatabricksRunNowOperator
notebook_task = DatabricksRunNowOperator(
job_id=job_id,
task_id="notebook_run",
notebook_params=notebook_params,
dag=dag
)
DatabricksSubmitRunOperator を使用すればDatabricks上でJobを作成しておく必要が無いのでこちらを使用したかったが、これを使うとジョブ完了後にExit code 1が返り、異常終了とみなされるようで、うまく解決できないまま DatabricksRunNowOperator に切り替えたらうまく動いた。
※原因および解決方法が不明なままなので、ご存知の方がいたら教えていただけると大変ありがたいです。
DatabricksのNotebookとJobを用意する
Databricksでパラメータを受け取って処理する簡単なNotebookを作成する。ADLSへのアクセス設定も含めてNotebookのコードは下記を使用した。
# ADLSにサービスプリンシパルとOAuth 2.0を使用して直接アクセスするための設定
spark.conf.set("fs.azure.account.auth.type.<storage-account-name>.dfs.core.windows.net", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type.<storage-account-name>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id.<storage-account-name>.dfs.core.windows.net", "<application-id>")
spark.conf.set("fs.azure.account.oauth2.client.secret.<storage-account-name>.dfs.core.windows.net", dbutils.secrets.get(scope="<scope-name>",key="<service-credential-key-name>"))
spark.conf.set("fs.azure.account.oauth2.client.endpoint.<storage-account-name>.dfs.core.windows.net", "https://login.microsoftonline.com/<directory-id>/oauth2/token")
# `dbutils.wigets.get("<Name>")` でパラメータを取得できる。Airflowからわたってきた `date` パラメータをここで受け取る
date = dbutils.widgets.get("date")
# ADLSのデータをDataFrameにロード
df = spark.read.csv("abfss://<filesystem name>@<storage account>.dfs.core.windows.net/AirflowTest/*.csv")
# パラメータで受け取った値を使って書き込み先のPATHを構築。今回は何も加工せずに書き込むだけのテスト
write_path = "abfss://<filesystem name>@<storage account>.dfs.core.windows.net/JobTest/data=" + date
# DataFrameをADLSにCSVで書き込み
df.write.save(write_path, format="csv")
実行してみる
テストのためマニュアルトリガーで実行する。
airflow dags trigger example_databricks_runnow_operator
[2020-12-19 09:19:03,694] {__init__.py:50} INFO - Using executor SequentialExecutor
[2020-12-19 09:19:03,695] {dagbag.py:417} INFO - Filling up the DagBag from /home/xxxx/airflow/dags/example_databricks_runnow_operator.py
Created <DagRun example_databricks_runnow_operator@ 2020-12-19 09:19:03+00:00: manual__2020-12-19T09:19:03+00:00, externally triggered: True>
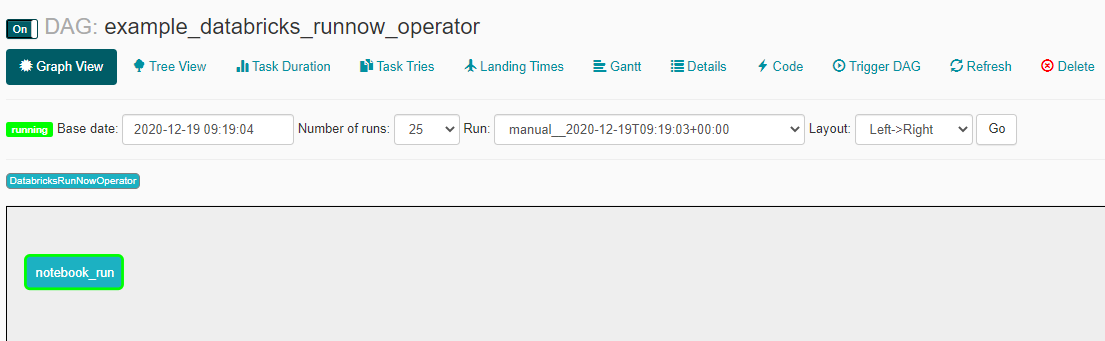
Webserverにアクセスして、DAGがトリガーされて running ステータスになることを確認
パラメータとして日付と時間が渡されていることを確認。
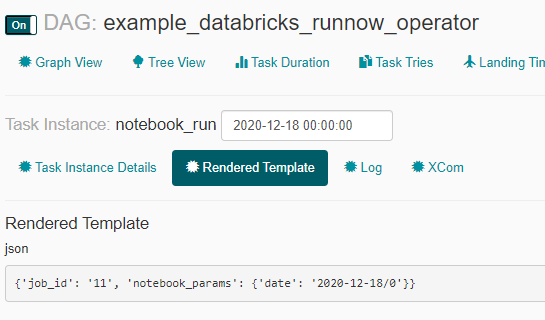
今回はTime zoneがUTCのままなのを直していないのでずれている。Timezoneについては下記のドキュメントに従って調整する必要がある。
https://airflow.apache.org/docs/apache-airflow/stable/timezone.html
まとめ
今回試したような処理はData Factoryを使用するともっと簡単に実装することができると思うが、AirflowでもDatabricksジョブを実行することができることが分かったので、この組み合わせでデータ変換などの処理の大部分は対応できることがわかった。その他IntegrationにおいてData FactoryがまだカバーできていないこともAirflowがカバーしているもの(例えばMulti-Cloudにおける相互のデータ書き込みなど)もあるので、例えばData Factoryの Web Activity で REST API を呼んでAirflowのDAGを起動するパイプラインを作ることで、Data Factoryの届かない範囲をカバーするなどなど、さらに調査していくと今後いろいろと有効なシナリオが見えてきそうだ。