はじめに
Azure Machine LearningはVNETテクノロジーでセキュリティ保護することができるが、複数のサービスが関連しているため、その構成は少し複雑だ。公式docを参照することでおおよそその意味しているところは理解できるが、実際に構築するとなるとそれなりにはまるような予感がするため、今回実際に試してみようと思う。ちなみに公式docを読んでの理解としては以下の通り。
- Machine Learning workspace自体はVNET内にデプロイすることができないが、Private Endpointを設定することでVNET経由でのアクセスに限定することはできる。
- Machine Learning Compute クラスターは通常の仮想マシン同様にVNET内にデプロイすることができる。
- 推論用のクラスター (ACI, AKS) はVNET内にデプロイすることができる。
- その他関連するサービス (Storage account, Key Vault, Container Registry) はService EndpointかPrivate Endpointでセキュアにすることができる。
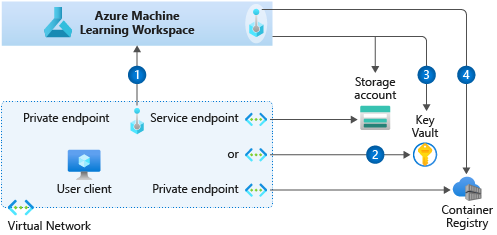
(From: https://docs.microsoft.com/ja-jp/azure/machine-learning/how-to-network-security-overview/)
また、同時にAzure DatabricksとMLFlowを使用してMachine LearningのexperimentをAzure Machine Learning workspaceにトラッキングして、モデルのデプロイまで試し、このようなVNET内での構成時に想定通りに動作することを確認してみようと思う。
今回作る構成について
上記をふまえたうえで今回作る構成は以下の通り。Azure Databricksをもろもろの処理の実行場所にしたかったため、Databricks + MLFlowを使用して、Machine Learning workspaceにトラッキングして、モデルを登録して、AKSにデプロイするという構成にした。
- Machine Learning関連のサービスをそれぞれ一つのVNETにデプロイする。
- 例えばComputeやScoring用のVNETが分かれていることは現時点ではサポートされていない。
- Azure Databricksも同じVNET内のサブネットにデプロイする。
- Key Vault, Storage, ACRに対してはService Endpointを利用する。
- 今回はDatabricksで処理を実行するのでMachine LearningのCompute Clusterは作成しない。
- 今回は推論クラスターはAKSを利用する。
- ACIはMachine LearningからのVNETデプロイに関して、VNETとMachine Learning workspaceが同一リソースグループ内でなければならないなどの制限がある。 (docを参照)

環境を構築する
az コマンドでリソースを作成していくが、先に定義した変数は後のコマンド実行時にも有効であるものとする。
Networkを作成する
今回は1つのVNETに5つのSubnetを作成する。
export MyResourceGroup="myRG"
export MyVnet="myVNET"
export VnetPrefix="10.100.0.0/16"
export location="japaneast"
# VNET and Subnet definition
export MLWSSubnet="ML-WS-Subnet"
export MLWSSubnetPrefix="10.100.100.0/24"
export MLComputeSubnet="ML-Compute-Subnet"
export MLComputeSubnetPrefix="10.100.110.0/24"
export MLScoringSubnet="ML-Scoring-Subnet"
export MLScoringSubnetPrefix="10.100.120.0/24"
export ADBPublicSubnet="ADB-Public-Subnet"
export ADBPublicSubnetPrefix="10.100.200.0/24"
export ADBPrivateSubnet="ADB-Private-Subnet"
export ADBPrivateSubnetPrefix="10.100.210.0/24"
# Create Resource Group
az group create -n $MyResourceGroup -l $location
# Create VNET
az network vnet create -g $MyResourceGroup -n $MyVnet --address-prefix $VnetPrefix
# Create Subnet for Machine Learning workspace private endpoint
az network vnet subnet create -g $MyResourceGroup --vnet-name $MyVnet -n $MLWSSubnet \
--address-prefixes $MLWSSubnetPrefix
# Create Subnet for Machine Learning Compute
az network vnet subnet create -g $MyResourceGroup --vnet-name $MyVnet -n $MLComputeSubnet \
--address-prefixes $MLComputeSubnetPrefix
# Create Subnet for Machine Learning Scoring
az network vnet subnet create -g $MyResourceGroup --vnet-name $MyVnet -n $MLScoringSubnet \
--address-prefixes $MLScoringSubnetPrefix
# Create Public Subnet for Databricks
az network vnet subnet create -g $MyResourceGroup --vnet-name $MyVnet -n $ADBPublicSubnet \
--address-prefixes $ADBPublicSubnetPrefix
# Create Private Subnet for Databricks
az network vnet subnet create -g $MyResourceGroup --vnet-name $MyVnet -n $ADBPrivateSubnet \
--address-prefixes $ADBPrivateSubnetPrefix
Machine Learning workspace作成に必要なリソースを作成
これらはMachine Learning workspaceを作成する際に自動で作成されるが、命名等を明確にしたい場合は今回の手順のように明示的に作成して紐づけする必要がある。
Container Registryの作成
# Container Registry name
export ACRName="myacr"
# Create Azure Container Registry
az acr create --resource-group $MyResourceGroup --name $ACRName --sku Basic --location $location
Application Insightsの作成
# Application Insights name
export AppInsightsName="myappinsights"
# Create Application Insights
az monitor app-insights component create --app $AppInsightsName --location $location --kind web -g $MyResourceGroup --application-type web --retention-time 120
Key Vaultの作成
# Key Vault name
export KVName="myamlkv"
# Create Key Vault
az keyvault create --name $KVName --resource-group $MyResourceGroup --location $location
ストレージの作成
# Storage Account name
export storageAccount="myamlstor"
# Create Storage Account
az storage account create \
--name $storageAccount \
--resource-group $MyResourceGroup \
--https-only true \
--kind StorageV2 \
--location $location \
--sku Standard_LRS
Machine LearningのPrivate Endpointのために対象サブネットのネットワークポリシーを無効にする
これを設定しないとMachine Learningのデプロイ時にPrivate Endpointの設定で失敗する。
# Private Endpoint for AML workspace
export PEName="myamlpe"
export PEResourceGroup="myRG"
export PEVnetName="myVNET"
export PESubnetName="ML-WS-Subnet"
# Disable network policies for a private endpoint
az network vnet subnet update \
--name $PESubnetName \
--resource-group $PEResourceGroup \
--vnet-name $PEVnetName \
--disable-private-endpoint-network-policies true
Azure Databricksを作成
Storageへのパススルー認証などを使用したかったためPremiumでデプロイ。
# Databricks name
export ADBWorkSpace="myadb"
# Create Azure Databricks
az databricks workspace create \
--resource-group $MyResourceGroup \
--name $ADBWorkSpace \
--location $location \
--sku premium \
--prepare-encryption \
--private-subnet $ADBPrivateSubnet \
--public-subnet $ADBPublicSubnet \
--vnet $MyVnet
Azure Machine Learning workspaceを作成
先に作成した関連リソースを紐づけた形でMachine Learningをデプロイする場合は、それぞれのリソースIDを指定する必要がある。
# Compose Resource ID
export SubscriptionID="XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX"
# Container Registry
export ACRID="/subscriptions/${SubscriptionID}/resourceGroups/${MyResourceGroup}/providers/Microsoft.ContainerRegistry/registries/${ACRName}"
# Application Insights
export AppInsightsID="/subscriptions/${SubscriptionID}/resourceGroups/${MyResourceGroup}/providers/Microsoft.Insights/components/${AppInsightsName}"
# Databricks link
export ADBWorkSpaceID="/subscriptions/${SubscriptionID}/resourceGroups/${MyResourceGroup}/providers/Microsoft.Databricks/workspaces/${ADBWorkSpace}"
# Key Vault
export KVID="/subscriptions/${SubscriptionID}/resourceGroups/${MyResourceGroup}/providers/Microsoft.KeyVault/vaults/${KVName}"
# Storage Account
export storageAccountID="/subscriptions/${SubscriptionID}/resourceGroups/${MyResourceGroup}/providers/Microsoft.Storage/storageAccounts/${storageAccount}"
# Machine Learning workspace name
export WorkspaceName="myamlworkspace"
# Create Machine Learning Workspace with Private Endpoint
az ml workspace create --workspace-name $WorkspaceName \
--adb-workspace $ADBWorkSpaceID \
--application-insights $AppInsightsID \
--container-registry $ACRID \
--keyvault $KVID \
--location $location \
--pe-name $PEName \
--pe-auto-approval \
--pe-resource-group $PEResourceGroup \
--pe-subnet-name $PESubnetName \
--pe-vnet-name $PEVnetName \
--resource-group $MyResourceGroup \
--sku basic \
--storage-account $storageAccountID
サービスエンドポイントを作成する
今回はStorage, Key Vault, ACRはサービスエンドポイントでセキュアにする方針のため、以下のコマンドで設定する。
az network vnet subnet update -g $MyResourceGroup --vnet-name $MyVnet -n $MLComputeSubnet --service-endpoints Microsoft.Storage Microsoft.KeyVault Microsoft.ContainerRegistry
az network vnet subnet update -g $MyResourceGroup --vnet-name $MyVnet -n $MLScoringSubnet --service-endpoints Microsoft.Storage Microsoft.KeyVault Microsoft.ContainerRegistry
az network vnet subnet update -g $MyResourceGroup --vnet-name $MyVnet -n $ADBPublicSubnet --service-endpoints Microsoft.Storage Microsoft.KeyVault Microsoft.ContainerRegistry
az network vnet subnet update -g $MyResourceGroup --vnet-name $MyVnet -n $ADBPrivateSubnet --service-endpoints Microsoft.Storage Microsoft.KeyVault Microsoft.ContainerRegistry
NSGを設定する
各サブネットに適切なNSG設定する。基本的にVNET外からのインバウンドをブロックし、VPNやBastionなどを使用したセキュアアクセスの入り口を構築するのがよさそう。下記を参考に今後試す予定。
https://github.com/jhirono/amlsecurity
Machine Learning Studioへのアクセス確認
VNETデプロイにより外部からのアクセスができなくなっていることを確認するために、Machine Learning StudioにVNET外からアクセスしてみたところ、アクセスすることはできた。トップ画面にアクセスした場合は通常通りの画面が表示されるが、各種メニューにアクセスを試みると、その中の情報を表示することができなくなっている。以下は Experiments にアクセスした際のエラー表示である。
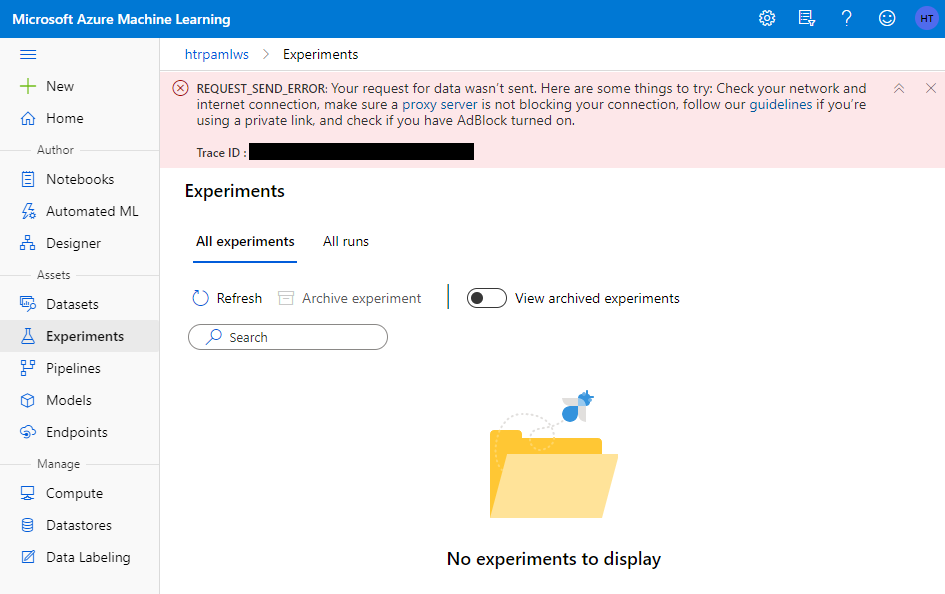
これは想像だが、Machine Learning Studio自体は共用のWeb画面のためアクセスはできるが、各workspace固有のAssetsなどにアクセスする際にアクセス元のネットワークを評価してコンテンツを取得するかどうかを判断しているのだろうか。いずれにしてもVNET内からMachine Learning Studioにアクセスした場合には問題なく表示されたので、VNETデプロイは成功したと考えられる。
MLFlowによるTracking
ライブラリのインストール
Databricksクラスターを作成し、 azureml-mlflow ライブラリを Pypi からインストールする。
インストールすると以下のようにクラスターのライブラリタブに表示される。
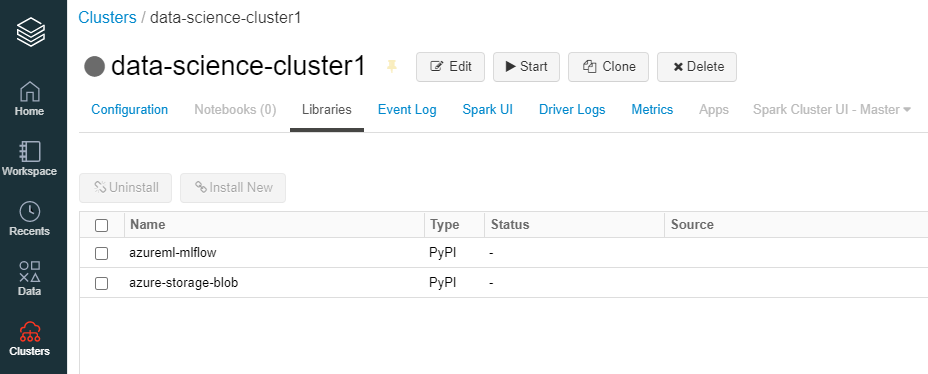
Notebookの作成
以下の例を参考にDatabricks Notebook上でMLFlow Trackingを実行していく。
https://docs.microsoft.com/ja-jp/azure/machine-learning/how-to-use-mlflow-azure-databricks
解説のためコードを分割しているが、実際にはすべて一つのNotebook上で実行するものとする。
Machine Learning workspaceへの接続
通常のMachine LearningのSDKを使用する場合と同じく、まずはworkspaceに接続する。使用中のAzure ADの Tenant ID (Directory ID), サブスクリプション ID, Machine Learningの リソースグループ名, Machine Learningの ワークスペース名, Databricksの Notebook名 を指定してデバイスログインを実行する。
import mlflow
import mlflow.azureml
import azureml.mlflow
import azureml.core
from azureml.core import Workspace
from azureml.core.authentication import InteractiveLoginAuthentication
interactive_auth = InteractiveLoginAuthentication(tenant_id="<Your Tenant ID>")
subscription_id = '<Your Subscription ID>'
# Azure Machine Learning resource group NOT the managed resource group
resource_group = '<Your Resource Group>'
# Azure Machine Learning workspace name, NOT Azure Databricks workspace
workspace_name = '<Your Machine Learning workspace name>'
# Instantiate Azure Machine Learning workspace
ws = Workspace.get(name=workspace_name,
subscription_id=subscription_id,
resource_group=resource_group)
# Set MLflow experiment.
experimentName = "<Path to Notebook>"
mlflow.set_experiment(experimentName)
上記を実行すると、以下のようにNotebookの実行結果にURLとコードが表示されるので、これらを使用してデバイスログインを実行する。ボーっとしているとこの表示に気づきにくい。

DatabricksもMachine Learning workspaceもVNET用に構成されているので、ここで問題なくworkspaceにアクセスでき、今後の作業が滞りなく動作することになる。
ちなみに今回のVNETの外にいるDatabricksからMachine Learning workspaceにアクセスを試してみたところ、デバイスログインは成功したが、その後の操作が 403 Forbidden となり拒否される動作になるようだ。以下のエラーはexperimentを作成しようとしたときにエラーになった例。

Trackingの設定
以下を実行して、Machine Learning workspaceでのみTrackingするように設定する。
uri = ws.get_mlflow_tracking_uri()
mlflow.set_tracking_uri(uri)
Experimentの作成
Experiment名を指定する。既存のものがなければ新規作成され、既に存在している場合はそのExperiment内で実行される。
experiment_name = "experiment-with-mlflow-1"
mlflow.set_experiment(experiment_name)
データセット作成
トレーニングとテスト用のデータセットを作成する。ここでは糖尿病データセットを使用して単純な回帰モデルを構築する。
import numpy as np
from sklearn.datasets import load_diabetes
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
X, y = load_diabetes(return_X_y = True)
columns = ['age', 'gender', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
data = {
"train":{"X": X_train, "y": y_train},
"test":{"X": X_test, "y": y_test}
}
print ("Data contains", len(data['train']['X']), "training samples and",len(data['test']['X']), "test samples")
モデルのトレーニングと、metricsとartifactsのtracking
-
with mlflow.start_run()でMLFlowによるtrackingを開始する。 -
mlflow.log_metric('alpha', 0.03),mlflow.log_metric('mse', mean_squared_error(data['test']['y'], preds))でmetricとして値を保存。 -
mlflow.sklearn.log_model(regression_model,model_save_path)でモデルを保存。 -
mlflow.log_artifact("actuals_vs_predictions.png")でartifactとしてチャートを保存。
import matplotlib.pyplot as plt
# Create a run object in the experiment
model_save_path = "model"
with mlflow.start_run() as run:
# Log the algorithm parameter alpha to the run
mlflow.log_metric('alpha', 0.03)
# Create, fit, and test the scikit-learn Ridge regression model
regression_model = Ridge(alpha=0.03)
regression_model.fit(data['train']['X'], data['train']['y'])
preds = regression_model.predict(data['test']['X'])
# Log mean squared error
print('Mean Squared Error is', mean_squared_error(data['test']['y'], preds))
mlflow.log_metric('mse', mean_squared_error(data['test']['y'], preds))
# Save the model to the outputs directory for capture
mlflow.sklearn.log_model(regression_model,model_save_path)
# Plot actuals vs predictions and save the plot within the run
fig = plt.figure(1)
idx = np.argsort(data['test']['y'])
plt.plot(data['test']['y'][idx],preds[idx])
fig.savefig("actuals_vs_predictions.png")
mlflow.log_artifact("actuals_vs_predictions.png")
ここでのチャートは以下のようになった。

推論クラスターとしてAKSを作成
今回AKSのエンドポイントをPrivateに閉じずにPublic IPでアクセスできるようにしたが、Privateに閉じる方法も今後試してみたい。
Machine Learning Studioから Compute -> Infence clusters -> +New と進み、以下のようにAKSをデプロイする。
- VNET, Subnetは事前に作成したものを指定する。
-
Kubernetes Servie address rangeはSubnetと被らないIPレンジを指定する。 -
Kubernetes DNS Serviec IP addressは上記のKubernetes Service address range内のIPを指定する。

トレーニング済みのモデルを登録
モデルのURLとモデル名を設定して実行する、モデルのURLにおける run_id はMachine Learning studioのExperimentsから見つけることができる。
model_pathの値は、モデルのトレーニング時に model_save_path = "model" として指定したものを指定する。この場合は "model" を指定。
model_url = "runs:/{run_id}/{model_path}"
model_name = "{model_name}"
result=mlflow.register_model(model_url, model_name)
AKSへのデプロイ
登録したモデルをAKSにデプロイする。
compute_target_name の値は事前にデプロイしたAKSの名前と一致しなければならない。
from azureml.core.webservice import AksWebservice, Webservice
from azureml.core.environment import Environment
from azureml.core.model import Model
# Set the web service configuration (using default here with app insights)
aks_config = AksWebservice.deploy_configuration(enable_app_insights=True, compute_target_name='{AKS Name}')
(webservice, model) = mlflow.azureml.deploy(model_uri=model_url,
workspace=ws,
model_name=model_name,
service_name='my-service',
deployment_config=aks_config,
tags=None, mlflow_home=None, synchronous=True)
webservice.wait_for_deployment()
デプロイが成功すると、以下のようにデプロイ完了のメッセージが表示される。

推論を実行する
デプロイまで完了したので、いったん今回の目的は概ね果たせたが、最後に念のため推論が動作するかどうかを簡単に確認してみる。
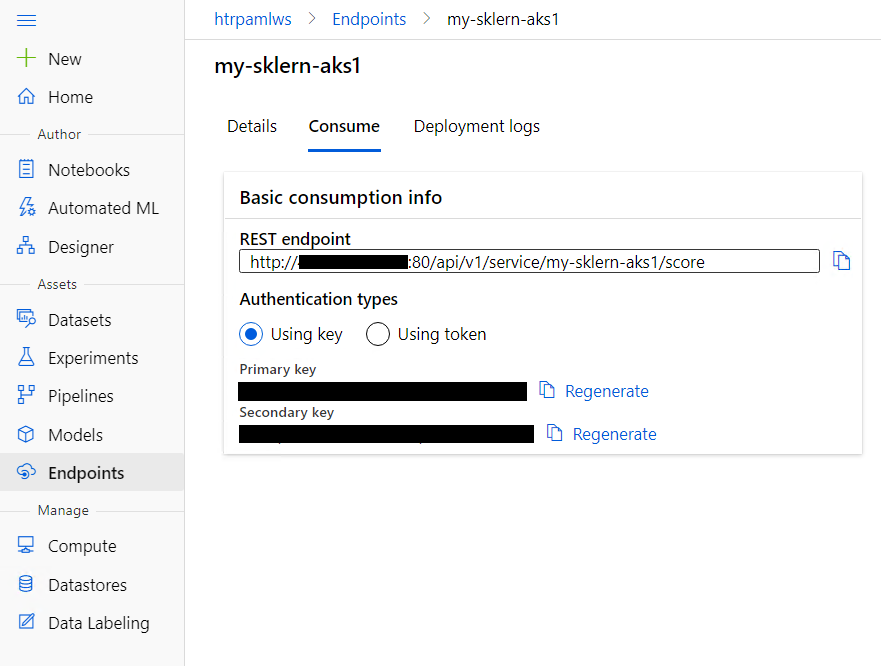
RESTのエンドポイントとKeyの取得
Machine Learning Studioから Endpoints -> (作成したサービス名) -> Consume と進むと以下のようにREST APIのエンドポイントとキーを取得できる。今回はPublic Endpointとしてデプロイしているが、完全なPrivate IPのEndpointをもったAKSも今後試して、ここに追記しようと考えている。
APIリクエストを送信
エンドポイントと認証設定
ここではPostmanを使用してPOSTリクエストを送信する。
以下のようにエンドポイントURLを指定し、 POST リクエストとして設定する。
認証は Bearer Token を選択し、 Token 欄にMachine Learning Studioで確認したKeyを張り付ける。

データの準備
予測させたいデータを準備する。JSON形式で以下のように data フィールドにネストされたリストで、必要なデータを並べる。
{"data":
[
[
0.01991321,
0.05068012,
0.10480869,
0.07007254,
-0.03596778,
-0.0266789,
-0.02499266,
-0.00259226,
0.00371174,
0.04034337
],
[
-0.01277963,
-0.04464164,
0.06061839,
0.05285819,
0.04796534,
0.02937467,
-0.01762938,
0.03430886,
0.0702113,
0.00720652
],
[
0.03807591,
0.05068012,
0.00888341,
0.04252958,
-0.04284755,
-0.02104223,
-0.03971921,
-0.00259226,
-0.01811827,
0.00720652
]
]
}
このデータをPostmanでBodyにセットし、 raw の JSON 形式を指定する。
Bodyのセットが完了したら Send を押して結果を確認する。今回3パターンのテストデータを投げたので、3つの結果が返ってきていることが分かる。

まとめ
VNET deploymentについて
Azure Machine Learningの環境をVNETでセキュアにする方法を実際にハンズオンとして試してみたが、やはりそれなりに躓きポイントがあり時間を要した。今後解消されていく可能性はもちろんあるが、現時点で制約事項がいくつかあり、ドキュメントを読んだだけでは設計時に見落とす可能性があると感じた。今回実際に何度も躓いたことで制約事項や設計時に考慮しなければならない点を理解できた。さらに、Machine Learning workspaceをVNET外からのアクセスから保護できることはわかっていたが、実際の挙動 (VNET外からでもStudioにはアクセスできるが、中身が表示されないことや、VNET外からでもSDKを使用してMachine Learning workspaceに接続することはできるが、操作が許可されない) についてよく理解できた。いずれにしてもMachine Learningの環境をよりセキュアにする方法として非常に重要な手段なので基本的には利用すべきだろう。
DatabricksとMachine LearningのMLFlow trackingについて
MLFlowを使用してDatabricksからMachine Learning workspaceにTrackingした。今回のような少ないデータでシンプルscikit-learnを使用した機械学習のケースであればDatabricksをあえて使う必要はないようにも見えるが、やはりSparkを使ったデータエンジニアリングは非常に強力なため、大量のデータを使用する場合にデータの変換などとのコンビネーションの中でモデル構築やデプロイまで一貫して実行したい場合などには有効ではないかなと感じた。また、Databricks単体でもMLFlowを使用して管理していくこともできるし、推論用のエンドポイントも持つこともできるが、今回はAKSへのデプロイまでシームレスに実施してみたかったのでDatabricks単体の方法は選ばなかった。今回取った方法を実際の運用で考えてみると、Databricksを使用する場合も、Machine Learning serviceを直接使用する場合も、どちらもMLFlowでMachine Learning workspaceにデータを集約することができるので、ツールなどの好みに関わらず一元管理することができるのはメリットになるかもしれない。