はじめに
Azure Data FactoryでのCI/CDの環境を実装したので、その方法と実装にあたってキーとなるポイントをここにメモする。Data FactoryでのCI/CDはData Factoryのパイプラインをある環境(開発環境など)から別の環境に(テスト環境や本番環境など)に展開することを意味する。Data FactoryはResource ManagerテンプレートでData Factory内部のエンティティを保存するため、これを他の環境に展開することで動作させることができるということになる。
Resource Managerテンプレートを手動で展開する方法と、Azure DevOpsのPipelinesを使用して自動的にデプロイする方法があるが、この記事では自動的にデプロイする方法を対象とする。
Data FactoryのGit統合とCI/CD
Data Factoryは現在LiveとGit統合の2つのモードをサポートしている。Git統合をすることによって以下のメリットがある。
- ソース管理
- 変更の追跡と監査の機能
-バグの原因となっている変更を元に戻す機能
- 変更の追跡と監査の機能
- コラボレーション
- コードレビューのプロセスを通じてチームメイトが相互に協力して作業
- 開発と変更のデプロイの権限を分離
- CI/CD
- リリースパイプラインを使用して変更がすぐに発行される仕組みを構築することができる
- 途中保存
- 変更を差分の形で保存していき、準備が整った時点でData Factoryに公開。Gitが作業が作業のステージングの場としての役割となる
- 差分の表示
- 前回Data Factoryに公開した時点から変更、追加、削除のあったリソースやエンティティがすべて表示される
構成の概要
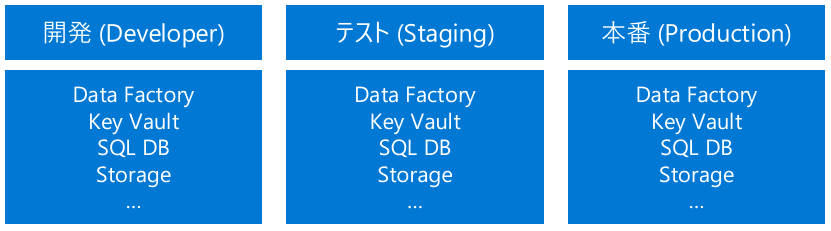
先に述べたように、Data FactoryでのCI/CDは、Data Factoryのパイプラインをある環境(開発環境など)から別の環境に(テスト環境や本番環境など)に展開することを意味する。例えば下図のように、開発(Developer)、テスト(Staging)、本番(Production)といった形で3つの異なるData Factoryの環境を用意して、開発環境からテストや本番環境に変更を展開する構成が代表的なものとして挙げられる。この後で触れることになるが、Gitとの統合は開発環境のData Factoryのみ行い、それ以外の環境には紐づけず、リリースパイプラインによってのみコードを展開する。そうすることによって、テストや本番環境のコードを直接更新することを避けることができる。

環境設定方法
Data FactoryでのCI/CD構成の方針
- 開発用のData FactoryのみにGitとの接続を行う。これはAzure DevOpsのReposまたはGitHubが利用可能。
- 開発者または領域などごとにブランチを作成する。開発者ごとのブランチにより、公開されているプロセスのバージョンに影響を与えることなく変更を加えることができる。
- コラボレーションブランチにコードを反映する前に、Pull Requestを作成してレビューされる必要がある。
- 例
- コラボレーションブランチ: main
- 開発ブランチ : ユーザー名-xxx, feature-xxx, etc
CI/CDのためのAzureリソース
リソース環境設計
Data Factoryの環境だけでなく、クレデンシャルを保存するKey Vaultやデータソースとなるサービスも同じ構成で各環境ごとにセットで用意しておくことが推奨。こうすることによってすべての環境で同じ動作を確認することができる。すべてのリソースが同じセットとして用意され、リソース名が規則に従って異なる、という環境にすると良い。
リソースのデプロイメント
実際のリソースのデプロイは再現性を持たせるために、以下のようにAzure CLIを使用したスクリプトを作成してデプロイした。今回のテストではすべてを一つのリソースグループにまとめているが、管理者の権限のことを考慮してそれぞれ別のリソースグループにしたほうが良いかもしれない。基本的にはData Factoryにコードを発行する権限を持つためには、リソースグループレベルで Data Factory contributorロールを必要とするため、リソースグループを分けることで管理できる範囲を制限することは良いアイデアのように思う。しかし一つのリソースグループを使用する場合にこのことを回避する方法もある。次のロールのセクションでそれについて説明している。
サンプルのデプロイスクリプト
#!/bin/bash
# Env variables
export subscriptionId="xxxxxxxxxx"
export resourceGroupName="your resource group name"
export location="your favorite region"
export devFactoryName="adf name for dev"
export stgFactoryName="adf name for stg"
export prodFactoryName="adf name for prod"
export devKvName="key vault name for dev"
export stgKvName="key vault name for stg"
export prodKvName="key vault name for prod"
export sqlserver="sql server name to host sql dbs"
export sqlAdminUser="sql admin user name"
export sqlAdminPassword="sql admin user password"
export devDatabaseName="sql db name for dev"
export stgDatabaseName="sql db name for stg"
export prodDatabaseName="sql db name for prod"
export devStorageAccount="storage account name for dev"
export stgStorageAccount="storage account name for stg"
export prodStorageAccount="storage account name for prod"
export AdlsFSName="file system name"
# Resource Group
az group create --name $resourceGroupName --location $location
# Data Factory
## Create Data Factory for Dev
az datafactory factory create --resource-group $resourceGroupName --factory-name $devFactoryName --location $location
## Create Data Factory for Staging
az datafactory factory create --resource-group $resourceGroupName --factory-name $stgFactoryName --location $location
## Create Data Factory for Production
az datafactory factory create --resource-group $resourceGroupName --factory-name $prodFactoryName --location $location
# Key Vault
## Create Key Vault for Dev
az keyvault create --name $devKvName --resource-group $resourceGroupName --location $location
## Create Key Vault for Staging
az keyvault create --name $stgKvName --resource-group $resourceGroupName --location $location
## Create Key Vault for Production
az keyvault create --name $prodKvName --resource-group $resourceGroupName --location $location
# SQL Database
## Create SQL Server
az sql server create \
--name $sqlserver \
--resource-group $resourceGroupName \
--location $location \
--admin-user $sqlAdminUser \
--admin-password $sqlAdminPassword
## Create Firewall rule - allow Azure access
az sql server firewall-rule create \
--resource-group $resourceGroupName \
--server $sqlserver \
-n AllowYourIp --start-ip-address 0.0.0.0 --end-ip-address 0.0.0.0
## Create SQL Database for Dev environment
az sql db create \
--resource-group $resourceGroupName \
--server $sqlserver --name $devDatabaseName \
--sample-name AdventureWorksLT \
--edition GeneralPurpose \
--compute-mode Serverless \
--family Gen5 \
--capacity 2 \
--auto-pause-delay 60
## Create SQL Database for Staging environment
az sql db create \
--resource-group $resourceGroupName \
--server $sqlserver \
--name $stgDatabaseName \
--sample-name AdventureWorksLT \
--edition GeneralPurpose \
--compute-mode Serverless \
--family Gen5 \
--capacity 2 \
--auto-pause-delay 60
## Create SQL Database for Production environment
az sql db create \
--resource-group $resourceGroupName \
--server $sqlserver \
--name $prodDatabaseName \
--sample-name AdventureWorksLT \
--edition GeneralPurpose \
--compute-mode Serverless \
--family Gen5 \
--capacity 2 \
--auto-pause-delay 60
# Storage Account
## Create data lake storage gen2 account for Dev
az storage account create \
--name $devStorageAccount \
--resource-group $resourceGroupName \
--https-only true \
--kind StorageV2 \
--location $location \
--sku Standard_LRS \
--enable-hierarchical-namespace true
## Create filesystem for Dev
az storage fs create -n $AdlsFSName \
--account-name $devStorageAccount \
--auth-mode login
## Create data lake storage gen2 account for Staging
az storage account create \
--name $stgStorageAccount \
--resource-group $resourceGroupName \
--https-only true \
--kind StorageV2 \
--location $location \
--sku Standard_LRS \
--enable-hierarchical-namespace true
## Create filesystem for Staging
az storage fs create -n $AdlsFSName \
--account-name $stgStorageAccount \
--auth-mode login
## Create data lake storage gen2 account for Production
az storage account create \
--name $prodStorageAccount \
--resource-group $resourceGroupName \
--https-only true \
--kind StorageV2 \
--location $location \
--sku Standard_LRS \
--enable-hierarchical-namespace true
## Create filesystem for Production
az storage fs create -n $AdlsFSName \
--account-name $prodStorageAccount \
--auth-mode login
Git統合
Gitリポジトリは開発用のData Factory用に一つ準備する。Data FactoryではAzure DevOpsまたはGitHubが利用可能。この記事の例ではAzure DevOpsを使用している。Gitリポジトリの準備に関してはドキュメントの通りに作成可能。Gitの準備ができたら、開発用Data Factoryで以下のようにGit統合の設定をする。

ロール
Azure ReposやGitHubのパーミッションはData Factoryのパーミッションとは独立している。基本的にはすべてのメンバーがData Factoryをアップデートできる権限を持つ必要はない。何人かの許可されたメンバーだけがGit経由でData Factoryに変更を加えることができればよい。以下がベースとなるガイドラインになる。
- すべてのメンバーは少なくとも
readパーミッションを持つ。- Data Factoryに対して
read権限しかない場合でもGitを使用したブランチへの変更およびPull Requestの作成が可能。Data Factoryに対する直接の編集権限を持たないということを意味する。
- Data Factoryに対して
- いくつかのメンバーがData Factoryに発行できるようにするために、
Data Factory contributorロールをリソースグループレベルに持たせる必要がある。- 先に述べたように、リソースグループレベルでロールを割り当てるため、他のData Factoryが同じリソースグループに存在する場合には、そのData Factoryに対する発行の権限を与えてしまうことになる。これを避けるために以下の回避策が提唱されている。
- ビルトインの
Contributorロールを該当のData Factoryに対してアサインする -
Microsoft.Resources/deployments/パーミッションを含むカスタムロールを作成してリソースグループレベルでユーザーにアサインする
- ビルトインの
- 先に述べたように、リソースグループレベルでロールを割り当てるため、他のData Factoryが同じリソースグループに存在する場合には、そのData Factoryに対する発行の権限を与えてしまうことになる。これを避けるために以下の回避策が提唱されている。
もう一つ大事なこととして、コラボレーションブランチ(mainなど)に開発者が直接変更を適用できないようにしておくと安全である。例えばAzure DevOpsであれば以下の図のように Require a minimum number of reviewers を設定することで直接の変更を拒否することができる。

CI/CDの自動化
Data FactoryのCI/CDを自動化するための方法としては以下の2つが公式ドキュメントでガイドされている。
1. 従来からののCI/CDのフロー
Data FactoryのUIで Publish して発行用のブランチ adf_publish にARMテンプレートが生成される。Azure DevOpsのリリースパイプラインは、その発行用のブランチに新しい変更がプッシュされるとトリガーされ、ARMテンプレートをデプロイするように構成する。
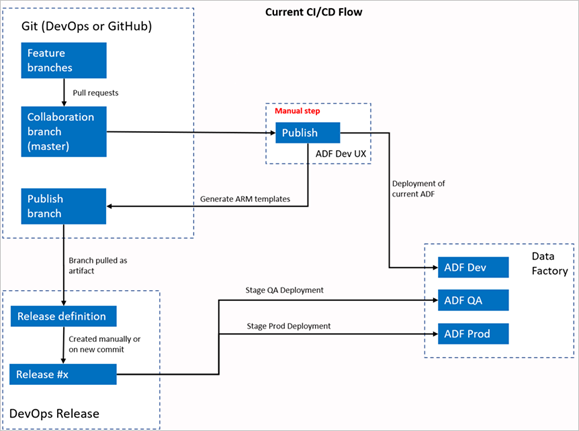
Source : https://docs.microsoft.com/en-us/azure/data-factory/continuous-integration-deployment-improvements
2. 新しいCI/CDのフロー
リリースパイプラインはPull Requestが承認されてコラボレーションブランチにマージされるとトリガーされる。パイプラインはADFUtilities NPMパッケージを使用する。これはすべてのリソースをチェックしてARMテンプレートを生成する。これはData FactoryのUIでの Publish ボタンの利用を不要にして、完全な自動化が可能になる。

Source : https://docs.microsoft.com/en-us/azure/data-factory/continuous-integration-deployment-improvements
リリースパイプラインの設定
従来からのCI/CDのためのパイプラインの設定
従来からのリリースパイプラインの設定方法は こちらのドキュメント に書かれている通りに設定すればOKだが、いくつかポイントだけここにメモする。
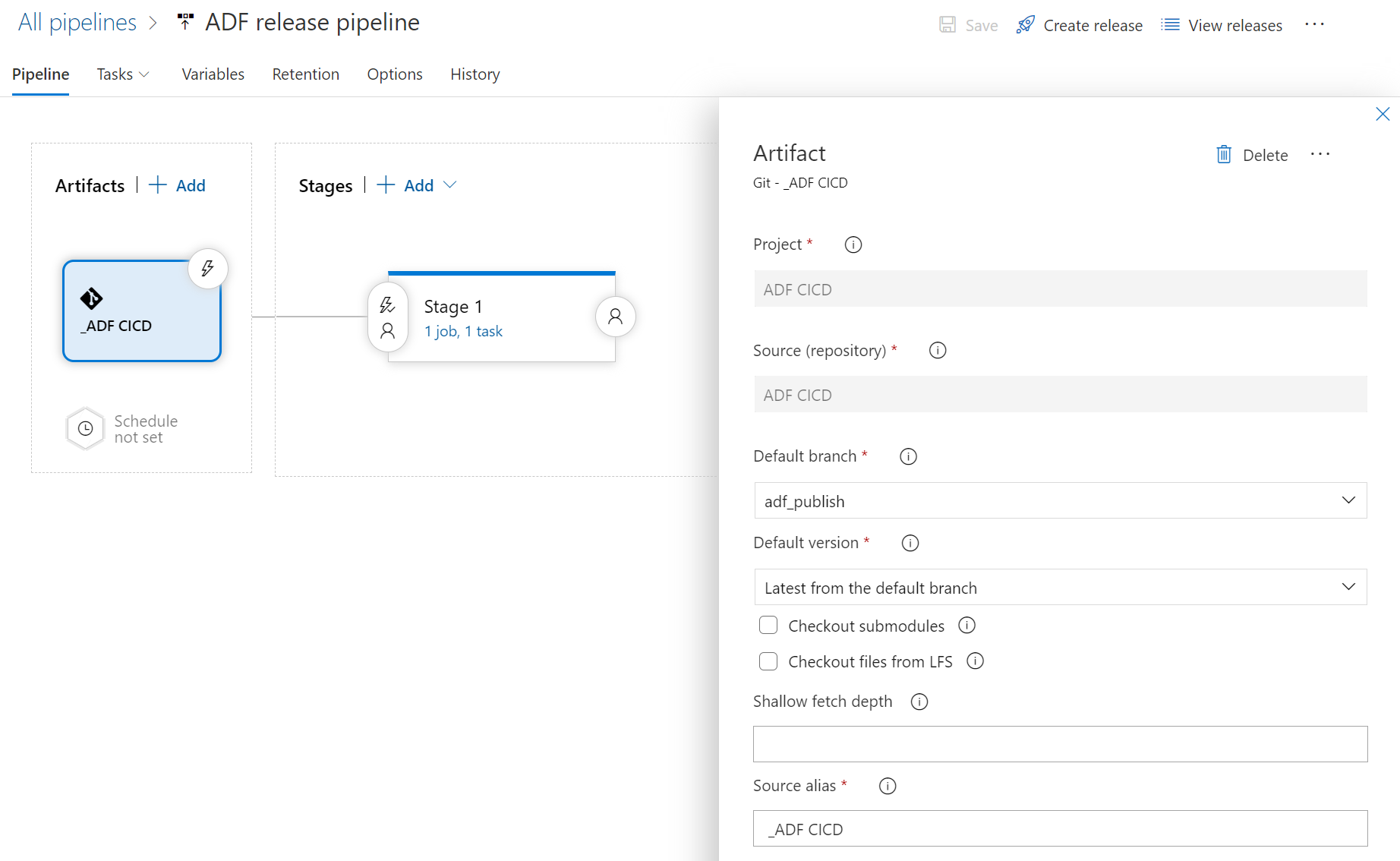
Artifact
Artifactは特別な設定は無いが、以下の項目は正しく設定が必要
- Default branch :
adf_publish(発行用ブランチの既定) - Default version :
Latest from the default branch(既定のブランチからの最新バージョン)
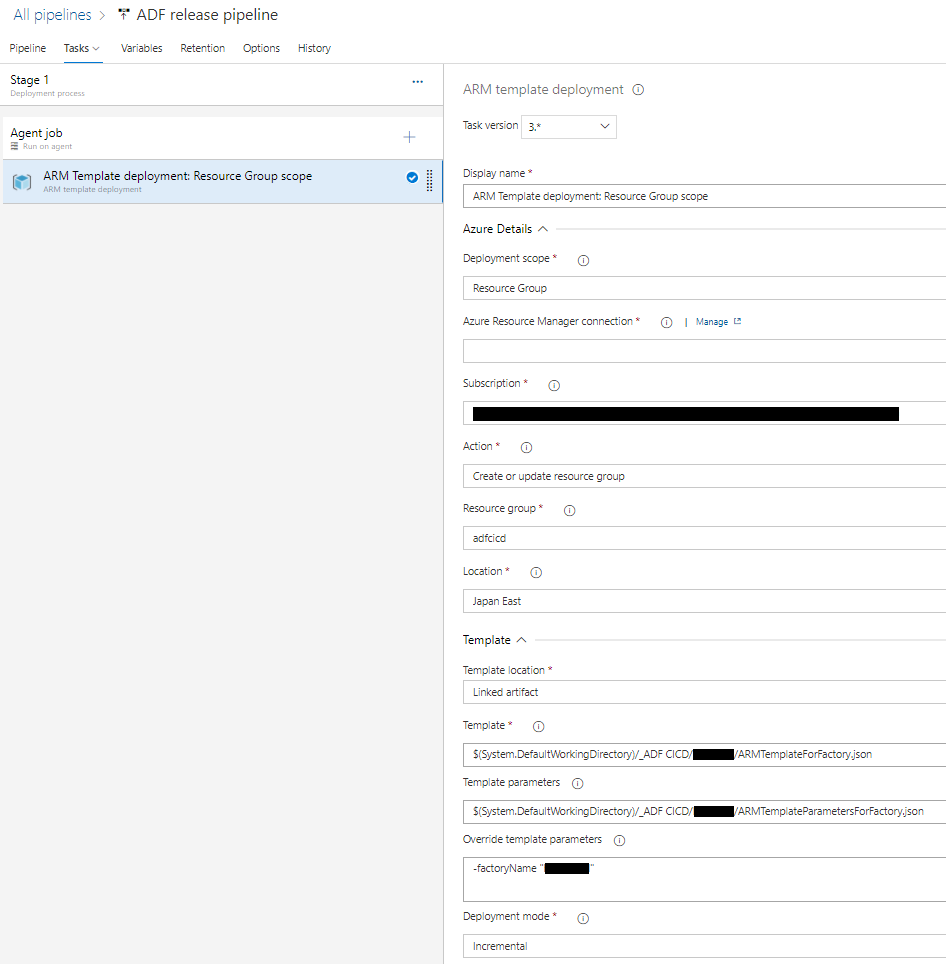
ARM Template deployment job
- ジョブの種類 :
ARM Template deploymentを探して選択 - Azure Resource Manager connection / Subscription / Resource Group / Location : Data Factoryのリソースをデプロイした環境のものを選択
- Action :
Create or update resource group - Template location
Linked artifact - Template : [...] を押して
ARMTemplateForFactory.json探して選択 - Template parameters : [...] を押して
ARMTemplateParametersForFactory.jsonを探して選択 - Override template parameters : ARMTemplateParametersForFactory.json に書かれているパラメータを上書きする場合に記述。今回の場合はデプロイ先のData Factoryを変更するため、
factoryNameパラメータにステージングや本番のData Factory名を上書き - Deployment mode :
Incremental
リリーストリガー
リリーストリガーを設定してデプロイを自動化するためには、公式ドキュメントの リリーストリガー を設定する。
今回設定したトリガーは以下の通り。

新しいCI/CDのためのパイプラインの設定
公式ドキュメント にその方法が記載されているが、このAzure Fridayの動画 を見たほうが設定方法がもっとわかりやすいかもしれない。
1. package.jsonの用意
リポジトリに行き、 package.json というファイルを作成する。下図はすでに作成済みの状態だが、ここで手動で新規ファイルとして作成すればOK。
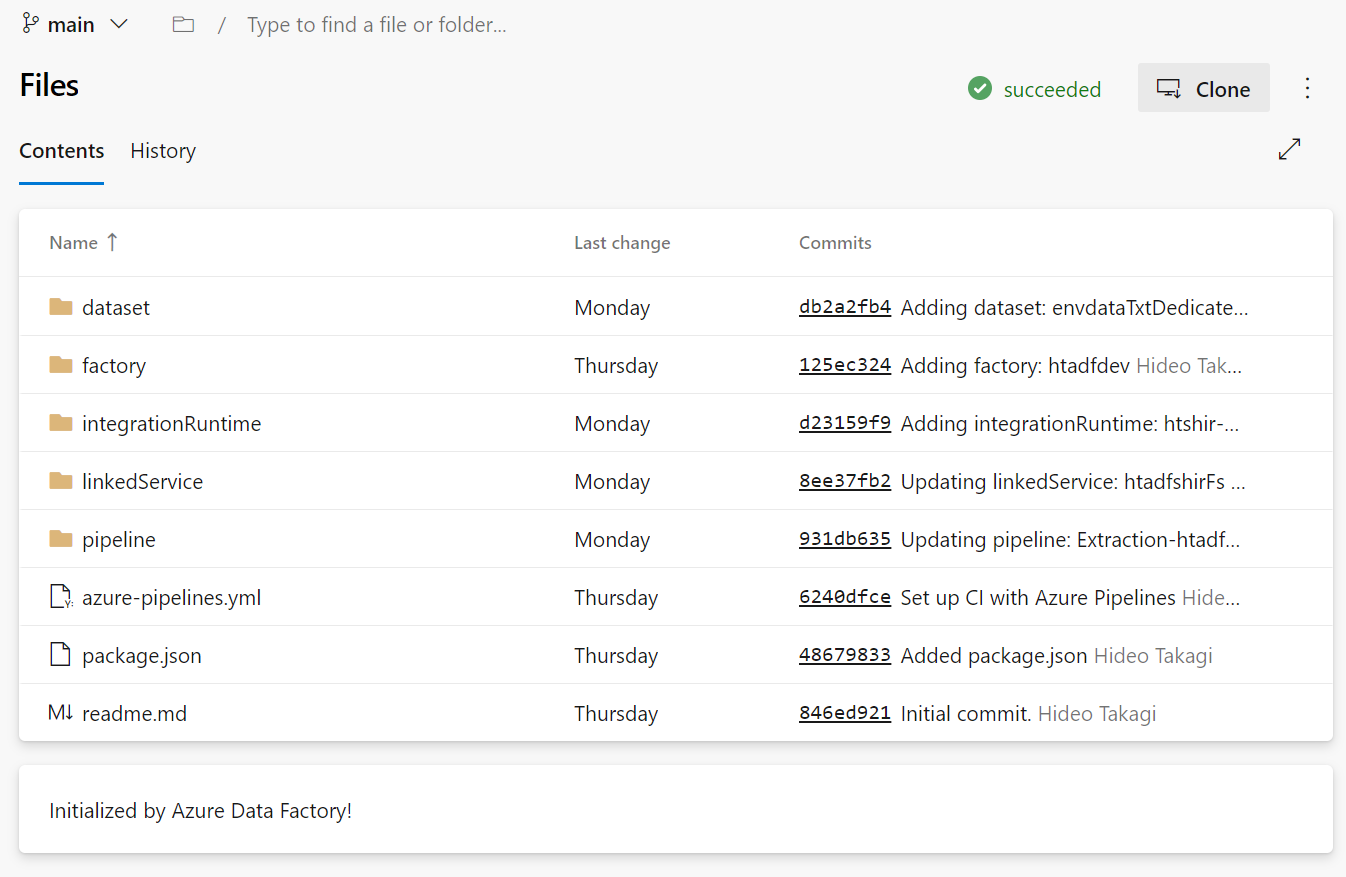
ファイルの中身は以下の通り。更新される可能性があるので、常に公式ドキュメントを参照してJSONをコピーすることをお勧めする。
{
"scripts":{
"build":"node node_modules/@microsoft/azure-data-factory-utilities/lib/index"
},
"dependencies":{
"@microsoft/azure-data-factory-utilities":"^0.1.5"
}
}
2. パイプラインの作成
次にパイプラインを作成する。新しいパイプラインとして Starter pipeline を選択。

azure-pipelines.yml に公式ドキュメント にあるYAMLを張り付けて、必要な個所を編集する。
# Sample YAML file to validate and export an ARM template into a build artifact
# Requires a package.json file located in the target repository
trigger:
- main # コラボレーションブランチの名前を指定
pool:
vmImage: 'ubuntu-latest'
steps:
# Installs Node and the npm packages saved in your package.json file in the build
- task: NodeTool@0
inputs:
versionSpec: '10.x'
displayName: 'Install Node.js'
- task: Npm@1
inputs:
command: 'install'
workingDir: '$(Build.Repository.LocalPath)/<folder-of-the-package.json-file>' # package.json ファイルのあるフォルダを指定。ルートに置いた場合はこの項目自体を削除してもOK。
verbose: true
displayName: 'Install npm package'
# Validates all of the Data Factory resources in the repository. You'll get the same validation errors as when "Validate All" is selected.
# Enter the appropriate subscription and name for the source factory.
- task: Npm@1
inputs:
command: 'custom'
workingDir: '$(Build.Repository.LocalPath)/<folder-of-the-package.json-file>' # 同様に package.json のあるフォルダを指定。
customCommand: 'run build validate $(Build.Repository.LocalPath) /subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/testResourceGroup/providers/Microsoft.DataFactory/factories/yourFactoryName' # サブスクリプション名、リソースグループ名、Data Factory名に置き換える。
displayName: 'Validate'
# Validate and then generate the ARM template into the destination folder, which is the same as selecting "Publish" from the UX.
# The ARM template generated isn't published to the live version of the factory. Deployment should be done by using a CI/CD pipeline.
- task: Npm@1
inputs:
command: 'custom'
workingDir: '$(Build.Repository.LocalPath)/<folder-of-the-package.json-file>' # 同様に package.json のあるフォルダを指定。
customCommand: 'run build export $(Build.Repository.LocalPath) /subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/testResourceGroup/providers/Microsoft.DataFactory/factories/yourFactoryName "ArmTemplate"' # サブスクリプション名、リソースグループ名、Data Factory名に置き換える。
displayName: 'Validate and Generate ARM template'
# Publish the artifact to be used as a source for a release pipeline.
- task: PublishPipelineArtifact@1
inputs:
targetPath: '$(Build.Repository.LocalPath)/<folder-of-the-package.json-file>/ArmTemplate' # 同様に package.json のあるフォルダを指定。ルートに置いた場合は /<folder-of-the-package.json-file> 部分を削除してもOK
artifact: 'ArmTemplates'
publishLocation: 'pipeline'
3. リリースの作成
YAMLの設定が完了したら次にリリースを作成する。

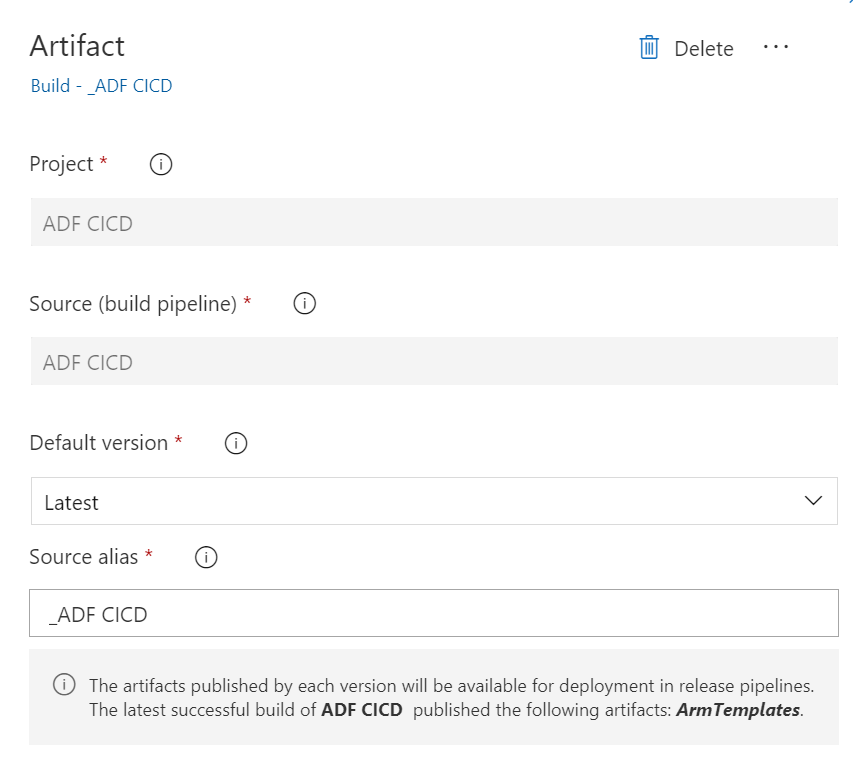
Artifact
Artifactとして、作成したビルドパイプラインを指定する。
ARM Template deployment job
従来からのCI/CDのためのパイプラインの設定のセクションで紹介した内容と同じ。
- ジョブの種類 :
ARM Template deploymentを探して選択 - Azure Resource Manager connection / Subscription / Resource Group / Location : Data Factoryのリソースをデプロイした環境のものを選択
- Action :
Create or update resource group - Template location
Linked artifact - Template : [...] を押して
ARMTemplateForFactory.json探して選択 - Template parameters : [...] を押して
ARMTemplateParametersForFactory.jsonを探して選択 - Override template parameters : ARMTemplateParametersForFactory.json に書かれているパラメータを上書きする場合に記述。今回の場合はデプロイ先のData Factoryを変更するため、
factoryNameパラメータにステージングや本番のData Factory名を上書き - Deployment mode :
Incremental

ビルドパイプラインで、コラボレーションブランチにマージされた場合にパイプラインがトリガーされるように設定したため、トリガーの設定はこの場合は不要となる。
Key Vaultを使用した認証情報の管理
Data FactoryとKey Vaultの構成
ARMテンプレートに渡すシークレットがある場合は、Azure PipelinesリリースでAzure Key Vaultを使うことが推奨されている。たいていの場合はデータソースに接続するためにシークレットを持ち、開発、テスト、本番環境でそれぞれ異なるシークレットが必要になることから、Azure Key Vaultを使用することは必須になるのではないかと思われる。
今回は各環境向けにKey Vaultを用意し、環境に応じて接続先を変更するように構成した。
この場合の構成のポイントは以下の通り。
- 各環境(開発、テスト、本番)のために別々のAzure Key Vaultを作成する
- Data FactoryのManaged identity を作成してKey Vaultのアクセスポリシーに追加する
- 同種のデータソースへのシークレットについて、すべての環境で同じシークレット名を使用する
- 各環境で異なるKey Vault名については、ARMテンプレートのパラメータを使用してリリースパイプラインでのデプロイ時に適用する
上記のポイントを図にすると以下のようになる。
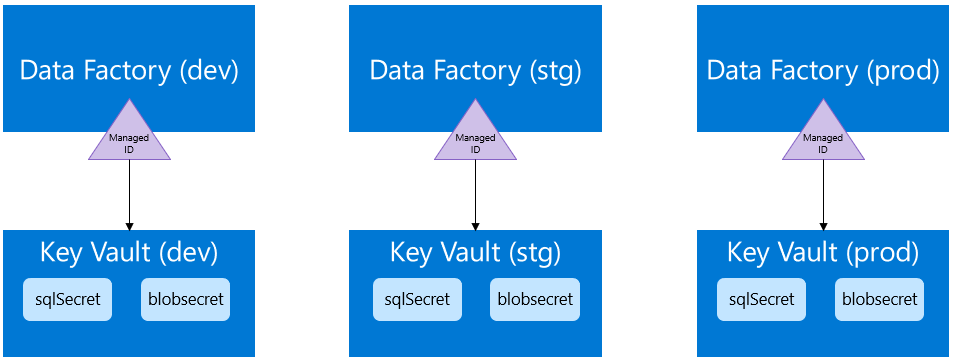
もちろん単一のKey Vaultにそれぞれの環境のシークレットを登録する方法も可能だが、一つのKey Vaultの中に開発、テスト、本番といったそれぞれの環境のシークレットを混在させたくない場合は、上記のようにキーコンテナごと分離するのが良い。
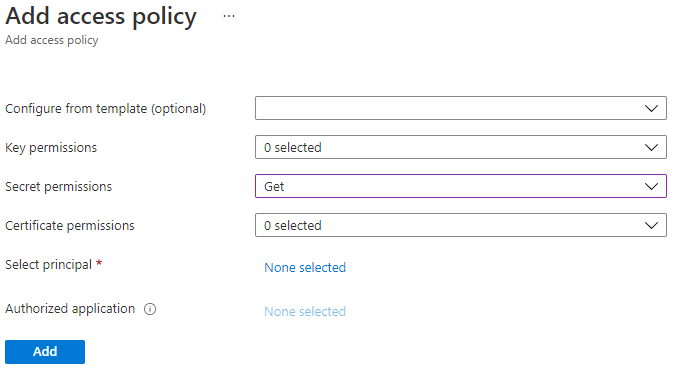
Key Vaultのアクセスポリシーでは、Data FactoryのManaged identityに対してシークレットに関して最低限 Get のみ権限を与える必要がある。
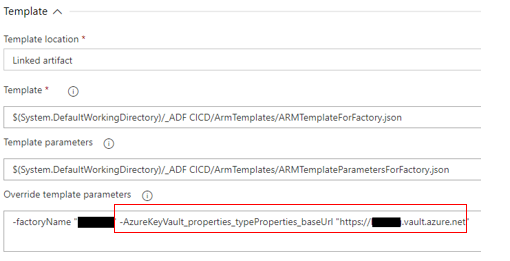
Key Vault名をARMテンプレートのパラメータとして渡す方法
Key VaultベースURLのパラメーター定義は、 ARMTemplateParametersForFactory.json にある。以下の図を参照。

Resource Managerのデプロイ中に一部のプロパティを変更したいが、プロパティがデフォルトでパラメーター化されていない場合は、カスタムパラメーターを定義する必要がある。 詳細については、このドキュメント を参照。
ARMテンプレートのデプロイのパイプラインジョブでパラメータの上書きを指定することにより、デプロイ中に別のKeyVaultを指定できる。
Integration Runtimeのデプロイ戦略
基本的な考え方
CI/CDシナリオでは、異なる環境での統合ランタイム(IR)タイプは同じである必要がある。 たとえば、開発環境にIRがある場合、同じIRは、テストや本番環境などの他の環境でもSelf-Hosted IRである必要がある。 同様に、統合ランタイムを複数のステージで共有している場合は、開発、テスト、本番などのすべての環境で、リンクされたSelf-Hosted IRとして構成する必要がある。各所での設定の手順としては、まず、開発環境でIR定義を作成し、それを他の環境(ステージングと本番)にデプロイしてから、実際のIRホストとの関連付けを設定する。
Self-Hosted IRのデプロイ戦略
(構成1) リンクされたSelf-Hosted IRを使用してシェアする

- 基となるSelf-Hosted IRをホストするための専用のData Factoryを用意し、Self-Hosted IRを作成する
- Self-Hosted IRの共有機能を使用して各環境に対してSelf-Hosted IRに対するアクセス許可を与える (以下の図SHIR(1)を参照)
- 開発環境でリンクされたSelf-Hosted IRを定義する(以下の図SHIR(2)を参照)
SHIR(1) - Self-Hosted IRへのアクセス権を与える

SHIR(2) - リンクされたSelf-Hosted IRの作成

(構成2) 各環境が専用のSelf-Hosted IRを持つ
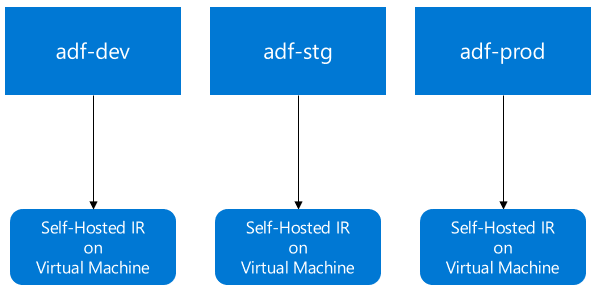
- 各環境向けに専用のSelf-Hosted IRを作成する
- 事前に各環境のSelf-Hosted IRの定義を作成しておくと、リリースパイプラインでのデプロイに失敗するため、開発環境のみで定義を作成し、リリースパイプラインで各環境にデプロイする
- ステージングや本番環境へのデプロイ後に、Self-Hosted IRの定義に対して実際のランタイムが紐づいていないためエラーが発生する。ここで手動でキーを登録して実際のランタイムとの紐づけを行う必要がある
- 本番環境とその他の環境のSelf-Hosted IRを混在させたくない場合はこの方法が推奨
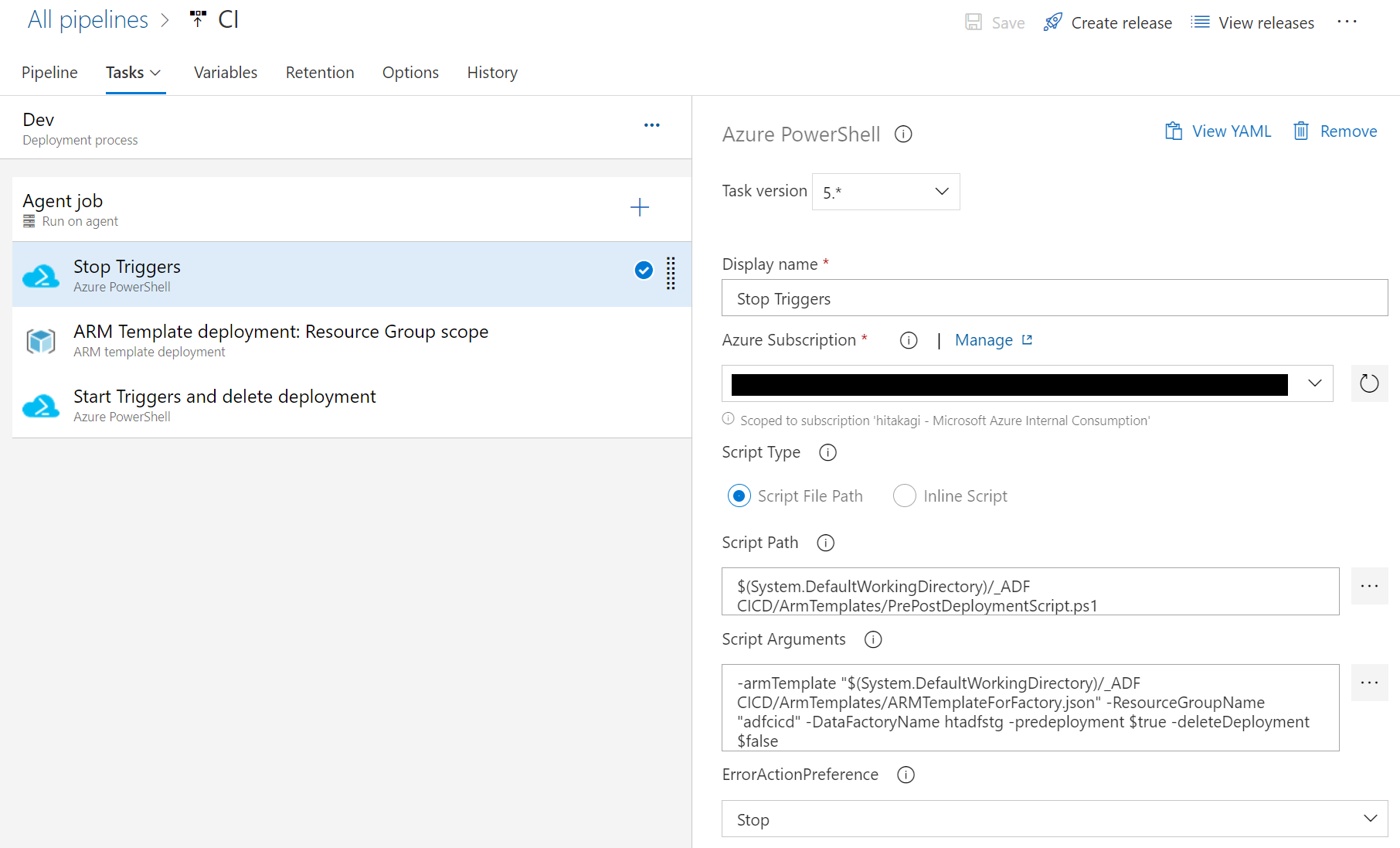
Pre/Postデプロイスクリプト
デプロイ前後のスクリプトを使用して、事前事後処理をすることも重要なタスクの一つ。
やることとしては以下が特に必要。
- Data Factoryのトリガーの停止と再開
- デプロイしている間にData Factoryのトリガーを停止し、デプロイが完了したら再開するようにスクリプトを実行する。これにより万一の不整合を防ぐためにデプロイ中にトリガーが起動されることを防ぐことができる。
- 削除されたオブジェクトのクリーンアップ
- ARMテンプレートのデプロイ増分操作になるため、削除されたリソースはクリーンアップされない。そのため、事後スクリプトによってこれらをクリーンアップする必要がある。
これらの操作に関しては 公式ドキュメント にサンプルが記載されている。
公式ドキュメント上に記載はなかったが、Data FactoryのARMテンプレートに PrePostDeploymentScript.ps1 スクリプトがあるため、これを利用すると便利。
リソース命名の考慮事項
これは公式ドキュメントの CI/CDのベストプラクティス に記載されているが、ARM テンプレートの制約により、リソースの名前にスペースが含まれていると、デプロイで問題が発生する可能性があるとの事。
Data Factoryのオブジェクトの名前に関しては、スペースの代わりに "_" または "-" 文字を使用することが推奨されている。
(例) "Pipeline 1" ではなく "Pipeline_1"
参考情報
ドキュメンテーション:
- Data Factoryのソース管理
- 継続的インテグレーションと配信
- CI/CDの自動発行
- Data FactoryのマネージドID
- Azure Key Vaultへの資格情報の格納
- Azure Data Factoryのロールとアクセス許可