はじめに
HDInsight 4.0以降、具体的にはApache Spark 2.3.1とApache Hive 3.1.0が異なるmetastoreを使うようになったため、これまでのようにmetastoreを共有して運用することが出来なくなったが、HortonworksがGitHub上で公開している Hive Warehouse Connector (HWC) を使うことで、SparkとHiveのmetastoreを一緒に使用することができるようになる。
HWCライブラリでLLAPデーモンからSpark Executorにデータが並列ロードされるので、JDBC接続よりもスケーラブルに動作するとの事。
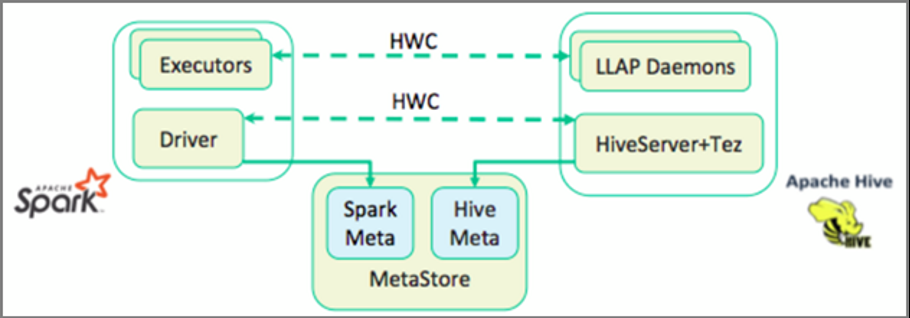
(From: https://docs.hortonworks.com/HDPDocuments/HDP3/HDP-3.1.0/developing-spark-applications/content/using_spark_hive_warehouse_connector.html)
HWCを通してできることは下記の通り
- テーブルを記述する (DESCRIBE)
- ORCフォーマットデータ用のテーブルを作成する
- HiveテーブルのデータをSELECTしてDataFrameに読み込む
- DataFrameをHiveテーブルにバッチで書き込む
- HiveのUPDATEステートメントを実行する
- Hiveからテーブルデータを読み取り、Sparkで変換し、新しいHiveテーブルに書き込む
- HiveStreamingを使用してDataFrameまたはSpark StreamをHiveに書き込む
制限事項としては下記の通り
- ORCフォーマットのみサポート
- Spark thrift serverはサポートされていない
HWCの設定
1. 事前準備
今回動作をテストするために新規にHDInsight Spark 4.0とHDInsight Interactive Query (LLAP) 4.0の2つのクラスターを作成した。この2つのクラスターは同じ仮想ネットワークに所属し、同じStorage Accountを使用するように設定した。デプロイの際の注意事項としては以下の2つが挙げられる。
- 同じVNETに作成するときはクラスター名の頭文字が6文字被っているとコケる
- 同じストレージアカウントでデプロイするとき、同じコンテナーは指定できない
2. 名前解決の設定
まず、LLAPクラスタとSparkクラスタのHeadNodeにそれぞれSSHログインし、LLAPクラスターのheadnode0の/etc/hostsのファイルの内容を、Sparkクラスターのheadnode0の/etc/hostsにコピーする。これによってSparkクラスターがLLAPクラスターのIPを解決できるようになる。以下のスクリーンショットのような感じ。
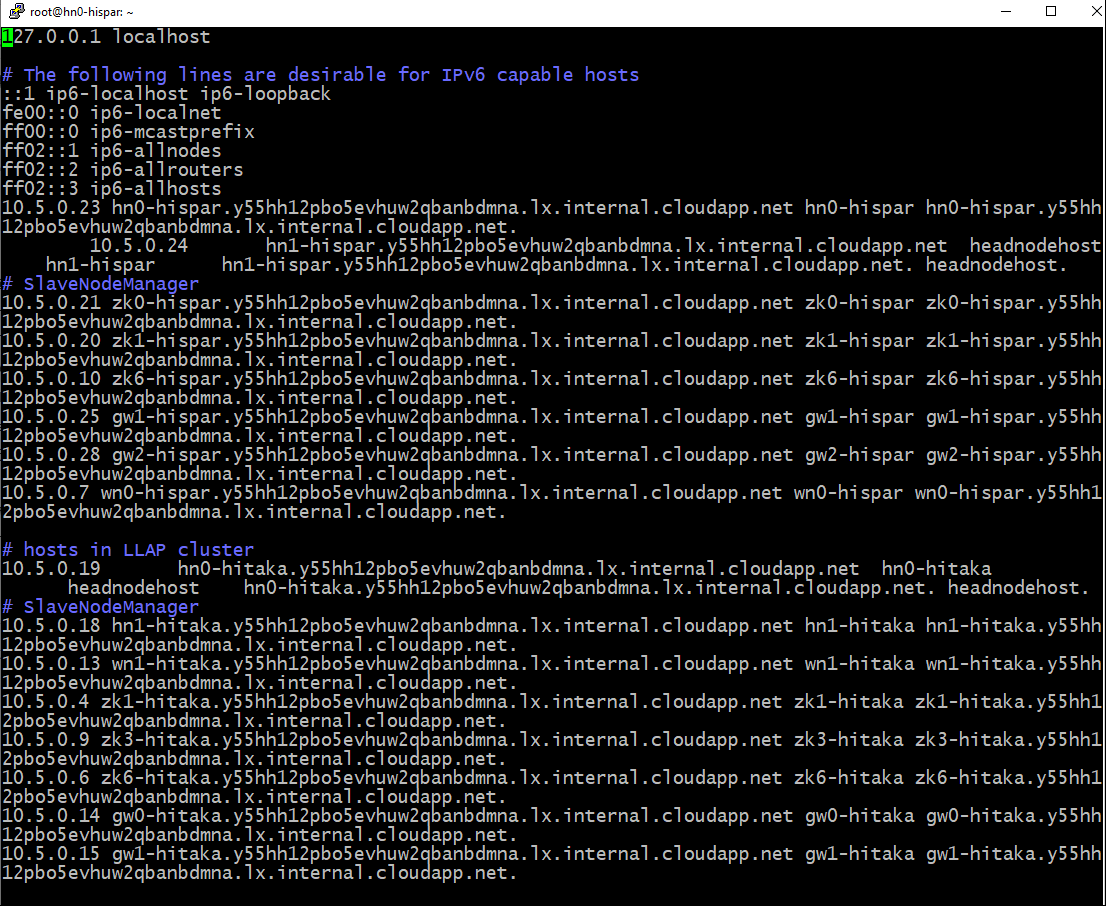
3. 各種パラメータの設定
AzureのポータルのHDInsightのSparkクラスターの管理ブレードから[Cluster dashboard]を選択し、Ambariにアクセス。Ambari画面上で、[Spark2] > [CONFIGS] > [Custom spark2-default]にアクセス。
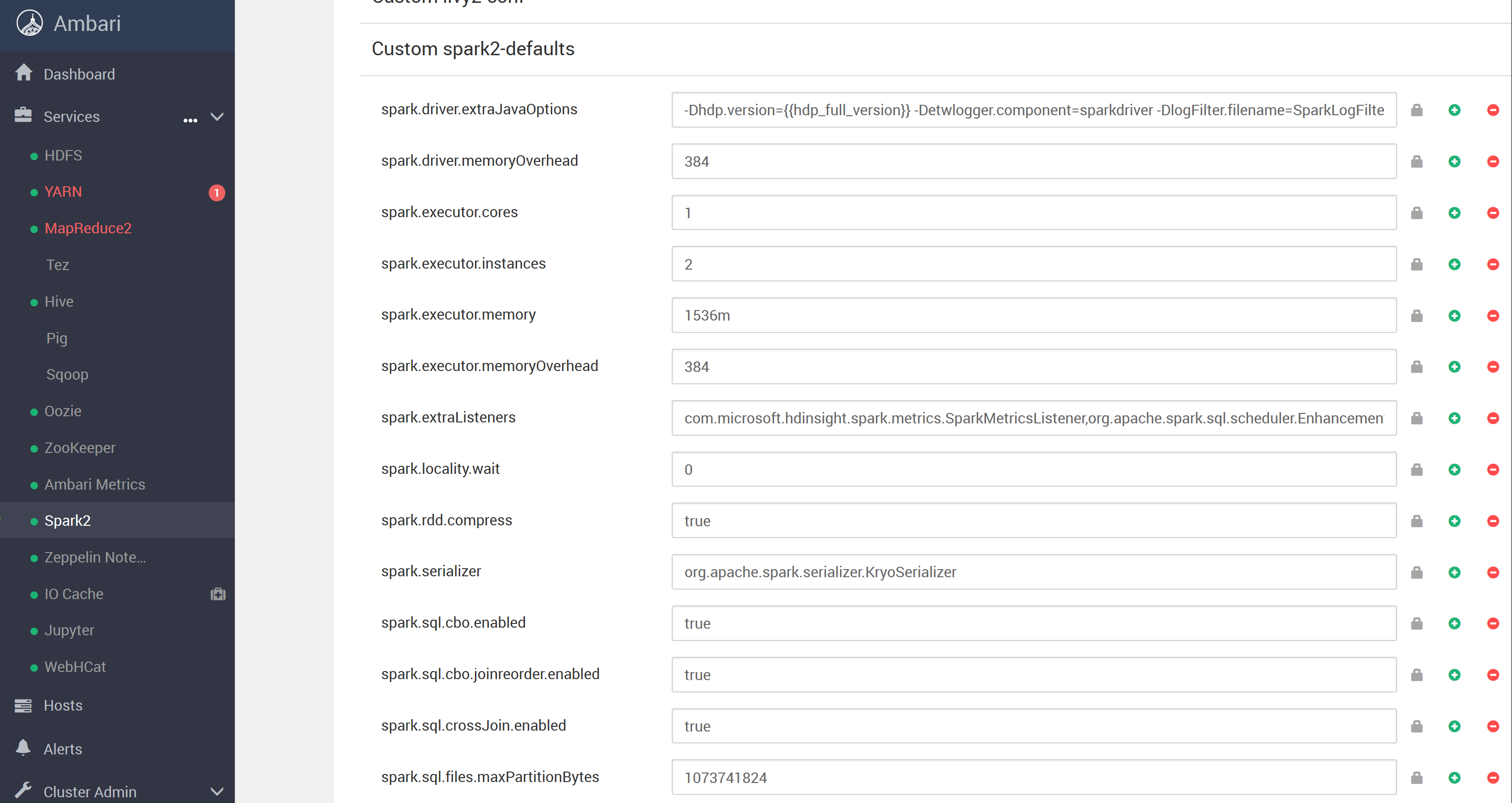
[Custom spark2-default]セクションの下部に[Add Property...]リンクがあるのでこれをクリックして設定画面を開く。
"spark.hadoop.hive.llap.daemon.service.hosts"に"LLAP App name"を設定する。設定する値は[Advanced hive-interactive-site] > "hive.llap.daemon.service.hosts"からコピーする。たぶん通常は"@llap0"になってると思う。
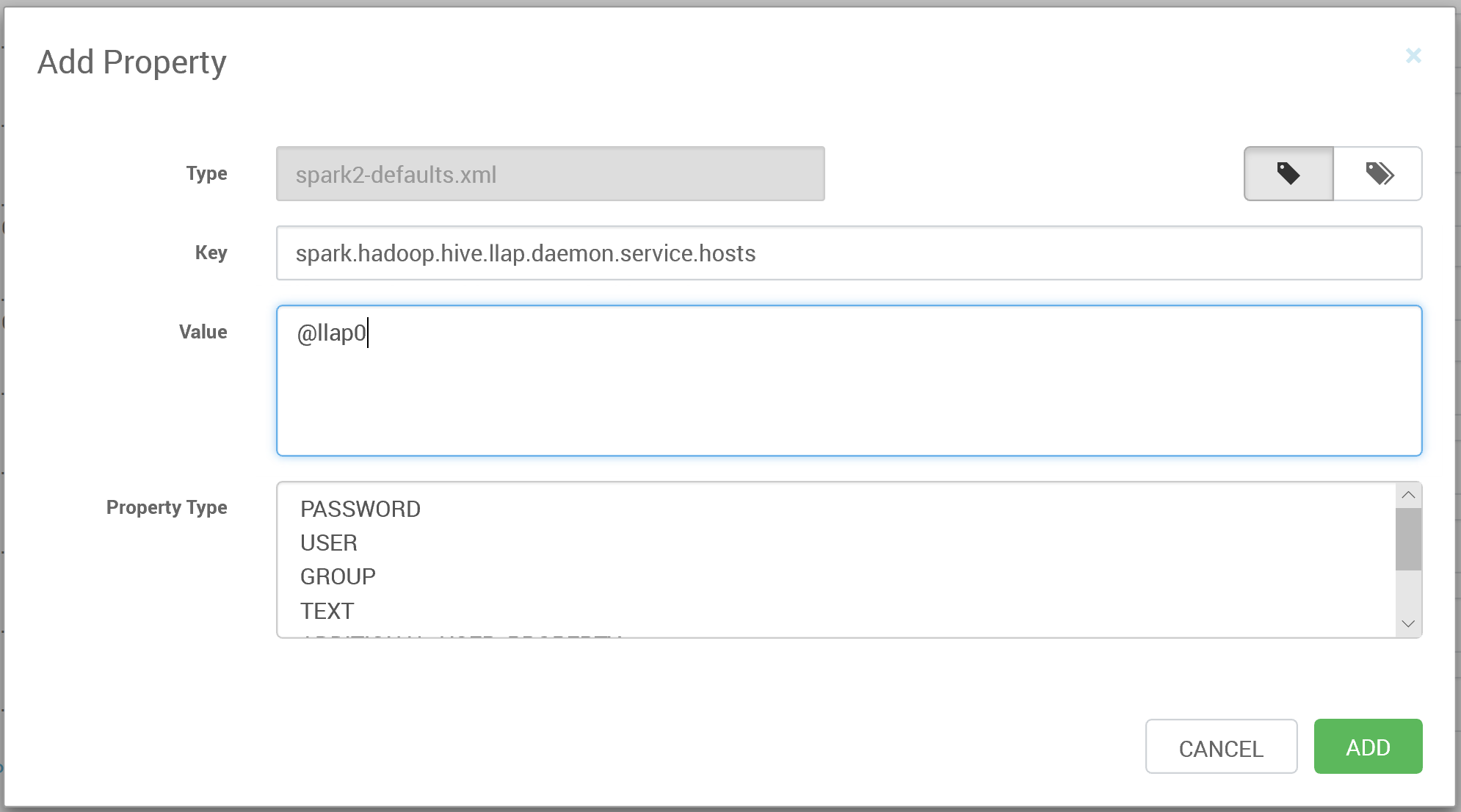
このようにして下記のパラメータも設定する。
| パラメータ | 値 | 補足 |
|---|---|---|
| spark.sql.hive.hiveserver2.jdbc.url | LLAPのJDBC接続文字列 | (例) jdbc:hive2://LLAPCLUSTERNAME.azurehdinsight.net:443/;user=admin;password=PWD;ssl=true;transportMode=http;httpPath=/hive2 ※LLAPCLUSTERNAME"は自分のLLAPのクラスター名に置き換える |
| spark.datasource.hive.warehouse.load.staging.dir | ストレージアカウント内のステージングディレクトリを指定 | (例) wasb://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.blob.core.windows.net/tmp ※STRAGE_CONTAINER, STORAGE_ACCOUNT_NAMEの値は自分の環境に合わせて置き換える |
| spark.datasource.hive.warehouse.metastoreUri | Ambariの[Hive] > [ADVANCED] > [General] > "hive.metastore.uris"の値をコピー | (例) thrift://hn0-hwclla.0iv2nyrmse1uvp2caa4e34jkmf.cx.internal.cloudapp.net:9083, thrift://hn1-hwclla.0iv2nyrmse1uvp2caa4e34jkmf.cx.internal.cloudapp.net:9083 |
| spark.security.credentials.hiveserver2.enabled | false | |
| spark.hadoop.hive.zookeeper.quorum | Ambariの[Hive] > [ADVANCED] > [Advanced hive-site] > "hive.zookeeper.quorum"の値をコピー | (例) zk1-nkhvne.0iv2nyrmse1uvp2caa4e34jkmf.cx.internal.cloudapp.net:2181, zk4-nkhvne.0iv2nyrmse1uvp2caa4e34jkmf.cx.internal.cloudapp.net:2181, zk6-nkhvne.0iv2nyrmse1uvp2caa4e34jkmf.cx.internal.cloudapp.net:2181 |
設定が終わったら[Save]して、サービスをRestartして反映させる。
HWCを使った接続
サポートされているクライアントツール
サポートされているクライアントツールは下記の通り。
- spark-shell
- PySpark
- Spark-submit
- Zeppelin
- Livy
spark-shellの起動
今回はspark-shellを使って接続を試すため、SparkクラスターのHeadNodeにSSHでログインして、以下のようにしてspark-shellを起動する。{VERSION}のところは実際のバージョンに置き換えて実行。
$ spark-shell --master yarn \
--jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-{VERSION}.jar \
--conf spark.security.credentials.hiveserver2.enabled=false
そうするといつものようにspark-shellが起動する
Sparkセッションの作成
最初にHWCを使ったSparkセッションを作成する。
import com.hortonworks.hwc.HiveWarehouseSession
val hive = HiveWarehouseSession.session(spark).build()
HiveテーブルにSELECTしてDataFrameに読み込む
標準で作成されているhivesampletableにアクセスしてクエリを実行してみる。
hive.setDatabase("default")
val df = hive.executeQuery("select * from hivesampletable where state = 'Colorado'")
val df = hive.executeQuery("select * from hivesampletable")
df.filter("state = 'Colorado'").show()
こんな感じで結果が出てくればOK。
+--------+---------+------+--------------+----------+-----------+--------+-------------+--------------+---------+--------------------+
|clientid|querytime|market|deviceplatform|devicemake|devicemodel| state| country|querydwelltime|sessionid|sessionpagevieworder|
+--------+---------+------+--------------+----------+-----------+--------+-------------+--------------+---------+--------------------+
| 28| 01:37:50| en-US| Android| Motorola| Droid X|Colorado|United States| 20.3095339| 1| 1|
| 28| 00:53:31| en-US| Android| Motorola| Droid X|Colorado|United States| 16.2981668| 0| 0|
| 28| 00:53:50| en-US| Android| Motorola| Droid X|Colorado|United States| 1.7715228| 0| 1|
| 28| 01:37:19| en-US| Android| Motorola| Droid X|Colorado|United States| 28.9811416| 1| 0|
| 186| 18:31:39| en-US| Android| LG| VS660|Colorado|United States| 3.1242108| 3| 6|
| 186| 00:33:42| en-US| Android| LG| VS660|Colorado|United States| 0.407366| 0| 0|
| 186| 00:33:43| en-US| Android| LG| VS660|Colorado|United States| 2.8991561| 0| 1|
| 186| 00:33:45| en-US| Android| LG| VS660|Colorado|United States| 0.9904373| 0| 2|
| 186| 15:53:14| en-US| Android| LG| VS660|Colorado|United States| 0.5970943| 1| 0|
| 186| 15:53:14| en-US| Android| LG| VS660|Colorado|United States| 1.4811596| 1| 1|
| 186| 15:53:16| en-US| Android| LG| VS660|Colorado|United States| 2.5451684| 1| 2|
| 186| 16:46:28| en-US| Android| LG| VS660|Colorado|United States| 0.312012| 2| 0|
| 186| 16:46:29| en-US| Android| LG| VS660|Colorado|United States| 2.6448547| 2| 1|
| 186| 16:46:31| en-US| Android| LG| VS660|Colorado|United States| 1.7891041| 2| 2|
| 186| 16:49:00| en-US| Android| LG| VS660|Colorado|United States| 0.0200286| 2| 3|
| 186| 16:49:00| en-US| Android| LG| VS660|Colorado|United States| 6.1997895| 2| 4|
| 186| 16:49:04| en-US| Android| LG| VS660|Colorado|United States| 1.0788553| 2| 5|
| 186| 18:09:48| en-US| Android| LG| VS660|Colorado|United States| 20.9030322| 3| 0|
| 186| 18:31:18| en-US| Android| LG| VS660|Colorado|United States| 0.7973807| 3| 1|
| 186| 18:31:19| en-US| Android| LG| VS660|Colorado|United States| 14.875574| 3| 2|
+--------+---------+------+--------------+----------+-----------+--------+-------------+--------------+---------+--------------------+
only showing top 20 rows
参考情報
Hive Warehouse Connector を使用して Apache Spark と Apache Hive を統合する
https://docs.microsoft.com/ja-jp/azure/hdinsight/interactive-query/apache-hive-warehouse-connector
Integrating Apache Hive with Kafka, Spark, and BI
https://docs.hortonworks.com/HDPDocuments/HDP3/HDP-3.1.0/integrating-hive/content/hive_hivewarehouseconnector_for_handling_apache_spark_data.html