本記事は東京学芸大学 櫨山研究室 Advent Calendar 2020の25日目の記事になります.
はじめに
本記事ではB'z,Mr.Children,椎名林檎,BUMP OF CHICKEN,RADWIMPS,YUIの歌詞情報を機械学習で分類します.
単純に言うと6値のテキスト分類です.
歌詞データのスクレイピング方法,機械学習モデルの構築・評価,モデルの予測結果にLIMEによる説明について記述しています.
使用するデータの収集
スクレイピングを使って利用する歌詞データを集めます.
手順を図に示すと以下のようになります.
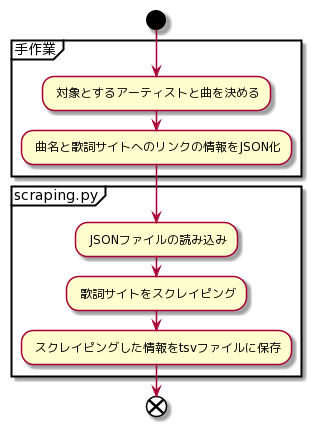
対象とするアーティストと曲の選択
今回は独断と偏見でB'z,Mr.Children,椎名林檎,BUMP OF CHICKEN,RADWIMPS,YUIを対象とします.
それぞれから20曲ずつ合計120曲分の歌詞データを収集します.
対象とする曲をリストアップすると以下の表のようになります.
|B'z|Mr.Children|椎名林檎|BUMP OF CHICKEN|RADWIMPS|YUI|
|:--|:--|:--|:--|:--|:--|:--|
|HEAT|365日|NIPPON|GO|25コ目の染色体|again|
|LOVE PHANTOM|and I love you|いろはにほへと|Hello, World!|いいんですか?|CHE.R.RY|
|May|CANDY|カーネーション|K|おしゃかしゃま|Cinnamon|
|OCEAN|everybody goes~秩序のない現代にドロップキック~|カプチーノ|ray|グランドエスケープ (Movie edit) feat.三浦透子|feel my soul|
|RED|GIFT|ギブス|sailing day|サイハテアイニ|fight|
|ultra soul|HANABI|ここでキスして。|アルエ|シュプレヒコール|GLORIA|
|YOU&I|HERO|ジユーダム|オンリーロンリーグローリー|スパークル (movie ver.)|Good-bye days|
|ZERO|himawari|すべりだい|カルマ|セプテンバーさん|Green a.live|
|イチブトゼンブ|innocent world|愛妻家の朝食|ギルド|トレモロ|HELLO|
|いつかのメリークリスマス|Marshmallow day|歌舞伎町の女王|スノースマイル|なんでもないや (movie ver.)|How crazy|
|グローリーデイズ|Over|丸の内サディスティック|ゼロ|ふたりごと|It's all too much|
|さまよえる蒼い弾丸|Tomorrow never knows|幸福論|ダイヤモンド|マニフェスト|Kiss me|
|さようなら傷だらけの日々よ|turn over?|至上の人生|プラネタリウム|愛にできることはまだあるかい|Laugh away|
|マイニューラブ|Your Song|人生は夢だらけ|ラフ・メイカー|君と羊と青|Namidairo|
|愛のバクダン|しるし|正しい街|ロストマン|最大公約数|Rain|
|愛のままにわがままに僕は君だけを傷つけない|ヒカリノアトリエ|長く短い祭|花の名|前前前世 (movie ver.)|Rolling star|
|世界はあなたの色になる|ラララ|夢のあと|記念撮影|大丈夫(Movie edit)|SUMMER SONG|
|夢見が丘|雨のち晴れ|目抜き通り|才能人応援歌|透明人間18号|TOKYO|
|有頂天|口がすべって|目眩|天体観測|夢灯籠|Tomorrow's way|
|恋心(KOI-GOKORO)|足音 ~Be Strong|野生の同盟|涙のふるさと|有心論|Your Heaven|
曲名と歌詞サイトへのリンクの情報をJSON化
曲名をkeyに歌詞サイトへのリンクをvalueとするJSONを作成します.
歌詞サイトにはうたまっぷを利用しました.
JSONは以下のような形式になります.
{
"曲名": "歌詞サイトへのリンク"
}
なおJSONファイルは各アーティスト毎に作成しました.
スクレイピングを実施するプログラムを書く
Pythonでスクレイピングを実施するプログラムを書きます.
スクレイピングにはBeautifulSoupを用います.
コードは以下のようになります.
import requests
from bs4 import BeautifulSoup
import pandas as pd
import json
# jsonファイル名
key = "sample"
prefix = "./data"
file_name = "{}.json".format(key)
json_data = open("{}/{}".format(prefix, file_name), "r")
json_data = json.load(json_data)
columns = ["artist", "title", "text"]
datas = pd.DataFrame(columns = columns)
for i, k in enumerate(json_data.keys()):
url = json_data[k]
html = requests.get(url)
soup = BeautifulSoup(html.content, "html.parser")
artist = soup.findAll(class_="pad5x10x0x10")
element = soup.find(class_="noprint kasi_honbun")
if element != None:
df = pd.DataFrame([artist[1].text, k, element.text.replace("\n", "")]).T
df.columns = columns
df.index = [i]
datas.loc[i] = df.loc[i]
print(datas)
datas.to_csv("{}/{}.tsv".format(prefix, key), sep="\t")
実行すると以下のような形式のtsvファイルで保存できます.
artist title text
0 椎名林檎 丸の内サディスティック 報酬は入社後並行線で東京は愛せど何にも無いリッケン620頂戴19万も持って居ない 御茶の水マ...
1 椎名林檎 ジユーダム お早う下ろし立てのときをどうしようか一切合財全部からきし未定わーい遊ぼう思い切り寝て食べて飲...
2 椎名林檎 人生は夢だらけ 大人になってまで胸を焦がして時めいたり傷付いたり慌ててばっかりこの世にあって欲しい物を作るよ...
3 椎名林檎 幸福論 本当のしあわせを探したときに愛し愛されたいと考えるようになりましたそしてあたしは君の強さも隠...
機械学習モデルの構築
教師あり学習によって機械学習モデルを構築します.
教師あり学習によるテキスト分類の流れを図に示しておきます.
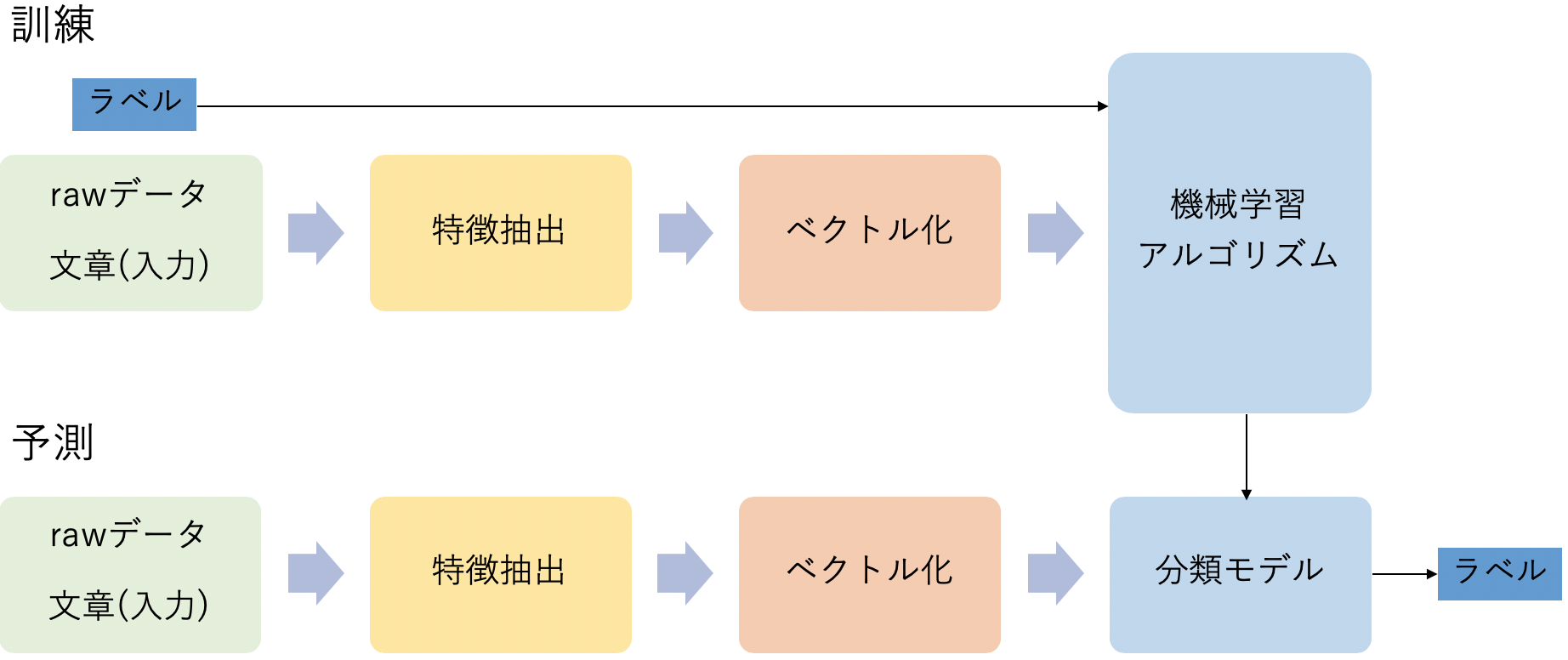
今回はrawデータが元の歌詞でラベルがアーティスト名になります.
歌詞データの読み込み
先ほど取得したtsvファイルを読み込みます.
tsvファイルの読み込みにはPandasを使用します.
import pandas as pd
prefix = "./data/"
# データのインポート
bz_df = pd.read_csv(prefix + 'bz.tsv', sep='\t', index_col=0)
mr_children_df = pd.read_csv(prefix + 'mr-children.tsv', sep='\t', index_col=0)
ringo_df = pd.read_csv(prefix + 'ringo.tsv', sep='\t', index_col=0)
bump_df = pd.read_csv(prefix + 'bump.tsv', sep='\t', index_col=0)
rad_df = pd.read_csv(prefix + 'rad.tsv', sep='\t', index_col=0)
yui_df = pd.read_csv(prefix + 'yui.tsv', sep='\t', index_col=0)
# ラベルを数値化
bz_df['artist'] = 0
mr_children_df['artist'] = 1
ringo_df['artist'] = 2
bump_df['artist'] = 3
rad_df['artist'] = 4
yui_df['artist'] = 5
label_dic = {
0: "B'z",
1: "Mr.Children",
2: "椎名林檎",
3: "BUMP OF CHICKEN",
4: "RADWIMPS",
5: "YUI"
}
# データを一つにまとめる
train_val_df = pd.concat([bz_df, mr_children_df, ringo_df, bump_df, rad_df, yui_df], ignore_index=True)
train_val_df["text"] = train_val_df["text"].astype(str)

特徴抽出
一般的に自然言語処理では文章を単語の集合として捉え,一つひとつの単語を特徴として扱います.
そこで文章を単語に区切る必要があります.
そこで用いるのが形態素解析です.
形態素解析では,辞書の品詞の情報に基づいて文を形態素と呼ばれる意味を持つ最小単位に区切ります.
形態素解析エンジンとして有名なMeCabを用いて文を区切ります.
この時,どの品詞の情報までを歌詞の特徴と捉えるかを考慮する必要があります.
今回は名詞,動詞,形容詞の3つを対象とします.
以下のような関数を作成します.
import MeCab
m_t = MeCab.Tagger('-Ochasen -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')
# MeCabで必要な品詞のみを取り出す関数を定義
def tokenizer_mecab(text):
f_list_to_string = lambda x: " ".join(x)
m_t.parse('')
node = m_t.parseToNode(str(text))
word_list = []
while node:
pos = node.feature.split(",")[0]
if pos in ["名詞", "動詞", "形容詞"]: # 対象とする品詞
word = node.surface
word_list.append(word)
node = node.next
return str(f_list_to_string(word_list))
この関数を利用すると以下のような出力を得ることができます.
>>> sample = tokenizer_mecab("天上天下繋ぐ花火哉万代と刹那の出会ひ")
>>> print(sample)
天上天下 繋ぐ 花火 哉 万代 刹那 出 会ひ
これを全てのデータに適用します.
適用後のデータをwakati列として保持します.
この操作はPandasのApplyメソッドを利用することで簡単に実現できます.
train_val_df['wakati'] = train_val_df['text'].apply(tokenizer_mecab)
ベクトル化
特徴抽出の次はベクトル化をする必要があります.
今回は事前学習済みのfastTextを用います.
事前学習済みのモデルは以下の記事で紹介されているWord Vectors(NEologd)を用います.
fastTextの学習済みモデルを公開しました, https://qiita.com/Hironsan/items/513b9f93752ecee9e670
ダウンロードしたzipファイルを展開し得られたmodel.vecファイルをロードして使用します.
# fastTextのインポート
from gensim.models.keyedvectors import KeyedVectors
model_dir = "model.vec"
model = KeyedVectors.load_word2vec_format(model_dir, binary=False)
fastTextからは単語一つの分散表現を取得するため,一つの歌詞データに含まれる単語全ての分散表現を平均したものをベクトルとして利用します.
このベクトルを取得する関数を作成します.
# 文章の各単語のfastTextによる分散表現を取得し平均を求める関数
def feature_fastText(sentences, arg1):
model = arg1
f = np.zeros((len(sentences), model.vector_size))
for i, s in enumerate(sentences):
for w in s:
try:
vec = model[w]
except KeyError: # 訓練データに出現しない単語
continue
f[i, :] = f[i, :] + vec
if len(s) != 0: # 0除算を防ぐ
f[i, :] = f[i, :] / len(s)
return f
この関数を利用すると以下のようにベクトル値を得ることができます.
>>> feature_fastText("天上天下 繋ぐ 花火 哉 万代 刹那 出 会ひ", model)
array([[ 0.14316 , -0.13605 , 0.21101999, ..., -0.024966 ,
-0.27485999, -0.21450999],
[ 0.059764 , 0.12624 , -0.34779999, ..., 0.052176 ,
-0.10524 , -0.27217999],
[ 0.14316 , -0.13605 , 0.21101999, ..., -0.024966 ,
-0.27485999, -0.21450999],
...,
[ 0. , 0. , 0. , ..., 0. ,
0. , 0. ],
[-0.20108999, -0.023195 , 0.36589 , ..., -0.38176 ,
-0.076424 , -0.00063253],
[ 0.12335 , 0.11111 , -0.21886 , ..., -0.24539 ,
0.081292 , 0.40628999]])
訓練データと検証データに分割
モデルの学習を始める前にデータを分割する必要があります.
今回は訓練データ:検証データを7:3の比率で分割します.
曲数で表すと84曲が訓練に使用され36曲が検証に使用されます.
データの分割にはscikit-learnのtrain_test_split関数を使用します.
from sklearn.model_selection import train_test_split
train_df, val_df = train_test_split(train_val_df, test_size=0.3, stratify=train_val_df.artist, random_state=10)
なおtrain_test_split関数ではstratifyオプションにラベルのデータを与えることで各ラベルが均等になるようにデータを分割してくれます.
今回の場合だと検証データの36曲には各アーティストの曲が6曲ずつ入るようになっています.
訓練データを使用して学習
アルゴリズムは深く考えずにとりあえずロジスティック回帰を使用します.
実装にはscikit-learnを使用します.
pipelineの定義
fastTextによるベクトル値の取得からロジスティック回帰での学習までをpipelineとして定義します.
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import FunctionTransformer
# fastTextによる分散表現を取得する関数をFunctionTransformerでラップ
feature = FunctionTransformer(feature_fastText, kw_args={'arg1': model})
# pipelineの定義
pipeline = Pipeline([
('feature', feature),
('clf', LogisticRegression(C=50))
])
なおロジスティック回帰の罰則項の強さを決めるハイパーパラメータ$c$はとりあえず$c=50$としました.
それでは学習させます.scikit-learnでのモデルの学習はfitを呼び出すだけでできるので非常に簡単ですね.
X_train = train_df["wakati"].values
y_train = train_df["artist"].values
clf = pipeline.fit(X_train, y_train)
検証データを使用した予測と評価
学習させた分類器に検証データを流して予測を実施します.
scikit-learnで構築したモデルでの予測はpredictを呼び出すだけでできるのでこちらも非常に簡単ですね.
X_val = val_df["wakati"].values
y_val = val_df["artist"].values
y_pred = clf.predict(X_val)
予測結果の精度をみてみましょう.指標にはAccuracy,Precision,Recall,F1-scoreを用います.
これらはscikit-learnのclassification_reportを使用します.
classification_reportでは正解と予測値を渡すだけで良い感じに求めてくれます.
from sklearn.metrics import classification_report
classification_report(y_val, y_pred, target_names=["B'z","Mr.Children", "椎名林檎", "BUMP OF CHICKEN", "RADWIMPS", "YUI"])
| Accuracy | 0.6111 |
|---|
Accuracy(正解率)は0.6111でした.なんとも微妙ですね😢
続いてPrecision,Recall,F1-scoreを見ていきましょう.
| Precision | Recall | F1-score | support | |
|---|---|---|---|---|
| B'z | 0.8333 | 0.8333 | 0.8333 | 6 |
| Mr.Children | 0.5000 | 0.3333 | 0.4000 | 6 |
| 椎名林檎 | 0.5555 | 0.8333 | 0.6666 | 6 |
| BUMP OF CHICKEN | 0.5714 | 0.6666 | 0.6153 | 6 |
| RADWIMPS | 0.7500 | 0.5000 | 0.6000 | 6 |
| YUI | 0.5000 | 0.5000 | 0.5000 | 6 |
| weighted avg | 0.6183 | 0.6111 | 0.6025 | 36 |
うーん,数値で見るとMr.childrenの精度が悪そうですね🤔
こういうのは可視化した方がわかりやすいので混同行列にします.
混同行列の作成
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
# 混同行列の作成
def calc_cm(y_true, y_pred):
cm = confusion_matrix(y_true, y_pred)
df = pd.DataFrame(cm)
df = df.rename(columns=label_dic, index=label_dic)
sns.set_theme(font='Hiragino Maru Gothic Pro')
sns.heatmap(df, annot=True, cmap="YlGnBu", cbar=False, square=True, fmt='d')
return df
calc_cm(y_val, y_pred)
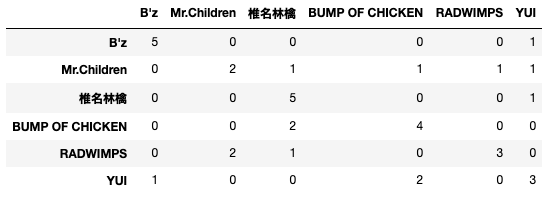
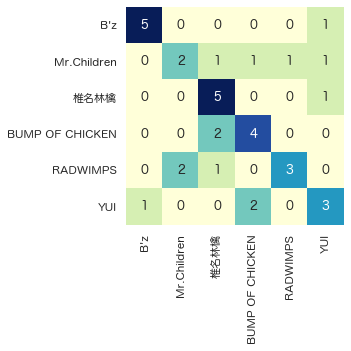
混同行列にしてみるとわかりやすいですね.
どうやら今回の分類器はB'zと椎名林檎については良く判定できているがその他は微妙という結果のようです.
具体的な予測結果をみる
ここまでで分類器の大体の傾向はつかめましたが個別の予測結果は見ていませんでした.
より具体的な個別の予測結果について見てみましょう.
そこで機械学習の予測結果に説明を付与するLIMEを使用します.
以下のコードで検証データのindexを指定して使用できます.
from lime.lime_text import LimeTextExplainer
idx = 1
explainer = LimeTextExplainer(class_names=["B'z","Mr.Children", "椎名林檎", "BUMP OF CHICKEN", "RADWIMPS", "YUI"])
exp = explainer.explain_instance(X_val[idx], clf.predict_proba, num_features=5, labels=y_val)
exp.show_in_notebook()
print(val_df.iloc[idx]["text"])
成功例①:BUMP OF CHICKENの「ロストマン」
BUMP OF CHICKENの「ロストマン」をきちんとBUMP OF CHICKENと判定している例です.
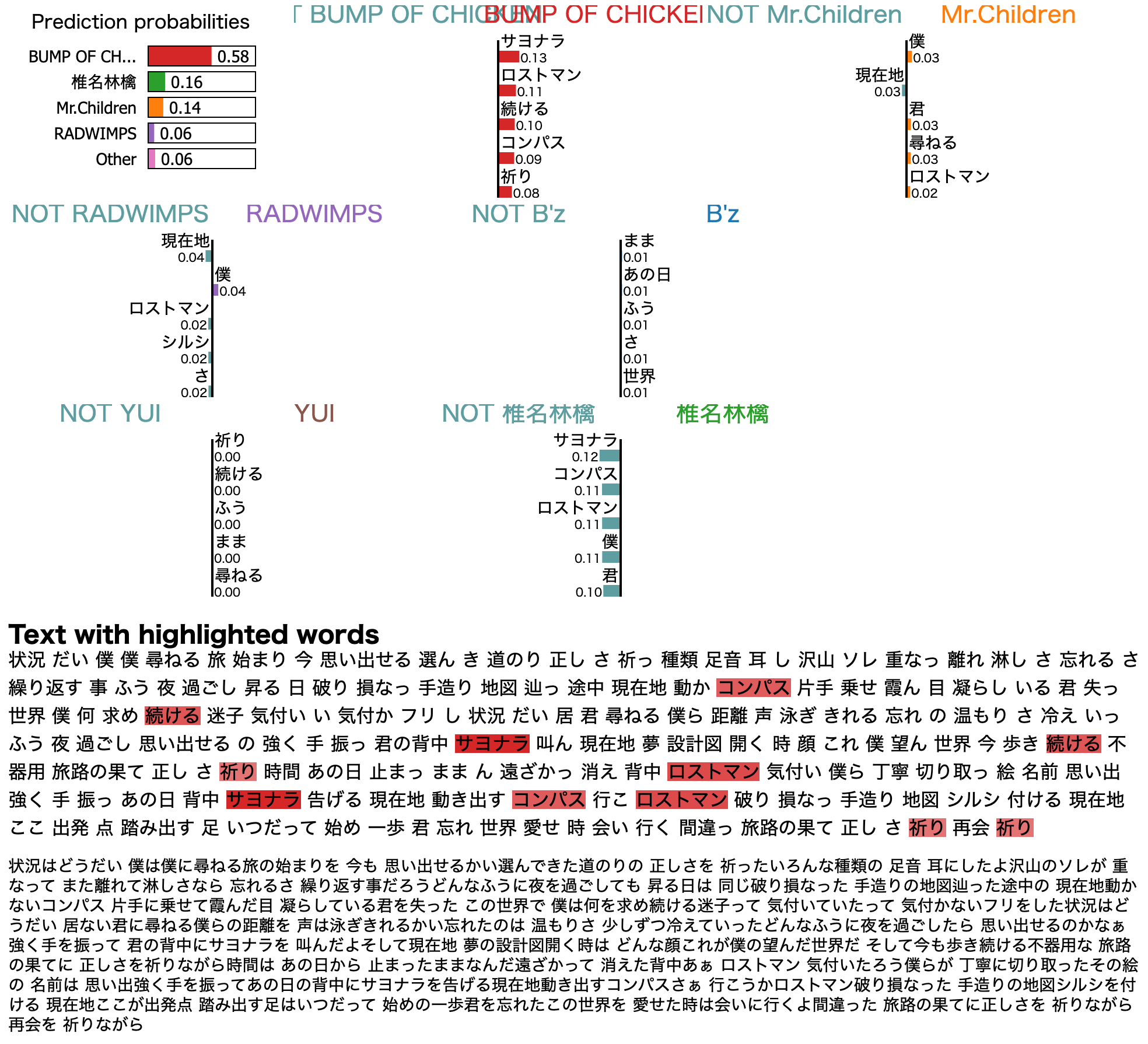
こうして見ると**"サヨナラ"や"ロストマン"**といった単語に着目してBUMP OF CHICKENと判定しているようです.
ちょっとこれは出来過ぎですね.
成功例②:椎名林檎の「歌舞伎町の女王」
椎名林檎の「歌舞伎町の女王」をきちんと椎名林檎と判定している例です.

どうやら**"あたし"は椎名林檎っぽい**ようです.
"歌舞伎町"がBUMP OF CHICKENっぽいのはなんか納得がいきませんが予測結果はダントツで椎名林檎なので良しとしましょう.
失敗例①:Mr.Childrenの「足音 ~Be Strong」
Mr.Childrenの「足音 ~Be Strong」を椎名林檎と誤判定している例です.

うーん,これだと結局は何が椎名林檎と判定しているかはわかりませんね…😥
まあ全体のベクトルの平均なので仕方ないのかもしれませんが.
とりあえず**"足音"という単語はBUMP OF CHICKEっぽいようですね.**
ここから考えらるのは訓練データの中にBUMP OF CHICKENの楽曲の中で歌詞に"足音"が含まれる可能性です.
これについては実際に"足音"が歌詞に含まれるBUMP OF CHICKENの「ゼロ」が訓練データに含まれていました.
そして全体のベクトルの平均だと椎名林檎っぽいということなのでしょう.
混同行列でも見ましたがMr.Childrenについてはうまく学習できてないです.
失敗例②:RADWIMPSの「愛にできることはまだあるかい」
RADWIMPSの「愛にできることはまだあるかい」をMr.Childrenと誤判定している例です.

数値で見ると僅差でMr.Childrenと誤判定しているようです.確率的には2番目がRADWIMPSですね.惜しい.
"君"がRADWIMPSっぽいのはなんとなく納得できますね.
おわりに
構築したモデルの精度はイマイチでしたが自然言語処理と機械学習は面白いですね😊
もっと計算リソースがあればBERTとかでもやってみたかったのですがそちらは今後の課題とします🙇♂️
形態素解析での品詞の抽出やアルゴリズム選択でのロジスティック回帰が適切だったのか?なども課題ですね.
本記事が何かの役に立てば幸いです🙏