毎日寒くて朝起きるのが辛い @wezardnet です。
今回は BigQuery で日ごとのログ件数を集計しようとした時にやらかした話を書こうと思います。
1. TL;DR
会社の G Suite 監査ログを BigQuery の日付別テーブルに流し込んでいる。ありがちなユースケースです。
2. 発覚、、、
毎日1件以上の監査ログが必ず発生する G Suite ログインや Google ドライブ/カレンダーなどは、下記のクエリーで問題なく、むしろ気付きませんでしたよ、ホントに。。。![]()
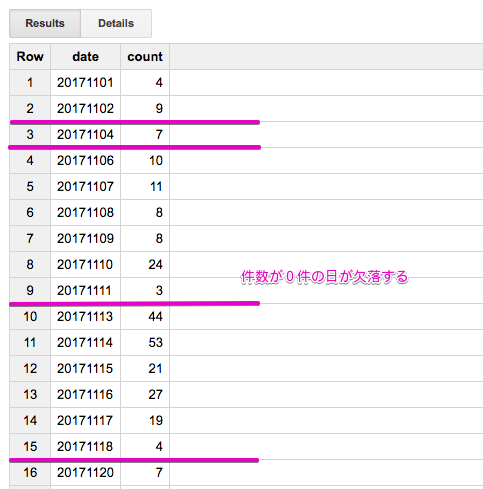
で、ログが発生しない日も度々ある Google グループを集計したときにヤバイことがわかりました。
SELECT
STRFTIME_UTC_USEC(DATE_ADD(Date, + 9, "HOUR"), "%Y-%m-%d") AS JST,
COUNT(*) AS count
FROM TABLE_DATE_RANGE([logs_groups.], TIMESTAMP("20171101"), TIMESTAMP("20171130"))
GROUP EACH BY JST
ORDER BY 1 ASC
コレを実行すると、次のような結果が出力されます。ん、なにか不足していると思ったら、件数が0件の日が欠落しているじゃないですかぁー![]()
当然ですよね、レコード内の日付見てクエリー叩いてんだからww
まっ、そういう仕様だとか、運用でカバーだとかエンジニア特有の魔法の言葉で言いわけ(ry
兎にも角にもさすがにコレはマズイわ。レポート出すにしろ、グラフ化するにしても面倒だし、なんにしても気持ち悪い...
3. 試行錯誤と経過...
という事情で久しぶりに BigQuery まわりのドキュメントとか読んでたら、レガシー SQL とスタンダード SQL に切り分けがされてることを知り、オイラが今まで使ってた SQL は レガシー に属するようで、それはそれで何気に気分悪いのでスタンダード SQL を学ぶことにしました。
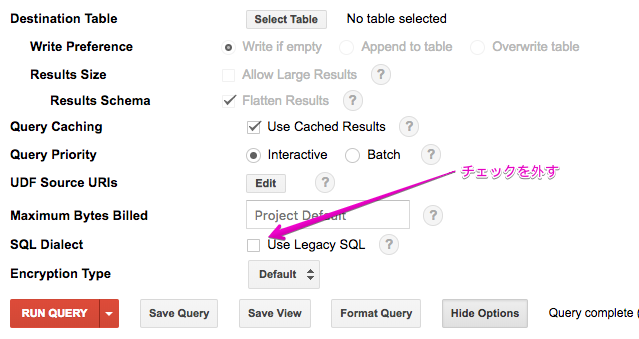
BigQuery Web UI でスタンダード SQL を利用するには、クエリーオプションで SQL Dialect の Use Legacy SQL のチェックを外すしてクエリーを実行するか、クエリーエディタの最初に #standardSQL を書くかのいずれかになります。前者はデフォルトでチェックが入っているので、後者で使うのが良さそうです![]()
3.1. version_1
見よう見まねで最初に書いた SQL が version_1 です。テーブル名が日付なので、どうにかテーブル名から日付を出力できないかなぁって考えていたところ __TABLES_SUMMARY__ というメタテーブルがあることを知り、コレと合体させて↓な感じになりました。
#standardSQL
with tbl as (
select table_id
from logs_groups.__TABLES_SUMMARY__
where length(table_id) = 8
)
select
tbl.table_id as date,
count(*) as count
from `logs_groups.*`, tbl
where
_table_suffix = tbl.table_id
and _table_suffix between "20171101" and "20171130"
group by tbl.table_id
order by 1 asc
コレを実行しても version_0 と結果は同じになります。何も進展してない…
補足になりますが where 句に length(table_id) = 8 が入っているのは、データセット内に過去の残骸で yyyyMM なテーブルが混ざっているからですww
3.2. version_2
まずはスタンダード SQL とメタテーブルの使い方を知ったところで、ログ件数が0件の日が出力されるように調整して version_2 の SQL になりました↓
#standardSQL
with tbl as (
select table_id
from logs_groups.__TABLES_SUMMARY__
where length(table_id) = 8
)
select
tbl.table_id as date,
logs.count as count
from tbl left join (
select
tbl.table_id as date,
count(*) as count
from `logs_groups.*`, tbl
where
_table_suffix = tbl.table_id
and _table_suffix between "20171101" and "20171130"
group by tbl.table_id
order by 1 asc
) as logs
on tbl.table_id = logs.date
where
tbl.table_id between "20171101" and "20171130"
order by tbl.table_id asc
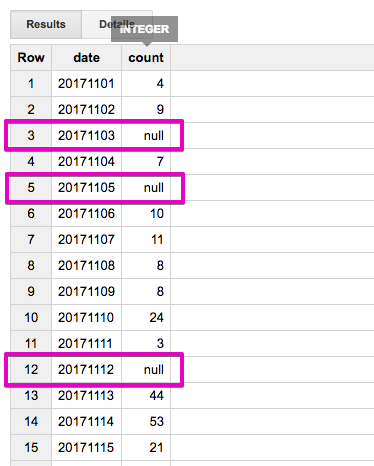
コレを実行すると、次のようになります。惜しいっ!
あとは関数使って null を0に置き換えれば目的は達成しそうです♪
3.3. version_3
null を0に置き換えるのは ifnull 関数を使えば解決できそうです。あとは SQL 内の期間を指定する日付部分を4箇所も変更するのは手間なので、パラメータ化しよって感じで version_3 になりました↓
#standardSQL
with config as (
select
"20171101" as date_start,
"20171130" as date_end
),
tbl as (
select table_id
from logs_groups.__TABLES_SUMMARY__
where length(table_id) = 8
)
select tbl.table_id as date, ifnull(logs.count, 0) as count
from config, tbl left join (
select
tbl.table_id as date,
count(*) as count
from `logs_groups.*`, tbl, config
where
_table_suffix = tbl.table_id
and _table_suffix between config.date_start and config.date_end
group by tbl.table_id
order by 1 asc
) as logs
on tbl.table_id = logs.date
where
tbl.table_id between config.date_start and config.date_end
order by tbl.table_id asc
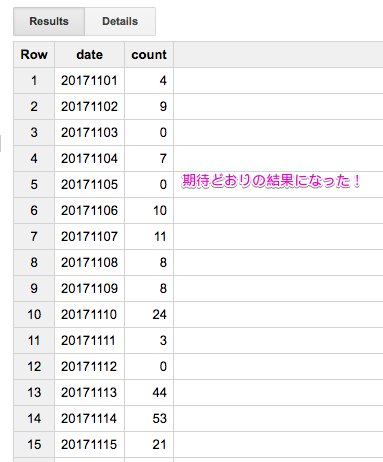
コレを実行した結果が次になります。おぉ、期待どおりになったぜっ!
データセット名の部分もパラメータ化したかったのだけど断念...(やり方知っている人いれば教えて欲しぃーです![]() )
)
4. おまけ
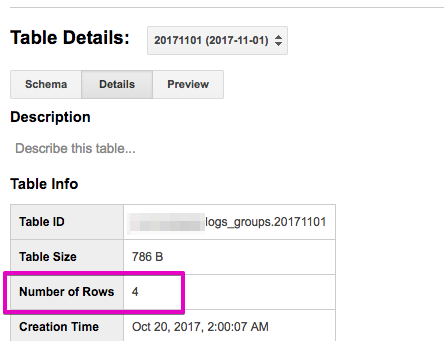
BigQuery の Web UI でテーブルの詳細を見ると、テーブルに格納されている行数が表示されます。この情報を取得できれば、レコード数をカウントしなくても同じことができんじゃね?と思って試してみました![]()
ということで、他サイトなどの情報を元に書いた SQL は↓な感じになりました。行数(Number of Rows)の情報は __TABLES__ というメタテーブルになります。詳しくは公式ドキュメントを参照ください。
#standardSQL
with config as (
select
"20171101" as date_start,
"20171130" as date_end
)
select table_id as date, row_count as count
from `logs_groups.__TABLES__`, config
where
table_id between config.date_start and config.date_end
order by table_id asc
この SQL を実行しても version_3 と同様の結果が得られますが、データ投入直後などは Number of Rows に反映されず、0件になってしまいます。行数が反映されるまでに半日ぐらい掛かりそうなので、正確な件数を即時に求めるのであれば、カウントを取ったほうが良さそうです。