pythonで自動化とかできるんでしょ~?よろしく~、って言われたので頑張る記録 その2
記録その1(https://qiita.com/wellwell3176/items/8e9a31d1595cdde89498 )で使った
「csv.dictreader」が良く分からなかったので調べて、何となく分かったという話。
というか、辞書形式という言葉に問題がある気がする・・・検索性悪い・・・検索性悪くない・・・?
調べた限り、要するに、1行目に書かれた情報を「データとして扱うか」「見出しとして扱うか」の差ということらしい。
図に落とし込まないと何も分からないマンなのでポンチ絵を作ってみたが、下図であっているはず。
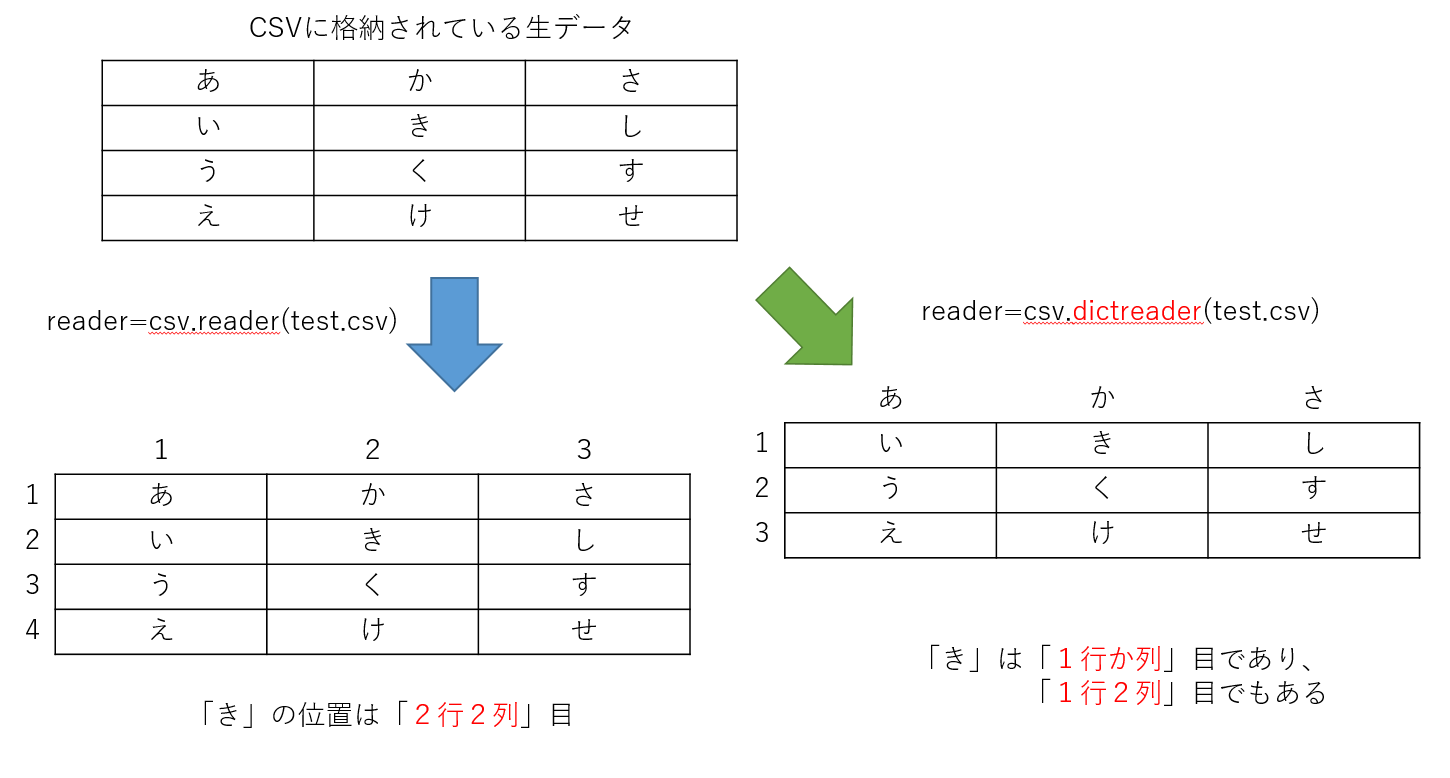
<図1:readerとdictreaderの差>
CSVデータの1行目にデータではなく見出し("No."とか、"年齢"とかそういうの)が入っているのであれば、
dictreaderの方が扱いやすそう。「年齢列の1~70行目のデータの平均値を出す」という書き方ができるはずなので。
一方、見出しが入っているCSVに対してreaderを使った場合は、「2列目の2~71行目のデータの平均値」というように、
「何列目に何の情報が格納されているか?」「1行目はデータに含まない」の2点を常に考慮しないと行けないから大変、と。
ざっくりだが、この理解で次に進もう。
とても独立記事を作るような内容ではないが、備忘録だし、一件一テーマで残しておくこととする。