これまでの踏跡
目次:今回の取組課題
元データの修正
7日目の夜勤不要
連続勤務不可
結果の出力
補足:プログラム全容
元データの修正
| 日付 | 昼夜 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 昼 | 有給 | |||||||
| 1 | 夜 | 忌避 | 忌避 | ||||||
| 2 | 昼 | 有給 | |||||||
| 2 | 夜 | ||||||||
| 3 | 昼 | 有給 | |||||||
| 3 | 夜 | 忌避 | |||||||
| 4 | 昼 | 有給 | |||||||
| 4 | 夜 | 忌避 | 忌避 | ||||||
| 5 | 昼 | 有給 | |||||||
| 5 | 夜 | ||||||||
| 6 | 昼 | 有給 | 忌避 | ||||||
| 6 | 夜 | 忌避 | 忌避 | ||||||
| 7 | 昼 |
前回データから、入力情報として不要な「必要人数」は削除
有給取得日を6個追加。
また、これまではsingle indexとしてdataframeを処理してきたが、
今後の新人フラグの追加などを考えると、multi indexでの対応が必要と考え変更した
(markdown表の見え方は今までと変わりない)。
処理を楽にするため英訳や数値変換を掛けたものは末尾の補足:プログラム全容に示す。
7日目の夜勤不要
これまでのプログラムではset関数を用いて変数x(m,d,a)のd,aを定めていた。
list_day =list(set(df_raw["日付"]))
list_action = list(set(df_raw["昼夜"]))
# 変数宣言
x = {}
for m in list_member:
for d in list_day:
for a in list_action:
x[m, d, a] = pulp.LpVariable("x({:},{:},{:})".format(m,d,a), 0, 1, pulp.LpInteger)
set関数の良いところは、重複を自動的に削除してくれることであるが、
日付と昼夜の全組み合わせを作ってしまうので[7,"夜"=1]というパターンの変数が自動生成されていた。
今回は[1,0][1,1][2,0]...[7,0]までが必要なd,aの組み合わせであり、これはMulti indexのindexをリスト化すれば得られる。
もしも日付と昼夜の列に重複する組み合わせがあるような場合は、drop_duplicates()関数を使うのが良さげ。
参考サイト1 : https://qiita.com/k_maki/items/f31db2ec797d73393672
list_da= df_raw.index.to_list()
x = {}
for m in list_m:
for d,a in list_da:
x[m, d, a] = pulp.LpVariable("x({:},{:},{:})".format(m,d,a), 0, 1, pulp.LpInteger)
>>>print(list_da)
[(1, 0), (1, 1), (2, 0), (2, 1), (3, 0), (3, 1), (4, 0), (4, 1), (5, 0), (5, 1), (6, 0), (6, 1), (7, 0)]
>>>print(x)
{(1, 1, 0): x(1,1,0)}
{(1, 1, 0): x(1,1,0), (1, 1, 1): x(1,1,1)}
{(1, 1, 0): x(1,1,0), (1, 1, 1): x(1,1,1), (1, 2, 0): x(1,2,0)}
{(1, 1, 0): x(1,1,0), (1, 1, 1): x(1,1,1), (1, 2, 0): x(1,2,0), (1, 2, 1): x(1,2,1)}
︙
{(1, 1, 0): x(1,1,0), (1, 1, 1): x(1,1,1), (1, 2, 0): x(1,2,0), (1, 2, 1): x(1,2,1), …中略… (8, 7, 0): x(8,7,0)}
中身を確認すると、list_daに[1,0][1,1][2,0]...[7,0]までの組み合わせが入り、生成した変数xもx(m,7,0)で終わっている。
これで7日目夜勤問題は解決した。
連続勤務不可
これは制約条件となる。
(d2-d1=|0| & a2-a1=|1|) | (d2-d1=|1| &a2-a1=|1|)となる全ての組み合わせを準備し、
mが同じ時の総和が1以下になるように制約すれば良い
というのが前回の考察だったので、これを実装する手段を考える。
計算量が無駄に大きくならないようにすることを考慮すると、
| d1 | a1 | d2 | a2 |
| 1日目 | 昼 | 1日目 | 夜 |
| 1日目 | 夜 | 2日目 | 昼 |
| 以下略 |
list_renzokukinmu = ([1,0,1,1],[1,1,2,0],・・・[6,1,7,0])
上表のような、d1-a1とd2-a2が一個ずつズレたリストがあれば、
for d1,a1,d2,a2 in list_renzokukinmu:
を、一回計算すれば解決しそうな気がする。やってみよー。
list_da1 = list_da[:-1]
list_da2 = list_da[1:]
for i in range(len(list_da1)):
list_da1[i]=list_da1[i]+list_da2[i]
for m in list_m:
for d1,a1,d2,a2 in list_da1:
ShiftScheduling += x[m, d1, a1]+x[m,d2,a2] <=1```
まず、list_da1とlist_da2は、それぞれlist_daの先頭行と最終行を切ったものである。
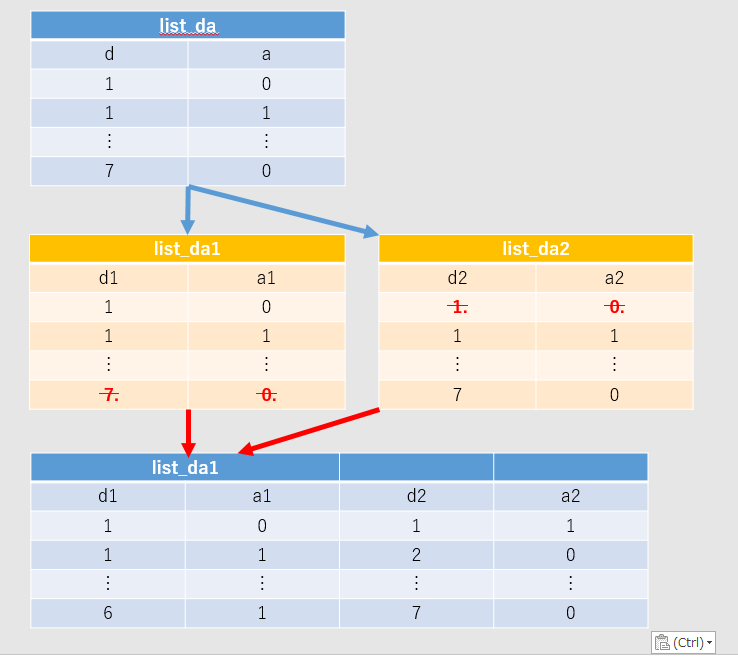
雑に図式化すると、上図のようになり、順番が1だけずれた列が2列増え、切った分だけ1行小さくなる。
list_da1の中身は[1,0,1,1],[1,1,2,0],・・・[6,1,7,0]、となっているのでこれを使ってforを回す。
x[m, d1, a1]+x[m,d2,a2] <=1
という式が、全ての勤務者に対して隣接するシフトに入ることは禁じる、という制約条件になっている。多分。
結果の出力
出力結果を表に戻すのが大変、という問題があったので、ひとまず力技で何とかした
results = ShiftScheduling.solve()
print("optimality = {:}, target value = {:}".format(pulp.LpStatus[results], pulp.value(ShiftScheduling.objective)))
>>>出力結果
optimality = Optimal, target value = 26.0
kekka=[]
for v in ShiftScheduling.variables():
kekka = kekka+[int(pulp.value(v))]
kekka=pd.DataFrame(np.array(kekka).reshape(8,13).T)
1-2行目は従来と同じ。
Solveで解決し、目的関数を満たせているかどうかを確認する。
出力結果はOptimalで出勤回数26回。解けたらしい。
そしてkekka = [] からが本番の変数をpandas.dataframeに整形する方法。
まず、x(m,d,a)が持っている値をリストの順に出力する方法はわかっている
for v in ShiftScheduling.variables():
print(pulp.value(v))
上記でx(1,1,0)からx(8,7,0)まで、順番に数値が取り出せる。
よって、これによって得られた数値をkekkaという空のリストに片っ端から押し込んでいく。
全データを押し込み、1×(全変数の個数)というサイズのリストが出来上がったら、
list型からnp.arrayに変換して8行13列の行列にして転置すれば完成である。
この方法だと.Tで転置しないと行列が合致しないので注意。
dataframeになったら、後はエクセルで出力して元の希望表にちゃちゃっと結合してやれば下図のとおりである。
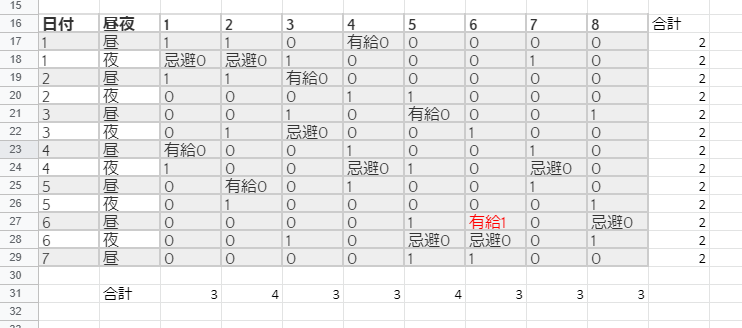
数値の0が休み、1が出勤である。
勤務者6番が有給出勤になってる!!!なんで!?
optimality = Optimalだから、制約条件は全て満たせたと思っていたんだけど・・・
原因がすぐには分かりそうにないので、オチもついたし今回はここまで。
追記
原因が判明。夜勤忌避周りのプログラムの修正が甘かった。
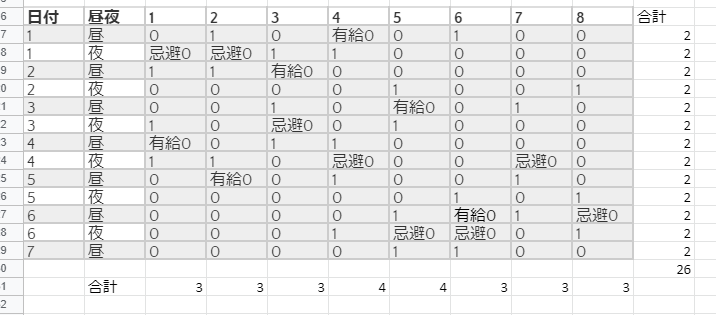
図 全部修正後にもう一回出力した結果
無事に解けた。
失敗もちゃんと履歴を残しておかないとマズいので、以下にミスってた部分の新旧を置き、
補足:プログラム全容には改訂版を置く。
# 旧・制約条件3:有給と夜勤忌避。失敗してた方
list_A=[]
list_B=[]
for m in list_m:
df_NG=df[df[m]>=1.0] #ミスその1
list_A = [m,df_NG["日付"].iloc[-1],df_NG["昼夜"].iloc[-1]] #ミスその2
list_B.append(list_A)
for m,d,a in list_B:
# 新・制約条件3:有給と夜勤忌避。上手く行った方
list_A=[]
list_B=[]
for m in list_m:
df_NG=df_raw[df_raw[m]>=1.0]
for i in range(len(df_NG.index.values)):
list_A = [m,df_NG.index.values[i][0],df_NG.index.values[i][1]]
list_B.append(list_A)
for m,d,a in list_B:
ShiftScheduling += x[m, d, a] == 0
失敗してた原因は2つ。
1.df_NGの参照先を昔のdataframeの名前(df)にしていた
dfからdf_rawに名前を変えたのだが、ここを直すのを忘れていた。
google colabは接続している間は古いデータをちゃんと保持しておいてくれるので、
dfに有給情報無しのデータ格納する → df_rawに有給情報ありのデータ格納する
→ dfを参照したら有給情報無しのデータを使って問題を解いてくれる
という事だったらしい。
2.有給と夜勤忌避でdf_NGが2行以上ある場合に対応していなかった
これは前回(https://qiita.com/wellwell3176/items/365c79b5939729d4688f )言及していた点で、
ただし、この方法は「夜勤忌避を各自1回しか出せない」という前提でのもの。
夜勤忌避が2回あると成立しないので、もう少し練り込む必要がある。
と、ちゃんと書いてある。忘れるな。
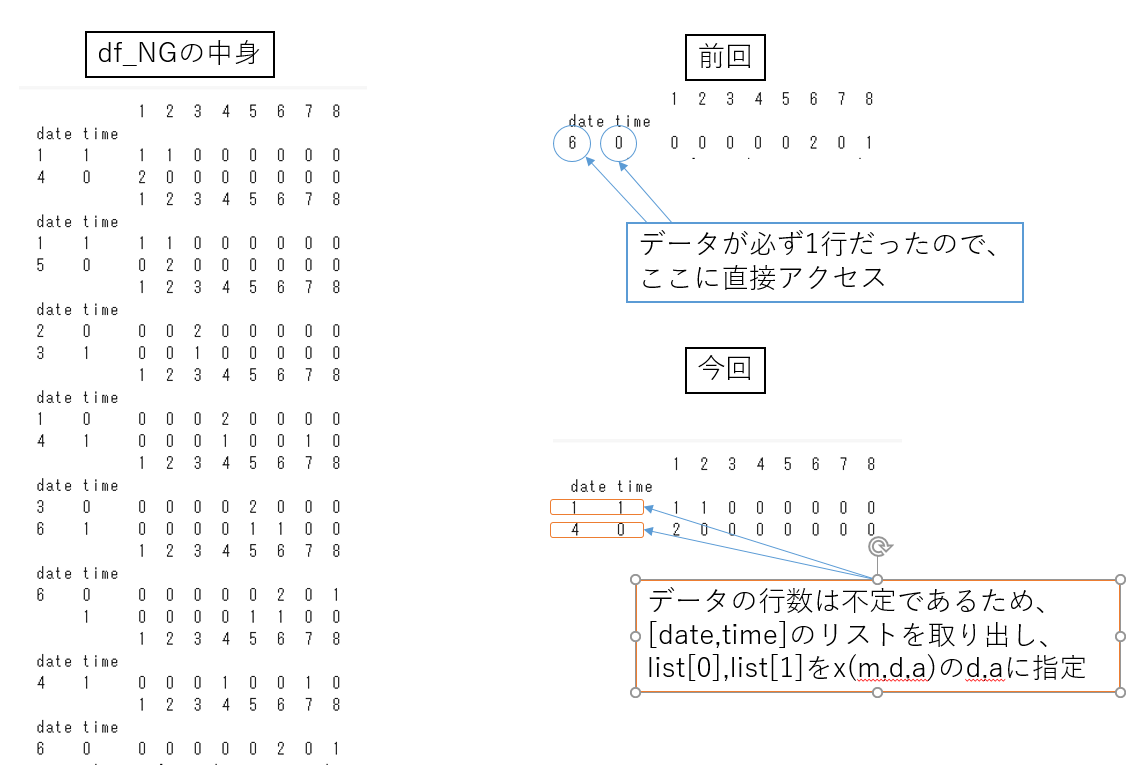
直した後のプログラムでやってることは上図みたいな感じ。
list_A = [m,df_NG.index.values[i][0],df_NG.index.values[i][1]]
ここの書き方が大変にエレファント。zipかなんか使えば行ける気がするけど、まあ動くから良いや。
プログラム全容
import openpyxl
import pandas as pd
import numpy as np
import pulp
df_raw = pd.DataFrame(
{1: {(1, 0): 0, (1, 1): 1, (2, 0): 0, (2, 1): 0, (3, 0): 0, (3, 1): 0, (4, 0): 2, (4, 1): 0,
(5, 0): 0, (5, 1): 0, (6, 0): 0, (6, 1): 0, (7, 0): 0}, 2: {(1, 0): 0, (1, 1): 1, (2, 0): 0,
(2, 1): 0, (3, 0): 0, (3, 1): 0, (4, 0): 0, (4, 1): 0, (5, 0): 2, (5, 1): 0, (6, 0): 0, (6, 1): 0,
(7, 0): 0}, 3: {(1, 0): 0, (1, 1): 0, (2, 0): 2, (2, 1): 0, (3, 0): 0, (3, 1): 1, (4, 0): 0,
(4, 1): 0, (5, 0): 0, (5, 1): 0, (6, 0): 0, (6, 1): 0, (7, 0): 0}, 4: {(1, 0): 2, (1, 1): 0,
(2, 0): 0, (2, 1): 0, (3, 0): 0, (3, 1): 0, (4, 0): 0, (4, 1): 1, (5, 0): 0, (5, 1): 0, (6, 0): 0,
(6, 1): 0, (7, 0): 0}, 5: {(1, 0): 0, (1, 1): 0, (2, 0): 0, (2, 1): 0, (3, 0): 2, (3, 1): 0, (4, 0): 0,
(4, 1): 0, (5, 0): 0, (5, 1): 0, (6, 0): 0, (6, 1): 1, (7, 0): 0}, 6: {(1, 0): 0, (1, 1): 0, (2, 0): 0,
(2, 1): 0, (3, 0): 0, (3, 1): 0, (4, 0): 0, (4, 1): 0, (5, 0): 0, (5, 1): 0, (6, 0): 2, (6, 1): 1,
(7, 0): 0}, 7: {(1, 0): 0, (1, 1): 0, (2, 0): 0, (2, 1): 0, (3, 0): 0, (3, 1): 0, (4, 0): 0,
(4, 1): 1, (5, 0): 0, (5, 1): 0, (6, 0): 0, (6, 1): 0, (7, 0): 0}, 8: {(1, 0): 0, (1, 1): 0,
(2, 0): 0, (2, 1): 0, (3, 0): 0, (3, 1): 0, (4, 0): 0, (4, 1): 0, (5, 0): 0, (5, 1): 0, (6, 0): 1,
(6, 1): 0, (7, 0): 0}})
df_raw.index.set_names(["date","time"],inplace=True)
list_m = df_raw.columns.to_list()
list_da= df_raw.index.to_list()
# 問題の定義
ShiftScheduling = pulp.LpProblem("ShiftScheduling", pulp.LpMinimize)
# 変数宣言
x = {}
for m in list_m:
for d,a in list_da:
x[m, d, a] = pulp.LpVariable("x({:},{:},{:})".format(m,d,a), 0, 1, pulp.LpInteger)
# 目的関数
ShiftScheduling += sum(x[m, d, a] for m in list_m for d,a in list_da),"Target"
# 制約条件1:全シフトに2人以上が出勤
for d,a in list_da:
ShiftScheduling += pulp.lpSum(x[m, d, a] for m in list_m) >= 2
# 制約条件2:全勤務者が3回以上出勤
for m in list_m:
ShiftScheduling += pulp.lpSum(x[m, d, a] for d,a in list_da) >= 3
# 制約条件3:夜勤忌避と有給希望には応える
list_A=[]
list_B=[]
for m in list_m:
df_NG=df_raw[df_raw[m]>=1.0]
for i in range(len(df_NG.index.values)):
list_A = [m,df_NG.index.values[i][0],df_NG.index.values[i][1]]
list_B.append(list_A)
for m,d,a in list_B:
ShiftScheduling += x[m, d, a] == 0
# 制約条件4:連続勤務はしない
list_da1 = list_da[:-1]
list_da2 = list_da[1:]
for i in range(len(list_da1)):
list_da1[i]=list_da1[i]+list_da2[i]
for m in list_m:
for d1,a1,d2,a2 in list_da1:
ShiftScheduling += x[m, d1, a1]+x[m,d2,a2] <=1
# 出力
results = ShiftScheduling.solve()
print("optimality = {:}, target value = {:}".format(pulp.LpStatus[results], pulp.value(ShiftScheduling.objective)))
kekka=[]
for v in ShiftScheduling.variables():
kekka = kekka+[int(pulp.value(v))]
kekka=pd.DataFrame(np.array(kekka).reshape(8,13).T)
print(kekka)
# excelにしたい時はkekka.to_excelとか使う