まえがき
自学自習で進めている機械学習の力量向上を目指して、不動産の金額予測をしてみました。
対象は東京都内のマンション約1万件。
広さや築年数、駅距離等の物件情報に、地域の人口や所得、駅の乗降客数の属性を加えて予測をしました。
ざっくりとした結論
不動産の価格程度であれば、ディープニューラルネットワークを利用しなくても十分な精度を得ることができました。
予測に利用したアルゴリズムはランダムフォレストとxgboost。
定性的な評価として、ランダムフォレストの場合の決定係数は0.79、xgboostの場合は0.83となり、ややxgboostのほうが精度が高い結果で、定量的にも理由は不明ですがランダムフォレストの予測では、高級住宅地の価格を過小に予測している傾向があったのに対して、xgboostの場合にはそのような傾向はなくなっているように感じました。
手順
具体的な処理手順について、コードを抜粋してご紹介します。
データ読み込み
スクレイピングにより取得したデータをGoogleDriveに格納し、そのデータをGoogle Colaboratoryが参照する形で分析を実施しています。
GoogleDriveからの読み込みは、以下のようにdriveにマウントをした上で、Googleドライブのルートディレクトリからのパスを渡すことで読み込みが可能です。
from google.colab import drive
drive.mount('/content/drive')
modelFilePath="drive/My Drive/propertyAnalizeData.csv"
model_data= pd.read_csv(modelFilePath,dtype=category_dtype,index_col=indexColumn)
OneHotEncoding
データ読込後、前処理としてデータ内から異常なデータを取り除いたあと、カテゴリ変数はpandasのget_dummies関数を用いてOneHotEncodingします。
ダミー変数に変換したい列データとして、dataframe内のobject型の列を指定しています。
import pandas as pd
X_model = pd.get_dummies(X_model,dummy_na=True,columns=X_model.select_dtypes(include=object).columns.values)
欠損値の補完
欠損値の補完はSimpleImputerを利用しています。変換後のdataframeに対しても変換前のindexを利用するためindex=X_model.index.values.tolist()と記載しています。
from sklearn.impute import SimpleImputer
imp = SimpleImputer()
imp.fit(X_model)
X_model = pd.DataFrame(imp.transform(X_model),columns=X_model.columns.values,index=X_model.index.values.tolist())
標準化
各特徴量のスケールの偏りを無くすため、以下のようにStandardScalerによる標準化を行っています。
from sklearn.preprocessing import StandardScaler
ssc=StandardScaler
X_model = ssc.fit_transform(X_model)
パラメータチューニング
パラメータチューニングはHyperOptを利用。
xgb_reg_paramsの変数として与えられたパラメータの組み合わせの中から、ベストモデルを抽出するようにしています。
ベストモデルの判定の際には、一つのパラメータの組み合わせに対してcross_validateを用いた複数回試行を行って、決定係数の平均値を取得しています。
そのような試行を複数のパラメータの組み合わせに対して実施し、それぞれで得られた決定係数の大小を比較して、最も優れたパフォーマンスを示したパラメータを与えたモデルがbestEst変数に残るようにしています。
xgboostの場合のコードは以下のような感じです。
実際に実装しているコードはクラス化&汎用化しており、そのコードから必要箇所を抜粋&簡素化して記載しているので、うまく動作しない可能性もあるのですがイメージを掴んでいただけると。
なお、google Colaboratoryで動作させる場合にはあらかじめxgboostのインストールが必要です。
!pip install --upgrade xgboost
from sklearn.model_selection import cross_validate
from xgboost import XGBRegressor
from hyperopt import fmin, tpe, STATUS_OK, STATUS_FAIL, Trials
from sklearn.model_selection import KFold
xgb_reg_params = {
'learning_rate': hp.uniform('learning_rate', 0.01, 0.3),
'n_estimators': hp.choice('n_estimators', np.arange(100, 201, 50)),
'max_depth': hp.choice('max_depth', np.arange(3, 16, 2, dtype=int)),#決定木の深さの最大値
hp.choice('min_child_samples', np.arange(20, 41, 10, dtype=int)),
'min_child_weight': hp.choice('min_child_weight', np.arange(1, 40, 2, dtype=int)),#決定木の葉の重みの下限
'colsample_bytree': hp.choice('colsample_bytree', np.arange(0.3, 0.8, 0.2)),
'subsample': hp.uniform('subsample', 0.9, 1),#ランダムに抽出される標本(データ)の割合
'gamma': hp.loguniform('gamma', -8, 2),#葉の数に対するペナルティー
'random_state': 1,
}
xgb_para = dict()
xgb_para['reg_params'] = xgb_reg_params
space = dict()
space["cls"]=XGBRegressor
space["cls_params"]=xgb_para
space["X"]=X
space["y"]=y
trials=Trials()
max_evals=10 #パラメータ探索回数
fmin(fn=_train, space=space, algo=tpe.suggest, max_evals=max_evals, trials=trials, rstate=np.random.RandomState(0))
loss=float('inf')
for item in trials.trials:
result = item['result']
if ("loss" in result.keys() and loss > result["loss"]):
loss = result["loss"]
bestEst= result["est"]
def _train(params):
X = params["X"]
cls=params["cls"]
cls_params=params["cls_params"]
est = cls(**cls_params)
evaluator = params["eva"]
y = params["y"]
try:
loss=_getLossValue(est, X, y)
return {'loss': loss, 'status': STATUS_OK, 'est':est}
except Exception as e:
return {'status': STATUS_FAIL,
'exception': str(e)}
def _getLossValue(est, X, y):
cv = KFold(n_splits=3, shuffle=True, random_state=1)
cross_validate_scores = cross_validate(estimator=est
, X=X
, y=y
, cv=cv
, scoring=['r2'])
value= cross_validate_scores['test_r2'].mean()
loss= 1-value
return loss
結果
予測金額と実際の金額をプロットした散布図は以下のようになります。
なお、今回は単位面積当たりの金額を予測しています。
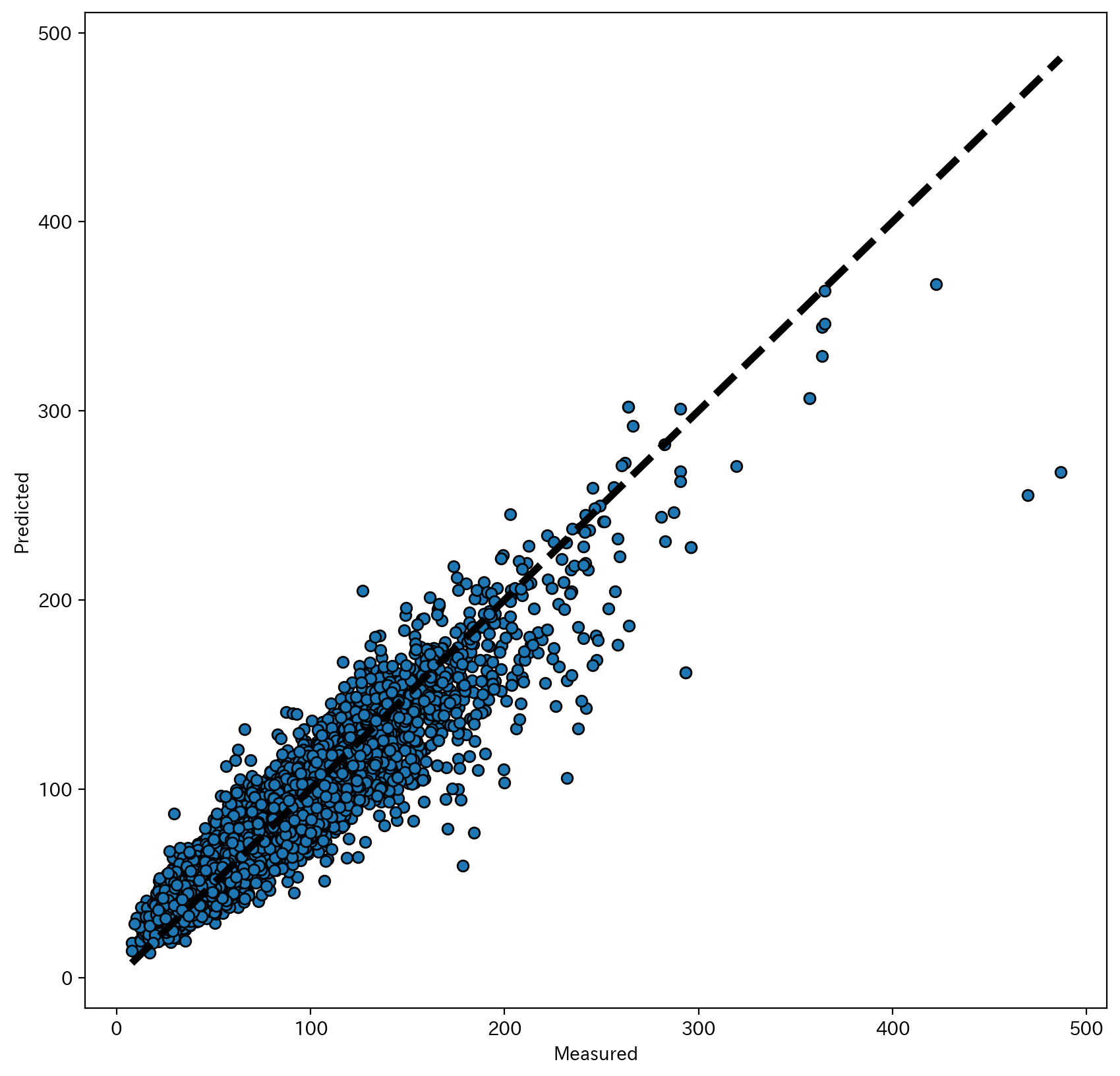
散布図を見た印象として、高価格帯はサンプルデータが少ないせいか精度はイマイチですが、全体的には概ね良好な結果となったかなと思っています。
あと、利用しているデータが募集価格であり成約価格ではないので、実際の成約価格よりちょっと高めに出ている可能性も。(交渉により募集価格>成約価格となっているケースもあるかと。)
「特徴量エンジニアリングはデータサイエンスの芸術的な部分である」という言葉があるように、コードを書くのはそれほど難しくはないですが、精度向上に役立つデータの収集がやっぱり難しいかなと感じました。
実際、分析データには各マンションのエレベータ設置有無をデータとして保持していないため、エレベータを設置していないマンションに対する予測価格が実勢価格よりも高めに出る、といった傾向も見つかっています。
余談
完全な余談ですが、今回のデータ収集を通じて東京にはとんでもない金額のマンションが存在することを知りました。一例ですが、この辺の金額は卒倒するくらいやばいですよ。
お暇があれば調べてみても良いと思いますが、調べないほうがいいかも。
- グランドヒルズ元麻布
- ザ 千代田麹町タワー
- ザ・パークハウスグラン南青山
- ブランズ六本木ザ・レジデンス
- 虎ノ門ヒルズレジデンス
港区の物件がわかるように色付けした結果も載せておきます。
赤いプロットが港区の物件ですが、高価格帯はほぼ港区。
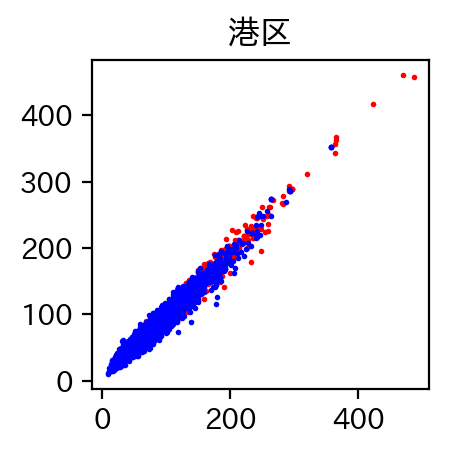
あー世の中って不平等。