この記事は私, wataokaが1年間をかけて作り続けた超大作記事です.
総文字数は8万を超えていますので, お好みのところだけでもみていってください.
ついにこの時が来ました!!!!!
— 綿岡 晃輝 (@Wataoka_Koki) December 31, 2020
1年間書き続けたQiita記事です!!!!!
ご覧下さい!!!!!https://t.co/eKBwP1zoeB
俺的ランキング
動画での解説も挑戦してみました!
ぜひぜひご覧下さい!

第3位: Likelihood-Free Overcomplete ICA and Applications in Causal Discovery
wataokaの日本語訳「尤度が必要ない過完備ICAと
因果探索における応用」
- 種類: ICA
- 学会: NeurIPS2019
- 日付: 20190904
- URL: https://arxiv.org/abs/1909.01525
前提知識
まず, ICA(独立成分分析)とは, 以下のような計算モデルを扱うものです. (線形の仮定をおいたversion)
x = As
ここで,
- x: 混合成分 (mixture components)
- s: 独立成分 (independent components)
- A: 混合行列 (mixture matrix)
です.
どのような状況かと言うと, 独立成分sが混合行列Aによってごちゃ混ぜにされた結果が混合成分xと言う状況です.どのようなタスクかと言うと, 我々観測者はxのみを観測し, sとAを予測するというタスクです. 例えば, 部屋の中に複数人の人が話をしており, 複数個のマイクが設置されているとします. 人々はワイワイと話しているので, マイクで観測できる音声は複数音声が足し合わされた結果となります. 我々観測者はマイクの音声(x)しかデータを取得することができません. マイクの情報から, それぞれの人間の音声(s)を分解したいとします. このような状況がまさにICAの出番となります. (マイクのデータがx, 元の音声がs, 人間iとマイクjの距離などから決定される重み$a_{ij}$を要素とする行列がA).
ICA手法の中ではFastICAなどが有名です. FastICAは「様々な分布が混ざるとガウス分布になることから, 独立成分に分解すると非ガウスになるだろう」という仮定から, $A^{-1}x$(つまり$s$)が非ガウスになるようにAを探索します. 探索はEMアルゴリズムなどが用いられます. 非ガウス性を測るためには様々な関数が提案されており, Hyvarinenによると, $\log{\cosh{u}}$などが有効だと提案されています.
基本的にICAはxの次元とsの次元が同じである状況を扱いますが, sの次元の方がxの次元より多い状況を扱うものをOvercomplete ICA(過完備独立成分分析)と言います. 自明なことですが, 観測できる情報の方が少ないので, 通常のICAより難しいタスクとなります. 今回紹介する論文はOvercomplete ICAを解く方法を提案したものです..
概要
既存OICAの悪いところとして以下が挙げられます.
- 独立成分の分布が非ガウスであるだろうという仮定が強い.
- EMアルゴリズムにおいて独立成分の事後分布の推論にかかる計算コストが高い.
LFOICAでは, 独立成分に分布の仮定をおかず, 勾配法でAを求めます.
手法
General Framework
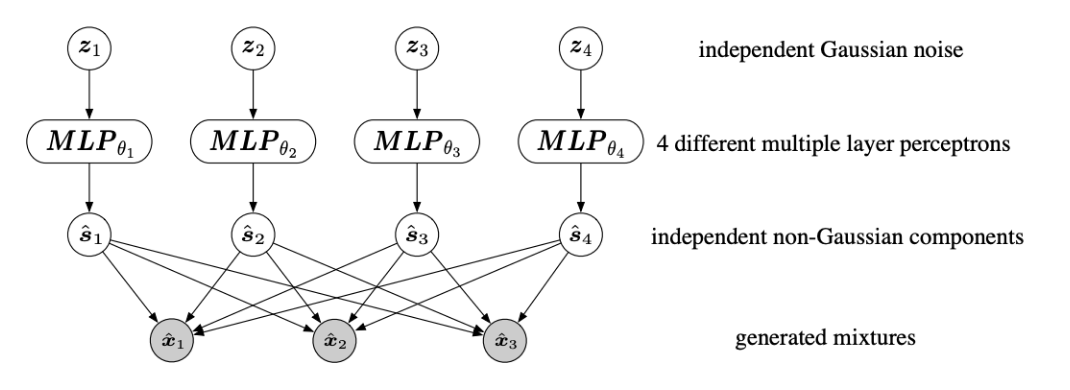
(数式的な)モデルは一般的なICAモデルの以下を考えている.
x = As (1)
そして, フレームワークとしては, 上の図のように, 独立成分を生成するノイズをz, 独立成分をs, 観測変数である混合成分をxとして, z→sを4層のMLP, s→xを式(1)としている.
学習するパラーメータはAとθ(MLPの重み)なわけだが, それは以下のようにMMDを最小化するように勾配法を適応することで学習する.
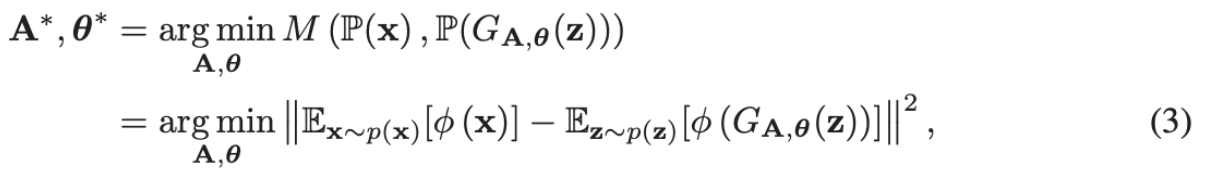
Algorithm1
- ガウスノイズからzのミニバッチをサンプルする.
- zをMLPに入力し, sを得る.
- 観測変数の分布p(x)からxのミニバッチをサンプルする.
- それらのミニバッチで式(3)を最適化する
- 最大イテレーションに達するまで1-4を繰り返す.
いろんな工夫
Sparsity
大体において混合行列Aはスパースになるので, 式(3)にLASSO正則化を加えた.
LASSO正則化のsoft閾値として, stochastic proximal gradient method[Nitanda2014]を用いた.
Insufficient data
データが十分に存在しない場合は独立成分に対してパラメトリックな仮定を置くのも有効.
混合ガウス分布でモデル化し, reparameterization tricなどを上手く使って学習すれば良い.
実験
OICAの人工データを用いて実験を行なった. 下の表は推論した混合行列と真の混合行列との2乗和誤差(以下, MSE).
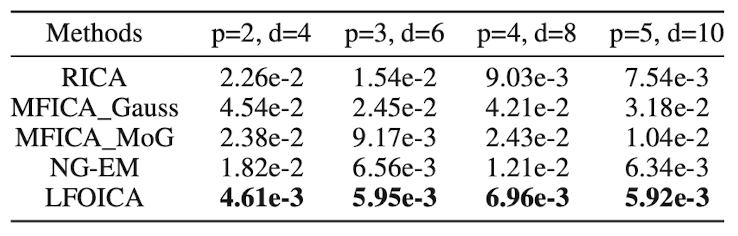
OICAは要素の順序の非決定性(permutation indeterminancy)とスケールの非決定性(scaling indeterminancy)が証明されている. 上記の実験では, 他のOICA手法と比較を行うために, 以下の対処を行なっている.
- permutation indeterminancyを取り除くために, 独立成分の分布をそれぞれ異なるものにし, 推定後に正しい分布に並び替えてからMSEを計測した. (具体的には, 独立成分の分布をラプラス分布として, それぞれでvarianceを変えた.)
- scaling indeterminancyを取り除くために, 真の行列と推定行列の最初の列のL2ノルムを1にする正規化を行なった.
wataokaのコメント
OICAほど抽象的で広範囲に適用できる問題に対して, ニューラルネットの力が遺憾無く発揮され, 人類の叡智がまた進んだ気がした. (絶対言い過ぎ) まぁとにかく, 読んでいた時に, 「おぉ。。こんなに大事な問題が2019年でもまだ先に進んでいるのか。。研究って面白いなぁ。。」と感動した.
また, ここでは省略したが, OICAを解くことによって未観測共通原因を含む因果探索を行うことができる. そこへの適用も面白く, 自分の研究のためになった. (動画では解説する予定.)
第2位: Counterfactual Fairness
wataokaの日本語訳「反実仮想公平性」
- 種類: fairness, counterfactual
- 学会: NIPS2017
- 日付: 20170320
- URL: https://arxiv.org/abs/1703.06856
前提知識
機械学習には公平性(以下, fairness)という分野があります. fairnessは機械学習による自動的な判断システムが特定のグループが不当な判断を行わないようにする分野です. 例えば, ローンの申請を認めるかどうかのシステムにおいて, 男性には優しく女性には厳しいなんてことがあれば大問題です. そのようなことに陥らないように, アルゴリズム側で正則化などをかけたり, データ自体に前処理を加えたり行います.
Fairnessを語る上で「何を持って公平か」という公平性の定義は避けることができません. ここでは, 代表的な公平性の定義を2つ紹介します. (本当は10以上存在している.)
Demographic Parity
簡単のため二値分類とします.
- $\hat{Y}$: 分類器の予測
- $S$: センシティブ属性 (例:女性or男性)
とした時, 以下を満たすならその分類器はdemographic parityを満たす.
P(\hat{Y}|S=0) = P(\hat{Y}|S=1)
つまり, 予測分布がセンシティブ属性間において不変であるべきという定義です. もう少し簡単に言えば, 分類器が0と出力する確率も1と出力する確率もセンシティブ属性間において同じであるべきという定義です.
Equal Opportunity
簡単のため二値分類とします.
- $\hat{Y}$: 分類器の予測
- $Y$: ラベル
- $S$: センシティブ属性 (例:女性or男性)
とした時, 以下を満たすならその分類器はequal opportunityを満たす.
P(\hat{Y}=1|Y=1,S=0) = P(\hat{Y}=1|Y=1,S=1)
つまり, true positive rateがセンシティブ属性間において不変であるべきという定義です. もう少し簡単に言えば, 答えが1である時, 分類器が1と出力する確率がセンシティブ属性間において同じであるべきという定義です.
上記のように, 公平性の定義には様々なものが存在します. この論文では, 新しい公平性の定義counterfactual fairnessを提案しました.
概要
- counterfactual fairnessを定義した.
- counterfactual fairnessはindividual fairness
- 実世界と反実世界(別のdemographicグループに属す世界)において決定が同じという直感を捉えている.
- low schoolの実データにおいて提案するフレームワークが成功したことを示した.
2 Background
読むのめんどくさい方は3まで飛ばしてOK.
2.2 Causal Models and Counterfactuals
causal modelは次を満たす三つ組(U, V, F)
- Vは観測変数集合
- Uは潜在背景変数集合で, 他のどの変数にも引き起こされない.
- Fは関数集合{f1,...,fn}で, Vi∈Vに対してVi=fi(pai, U_pai).
- paiはViの親変数集合
- U_apiはViの潜在背景変数集合
- それぞれの方程式は構造方程式(structural equations)と呼ばれる.
変数Viに対する介入(intervention)とは,
構造方程式Vi = fi(pa_i, U_{pa_i})をVi=vに置き換えること.
そもそも構造方程式の集合Fを知っているというのはものすごく強い仮定ではあるが, それによってcounterfactualな量を計算することができる.
counterfactualはZに関する方程式をZ=zに置き換えた状況において, U=uが与えられた時のYの解としてモデル化される. これをY_{Z←z}(u)と書いたり, 簡潔にY_Zと書いたりする.
Counterfactual inferenceは次の3step.
- Abduction: Uの事前分布P(U)について, evidence Wで事後分布P(U|W)を計算する.
- Action: 構造方程式におけるZを介入値zに変更する. 変更後の方程式をFzとする.
- Prediction: Fzを用いて残りのVの値を計算する.
3 Counterfactual Fairness
- A: センシティブ属性
- X: 残りの属性
- Y: ラベル
- $\hat{Y}$: 分類器の予測
とし, 因果モデル(U, V, F) where V:=A∪Xが与えられたとする. この時, 以下を満たせば, 分類器はcounterfactually fair.
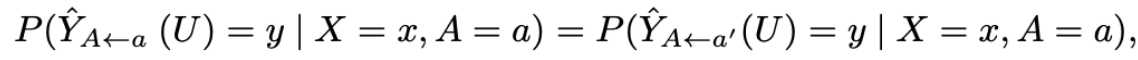
つまり, ある人物(X,A=0)がもし(X,A=1)だったら(そんなパラレルワールドがあったら), 分類器はどちらの世界でもその人物に対する予測値は同じであるべきという公平性の定義となります.
Lemma 1.
Gをmodel(U, V, F)の因果グラフとする. その時, Y^がAの非子孫から予測する関数であれば, Y^はcounterfactually fairである.
4 Implementing Counterfactual Fairness
Y^を因果グラフにおいてAの非子孫の関数に制限する.
4.1 Algorithm
AlgorithmはデータセットDと因果モデルMを受け取る.
- 各データ点に対して, m個のMCMCサンプルU1(i),...,Um(i) ~ P_M(U|x(i), a(i))をサンプルする.
- D’をaugmented dataとし, Dにおけるデータ点(a(i), x(i), y(i))をm個のデータ集合{(a(i), x(i), y(i), u(i)j)}に置き換える.
- θ^ ← argmin_θ (sigma L)

Deconvolution perspective
(deconvolutionはおそらくdisentanglement的な意味で言ってる?)
このアルゴリズムはdeconvolutionアプローチだと理解することができる. 要するに, 観測変数A ∪ Xが与えられた時に, 潜在的なソースUを抽出し, 予測モデルに組み込んでる.
counterfactualな仮定はデータからfairな潜在ベクトルを抽出する系の全ての手法の基礎として組み込まれるべき. Louizos et al.はP(U|X, A)を抽出するために, DAG A→X←Uを用いた. Xが与えられた下でUとAは独立なので, この制約はP(U|A=a, X)=P(U|A=a’, X)を満たすような事後分布P(U|X, A)を生成することになる. しかし, これはcounterfactual fairnessの必要条件でも十分条件でもない. AとUが与えられたXのモデルは因果的に正当化されなければならない.
モデルMは与えられたUとpa_i間の関係に依存する経験損失によって学習することができる. 要するに, Mで学習される. Y^ではない.
4.2 Designing the Input Causal Model
完全な決定的モデルを指定する必要はなく, 構造方程式は条件付き分布として緩和できる.
特に, counterfactual fairnessの概念は強さが増す3段階の仮定の下で保持される. (level3が最も強い仮定)
Level 1: Y^はAの非子孫な観測のみを用いて構築される. これは, 一部の因果関係を使うやり方だが, ほとんどの問題において, 完全にAに非子孫な観測などほとんどない. (ほとんどにおいて属性はセンシティブ属性の下流)
Level 2: 潜在背景変数は観測可能な変数の非決定的原因として機能し, 明確なドメイン知識に基づいている. (観測可能な変数は潜在背景変数によって非決定的)
Level 3: 潜在変数を持った完全に決定的モデルを仮定する. 例えば, 分布P(Vi | pa_i)は誤差モデルVi = fi(pa_i)+eiとして扱われる. 誤差項eiは観測変数から計算されたとしてY^への入力となる. これはfairな予測器Y^によって抽出された情報を最大化する.
4.3 Further Considerations on Designing the Input Causal Model
例えば, counterfactual fairnessの定義は
P(Y^=1 | do(A=a)) = P(Y^=1 | do(A=a’))
とかだといけないのか?
(つまり, センシティブ属性に対して介入した時のY^への効果の平均で, 個人ではない.)
これは公平である保証がない. なぜならば, 半分の個人がnegativeな差別を受けていて, 半分の個人がpositiveな差別を受けていたとしても等式をみてしてしまうから.
5 Illustration: Law School Success
タスク: LSAT, GPAからFYAを予測する.
- LSAT: 入学試験の成績
- GPA: 入学前の成績
- FYA: 卒業年次の成績 (target)
Level1では, LSAT, GPA, FYAはraceとsexでバイアスされているから, counterfactually fairなpredictorを構築するためにはLSAT, GPA, FYAという観察データを使用することはできない.
Level2では, 学生の知識(K)という潜在変数はGPA, LSAT, FTAに影響していると仮定する. 下記のモデルについて, 観測された学習セットを用いてKの事後分布を推論する. Kを用いて構築された予測器のことをFair Kと呼ぶ.

Level3では,GPA, LSAT, FYAをraceやsexに依存しない誤差項を持つ連続変数としてモデル化する(raceやsexは順番に互いに相関している可能性はある). つまりこんな感じ.
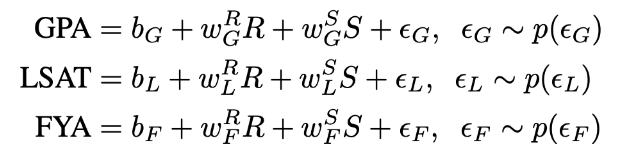
まず, raceとsexを使用し, GPAとLSATを予測する二つのモデルをfitさせることによって, 誤差項を推定する. (つまりUの推定)
ε_G = GPA - Y^_GPA
ε_L = LSAT - Y^_LSAT
この予測誤差項をε_G, ε_LをFYAの予測のために使用する.
順に
- 全ての仮定を満たしていない. (Full)
- Lv1 (Unaware)
- Lv2 (Fair K)
- Lv3 (Fair Add)
の結果
↓
Accuracy
- Fullモデルはraceとsexを使用して, 正確にFYAを再構成しているのでRMSEはもっとも低く抑えられているが, fairにはならない.
- Unawareモデルはunfairな変数GPA, LSATを使用しているが, raceとsexは使用していないので, FullモデルよりRMSEは高くなってしまっている.
- 一つ目の提案モデルであるFair Kはlevel2の仮定が置かれており, RMSEはもっとも高い.
- Fair AddはLevel3の仮定が置かれており, Fair Kより少しRMSEが低く抑えられている.
Counterfactual Fairness
ベースライン手法がcounterfactually fairであるかどうかをempiricallyにテストしたい. そのために, Figure2のLevel2のグラフが真のモデルであると仮定した. そして, 観測データを用いて因果モデルのパラメータをfitさせ, そこからのサンプルによってcounterfactual fairnessを評価した. 具体的には観察された人種と性別, また反実仮想の人種や性別の変数のいずれかを与えられたモデルからサンプルを生成する. そして, 実データと反実データの両方でモデルをfitさせる. FYAの予測分布がそれぞれに対してどれほど変化するかをプロットする. Figure2において青色の分布は実データに対するFYAの予測で, 赤色の分布は反実データに対するFYAの予測.
Fullモデルはsexをのぞいてcounfatectual fairnessが悪い.
UnawareモデルもFullモデルよりマシだが大体同じ.
なぜ, sexに対してモデルはfairになるのかを見るために, counterfactual dataを生み出すDAGの重みを見た. (male, female)からGPAへの重みは(0.93, 1.06)で(male, female)からLSATへの重みは(1.1, 1.1)となっていた. つまり, sexとGPA/LSATの間における因果関係が非常に弱いために, 単にsexとの関係では公平になっていた.
wataokaのコメント
Counterfactual fairnessの定義は非常に直感的で説得力のある定義だと感じます. そして, counterfactual fairnessの定義であるセンシティブ属性に対する介入がラベルに影響しないということは, 因果推論におけるセンシティブ属性のラベルに対する因果効果がないと言い換えることができます. センシティブ属性が因果的に結果と繋がっていないことは機械学習サービスを提供する側としては非常にユーザー側への力強い主張となるかと思います.
やはり, counterfactual quantityを計測することが非常に困難であることがネックになるかと思います. どれほど識別可能であるのか, boundは取れるのかなどの理論的な解析はWu et al.の論文 を参照されたいです.
第1位: Interpreting the Latent Space of GANs for Semantic Face Editing
wataokaの日本語訳「意味論的顔編集のためのGANの潜在空間の解釈」
- 種類: GAN
- 学会: CVPR2020
- 日付: 20190725
- URL: https://arxiv.org/abs/1907.10786
概要
最新の画像編集手法です.

これまでの研究では, GANが学習する潜在空間はdistributed representationに従うと仮定してきたが, ベクトル演算現象が観測されてきています. この研究では, GANが学習した潜在意味空間を解釈することで意味論的顔編集を行うための新しいフレームワークInterFaceGANを提案しました. わかりやすく言い直すと, 「潜在空間でうまいことして顔編集したい!」という研究です.
この研究では, 顔生成のためにGANの潜在空間にどのように異なる意味論がエンコードされているかを詳細に研究されています. よく訓練された生成モデルの潜在コードは線形変換後, disentangledされた表現を学習していることが知られています. その表現を利用するために部分空間射影を用いることで, entangledされた(もつれた)意味論を切り離し, 正確な顔属性のコントロールを行います. 性別, 年齢, 表情, メガネの有無などに加えて, GANが誤って生成した画像を修正することも可能となります. また, 顔生成を自然に学習することによって, disentangleされ, コントロールしやすい顔属性表現を獲得することができます.
Related Work
GAN Inversion (GANの逆変換)
画像空間から潜在変数への逆写像をいるための手法のことをGAN Inversionと言います. [42], [43], [44] (論文中の参照番号をそのまま記載.)
既存手法として, 以下がある.
- インスタンスレベルの最適化手法 [45], [46], [47]
- generatorと対応するencoderの学習 [48], [49], [50]
最近の研究では, 以下がある. - エンコーダを用いて最適化における良い初期値を見つける. [51], [52]
- Guらは良い再構成のために潜在空間の次元を増やすことを提案している. [53]
- Panらはモデルの重みとともに潜在変数の最適化を試みしている. [54]
- Zhuらはピクセルの値を復元することと共に, 意味論的情報も考慮に入れている. [55]
(論文中の参照番号をそのまま記載.)
InterFaceGAN
- 与えられているもの
- 画像
- 画像に関する属性
- well-trainedなGANのgenerator
- フレームワーク (というか編集手順)
- 属性情報を持つ画像をGAN Inversion(上のRelated Work参照)で埋め込む.
- 属性情報を持つ潜在変数が手に入る.
- 潜在変数たちを属性aで線形分類する.
- 潜在空間上での決定境界の超平面が手に入る.
- ある潜在変数を決定境界の超平面と直交する方向に移動させる.
- 移動させた潜在変数を生成すると, 属性aに関して編集された画像が手に入る.
以上の手順がInterFaceGANです. お分かりの通り, GANのアーキテクチャなどに関する制約はほとんどなく, 潜在変数から画像を生成できる大きな関数と考えます. そして, 豊かな表現力を持つgeneratorを利用して, その潜在空間上で潜在変数をうまく移動させることで画像編集を行います. 潜在変数を何かしらの属性で線形分類することで得られる決定境界の法線ベクトルをその属性に関する情報のベクトルと考え, 編集に利用していますが, これは豊かな表現力を持つgeneratorが属性情報に関して"いい感じに潜在変数を配置している"という仮定のもと成り立つ方法となります. そして, その手法が最初に示した結果の通り, 大変うまく編集できていますので, その仮定はあながち間違っていないと言えます. ということで, この論文は「潜在変数を移動させることで簡単に編集できます!」ということ単に提案しているだけでなく, 学習済みGANの潜在表現について大きな理解を与えてくれている論文となります. 他にも非常に面白い結果を与えてくれていますので, 一つ一つ見ていきましょう.
面白い結果その①「潜在変数は属性の強さ順に並んでいる」
下の画像の左側に"Distance"と書かれていると思います. これは決定境界からの距離を意味しています. 決定境界からの距離が0(決定境界上)である潜在変数を生成すると中段のような画像が得られますが, その潜在変数から決定境界に直交する方向にぶっ飛ばすと, それぞれの属性が以下のようになります.

Poseでは真横を向き, Smileでは爆笑したり,... とにかく面白い結果になったかと思います. このことから潜在変数は潜在空間上で属性の強さ順にある程度は並んでいるのではないかと言えます. (極端な例しか載せていないところから完璧にそうではなさそう?)
面白い結果その②「潜在空間には"出来の良さ"という情報もある」
この論文は以下の実験を行いました.
- 画像を適当にサンプル.
- 出来の良い画像と出来の悪い画像を手動でラベリング.
- そのラベル情報を用いて, 先ほどと同じように決定境界を引き, 法線ベクトルを得る.
- そして, 出来の悪い画像に対して, 法線ベクトルの方向に移動させて, 画像を生成.
すると下のように, 画像の出来がよくなります...

「ほんまか?笑」としか思えないような結果ですが, ほんまらしいです. 大変驚きましたが, まぁGANの潜在空間は高次元のだだっ広い空間なので, 綺麗に画像を出力できない場所があってもおかしくはありません. 例えば事前分布において非常に尤度の低い範囲においてはgenerator側が想定できていない値になるので, 必然的に出来は悪くなるでしょう. 何はともあれ, GANの潜在空間には"出来の良さ"という情報もありそうです. (サンプル数が非常に少なく, 確か定量的評価もなかったため, 断言はできない.)
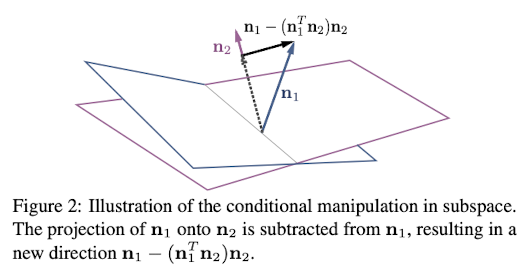
面白い結果その③「InterFaceGANは条件付け編集も可能」
筆者はConditional Manipulationと読んでいる手法です.
属性1と属性2があるとします. 今, 属性1に関して編集したくて, 属性2はしっかり固定したいとします. その時に, 属性1と属性2について決定境界を得て, それぞれの法線ベクトル$\bold{n_1}, \bold{n_2}$を得ます. ベクトル$\bold{n_1}$からベクトル$\bold{n_2}$の成分を取り除くと, $\bold{n_1} - (\bold{n_1}^{T}\bold{n_2})\bold{n_2}$となります. このベクトルを用いて編集すると, 属性2の決定境界には平行であり, できるだけ属性1の決定境界を跨ぎやすいベクトルとなっていますので, 属性2を固定しながら属性1を編集できます.
結果, 以下のようになります. 非常に綺麗に条件付けに成功しているかと思います. ここでは, オリジナル画像から, 年齢を固定, 性別を固定, メガネを編集した時の結果となります.
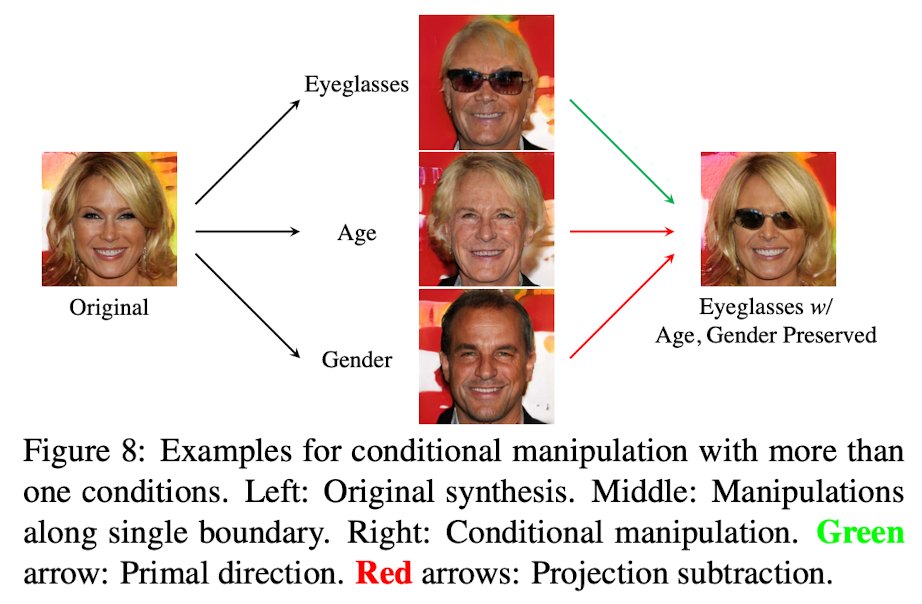
wataokaのコメント
Detecting Bias with Generative Counterfactual Face Attribut Augmentationの理論的かつ拡張的な論文で, 面白い結果から面白いGANに対する理解ができる面白い論文.
実はwataokaはこの論文と完全に同じ手法を思いついており, コーディングも進めていた矢先に世に出てきた論文です. Conditional Manipulation, そしてConditional Manipulationの一般化まで完全に同じ式を導出していました. この論文を読んだ時, 血の気が引く思いもしましたが, 同時に自分以上に良い解析であり, 良い書き方であり, 良い論文だなと感服しました. この論文から多くのことを学びました. 隅から隅まで読み込み, 自分にないところを吸収しまくってやりました. そんな僕の研究生活の中で思い出に残るこの論文を第一位にさせていただきました. もちろんそんな私情を差し引いても非常に興味深い結果が多いかと思います.
論文100本解説
4本目の論文: Unsupervised Discovery of Interpretable Directions in the GAN Latent Space
wataokaの日本語訳「GANの潜在空間における解釈可能方向の教師なし発見」
- 種類: GAN
- 学会: ICML2020
- 日付: 20200210
- URL: https://arxiv.org/abs/2002.03754
概要
unsupervised editing. 背景削除の方向を見つけたらしい. sacliency detectionでSOTA.
[1~K]のどれかkをone-hotエンコードし, ε倍する. (d×Kの行列A) * (ε倍されたK次元one-hotエンコードe)でε倍されたAの列を一つ取り出す. その列をzに足した奴がshift. zとz+A(εe)をreconstructor Rに入力し, kとεを予測. AとRの精度を上げることで, 見分けが追記やすいshiftになる.
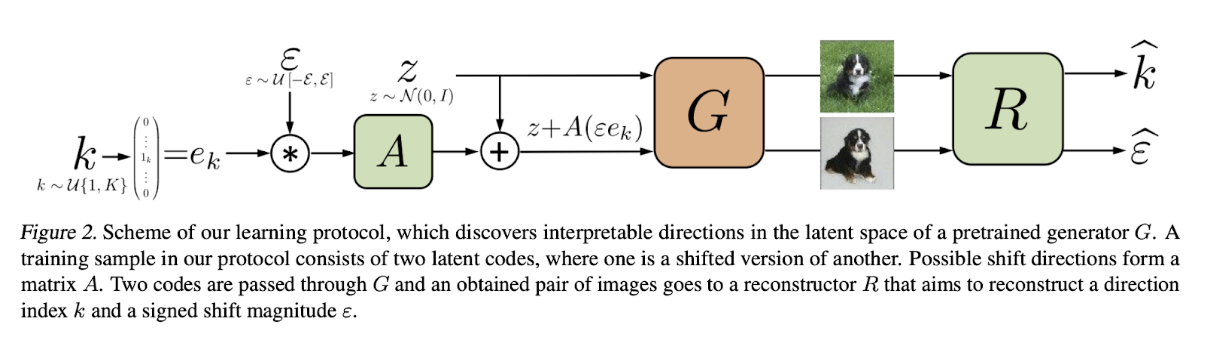
Figure2.
- direction index kをone-hotでエンコード: e_k
- e_kを[-ε, ε]の範囲のどれかの値でかける: ε*e_k (ε: shift magnitude)
- その結果を行列Aにかける.
- zとz+A(ε*e_k)をGに入力.
- Gは二つの画像を生成.
- 生成した二つの画像をRに入力. (R: Reconstructor)
- Rは二つの画像からkとεを予測.
つまり, Aの列がwalkする方向に当たる.
手法 (3. Method)
3.2 Learning
- A: d×K行列
- d: zの次元
- K: 見つけたい方向の数. (これはハイパラであり, 次のsectionで議論している.)
- G: 学習済みgenerator
- R: reconstructor. G(z)とG(z+A(ε*e_k))を受け取り, kとεを予測する. ( R(I1, I2) = (k^, ε^) )
損失関数
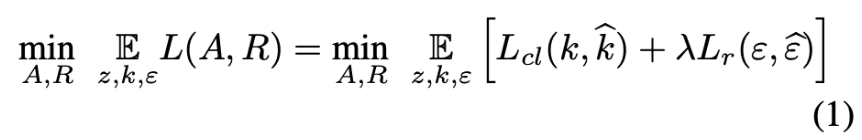
普通にkの損失とεの損失の線形和.
kの損失はcross-entropy
イプシロンの損失はmean absolute error
実験では, λ=0.25とした.
これにより, AはRが区別しやすい画像変換を引き起こす方向を学習することになる.
結果, 人間においても解釈しやすい画像変換をしてくれるようになる.
3.3 Practical details
Generator
4章に書かれてる
- Spectral Norm GAN for MNIST and AnimeFace
- ProgGAN for CelebaA-HQ
- BigGAN for ILSVRC
Reconstructor
- モデル
- ReNer for MNIST and AnimeFaces
- ResNet-18 for Imagenet and CelebA-HQ
- concatnate
- 二つの画像はchannel wiseにconcatnateしている.
- つまり, MNISTでは2ch, 他では6chとして入力している.
Distributions
- latent code
- N(0, I)
- direction index k
- U{1, K}
- shift magnitude ε
- U[-6, 6]
実験
MNIST, AnimeFace, Imagenet, CelebA-HQで実験した. saliency detectionでSOTA.
wataokaのコメント
code: https://github.com/anvoynov/GanLatentDiscovery, まだarXiv論文だがどこかにacceptされそう.
5本目の論文: PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models
wataokaの日本語訳「PULSE: 生成モデルの潜在空間探索によるself-supervised高画質化」
- 種類: GAN, superresolution
- 学会: CVPR2020
- 日付: 20200308
- URL: https://arxiv.org/abs/2003.03808
概要
高解像(HR)なし, 低解像(LR)のみで超解像(SR)を作成できるPULSEを提案.
手法 (3. Method)
- LR: 低解像度画像
- HR: 高解像度画像
- SR: 超解像度画像
- M: 自然画像多様体
- G: generator
- L: lantent space
- I_LR: 低解像度画像 (given)
- DS: Down Scaling
- R: HRをDSした時, LRになるHRの集合.
学習済みGはz→自然画像多様体というmapをしてくれるという仮定の下, ||DS(G(z)) - LR||を最小化するzを探索する. 勾配が得られるので勾配ベース. 探索の工夫としては, 超球面の表面上のみで探索を行う制約をかけてzの尤度をあげている.
3.2 Latent Space Exporation
理想としては, 生成画像G(z)の集合が多様体Mを近似してくれていれば,
||DS(G(z)) - I_{LR}|| \leq \epsilon
というzを見つけるだけでOK.
しかし, G(z)∈Mとなる保証はない.
G(z)∈Mを保証するためには, 事前分布において高い確率のLの領域にいる必要がある.
潜在変数が高い確率の領域にいるようにするために, 事前分布の負の対数尤度の損失項を加える.
事前分布がガウス分布である場合, L2正則としている研究があるが, この正則はベクトルを0に向けて強制するもので, 高次元ガウシアンの質量の大部分は半径√dの球体の表面付近にある. これを回避するために, 事前分布をR^dのガウス分布ではなく√d S^(d-1)の一様分布とした.
wataokaのコメント
データセットバイアスが原因でちょっと炎上してた論文. 研究自体は面白い.
website: http://pulse.cs.duke.edu/
6本目の論文: CausalVAE: Structured Causal Disentanglement in Variational Autoencoder
wataokaの日本語訳「因果VAE: VAEによる構造化因果のDisentanglement」
- 種類: cusal inference, vae
- 日付: 20200418
- URL: https://arxiv.org/abs/2004.08697
概要
- 潜在変数へのdisentanglementはよく行われているが, 現実世界で意味論的な要素が独立しているとは限らない.
- 独立の因子を因果因子に変換するためのcausal layersを持っているVAEを提案.
- Causal VAEと呼ぶ.
- Causal VAEの識別可能性も解析した.
- 識別可能性: Q(M)をモデルMにおいて計算可能な量とする. あるモデルのクラスMから得られる任意のモデルM1とM2に対して, P_M1(v)=P_M2(v)が成り立つ場合には, いつでもQ(M1)=Q(M2)である時, MにおいてQは識別可能であるという.
- 学習した生成モデルがある程度までは真のモデルを復元しているということを示すことで解析した. (はぁ?)
- 実験データセット
- 物理的因果関係を持つ人工画像データ (太陽と振り子と影)
- CelebA
- 結果, CausalVAEの因果表現は意味論的に解釈可能で, downstreamタスクに関していい結果だった.
情報の流れ
- xはencoderで潜在変数εに変換される.
- εは多変量正規分布の事前分布p(ε)を持っている.
- εはcausal layerで因果表現zに変換される.
- zは条件付き分布p(z|u)を持っている.
- uはラベルなどの追加情報.
- zはdecoderによってxに変換される.
3. Method
3.1 Causal Model
xからεは普通にencoder
εからzは, 以下のようなLinear Structural Equation modelsを仮定している.
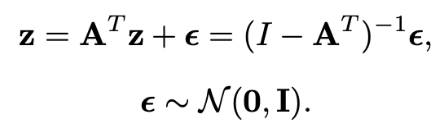
zはn次元ベクトルで, それぞれが何らかの物理的な意味に対応している.
Azがzの項でもあることから, ziとzjの因果関係なども記述していることがわかる.
3.2 Generative Model
モデルの教師なし学習は識別可能性問題によって不可能.
([1]で議論済み)
この問題に対処するためにiVAE(Khemargem et al., 2019)を参考に, 観測signalとして真の因果コンセプト情報を使用した. (端的にいえばラベルありにした.) 追加的な観測はラベル, ピクセルレベルの観測などであり, uで表される. u_iがi番目のコンセプトである.
下のような生成モデルを考える.
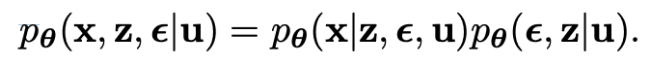
- 属性情報uによって, 以下が生成される.
- 画像x
- 意味論を持つ潜在変数z
- ノイズ潜在変数ε
3.3 Training Method
相変わらずELBOを最適化する. (p(x|u)のELBO)
因果隣接行列Aの最適化は, continuous constraint functionを使用.
(Zheng et al., 2018; Zhu & Chen, 2019; Ng etal., 2019; Yu et al., 2019)
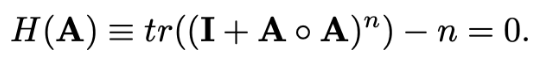
この関数は次のような性質を持つ.
AがDAGを形成する値である <=> H(A)=0
なので, H(A)を正則化項とすればいいのだが, 2乗項も加えると学習がスムーズになる.
従って, 下が損失関数.
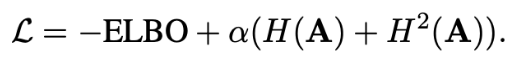
5. Experimetns
5.1 Dataset
5.1.1 Synthetic Data
- Pendulum (振り子)
- 3つのエンティティ
- 振り子
- 光
- 影
- 4つのコンセプト
- 振り子の角度
- 光の角度
- 影の場所
- 影の長さ
- 3つのエンティティ
- Water
- 2つのエンティティ
- 水
- ボール (水の入ったカップの中にある)
- 2つのコンセプト
- ボールのサイズ
- 水の高さ
- 2つのエンティティ
5.1.2 Benchmark Dataset
CelebA
6 Experiments
- 合成データとCelebAで実験した.
- CausalVAEと既存のdisentangle手法と比較した.
- 以下の点に重点を置いている.
- アルゴリズムが解釈可能な表現を学習できているか
- 潜在変数への介入の結果が因果系の理解と一致しているか
6.1 Dataset, Baseliens & Metrics
Metrics
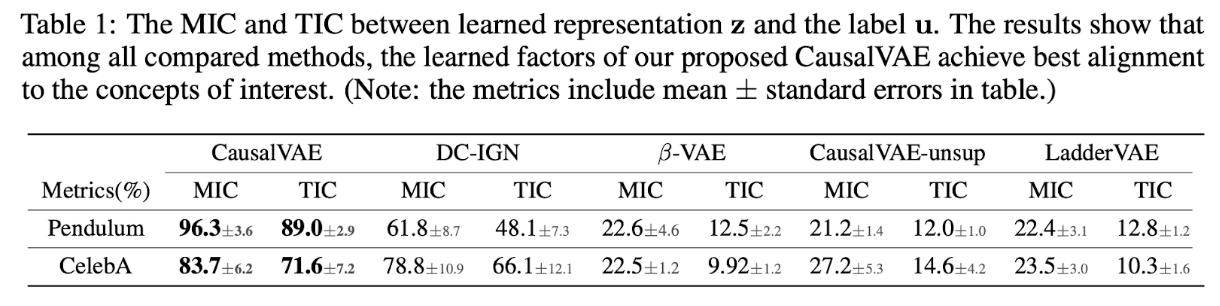
評価指標として以下の2つを使用した.
Maximal Information Coefficient (MIC)
Total Information Coefficient (TIC)
どちらも表現とground truth labels of conceptsとの間の相互情報量を示したもの.
MICはいろいろと分割して相互情報量が最大となる値を採用するmetric. (21世紀の相関)
6.2 Intervention experiments
何かしらのコンセプトと対応しているzを介入した結果, どんな画像を出力されるかを観測した. (振り子とCelebA)
振り子に関してもCelebAに関しても, しっかりと介入できてることを画像を見せて示した.
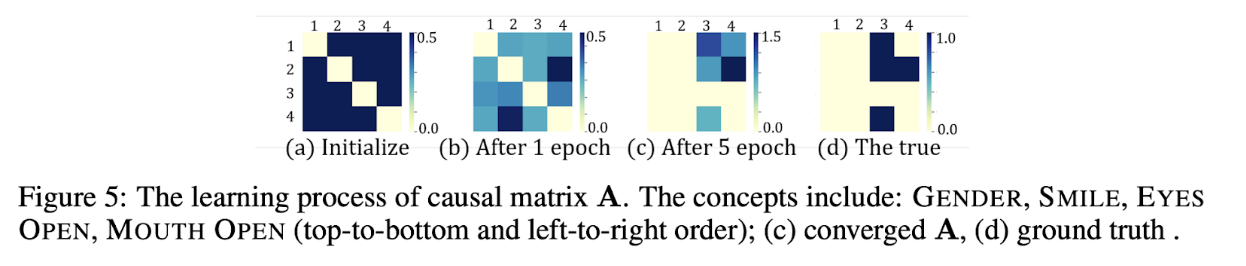
因果行列Aの学習プロセスをヒートマップの流れで表現し, 真の因果行列に収束していっていることを示した.
reference
[1] Challenging common assumptions ¨ in the unsupervised learning of disentangled representations.
wataokaのコメント
潜在変数で因果探索を行うところは良いと思うが, 介入の方法については微妙?定性的評価の時点で少し所望の動きができていないところがある. 現時点でどこにもacceptされていないので, 経過を見たいところ. (2020年12月現在でacceptされてないっぽいので, どこかに出してrejectされたかも.)
7本目の論文: Progressive Growing of GANs for Improved Quality, Stability, and Variation
wataokaの日本語訳「質, 安定性, 多様性を向上させるためのPG-GAN」
- 種類: GAN
- 学会: ICLR2018
- URL: https://arxiv.org/abs/1710.10196
概要
- 画像などの解像度が高くなると生成分布のランダム要素が強くなるので, 学習が不安定になる. そこでPGGANを提案した.
- PG-GANは低解像度の画像から始めて, ネットワークにレイヤーを徐々に追加して解像度を上げていくGAN.
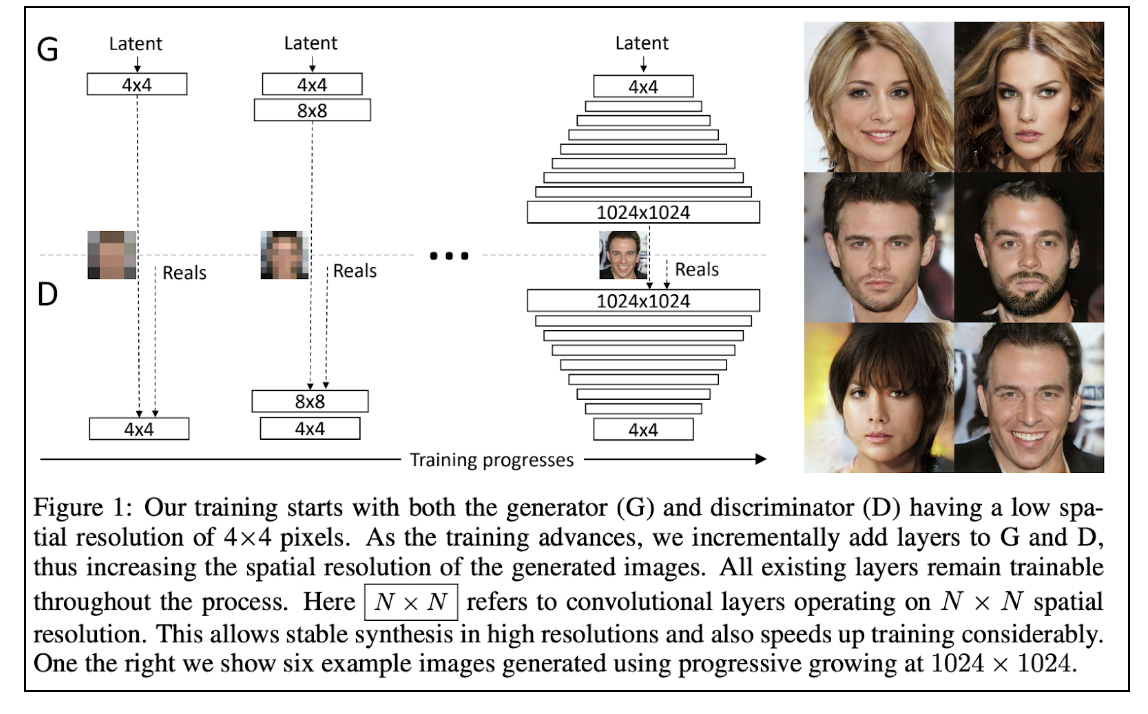
いろんな工夫
progressive growing
GeneratorとDiscriminatorにレイヤーを一つずつ追加していくことで, 解像度を徐々に上げていく.
レイヤーを追加する際も, 2×した結果と2倍のCNNの結果を線形結合し, αの値を徐々に上げていくことで, 2倍のCNNの結果の影響を徐々に上げていく.
2×: 2×2で複製, 0.5×: average pooling
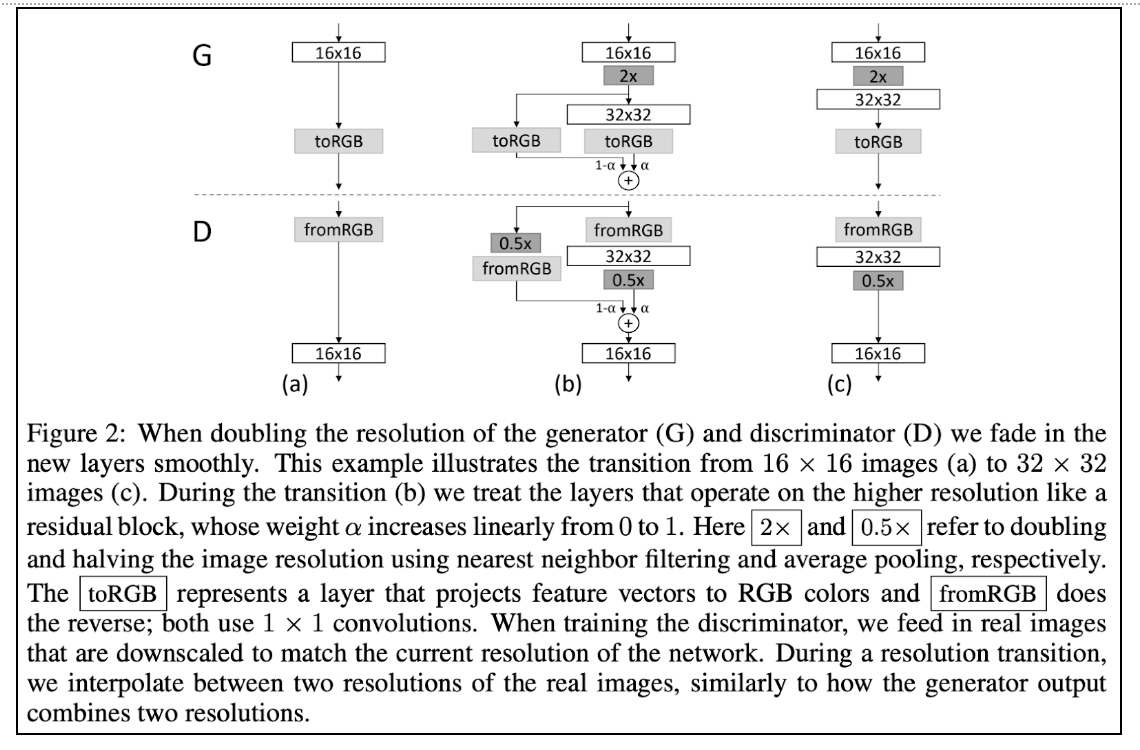
minibatch discrimination (model collapse対策)
- minibatchの同じ画素に関して標準偏差を求める.
- 出来上がった1枚の画像の全てのピクセルで平均値を計算. スカラーを得る.
- そのスカラーを複製することで1チャネルの画像(H×W)を得る.
このミニバッチカラー画像→1枚の白黒画像という処理をDiscriminatorの最後に追加する. これにより, Discriminatorはミニバッチ全体の統計量も考慮の対象となる. 従って, Generatorはミニバッチ全体での統計量分布も模倣するので, real data同様多様性を獲得する. らしい.
equalized learning rate (収束性対策)
重みの初期値としてガウス分布N(0, 1)を使用する.
そして,
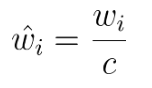
とする.
wi: 重み
c: 各層の正規化定数. (Heの初期化を行う.)
これによって以下のようになる.
- スケールの影響を受けずにパラメータの更新ができるので学習速度があがう.
- スケールを整えているので, 全ての重みに対して均質に学習するため, 強い情報に引っ張られすぎない.
pixelwise feature vector normalization in generator (収束性対策)
普通に特徴量の正規化.
GeneratorのCNN層の後に各ピクセル毎にfeature vectorを以下のように正規化する.
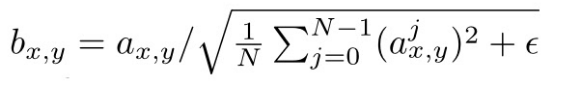
- N: チャネル数
- a: 元の特徴ベクトル
- b: 正規化されたベクトル
pixel毎に正規化してる感じが影響の強い信号を軽減させてる感じなのかな?多分.
multi-scale structural similarity (評価手法)
- うまく学習できたGは以下であると仮定している.
- 局所的な画像構造が全てのスケールにわたって本物の画像と似ている.
- (DとGの局所的な画像構造の分布が全てのスケールで近い)
- 局所特徴量
- レベルLの1枚の画像から128個の特徴量を抽出する.
- 局所特徴量は7x7ピクセルで3チャネル.
- レベルLの訓練データの特徴量xは128×(データ数)だけ得られる.
- 生成データも同じデータ数生成することで同じだけ特徴量yが得られる.
- 128x(データ数)個の特徴量をそれぞれ{x}, {y}と表記する.
- 分布距離
- 各チャンネルの平均と標準偏差から{x}と{y}を正規化する.
- {x}と{y}の統計的な類似度として, sliced Wasserstein distanceを採用する.
- SWD({x}, {y})
- これが小さければ分布{x}と分布{y}が類似している.
これによって
- 最低解像度16x17での分布距離は大まかな画像構造の類似性を表し,
- 高解像度での分布距離はエッジやノイズの鮮明さなどピクセルレベルでの情報の類似性を表す.
wataokaのコメント
GANの進化の中でも非常に重要な論文. 高解像な画像の生成に初めて成功したと言っていい. この先に, StyleGANやBigGANへと受け継がれていく.
実際に手を動かして学習させてみたが, 非常にハイクオリティに生成できた. しかしまだやはり, 多様性の乏しさなどが見受けられた.
8本目の論文: Discovering Causal Signals in Images
wataokaの日本語訳「画像における因果信号の発見」
- 種類: causal inference
- 学会: CVPR2017
- 日付: 20150526
- URL: https://arxiv.org/abs/1605.08179
概要
現実世界ではcar→wheelという出現関係があり, 画像に現れると仮定している. そのようなcausal dispositionを明らかにするような方法を提案した.
この論文は画像内に現れるオブジェクトカテゴリの”causal dispositions”を明らかにする観測可能なfootprintが存在することを示す.
- ステップ1
- 確率変数ペア間のcausal directionを見つける分類器を構築.
- NCC (Neural Causation Coefficient)
- ステップ2
- 画像の中からobject featuresとcontext featuresを見分ける分類器を使用.
1. Introduction
featuresについて
- causal features
- 因果特徴
- オブジェクトの存在を引き起こすもの
- anticausal features
- 反因果特徴
- オブジェクトの存在に引き起こされるもの
- object features
- オブジェクト特徴
- 関心のあるオブジェクトのbounding box内でactivateされるもの
- context feaatures
- 文脈特徴
- 関心のあるオブジェクトのbounding box外でactivateされるもの
Hypothesis 1.
画像データセットは因果配置(causal dispositions)に起因するオブジェクトの非対称関係を明らかにするような観測可能な統計信号を持っている.
↓言い換えた
- 画像データセットは観測可能な統計信号を持っている.
- 観測可能な統計信号はオブジェクトの非対称関係を明らかにする.
- オブジェクトの非対称関係はcausal dispositionに起因する.
Hypothesis 2.
object featuresとanticausal featuresの間には観測可能な統計的依存が存在する.
context featuresとcausal featuresの間には観測可能な統計的依存がないor非常に弱い,.
手法
画像からobjectとcontextに分離, それぞれをcausal featureなのかanticausalなのかに二値分類.
9本目の論文: Visual Causal Feature Learning
wataokaの日本語訳「視覚的な因果関係の学習」
- 種類: causal inference
- 学会: UAI2015
- 日付: 20141207
- URL: https://arxiv.org/abs/1412.2309
概要
- 行動の視覚的因果の定義を提案する.
- 行動の視覚的因果は人間, 動物, ニューロン, ロボット, その他の知覚システムにおける視覚的に駆動される行動に応用可能.
- 提案フレームワークは因果変数がミクロ変数から構成されている必要があるような標準的な因果学習を一般化する.
- Causal Coarsening(因果関係の粗大化)定理を証明した.
- この定理により最小限の実験による観測データから因果知識を得ることができる.
- この定理は標準的な因果推論のテクニックを画像特徴を識別する機械学習に接続する. (画像特徴はターゲットの行動を引き起こすわけではないがターゲットの行動と相関がある.)
- 最終的にターゲットの行動の視覚的因果を自動的に特定するために画像におけるoptimal manipulationsを行うmanipulator関数を学習するためのactive learningスキームを提供する.
- 人工データとreal dataで実験した.
1. 導入
Three advances
画像空間を作るミクロ変数(pixels)から構成されるマクロ変数としてのターゲットの行動の視覚的因果を定義した. 視覚的因果は画像内にターゲットの行動に関する因果情報があるという点で他のマクロ変数と異なる.
Causal Coarsening Theorem (CCT)を証明。CCTは最小限の実験的努力から視覚的因果を学習するために観測データをどのように使えるかを示してくれる.
manipulator関数を学習する方法を示す. manipulator関数は自動的に視覚的因果においてoptimal manipulationsを実行してくれる.
2. A Theory of visual causal features
2.2 Generative Models: from micro to macro variables
Definition 1 (Observational Partition, Observational Class)
振る舞いTに関する集合Iのobservational partition Π_o(T, I) (⊂I)は,
i~j <=> P(T|I=i)=P(T|I=j)
という等価関係に基づく分割である.
画像のobservational partitionを知ることはTの値を予測することになる.
Definition2 (Visual Manipulation)
visual manipulationは操作man(I=i)である.
Definition 3 (Causal Partition, Causall Class)
振る舞いTに関する集合IのCausal partition Π_o(T, I) (⊂I)は,
i~j <=> P(T|man(I=i)) = P(T|man(I=j))
という等価関係に基づく分割である.
スライド
下記スライドが非常にわかりやすかった.
https://www.slideshare.net/KojinOshiba/visutl-causal-feature-learning
目的: 人間の視覚的な因果を理解すること
マクロ変数(e.g. ピクセルの集合)から因果学習するフレームワーク
ミクロ変数(e.g. 聴覚や嗅覚データ)への応用可能
C: macro-variable
I: image
T: behavior
H: discrete variable (Iを生成する)
10本目の論文: Achieving Causal Fairness through Generative Adversarial Networks
wataokaの日本語訳「GANを用いた因果公平性の達成」
- 種類: causal inference, gan, fairness
- 学会: IJICAI2019
- 日付: 20190816
- URL: https://pdfs.semanticscholar.org/1846/bb80fbd235bcf3316b5ffb09a6d3e22ebeab.pdf
概要
CausalGAN [Kocaoglu, 2018]の拡張, Causal Fairness-aware GAN(CFGAN)を提案. 与えられた因果関係グラフに基づいて様々な因果関係の公平性を確保しながら分布を学習できる.
2. Preliminaly
因果モデル
causal model [Pearl, 2009]とは次のような三つ組みM={U, V, F}
- U: 観測不可能な確率変数の集合. Vのあらゆる変数に起因しない潜在変数.
- V: 観測可能な確率変数の集合.
- F: 共分散構造の集合.
因果ベースの公平性
それぞれに特化したCFGANを設計できる.
- total effect
- direct discrimination
- indirect dicrimination
- counterfactual fairness
3. CFGAN
3.1 Problem Statement
- 変数
- V = {X, Y, S}
- S: センシティブ属性
- Y: 決定変数
- X: S以外の属性集合
- causal graph G = (V, E)
- データセットはm点のサンプル(x, y, s)
- サンプル(x, y, s)はP_data(=P(V))からサンプルされる.
- V = {X, Y, S}
- CFGANのゴール
- read dataの全ての属性の分布を保護した新しいデータ(x^, y^, s^)を生成する.
- 様々なcausalベースの基準において, 生成されたデータS^がY^に差別的な影響を与えない.
3.2 Model Framework
CFGANは以下を持っている.
- 2つのgenerator (G1, G2)
- 2つのdiscriminator (D1, D2)
- Generator
- G1
- 元の因果モデルMの役割 (CausalGANと同じ.)
- 目的: read dataの分布に近づけたい.
- G2
- 介入モデルM_sの役割
- 目的: 公平性を満たした介入データを生成したい.
- G1とG2で共有しているもの
- 入力ノイズ
- 因果モデル間の接続を表すパラメータ
- G1とG2で異なるもの
- 介入を表すサブニューラルネットのコネクション
- Discriminator
- D1
- read dataかgenerated dataかを見分ける.
- D2
- 介入do(S=1)の分布なのか, 介入do(S=0)の分布なのかを見分ける.
- もともとnegなsならばdo(S=0)は普通のy^なので, これを予測に用いる.
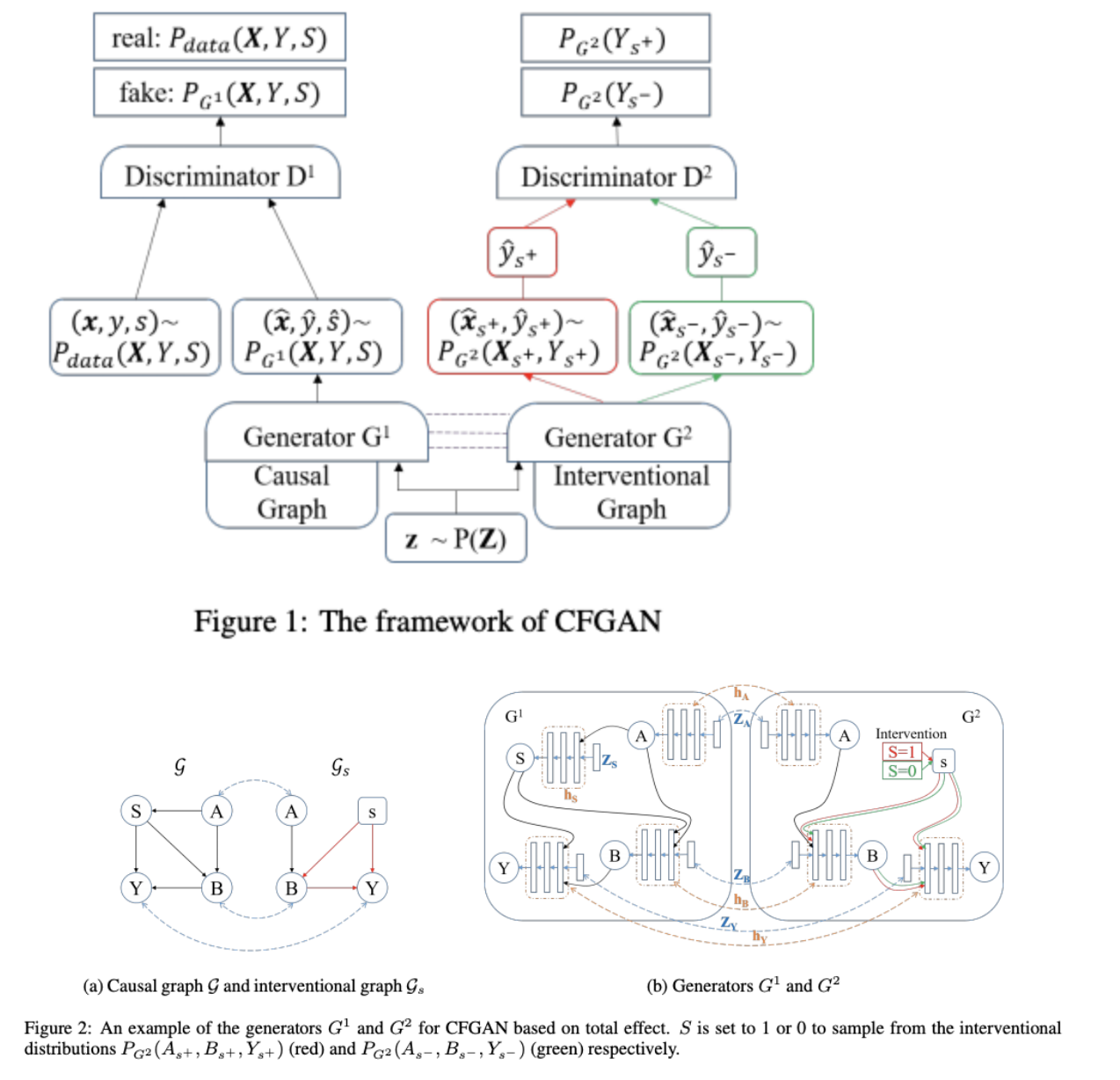
CFGAN for Counterfactual Fairness
- オリジナルの因果モデルと介入因果モデルとのコネクションを考慮する必要がある.
- このコネクションを反映するために, G1によって生成されたサンプルとG2によって生成されたサンプルの直接的依存関係を構築する.
- G1とG2の構造は上と同じだが, 各ノイズzにおいて最初にG1を使用して観測サンプルを生成し, そのサンプルがデータセットにあるかどうかを確認する.
- ある場合にのみ, そのノイズをG2に入力し, 介入サンプルを生成する.
- D2がそれを見抜こうとするので,
- 最終的にP(Y_{S←1}|O)=P(Y_{S←0}|O)が達成される.
11本目の論文: Estimating individual treatment effect: generalization bounds and algorithms
wataokaの日本語訳「個人介入効果の推定: 汎化誤差とアルゴリズム」
- 種類: causal inference
- 学会: ICML2017
- 日付: 20160613
- URL: https://arxiv.org/abs/1606.03976
概要
TARNetを提案. ITE(個人介入効果)を推定する. さらに, 介入分布とコントロール分布の距離と汎化誤差を用い, 推定されたITEの誤差のboundをとった.
3. Estimating ITE: Error bounds
3.1 Problem setup
representation関数Φ: X→Rとする. (R: representation space)
Assumption 1.
representationΦは二階微分可能な単射関数.
一般性を失わないので, RをΦにおけるXの像(image)とし, Ψ:R→XをΦの逆関数とする.
(ψ(Φ(x)) = x for all x∈X)
representationΦはtreated distributionやcontrol distributionから空間Rへ押し出す.
Definition 1.
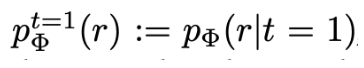
p^{t=0}_{\phi} (r) := p_{\phi} (r|t=0)
とする. (the treated and control distributions induced over R)
Φは単写のため, ψ(r)のヤコビアン行列を用いると, 分布p^{t=1}{Φ}, p^{t=0}{Φ}は得られる.
wataokaのコメント
CEVAEに参考にされている.
12本目の論文: Gender Slopes: Counterfactual Fairness for Computer Vision Models by Attribute Manipulation
wataokaの日本語訳「Gender Slopes: 属性編集を用いた画像モデルのための反実仮想公平性」
- 種類: counterfactual, fairness
- 日付: 20200521
- URL: https://arxiv.org/abs/2005.10430
概要
- 他の属性を固定し, 人種や性別などの属性を変化させた画像を生成するためのオートエンコーダーを提案した.
- そのオートエンコーダーを用いて商用に公開されている画像認識器のcounterfactual fairnessを測定した.
手法 Counterfactual Data Symthesis
Problem Formulation
- Y: 予測器
- x: 画像
- Y(x) = {True, False}
- A: sensitive attribute (binary)
Face Attribute Synthesis
- Denton2019の方法とは違って, この論文ではFaderNetworkを使用した.
- 理由: GANの潜在空間は容易にentangleされているので, 明示的にdisentangleしているモデルを使用した方がいいと考えたから.
- FaderNetworkは以下のようなモデル.
- エンコーダEを用いてx→E(x)
- DiscriminatorがE(x)を用いて属性aを予測
- 敵対的学習により, EはDiscriminatorがaを予測できないように学習する.
- 結果, E(x)は属性a以外の情報となる.
- デコーダDにE(x)とaを入力し, 画像D(E(x), a)を生成.
- 結果, aをいじることで属性aを編集した画像を生成できる.
- Gender SlopesではFaderNetworkを以下の点で変更を加えた.
- [Yu+, 2018]を使用して, 顔の領域をセグメントし, その領域以外で編集することを禁止した.
- (せこい...)
- センシティブ属性aと相関性のありそうな属性もセンシティブ属性と同じように敵対的学習で明にE(x)から分離して調節できるようにし, aを編集する時に固定した.
- aをE(x)から分離する時点でこの操作はいらない気もするが, データセットバイアスに対処するために明示的に行ったらしい.
- [Yu+, 2018]を使用して, 顔の領域をセグメントし, その領域以外で編集することを禁止した.
Experiments
Computer Vision APIs
以下のAPIを調べた
- Google Vision API
- Amazon Rekognition
- IBM Watson Visual Recognition
- Clarifai
Occupational Images
職業に関するデータセットを作成した
- Bureau of Labor Statisticsから129の職種リストを入手
- Google Image検索でそれらの職業を検索し, ダウンロード.
- 顔のない画像は無視している.
- 多様な画像を得るために以下のキーワードも組み合わせた.
- 男性
- 女性
- アフリカ系アメリカ人
- アジア系
- 白人
- ヒスパニック
学習用データとして,
- 性別操作モデルにはCelebAを用いた.
- CelebAは白人の顔が多いので人種操作モデルには適していない.
- 人種操作モデルにはCelebA+検索とかいろいろ頑張って画像と属性を集めた.
Results
- Gender Slope
- aの範囲を(-2, 2)として, 7分割し, それらをclassifierに入力する.
- aがある値a’を取ったとすると,a’である画像サンプル複数に対してpositiveと出力する確率を算出.
- 結果, 7つの確率が得られ, それらをplotすると右肩上がりになる.
- 最小二乗法による線形回帰した結果の傾きbをGender SlopeもしくはRace Slopeとして, 一つの評価手法としている.
- (equal opportunityじゃなくてdemographic parityな評価指標)
いろいろなAPIにいろいろなセンシティブ属性に対してslopeを計算して表にまとめている.
そして, 全ての属性に対してモデルのoutputがp値<0.001で相関していることと結論づけた.
13本目の論文: CausalGAN: Learning Causal Implicit Generative Models with Adversarial Training
wataokaの日本語訳「CausalGAN: 敵対的学習を用いた明示的な因果生成モデルの学習」
- 種類: causal inference, gan
- 学会: ICLR2018
- 日付: 20170914
- URL: https://arxiv.org/abs/1709.02023
概要
- 因果グラフがgivenの時の因果を含んだ生成モデルの学習
- 生成アーキテクチャがgivenの因果グラフと一致しているなら, 敵対的学習は真の観測分布と介入分布の生成モデルを学習することに使えることを示した.
- 顔の属性情報が与えられた時, そんな顔を生成できる.
- 2つのステップでこの問題に取り込む.
- 因果グラフと整合性のあるNNを用いて, 二値ラベル上の因果暗黙的生成モデルを生成器として訓練する.
- causalGAN
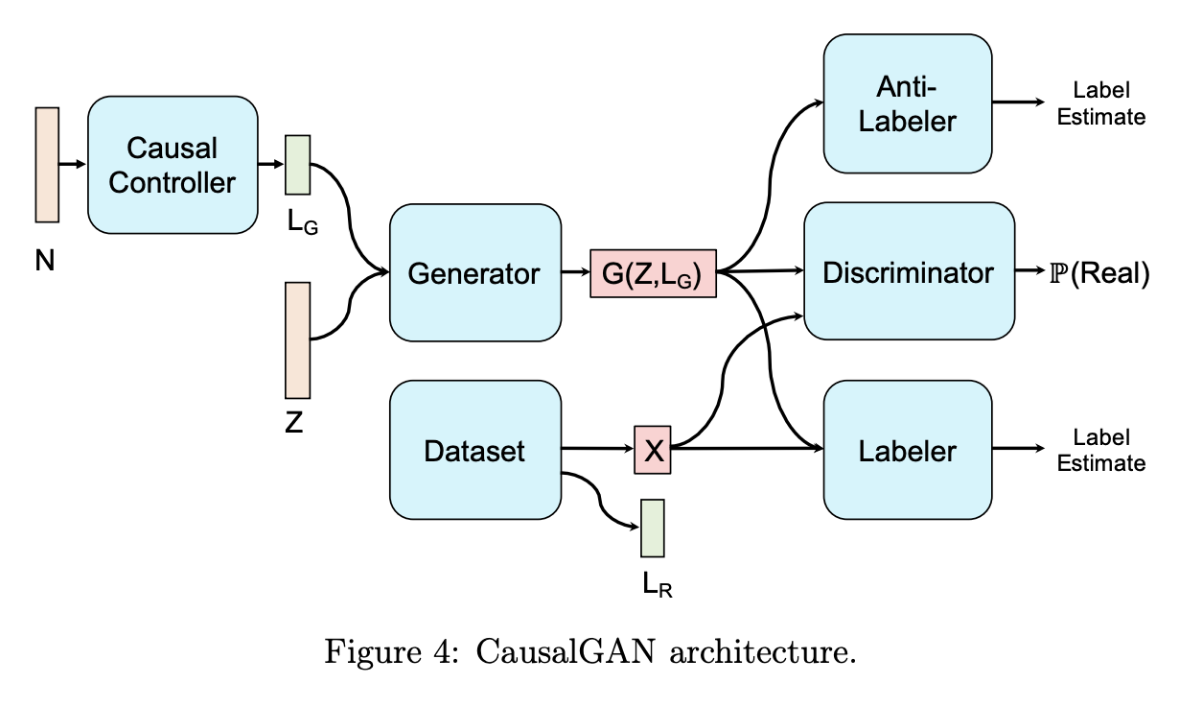
4 Causal Implicit Generative Models
Implicit generative model[28]は明示的なパラメータなしに, 分布からサンプリングすることに使われる. (GANがその成功例) しかし, 介入分布からのサンプリングはできない. Causal Implicit Generative Modelはそれができる.
因果グラフが与えられており, それぞれに対応する構造方程式をニューラルネットで近似するだけ.
5 Causal Generative Adversarial Networks
5.1 Causal Implicit Generative Model for Binary Labels
Causal Controllerはラベル集合において条件付けしたり介入したときに画像がどの分布からサンプルされるかをコントロールするためにある. 4章で説明済み.
5.2 CausalGAN Archtecture
最適化されたgeneratorは画像分布で条件づけられたラベルを出力する.
Causal Controllerは事前学習済みで, アップデートしない.
Labelerはデータセットの画像のラベルを推定することで訓練するモデル.
Anti-Labelerはgeneratorから生成された画像のラベルを推定することで訓練するモデル.
Generatorを最適化する際, 3つの目的がある.
- discriminatorを騙すようにすることで, realな画像を生成する.
- Labelerに正しく分類されようとすることで, L_G通りの画像を生成する.
- Anti-Labelerを騙すようにすることで, ラベリングしやすい非現実的な画像分布になることを避ける.
手法のまとめ
- 構造方程式を近似
- 因果グラフはgiven
- f_{x_i}の部分はニューラルネット
- 学習方法はDiscriminatorを用意して敵対的学習.
- “Improved training of wasserstein gans”を参考に学習.
- zから属性を出力するgeneratorをCausal Controllerと呼ぶ.
- Causal GANを学習.
- Generator: Causal Controllerから生成された属性から画像を生成する.
- Discriminatorの損失を最大化するように学習することで, 実データっぽい画像を生成.
- Labelerの損失を最小化するように学習することで, 画像が属性に従っていく. (Labelerに属性を見破られようとする.)
- Anti-Labelerの損失を最大化するように学習することで, ラベリングしやすい非現実的な生成画像分布にならないようにする.
- Discriminator: 生成画像か実画像かを見分ける.
- Labeler: 実画像から属性を推定.
- Anti-Labeler: 生成画像から属性を推定.
- Generator: Causal Controllerから生成された属性から画像を生成する.
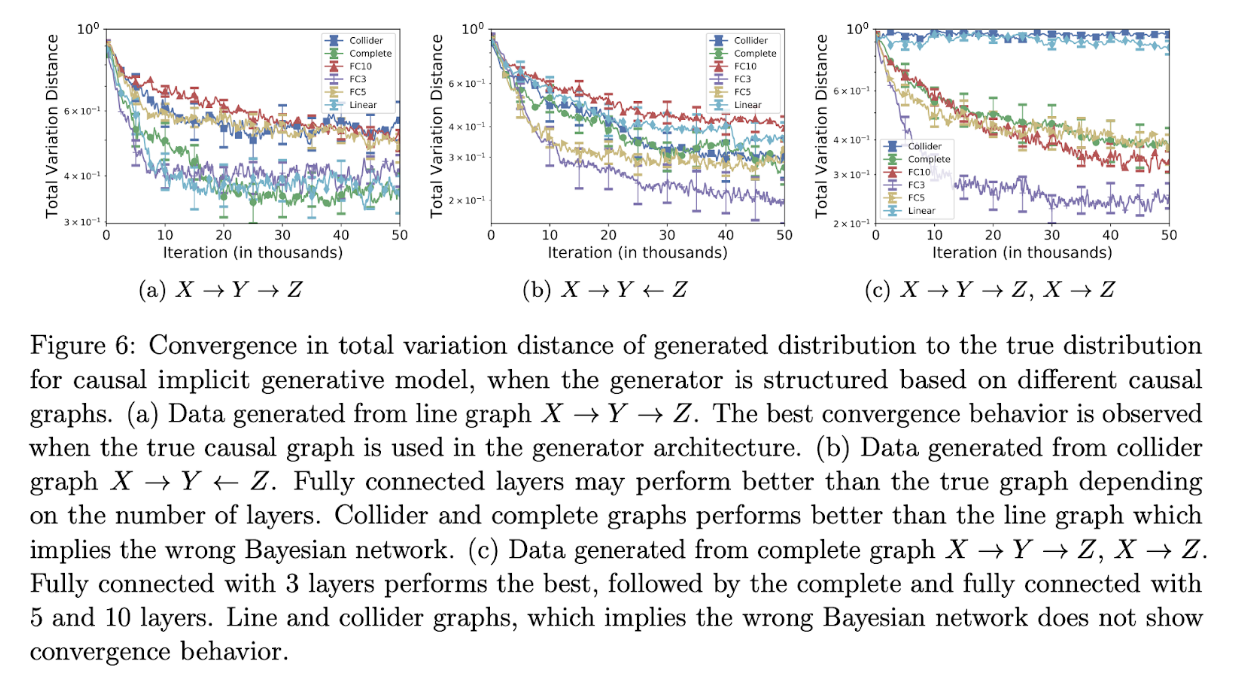
8 Result
8.1 Dependence of GAN Behavior on Causal Graph
以下の3つのどれか1つからサンプルされたデータに対してのcausal implicit generative modelの収束を調べた.
- “line”: X→Y→Z
- “collider”: X→Y←Z
- “complete”: X→Y→Z, X→Z
親がn個あるノードは外生変数1個と親n個の計n+1個のノードから計算される. それぞれのモデルに対して20回サンプルし, 平均値を記載している.
記載されているgeneratorは6つ
- line: lineの因果構造を持ったcausal controller
- collider: colliderの因果構造を持ったcausal controller
- complete: completeの因果構造を持ったcausal controller
- FC3: 外生変数から全属性を出力する3層のnn
- FC5: 外生変数から全属性を出力する5層のnn
- FC10: 外生変数から全属性を出力する10層のnn
FC系は因果グラフがわかっていない比較用のgenerator.
(しかしFC3が結構勝ってるやん...)
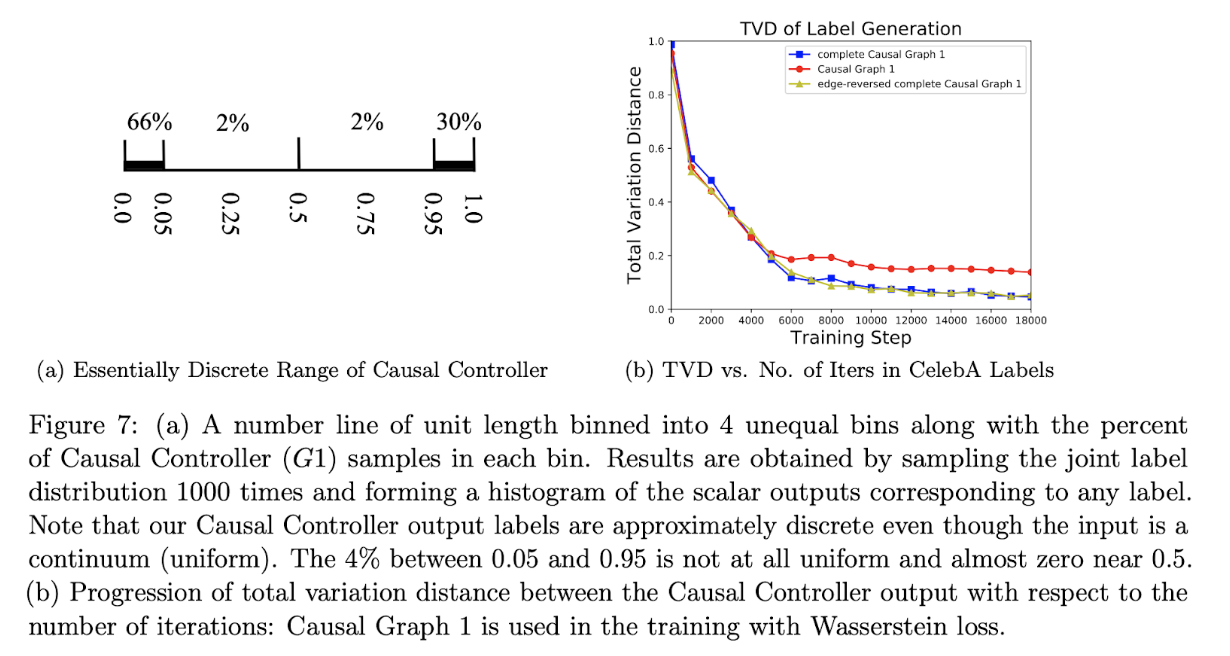
8.2 Wasserstein Causal Controller on CalabA Labels
実験で用いたWasserstein Causal Controllerはノイズを連続一様分布からサンプルしているが, 出力のラベルはほとんどが0か1付近に存在しているので, ほぼほぼ離散分布として機能してくれた.
Causal Graph毎にどのようにtotal variational distanceが収束していくかを観測した.
8.3 CausalGAN Results
条件付き分布と介入分布の違いを確認した.
- 髭で条件付けした時, 髭の男しか生成されない
- 髭で介入した時, 髭の男も髭の女も生成された.
14本目の論文: Latent Space Factorisation and Manipulation via Matrix Subspace Projection
wataokaの日本語訳「行列部分空間射影を用いた潜在空間分解と編集」
- 種類: disentanglement
- 学会: ICML2020
- 日付: 20190726
- URL: https://arxiv.org/abs/1907.12385
概要
- オートエンコーダーの潜在空間をdisentanglingし, 1つの属性だけを変化させる手法Matrix Subspace Projection (MSP)を提案.
- MSPのいいところ
- MSPは既存手法よりシンプル.
- 複数のdiscriminatorを必要としない.
- 複数の損失関数に対して慎重に重み付けする必要がない.
- 任意のオートエンコーダーに適応可能.
- 画像やテキストなど多様なドメインに適応可能.
- MSPは既存手法よりシンプル.
- 異なるドメインで実験を行い, 人間による評価と自動的な評価を行い, ベースラインよりよかった.
1. Introduction
提案手法は以下の2つを特徴を持つ
- ランダムシード(しかし属性はあり)からサンプルが生成される.
- ある特定の属性と入力サンプルを与えると, 入力サンプルのその属性を修正することができる.
Contributions - シンプルかつ普遍性のある方法で条件付き生成を可能にした.
- (ここでいう普遍性とは, 任意のオートエンコーダーに使えるという意味)
- 複数属性に対して精度のいいdisentanglementを可能にした.
- コードを公開している.
2. Related Work
潜在ベクトルから特定の属性情報を分離する問題としてよく用いられる方法は, zの属性を予測するネットワークを用いて, 敵対的学習を行い, 特定の情報を消去し, 所望の属性のみにする方法. この手法の欠点は, 再構成誤差とトレードオフになっており, 学習率のスケーリングが大変であること.
3. Method
3.1. Problem Formulation
D: データセット
x: 画像 (n次元)
y: 属性 (k次元)
F: オートエンコーダー
G: デコーダー
z: 潜在ベクトル (z = F(x))
K: 置換関数
zの属性がynに変わるように置換した結果をznとすると,
zn = K(z, yn)
また, zの属性がynに変わるように置換した結果, 生成される画像をxnとすると,
xn = G(K(z, yn))
結果得られた画像xnの属性はyでなくynであると予測されるようになるが, それ以外の情報は保存されている.
3.2. Learning Disentangled Latent Representations via Matrix Subspace Projection
潜在変数zとinvertibleな任意の関数が与えられた時,
Hはzを新しい線形空間に飛ばしてくれる. ($\hat{z}$=H(z))
どのような線形空間かというと, 以下の(a)と(b)を満たす.
(a) $\hat{z}$に行列Mをかけることでyに近づけることができる線形空間.
(b) 直交行列U = [M, N]が存在する.
ただし, NはMの零空間で, N$\hat{z}$はy以外の情報($\hat{s}$とする)となる.
要するにHはzからy, zから$\hat{s}$への変換において, ラスト一歩手前まで持っていった感じ.
あとは行列で線形変換すればyとかsになれるよというギリギリの$\hat{z}$まで持っていくのがH.
invertibleなHを省くことで, GとFにHの機能を学習させると考えることができる.
Mに関しては直交行列の一部である必要があるため, GとFにMの機能を学習させることはできない.
Mを最適化するために以下をする必要がある.
- $\hat{y}$をyに近づける.
- $\hat{s}$が$\hat{z}$からの情報を持たないようにするために$\hat{s}$のノルムを小さくする.
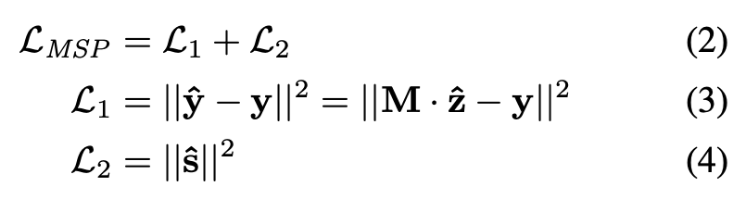
L2に関しては次のように式変形することで計算可能にする.

3.4. Conditional Generation and Content Replacement
モデルの学習が完了すると, Mが得られるのでUも得られる. (MN=0をsolverで解けばいい)
なので,
Fを用いてxから$\hat{z}$が得られ,
Uを用いて$\hat{z}$から[$\hat{y}$;$\hat{s}$]が得られる.
そして,
[$\hat{y}$;$\hat{s}$]を[yn;$\hat{s}$]に置き換えて,
Uの逆行列(Uの転置)を用いてznが得られ,
Gを用いてznからxnが得られる.
4. Evaluation
4.1. Matrix Subspace Projection in VAE
vanilla VAEに適用した.
また, 生成画像をシャープにするためにadditional PatchGANを使用した.
baselineは
- Fader networks (Lample+, 2017)
- AttGAN (He+, 2019)
定性的評価として,
Fader netやattGANではメガネに対する編集に失敗し, MSPは成功していることなどを例にあげた.
定量的評価として,
- ResNet-CNNを先に学習させておき, (xn, yn)に対するaccuracyを測定した.
- MSPが圧勝した.
- Frechet Inception Distance (FID)スコアを算出した.
- 元画像と生成画像がどれほど似ているかを示す指標.
- 0がベストで小さければ小さいほど良い.
- MSPがスコアが高く, 良くなかった.
- (他の手法が編集してないことをアピールしたい?)
画像編集において他より秀でていることとして, MSPは40個の属性のうち1個を変更して39個を固定することに長けている. CelabAにおけるdisentangleの世界では, 女性を変更させた時に化粧や口紅をしてはいけないという暗黙のルールがあるが, Fader netなどの方法はそういった変更に適していない.
4.2 Human Evaluation of Generated Example Quality
1000枚の画像を抽出し, その画像に対してランダムに1つか2つの属性を編集する.
参加者に対して2枚の画像を見せ, 「クオリティの高い画像を選んでください. もしくはどちらも同じぐらいとしてください.」と質問し, 定性的なクオリティの評価も行った.
比較したのは, オートエンコーダーに対してMSPを入れたか入れていないかにおいて行った.
そして, オートエンコーダーとしてはSeq2seq, VAE, VAE+GANの検証を行った.
結果としては「MSPを入れた時クオリティが最も悪い」という帰無仮説はp<0.03で棄却された.
4.3 Evaluation of Disentanglement
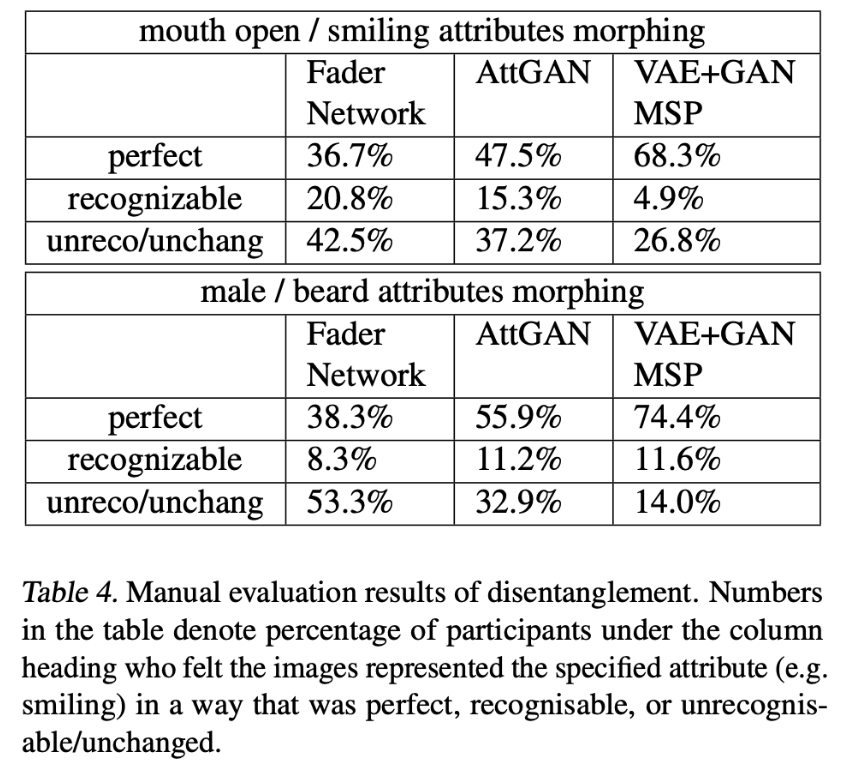
Amazon Mechanical Turkを用いて手動ラベリングを行った.
3つのレベルのリッカート尺度(perfect, recognisable, andunrecognisable/unchanged)で属性変換が成功しているかどうかを参加者に評価してもらった.
結果MSPが最もよかった.
また定量的評価として, ある属性を変更した際, それと相関性のある属性がどれほどclassifierの出力に影響を与えるかを測定した. 例) 男性を変化させた時に, 髭がどれほど動かなかったかを測定している. 結果として, MSPが最も動かなかった.
所望の属性は最も動き, それと相関性のある属性が最も動かなかったので, MSPが最もdisentangleできていると結論づけている.
wataokaのコメント
非常に読んでいて楽しかった. ベスト3に載せるか迷ったほど. 実際には計算する必要のない架空の行列Nを理論上の計算でこねくり回して, 結局は行列Mに関する最適化だけでいいよって流れがとても面白い. ただし, 無情報化するためにのノルム0とし, そうすることでdisentangleの達成というのは, 必要条件しか満たしていなさそうな気がする.
15本目の論文: Avoiding Discrimination through Causal Reasoning
wataokaの日本語訳「因果関係を用いた差別の回避」
- 種類: fairness, causal inference
- 学会: NIPS2017
- 日付: 20170608
- URL: https://arxiv.org/abs/1706.02744
概要
fairnessの評価指標はだいたい予測, センシティブ属性, アウトカムに依存したjoint distributionにのみ依存している.
因果推論の視点は「正しい公平性の指標は何か」から「因果データ生成プロセスにどんなモデルを仮定するか?」にシフトさせる.
因果推論によって下の3つのContributionをした.
- なぜ, そしてどんな時に指標が失敗するのかを明確に述べ, その問題を定式化した.
- 今まで無視されてきた微妙なことを明らかにし, それが根本的な問題であることを示した.
- 差別を回避するための因果基準の公平性を定義し, それらを満たすアルゴリズムを提案する.
2. Unresolved discrimination and limitations of observational criterion
resolving variable: 差別的な影響をAから受けていない変数
unresolving variable: 差別的な影響をAから受けている変数
Definition 1. (Unresolved Discrimination)
次の2つを満たす時, 因果グラフにおける変数Vは未解決の差別という.
- resolving変数によってブロックされていないAからVへのダイレクトパスが存在する.
- V自身がnon-resolving変数.
Theorem 1.
resolving variableを特定できているセンシティブ属性A, ラベルY, 特徴X1,...,Xnのjoint distributionが与えられた時,
ベイズ最適な制約なし分類器もしくはベイズ最適なequal oddsを満たした分類器がunsolved discriminationを示すかどうかを決定できる評価指標は存在しない.
3. Proxy discrimination and interventions
Definition 2. (Potential proxy discrimination)
次を満たす時, 因果グラフにおける変数Vはpotential proxy discriminationを示す.
- proxyからブロックされないAからVへのダイレクトパスが存在する.
- V自身がproxyではない.
definition 3. (Proxy discrimination)
次を満たす時, 識別器Rはproxy Pに基づくProxy discriminationではないことを示す.
- 全てのp, p’について
- P(R|do(P=p)) = P(R|do(P=p’))
16本目の論文: Estimation of causal effects using linear non-Gaussian causal models with hidden variables
wataokaの日本語訳「隠れ変数のある線形非ガウス因果モデルを用いた因果効果の推定」
- 種類: causal inference
- 学会: International Journal of Approximate Reasoning 2008
- 日付: 20081000
- URL: https://189568f5-a-62cb3a1a-s-sites.googlegroups.com/site/sshimizu06/ijar07.pdf?attachauth=ANoY7cpqDtq0TkopTBeV1UYzz2oXubY2uiu6V-FC8ZnvVB8ek_mwcJX3-Is8a0a_SzkgNKcxnRNrYI7j6nQn5bljXUp502hDKP9dAZJq4qZnHeYMwWUAko1Bt5z2coxAghulrT1ic-PFyDRTWNIikZyrA69pkpt0St2XOF0SA_t72skyVRceUvUvp9v38AxG2j7kQx-dQqWF8vQKNHJSFl-vjvSmWPFfBg%3D%3D&attredirects=0
概要
- LvLiNGAMを提案.
- LvLiNGAMは隠れ変数(未観測共通原因)が存在していても因果推論が可能なモデル.
- 混合行列に線形性を仮定.
- 外生変数の分布に非ガウスを仮定.
- 数値シミュレーションを行い, コードも公開している.
2 Two observed variables
2.3 Exploiting non-Gaussianity
忠実性を仮定すると, 行列Aさえ推定できれば6つのモデルは識別可能. Aに関してはICAの理論を適用することができる. 共通原因がない場合は独立変数の数と観測変数の数が同じであり, ‘easy case’である. 共通原因がある場合は’overcomplete basis’ ICA(不完全基底ICA)の困難なケースである. ただし, 行列Aは十分なデータがあれば識別可能であることが証明されている. (実用的な推定方法については4章で議論している.)
共通原因が複数ある場合について
共通原因が複数あったとしても, 因果グラフの構造は正しく識別することができる.
しかし, パラメータに関しては, 共通原因がN_hあるとすると, N_h + 1通りの異なる解が存在する. 理由としては外生変数の割り当て, 交絡因子の割り当ての選択に起因している.
3 The general case
3.2 Canonical models
Figure2(a)のx7
観測変数から影響を受けていて, 誰にも影響を与えないような潜在変数は検知不可能であるが, 「観測変数間の因果関係を明らかにしたい」という目的の上では検知する必要がないので問題ではない.
Figure2(b)のx6
観測変数→x6→潜在変数というようなx6は観測変数→潜在変数という風に書き下すことができるので, 探索した結果そのような書き下した結果が得られる. Figure2(b)
Canonical model (正準モデル)の定義:
以下を満たすlatent variables LiNGAMモデル
- 潜在変数はrootノード(親を持たない)
- 潜在変数は少なくとも2つの子をもつ
- 潜在変数は平均0で分散1
- 異なる2つの潜在変数が同じ子集合を持つことはOKだが, 観測変数への影響度の大きさが同じ比率になってはいけない
任意のlatent variable LiNGAMモデルを入力とし, それのCanonical modelを出力するアルゴリズムも提案している. Algorithm A
3.3 Model estimation in the Gaussian framework
この節では, related worksのように関連する話題を出している.
外生変数にGaussを仮定した場合
- 潜在変数がないとわかっていて, 変数の時間順序がわかっているときは簡単だよ.
- 潜在変数がないとわかっていて, 変数の時間順序がわかっていないと一意に推定できないよ.
- 潜在変数がないとわからない時, FCIのようにデータを生成した可能性のある忠実な因果モデルセットを出力するアルゴリズムはあるが, 条件付き独立だけに基づいているため, 出力できる情報量がかなり制限されている.
非ガウス性を利用することでモデルを区別する能力を大幅に向上できるのに...という話
3.4 Model estimation based on non-Gaussianity
任意の忠実なlatent variable LiNGAMモデルによって生成されたデータから生成モデルと観測的に等価な正準モデルのセットを推定する方法を示す.
x~をfull data vectorとする.
変数を中心化すると, 次のように書ける.
$\hat{x}$ = $\hat{B}$$\hat{x}$ + e
(DAGの過程をおいているので)
また, 因果順序k(i)を知っているなら, $\hat{B}$は厳密な下三角行列に並び替えることができる.
$\hat{x}$について解くと,
\hat{x} = \hat{A}e
\hat{A} = (I - \hat{B})^{-1}
となる.
A~もまた(厳密ではないが)下三角行列に並び替えることができる.
これは標準線形ICAの枠組みで解くことができる.
(線形, 非ガウス, 独立などの仮定があるから)
観測変数の数が独立変数の数より少ないとき,overcomplete basis in the ICAの枠組みとなる.
Algorithm B:
overcomplete basis Aと観測された変数の平均が与えられた時, 基底と互換性のある全ての観測的に等価な正準latent variable LiNGAMモデルを計算する.
- NhはAの列数から行数から引いたもの.
- Aの列それぞれを観測変数の外生変数と潜在変数の外生変数に属するものとして分類する.
- 潜在変数として選択されたものが最初に来るようにAを並び替える.
- 行列Aの上部にfig3aのようにゼロを拡張されることで, 推定行列$\hat{A}$を得る.
- $\hat{A}$をlower三角形に並び替えできるかどうかを検定する. できなければ次の分類に進む. (for文でいうcontinue)
- $\hat{B}$ (=I-$\hat{A}~{-1}$)を計算する.
- Bのネットワークが忠実性の仮定に適合していることを確認する. そうでない場合は次の分類に進む. (for文でいうcontinue)
- データを生成した可能性のある観測的に等価なモデルのリストに$\hat{B}$を追加する.
wataokaのコメント
未観測共通原因を扱う因果探索はLvLiNGAMの他のも多く存在しているが, 未観測共通原因の値まで推定する手法はほとんど存在しない. OvercompleteICAの枠組みに落とし込んだ後, 行列の推定のためにEMアルゴリズムを用いることがあるが, 非常に計算量が高いため, 高次元では使い物にならない. 2019年にLFOICAというディープラーニングを用いた手法が提案されているので, そちらを用いればなんとかいける.
17本目の論文: ParceLiNGAM: A causal ordering method rubust against latent confounders
wataokaの日本語訳「ParceLiNGAM: 潜在交絡に対してロバストな因果順序法」
- 種類: causal inference
- 学会: Neural Computation2014
- 日付: 20130329
- URL: https://arxiv.org/abs/1303.7410
概要
- 潜在交絡因子が存在しないという仮定を取っ払ったLiNGAMであるParceLiNGAMを提案.
- Key ideaは外生変数間の独立性をテストすることで潜在交絡因子を検知し, 潜在交絡因子によって影響を受けていない変数集合(parcels)を見つけるということ.
- 人工データと脳画像データで実験を行った.
xjと全てのiに対する残差r(j)iが独立である=xjはsource変数という性質とその逆を用いて, source変数とsink変数を排除していくアルゴリズムをベースとして, それが解けない状況にもrobustな改良もしている. 出力はcausal order matrix
3 A method robust against latent confounders
3.1 Identification of causal orders of variables that are not affected by latent confounders
x = Bx + Λf + e (3)
Lemma 1
式(3)における潜在変数LiNGAMの仮定を満たし, サンプル数が無限である時, 以下が同値.
「全てのiに対してx_jと残差r(j)_iが独立」
「x_jは親も潜在交絡因子も持たない外生変数」
Lemma 2
Lemma 1の逆. 全部と依存してたらsink変数だよ的な定理.
wataokaのコメント
潜在行楽因子は存在するが, その値までは推定しない手法.
18本目の論文: In-Domain GAN Inversion for Real Image Editing
wataokaの日本語訳「実画像編集のためのIn-Domain GAN Inversion」
- 種類: GAN inversion
- 学会: ECCV2020
- 日付: 20200331
- URL: https://arxiv.org/abs/2004.00049
概要
- 背景
- GANの潜在空間には多様な意味論が含まれている.
- しかし, それを実画像編集に利用するのは難しい.
- 一般的な既存のGAN inversionの手法はピクセル単位での画像再構成.
- その方法では, 潜在空間の意味論ドメインに埋め込むことは難しい.
- この論文では, in-domain GAN inversionを提案する.
- 入力画像を忠実に再構成する.
- 埋め込んだコードが編集のための意味論を持ち合わせている.
- 手法
- まず, 新たに提案するdomain-guidedエンコーダーを学習する.
- 次に, エンコーダが生成する潜在コードを微調整し, ターゲット画像をより復元するために, エンコーダを正則化器として関与させることで, ドメイン正則化の最適化方法を提案する.
- 提案手法は実験により以下が示された.
- 安全な実画像の再構成
- 編集タスクにおいて多様な画像を生成できる
2 In-Domain GAN Inversion
大体の訳)
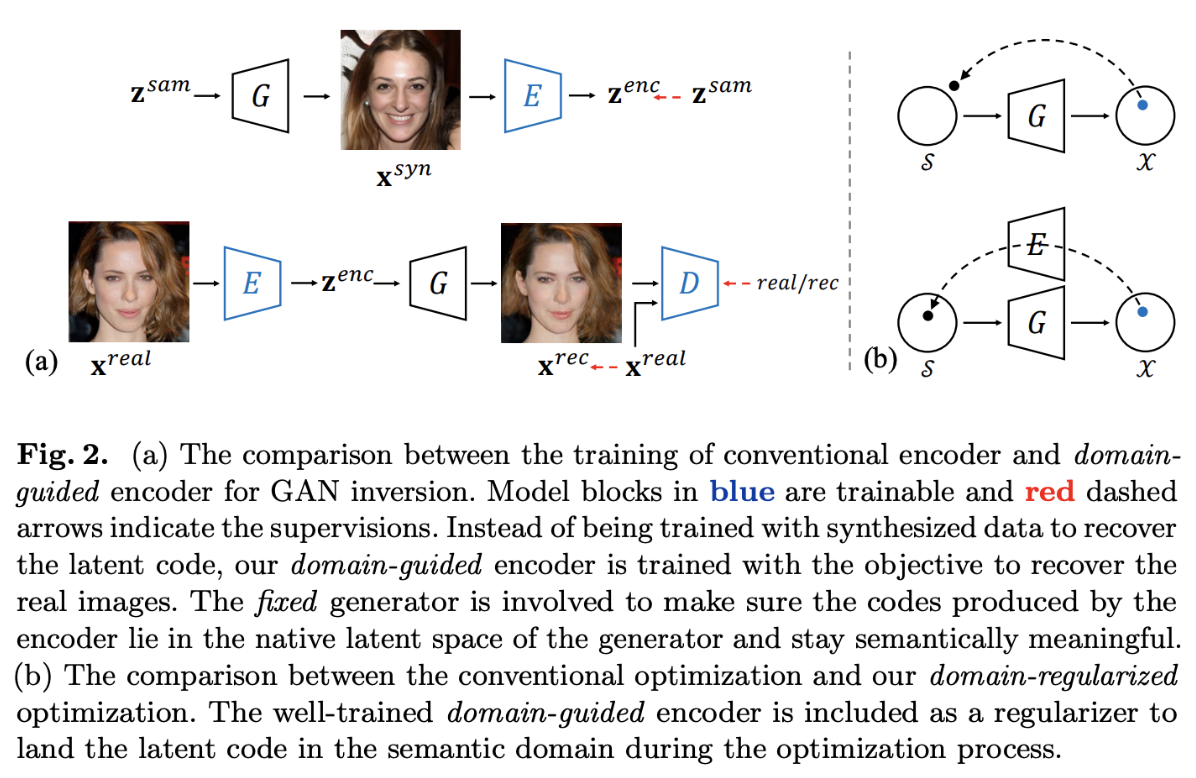
Fig.2. (a) 従来のエンコーダの学習とdomain guided encoder for GAN inversionの違い. 青色のブロックは訓練を行うモデル. 赤色の点線矢印は教師データからの監視を示している. 従来では, z→生成画像→z’だったが, 提案するdomain -guided encoderは実画像→e→再構成画像とする. (b) 従来の最適化と提案するドメイン正則化の最適化の比較. 訓練ずみdomain-guided encoderは最適化プロセスの中で意味論的ドメインに潜在コードを埋め込みための正則化として含まれる.
2.1 Domain-Guided Encoder
zをサンプルし, 画像を生成し, zを再構成するだけの従来手法とは以下の3つの点で異なる.
- 潜在空間での再構成ではなく, 画像空間でも再構成.
- 生成データではなく, 実データでの学習.
- 再構成データをrealにするためにDiscriminatorを使用する.
2.2 Domain-Regularized Optimization
GANは潜在分布から画像分布への近似という分布レベルのものであるが, GAN inversionはインスタンスレベル. なので, エンコーダのみで逆変換を行うのには限界がある. それゆえ, 提案したdomain-guided encoderで推論した潜在コードをピクセルレベルで修正する必要がある.
Fig.2.(b)で示している通り, 従来手法ではgeneratorのみに基づいた, 言わば自由な最適化が行われる. (xからどの意味論にするのかが結構自由という意味) なので, 割とドメイン外の潜在コードを推論してしまう可能性がある. 我々はdomain-guided encoderを用いてxから最適なzを求める. 理想的なスタート地点として, domain-guided encoderの出力を用いる. これによって, この後の最適化で局所解に陥ることを防ぐ. そしてdomain-guided encoderを正則化として用いる. これによって, 意味論のドメイン外の潜在コードを推論してしまうことを防ぐ. xが与えられた時に, zを推論する際の目的関数は以下である.
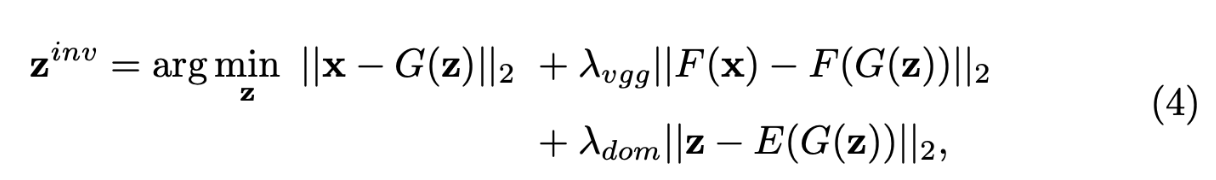
where FはVGGのような特徴量抽出用モデル.
つまり, xが与えられた時に, zは以下を満たすもの.
- 生成画像G(z)がxに近い.
- 生成画像G(z)の特徴量とxの特徴量が近い.
- 生成画像G(z)のエンコードが元のzからできるだけ離れない.
結果
顔属性変換, image interpolation, semantic diffusionタスクに適応させて, 従来手法よりよかった.
wataokaのコメント
"TensorFlowのコードもPyTorchのコードもある
website: https://genforce.github.io/idinvert/
interfaceganとLIAと同じgithubグループ"
19本目の論文: FACE: Feasible and Actionable Counterfactual Explanations
wataokaの日本語訳「FACE: 実現可能で実用可能な反実仮想説明」
- 種類: counterfactual
- 学会: AAAI2020
- 日付: 20190920
- URL: https://arxiv.org/abs/1909.09369
概要
- 反実仮想生成の欠点その1
- 反実仮想生成における現在のSOTAはrepresentativeではない.
- つまり, そのSOTAシステムを使用すると, 非現実的なアドバイスをされる.
- 例えば, 障害者が生命保険に加入できるように「めちゃくちゃスポーツするといいよ。」とかアドバイスされる.
- 反実仮想生成の欠点その2
- 現在の状態と提案の間の実行可能経路を考慮に入れられていない.
- 例えば, スキルが低い人が住宅ローンに成功するためのアドバイスとして, 「収入を2倍にするといいよ。」とかアドバイスされる. しかし, 実際にはスキルをあげることの方が大切. 現在の状態を考慮に入れられていない.
- contributionその1
- Counterfactual Explanationの新しいラインを提案.
- actionableでfeasibleなパスを提供する.
- contributionその2
- FACEを提案.
- 重み付き最短経路問題に基づいたfeasible pathを計算するアルゴリズム.
Introduction
どんなタスク?
タスクはCounterfactual Explanations
「なぜローンの申請に失敗したのか?」という疑問に対して「なになにをするべきだった」と返してくれるもの.
手法
他のサンプルが近くに存在する経路を通りながら別クラスの領域に移動させていくことで, 不自然な変換を行わないようにしている.
結果
人工トイデータとMNISTで実験した. 0→8への変換の時, 0でも8でもない画像が生まれない.
20本目の論文: Controlling generative models with continuous factors of variations
wataokaの日本語訳「変動の連続的な要因による生成モデルの制御」
- 種類: GAN
- 学会: ICLR2020
- 日付: 20200128
- URL: https://arxiv.org/abs/2001.10238
概要
semi-supervised editing. 鳥とかきのことかを編集している. pixel-wiseな損失では高周波成分をうまく再構成できていないと怒っていた.
2 LATENT SPACE DIRECTIONS OF A FACTOR OF VARIATION
2.1 Latent Space Trajectories of an Image Transformation
G: 潜在空間→画像空間
Tt: 画像空間→画像空間 (parametrized by t)
I = なんかの画像とした時,
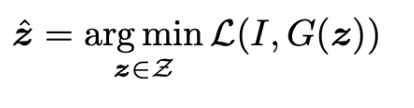
となるような潜在ベクトルz^を見つけたい.
Encoderを学習すればできることだがそうはしない.
三つ組(z0, zdt, dtn)のデータセットを作成→それを用いて
このまま最適化すれば, 尤度の低い点に最適値を見つけてしまい, unrealisticな画像を生成してしまう危険がある. zは多次元ガウシアン分布に従うので, ノルムの期待値はsqrt(d)となる. (d: 潜在空間の次元) 従って, 下のように制限を加える.
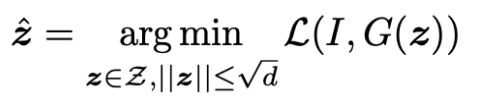
↑
式(2)
2.1.1 Choice of the Reconstruction Error L
順当に考えれば,
- MSE
- pixel-wise cross-entropy
とかが妥当.
しかし, 実験的にpixel-wiseな上の二つではぼやけた写真が生成されることがわかっている.
ぼやける仮説:
テクスチャの多様体は非常に高次元だが潜在空間が低次元である. pixel-wiseな誤差では, テクスチャが一つ領域として再構成されるので, 高周波数の位相が潜在空間では符号化できない. → 周波数成分毎に再構成すればいい!
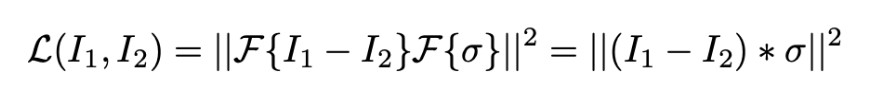
- F: フーリエ変換
- σ: ガウシアンカーネル
-
- : convolution operator
つまり, 画像1と画像2のpixel-wiseの引き算をして, それをガウシアンフィルタする. (ある周波数成分だけ取り出す.)
- : convolution operator
論文では, 高周波数成分の再構成は不可能であると仮定し, 低周波数成分だけを取り出して学習している. よりぼやけた解になるようにしている. (はぁ?)
2.1.2 Recursive Estimation of the Trajectory
式(2)を下のようにすることで問題を解く.
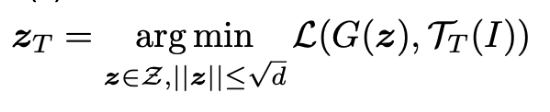
(生成画像を変換画像に近づけるzを見つける.)
自然画像の線形和は自然な画像にならないので, 自然画像の多様体が高度に湾曲していることがわかる. このことから, 式(2)の問題の収束が遅いことが理解できる.
対処するために, transformation Τtを何度も行う多様体上の最適化を提案する.
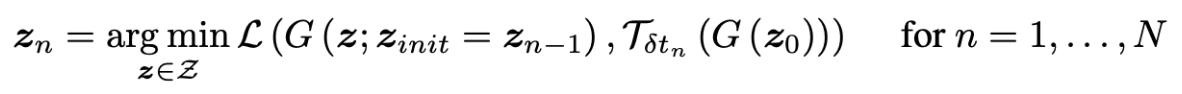
wataokaのコメント
問題への仮説→改善案という綺麗な研究な気がした. もちろん理論的に証明し切って改善案の提案とかの方がかっこいいが, 現在のディープラーニングに対する理解の推し進め方はこの論文のような形が多く, 理論屋より実験屋が突っ走ったいっときの航空力学の世界を彷彿とさせる.
21本目の論文: Counterfactual Image Network
wataokaの日本語訳「反実画像ネットワーク」
- 種類: counterfactual
- 学会: ICLR2018
- 日付: 20180216
- URL: https://openreview.net/pdf?id=SyYYPdg0-
概要
目的はセグメンテーションの向上.
それを実現するために, セグメントした層を一定確率で削除し, 削除された物がreal dataであるかどうかをdiscriminatorに判断させることで, より自然な削除(つまりより自然なセグメント)ができるようになっていく.
仮説
オブジェクトを削除すれば自然であるが, ランダムパッチを削除すれば不自然である. このように「オブジェクトを綺麗にセグメントできること」<=>「そのオブジェクトを削除した時反実仮想画像となる」という仮説を考えている.

アーキテクチャ
画像をエンコードし, K個のレイヤーでセグメントする. 一定確率pでcombineし, 1-pでcombineしない. そうして生成されが画像をDiscriminatorが識別することで, より自然に削除できるようになっていく.
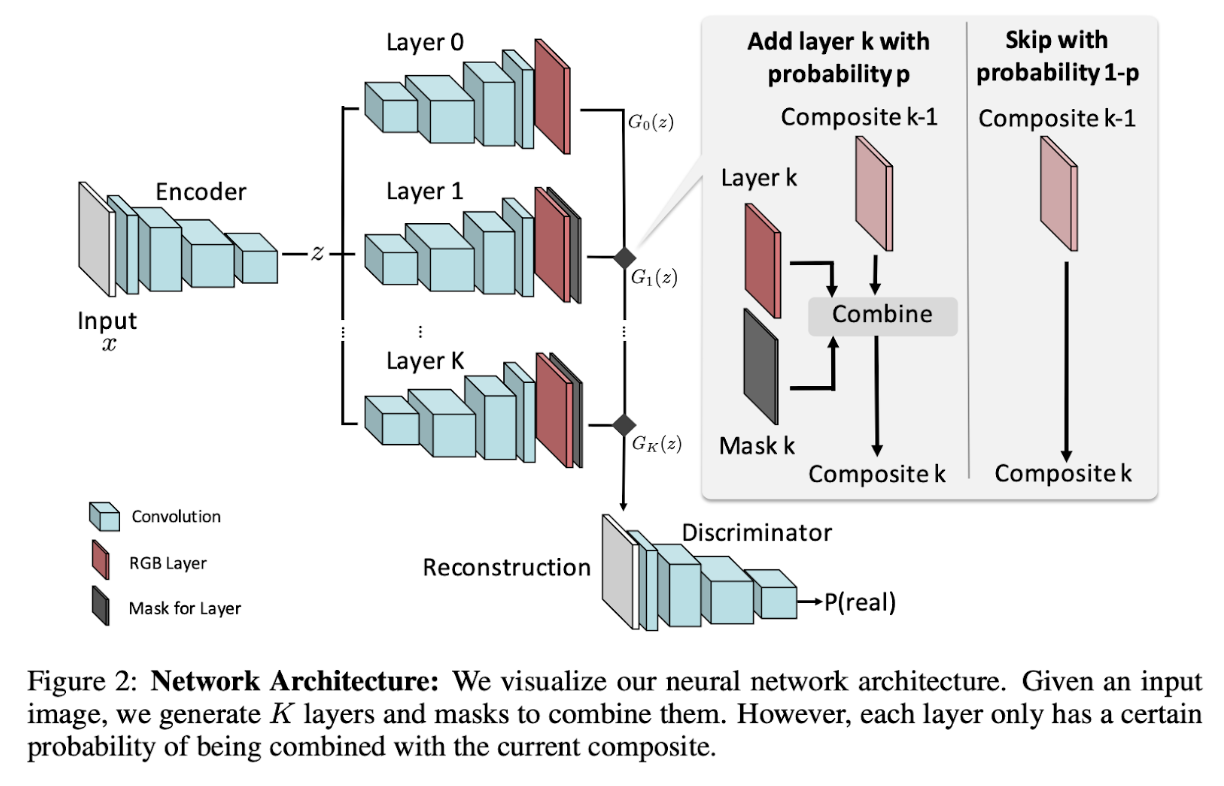
レイヤーが出力したセグメントの例

22本目の論文: ON THE “STEERABILITY” OF
GENERATIVE ADVERSARIAL NETWORKS
wataokaの日本語訳「GANの「操縦性」について」
- 種類: GAN
- 学会: ICLR2020
- 日付: 20200311
- URL: https://openreview.net/pdf?id=HylsTT4FvB
概要
semi-supervised editing手法. GANはデータセットバイアス(e.g.物体が中心にくる)に影響されているが, 潜在空間で「steering」することで, 現実的な画像を作成しながら分布を移動することができる.
1 Introduction
main findings
- GANの潜在空間の中でのsimple walkで, 出力画像空間におけるカメラモーションや色変換などを可能にする. そのsimple walkは属性ラベルやラベルやソース画像とターゲット画像のラベル無しで学習できる.
- 線形walkは非線形walkと同様に効果的. モデルを明示的に学習しなくてもそうなるようになってる.
- モデルの分布をどれだけシフトできるかとデータセットの豊さの関係を定量化した.
- 変換は汎用フレームワーク. BigGAN, StyleGAN, DCGANなどで行える.
- 歩行軌跡の訓練により, 操縦性を向上させる.
2 Related work
Applications of latent space editing
- Denton, 2019: 顔属性検出器のバイアス測定
- Shenet, 2019: 潜在空間のdisentanglementの可視化
- この論文: データセットバイアス測定
3 Method
目標: Figure 2のように, 潜在空間内を移動することで, 出力空間内の変換を実現する
この目標は入力空間における変換が出力空間における等価変換をもたらすという等変量における考え方だと捉えることができる. (c.f. Hinton(2011), Cohen(2019), Lenc&Vedaldi(2015))
zにαwを足すことが操縦で, 所望の操作edit(G(z), α)との損失を最小化する. 損失はL2ノルム
edit(G(z), α)は, 例えば生成画像G(z)をα倍ズームしたものとか. αwを足すような線形的な移動だけでなく, ニューラルネットを用いた非線形な手法にも拡張できる.
メモ
- edit(G(z), α)が計算可能なものは限られている.
- edit(G(z), α)が計算可能ということはそのような画像を作れること自体に価値はない.
- なので, steerabilityの評価からデータセットバイアスにつなげている.
4 Experiments
4.1 What Image Transformatinos can we achieve in latent space?
walkさせた時に2つの失敗を観測した.
- unrealisticになってしまう.
- 所望のtransformが全然できていない
猫ちゃんをzoom-inとzoom-outしようとしたら溶けたり立ち上がったりした.
ピザを回転させようとしても全くしなかった
↓
ImageNetのデータセットにある画像に限界があるからではないかと考えた.
興味深いことに, walkがoutputに影響を与える量は画像のclassに依存していた.
(クラゲは様々な色に変化ができたが, goldfinch(黄色の鳥)はできなかった)
(噴火する火山は明るさを変えられたが, アルプスは変えられなかった)
wataokaのコメント
GANの操縦性というキャッチーな言い方がとても好き.
これは自分の勝手な妄想だが,
- GANの潜在変数をいじって編集したい!
- 考えた!
- しかしこれ編集自体に価値ないよな... zoomとかできるし...
- よし, この技術でデータセットバイアス測ろう!ちょっとうまくいかんやつもあるし!
みたいな研究の流れなんじゃね?と思っている. もしそうだとしたら, 逃げ方がうますぎる. これはディスっているのではなく, 研究における発表の仕方, ひいてはプロモーションの仕方は言い方次第でとても変わることを学べた. 自分も何かを発表したい時は完璧な言い方を一度は模索しようと思う.
23本目の論文: GANalyze: Toward Visual Definitions of Cognitive Image Properties
wataokaの日本語訳「GANalyze: 認知的画像特性の視覚的定義に向けて」
- 種類: GAN
- 学会: ICCV2020
- 日付: 20190624
- URL: https://arxiv.org/abs/1906.10112

Figure1: GANalyzeで作成した可視化. 中央の列は, 元の種となる生成された画像を表している. 元画像は関心のある特性(記憶力, 美的感覚, 情緒的価値)によって, より特徴的な(右)かより特徴的でない(左)かを判断するように修正されている. 画像のそれぞれの特性のスコアは左上隅に表示されている.
概要
- 記憶力、美学、感情的価値などの認知特性を研究するためのフレームワークを提案.
- GANの潜在変数を記憶性を高める方向にナビゲートすることで, 生成された特定の画像が記憶に残りやすくなったり, 記憶に残らなくなったりするためには, どのように見えるかを可視化することができる.
- 結果として得られる「視覚的定義」には, 記憶性の根底にあるかもしれない画像の特性(「物体の大きさ」など)が表面化されている.
- 本研究では, 行動実験を通じて我々の手法が人間の記憶力に影響を与える画像操作を実際に発見できることを検証する.
- さらに, 同じフレームワークを用いて, 画像の美学や情緒的価値観の分析が可能であることを実証する.
2 手法 (Model)
2.1 Formulation
目的: 任意のクラスyの任意のノイズベクトルzを変換し, その結果生成された画像の記憶性がある量αだけ増加(または減少)するように学習することである.
A: Assessor (評価関数): 生成画像→属性値
とすると,
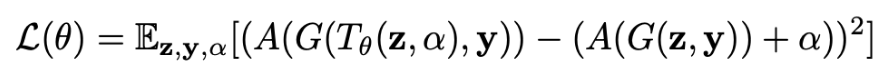
を最小化するT(のパラメータθ)を Adamで探索する.
この論文では,
T_θ(z, α) = z + αθ
A: MemNet
としている.
MemNet
memorabilityを予測してくれるCNN.
結果
画像の記憶性が物体の大きさとして表面化したことを示した.
wataokaのコメント
発想というか, 学習結果の解釈がキャッチーで見習うべきことかと思う. しかしMemNetのことを信頼しすぎてる感もある.
website: http://ganalyze.csail.mit.edu/
24本目の論文: Disparate Interactions: An Algorithm-in-the-Loop Analysis of Fiarness in Risk Assessments
wataokaの日本語訳「異なる相互作用: リスク評価に関するFairnessの分析ループ内のアルゴリズム」
- 種類: fairness
- 学会: FAT2020 Best paper
- 日付: 2018/11/20
- URL: https://scholar.harvard.edu/files/19-fat.pdf
概要
機械学習の決定に関するFairnessではなく, 機械学習の出力を人間がどう解釈するかが重要. 参加者を雇って, criminal judgeをしてもらった. そして, disparate interactionsを観測した. (リスク評価を使用することで黒人にリスク予測が高くなる)
手法
disparate interactionsに避けるためにalgorithm-in-the-loopを提案. human-in-the-loopはアルゴリズを向上させるために人を加えることだが, algorithm-in-the-loopは逆.
25本目の論文: Equality of Epportunity in Supervised Learning
wataokaの日本語訳「教師あり学習の機会平等」
- 種類: fairness
- 日付: 2016/10/07
- URL: https://ttic.uchicago.edu/~nati/Publications/HardtPriceSrebro2016.pdf
概要
Equal Opportunityを提案した論文.
手法
「異なるセンシティブ属性間においてprecisionが等しい」がequal opportunity
26本目の論文: Learning Non-Discriminatory Predictors
wataokaの日本語訳「無差別な予測器の学習」
- 種類: fairness
- 日付: 2017/11/01
- URL: https://arxiv.org/pdf/1702.06081.pdf
概要
公平性の汎化バウンドはモデルの複雑さに依存しなくさせることができることを示した論文.
27本目の論文: Flexibly Fair Representation Learning by Disentanglement
wataokaの日本語訳「Disentanglementによる柔軟な表現学習」
- 種類: fairness
- 学会: ICML2019
- 日付: 2019/06/06
- URL: https://arxiv.org/abs/1906.02589
概要
VAEでdisentanglementした表現を獲得. その表現を用いて, flexibly fairな応用を行う.
手法
非センシティブな表現zとセンシティブな表現bに切り分ける. 任意のbiとbjは独立, bとzは独立, bとセンシティブ属性は相互情報量を最大化させるようにobjectを設計した.
wataokaのコメント
埋め込まれたsensitive latent, bはsensitive attribute, aを予測できるように埋め込まれている. うまくdisentangleされたbのうち, 特定のsensitive attributeを消すということはその属性を予測されないようにしているということ. つまりdemographic parity最適化.
28本目の論文: Contional Learning of Fair Representations
wataokaの日本語訳「公平表現の条件付き学習」
- 種類: fairness
- 学会: ICLR2020
- 日付: 2019/10/16
- URL: https://arxiv.org/abs/1910.07162
概要
BERがaccuracy parityとequalized oddsを同時に最適化できることを証明.さらに, EOが満たされた時, BERはそれぞれのグループのupper boudとなることを証明. しかもdemographic parityも守られる.
29本目の論文: Fair Division of Mixed Divisible and Indivisible Goods
wataokaの日本語訳「割り切れるグッズと割り切れないグッズの公平な区分」
- 種類: fairness
- 学会: AAAI2020
概要
Fair division問題におけるEnvy-Freenessを拡張したEnvy-Freeness for Mixed goodsを提案し, その割り当てアルゴリズムも提案している.
30本目の論文: Learning Fair Naive Bayes Classifiers by Discovering and Eliminating Discrimination Patterns
wataokaの日本語訳「差別パターンを発見し, 除去することによる公平なナイーブベイズ分類器の学習」
- 種類: fairness
- 学会: AAAI2020
概要
この研究では部分的観測をするナイーブベイズ分類器を考える. あるセンシティブ属性が観測されるかどうかで生まれる差別を紹介.
手法
modelがfairになるまで差別パターンを発見し, 除去していくアプローチをした. 結果, 簡単な制約を加えるだけで多くの差別パターンを削除することができた.
31本目の論文: Fairness in Network Representation by Latent Structural Heterogeneity in Observational Data
wataokaの日本語訳「観測データにある潜在的な構造の不均一性によるネットワーク表現の公平性」
- 種類: fairness
- 学会: AAAI2020
概要
network representation learningにおけるfairnessの論文.
手法
Mean Latent Similarity Discrepancy(MLSD)という測度を提案. MLSDは構造的不均一性に対して敏感であるノード表現における差異を計算する. (Figure1. みたいなのが構造的不一致に対して敏感なノード表現)
32本目の論文: White-box Fairness Testing through Adversarial Sampling
wataokaの日本語訳「敵対的サンプリングを用いたホワイトボックス公平性テスト」
- 種類: fainress
- 学会: ICSE2020
- URL: https://ink.library.smu.edu.sg/cgi/viewcontent.cgi?article=5635&context=sis_research
概要
個人差別を探索するための手法を提案. 勾配を用いた探索で, 既存手法よりスケーラブルで軽量な探索方法となっている.
33本目の論文: Π-nets: Deep Polynomial Neural Networks
wataokaの日本語訳「Π-nets: ディープ多項式ニューラルネットワーク」
- 種類: general
- 学会: CVPR2020
- URL: https://arxiv.org/abs/2003.03828
概要
pi-netというCNNに変わる手法を提案. 出力は入力の高次元多項式. pi-netは日線形関数無しにDCNNよりいい表現を獲得でいる. 活性化関数を用いると画像生成でSOTA. また, このフレームワークでなぜStyleGANがうまくいったかがわかる.
手法
pi-netは特別な種類のskip connectionで実装され, それらのパラメータは高いオーダーのテンソルを通して表現される.
34本目の論文: Cost-Sensitive BERT for Generalisable Sentence Classification with Imbalanced Data
wataokaの日本語訳「不均衡データの一般化可能な文書分類のためのコストセンシティブBERT」
- 種類: nlp, imbalance
- 学会: NLP4IF2019
- 日付: 20200316
- URL: https://arxiv.org/abs/2003.11563
概要
BERTはdata augmentation無しに不均衡なクラスを処理できるが, trainとtestでデータが似ていない場合は一般化できないことを示し, その場合の対処法を提案.
手法
ウィルコクソンの符合順位検定を用いてp値を計算することで二つのsetの類似度を比較し, 一定値以上は不均衡データに対応できていないことを示した. コストセンシティブな手法は, misclassificationしたクラスの重要度をますように設計.
結果
propaganda fragment-level identificationとpropagandadistic sentence-level identificationの2つのタスクに適応させた.
35本目の論文: Domain Adaptation by Class Centroid Matching and Local Manifold Self-Learning
wataokaの日本語訳「クラス重心マッチングと局所多様体自己学習によるドメイン適応」
- 種類: domain adaptation, manifold learning
- 日付: 20200320
- URL: https://arxiv.org/abs/2003.09391
概要
ドメインのデータ分布構造を強調するためにsourceとtargetドメインそれぞれのクラスの重心を使用して, target dataに擬似ラベルを割り当てるドメイン適応を提案した.
手法
domain adaptationをclass centoidマッチング問題に置き換えた.
36本目の論文: When NAS Meets Robustness: In Search of Robust Architectures against Adversarial Attacks
wataokaの日本語訳「NASが堅牢性を満たす時: 敵対的攻撃に対して堅牢なアーキテクチャ探索」
- 種類: nas, adversarial attacks
- 学会: CVPR2020
- 日付: 20191125
- URL: https://arxiv.org/abs/1911.10695
概要
敵対的攻撃に堅牢なアーキテクチャを研究したかったので, アーキテクチャ探索を用いた.
結果
密に結合されたパターン, 計算力が少ない場合はdirect connection edgeにCNNを追加する, flow of solution procedure(FSP) matrixなどが効果的だった.
37本目の論文: Fairness Is Not Static:
Deeper Understanding of Long Term Fairness
via Simulation Studies
wataokaの日本語訳「Fairnessは静的では無い: シミュレーション研究による長期公平性のより深い理解」
- 種類: fairness
- 学会: ACM FAT2020
概要
機械学習の研究に用いられるデータセットは静的だが, 実際は長期にわたる動的な問題であると主張.
手法
シミュレーションでagent, environment, metricsの関係をタイムステップ毎に解析した.
wataokaのコメント
ソースコードが公開されている. https://github.com/google/ml-fairness-gym
38本目の論文: Wasserstein Fair Classification
wataokaの日本語訳「ワッサースタイン公平分類」
- 種類: fairness
- 日付: 20190728
概要
ワッサースタイン距離の最小化がStrong Demographic Parityの最小化と等しいことを証明.
39本目の論文: When Worlds Cllide: Integrating Different Counterfactual Assumptions in Fairness
wataokaの日本語訳「世界が衝突するとき: 公平性における異なる反事実な仮定の統合」
- 種類: fairness, counterfactual
- 学会: NIPS2017
- 日付: 20171204
- URL: https://papers.nips.cc/paper/7220-when-worlds-collide-integrating-different-counterfactual-assumptions-in-fairness.pdf
概要
全ての因果関係を検証することは不可能なので, 複数の因果モデルに対して, どちらの因果の世界が正しいかではなく, どちらが公平な判断を提供するかを考えることが望ましい. 本論文では, 同時に一度の因果モデルに対して公平な予測ができる方法を提案する.
40本目の論文: Causal Reasoning for Algorithmic Fairness
wataokaの日本語訳「アルゴリズムの公平性のための因果関係」
- 種類: fairness, causal inference
- 日付: 20180315
- URL: https://arxiv.org/abs/1805.05859
概要
既存のfairness手法のレビューし, あらゆるfairアプローチにとって因果的アプローチが必要であることを議論した. また, 近年の因果ベース公平性へのアプローチを詳細に解析した.
41本目の論文: Path-Specific Counterfactual Fairness
wataokaの日本語訳「パス特有の反実仮想公平性」
- 種類: fairness, counterfactual
- 学会: AAAI2019
- 日付: 20180222
- URL: https://arxiv.org/abs/1802.08139
概要
Path-Specific Counterfactual Fairnessを提案. unfairなpathwayに沿った影響を無視する因果手法
手法
センシティブ属性によって悪影響を及ぼす観測を修正し, 使用する. ディープラーニングと近似推論で非線形なシナリオに適用.
結果
AdultとGermanで実験.
42本目の論文: Counterfactual Fairness: Unidentification, Bound and Algorithm
wataokaの日本語訳「反実仮想公平性: Unidentificationとboundとアルゴリズム」
- 種類: fairness, counterfactual
- 学会: IJCAI2019
- 日付: 20190810
- URL: https://www.ijcai.org/Proceedings/2019/0199.pdf
概要
反事実の値が特定的でない場合, counterfactual fairnessは限界がある(計算しにくい). 非特定的な反事実の値を数学的にboundした. また, counterfactually fairな分類器を構築するための理論的に正しいアルゴリズムを開発した.
手法
τ-Counterfactual Fairnessを定義し, これが閾値を超えないように学習する.
43本目の論文: Counterfactual fairness: removing direct effects through regularization
wataokaの日本語訳「反実仮想公平性: 正則化による直接的影響の削除」
- 種類: fairness, counterfactual
- 日付: 20200226
- URL: https://arxiv.org/pdf/2002.10774.pdf
概要
Controlled Direct Effect (CDE)を用いて因果関係を取り入れた新しい公平性の定義を提案.
44本目の論文: WHERE IS THE INFORMATION IN A DEEP NETWORK?
wataokaの日本語訳「ディープネットワークの情報はどこにある?」
- 種類: general
- 学会: ICLR2019
- URL: https://openreview.net/pdf?id=BkgHWkrtPB
概要
DNNが過去のデータから収集した情報は全て重みでエンコードされる.
その情報は未知データに対するDNNの反応にどう影響するのかは未解決問題.
実際, DNN内の情報の定義の仕方や測り方でさえ曖昧.
DNNの重みの情報はaccuracy重みに複雑度とのトレードオフとして測られる.
事前分布に依存する定義としてシャノン 相互情報量やフィッシャー情報量など既知の情報に落とし込まれ, 一般にPACベイズboundを介した汎化と不変性に関連づけることを可能にする追加の柔軟性を提供する.
後者についてはactivationに有効な情報の概念を導入する.
これは未知の入力の決定論的な関数.
これを重みの情報に使用して, 複雑度の低いモデルは汎化性能が向上するだけでなく, 未知の入力の不変表現を学習することに繋がる.
これらの関係はモデルのアーキテクチャだけでなくモデルのトレーニング方法にも依存する.
45本目の論文: Causal Generative Neural Networks
wataokaの日本語訳「因果生成ニューラルネットワーク」
- 種類: causal inference
- 日付: 20171124
- URL: https://arxiv.org/abs/1711.08936
概要
CGNNを提案. 因果構造を発見する.
手法
観測データ分布と生成データ分布のMMDを最小化する.
wataokaのコメント
code: https://github.com/GoudetOlivier/CGNN
46本目の論文: FairGAN: Fairness-aware Generative Adversarial Networks
wataokaの日本語訳「公平なGAN」
- 種類: fairness, gan
- 学会: IEEE ICBD2019
- 日付: 20180328
- URL: https://arxiv.org/abs/1805.11202
概要
FGAN (FairGAN)を提案
手法
G:(z, s)→(x, y)
D1:(x, y)→real or fake
D2:(x, y)→s=0 or s=1
という構成で敵対的学習するだけ.
47本目の論文: The Variational Fair Autoencoder
wataokaの日本語訳「変分公平オートエンコーダー」
- 種類: fairness, vae
- 学会: ICLR2016
- 日付: 20151103
- URL: https://arxiv.org/abs/1511.00830
概要
VFAEを提案.
48本目の論文: Causal effect inference with deep latent-variable models
wataokaの日本語訳「ディープ潜在変数モデルを用いた因果効果推論」
- 種類: causal inference, vae
- 学会: NIPS2017
- 日付: 20170324
- URL: https://arxiv.org/abs/1705.08821
概要
CEVAE (Causal Effect VAE)を提案. Individual Causal Effectを推論するタスクにおいてSOTA. 特定の患者にとっての治療効果を推論することなど, 観測データ個人レベルの因果効果を学習することは意思決定者にとって重要な問題である. 観測データから因果効果を推論する重要な問題は, 介入とアウトカムに影響を与える要素や交絡因子などをうまく扱うことである. 慎重に設計された観測実験は全ての重要な交絡因子を測定することを試みてきた. しかし, 全ての交絡因子にアクセスできない場合, 交絡因子の代理変数にノイズや不確実性が存在してしまう. 近年では, 交絡因子や因果効果をサマライズする未知な潜在空間を推測する潜在変数モデリングが発展している. 私たちの手法は代理変数を用いた因果構造推論を行うVAEに基づいている. そして, 私たちのメソッドは既存手法よりロバストであり, 個人介入効果に関するベンチマークでSOTAであることを示す.
手法
xからq(t|x)を推論し, q(y|t,x)を推論し, q(z|t,y,x)を推論する. zからp(x|z)を推論し, p(t|z)を推論し, p(y|t,z)を推論する. 精度が上がったp(y|t,z)で介入による差異を計算することで, 介入効果を計算する.
結果
人工データと二つのread data(IHDPとJobs)で検証.
wataokaのコメント
FCVAEに引用されている. 理論的保証はないが, empiricalにSOTAを達成して黙らせた感じ.
49本目の論文: Fairness Through Causal Awareness: Learning Latent-Variable Models for Biased Data
wataokaの日本語訳「因果レベルでの公平性: バイアスデータのための潜在変数モデルの学習」
- 種類: fairness, causal inference, vae
- 学会: FAT2019
- 日付: 20180907
- URL: https://arxiv.org/abs/1809.02519
概要
バイアスデータからどのように学習するべきだろうか?ヒストリカルデータセット は歴史的な偏見を含んでいる. (センシティブ属性が観測されたtreatmentやoutcomeに影響を与えたりする.) 分類アルゴリズムは 観測データから学習し, 精度を上げていく過程で, そのようなバイアスを再現してしまう.
ディープラーニングと生成モデルの以前の研究に基づいて, 本論文は観測データからどのように因果モデルのパラメータを学習するかを説明する. (観測不可能な交絡因子が含まれていたとしてもOK)
そして, fairness-aware causal modelingがセンシティブ属性と介入とアウトカムの間の因果効果の推定をよりよく行えることを実験的に示す. さらに, ヒストリカルバイアスデータが与えられた下では因果効果推定がよりaccurateでfairな学習ができることを証拠を示す.
手法
CFVAE (Causal Fairness VAE)を提案. センシティブ属性を交絡因子として考えたことで, ヒストリカルバイアスデータセットにおける因果効果の推論精度が上がった.
50本目の論文: DAGs with NO TEARS: Continuous Optimization for Structure Learning
wataokaの日本語訳「NO TEARSのDAGs: 構造学習のための連続最適化」
- 種類: causal inference
- 学会: NIPS2018
- 日付: 20180304
- URL: https://papers.nips.cc/paper/8157-dags-with-no-tears-continuous-optimization-for-structure-learning.pdf
概要
NP困難であるDAGの構造学習を実数行列上の連続最適化問題に定式化した.
手法
h=tf(e^{W○W})-1とすると, G(W)∈DAGs <=> h(W)=0となる. hは簡単に微分可能なので連続最適化ができる.
51本目の論文: Inclusive FaceNet: Improving Face Attribute Detection with Race and Gender Diversity
wataokaの日本語訳「包括的なFaceNet: 人種や性別に多様な顔属性検知の向上」
- 種類: causal inference
- 学会: FAT/ML 2018
- 日付: 20171201
- URL: https://arxiv.org/abs/1712.00193
概要
問題設定: 性別において, 顔の属性分類の精度を合わせる.
結果
データセット: Faces of the World, CelebA
52本目の論文: Towards Fairness in Visual Recognition: Effective Strategies for Bias Mitigation
wataokaの日本語訳「視覚認識の公平性に向けて: バイアス除去のための効果的な戦略」
- 種類: causal inference
概要
問題設定: 性別において, 顔の属性分類の精度を合わせる.
結果
データセット: CIFAR-10S, CelebA
53本目の論文: Face Recognition Performance: Role of Demographic Information
wataokaの日本語訳「顔認識のパフォーマンス: 人口統計情報の役割」
- 種類: causal inference
- 学会: TIFS2012
概要
問題設定: 性別において, 顔認識の精度を合わせる.
54本目の論文: Balanced Datasets Are Not Enough: Estimating and Mitigating Gender Bias in Deep Image Representation
wataokaの日本語訳「バランスの取れたデータセットは十分でない: ディープ画像表現における性別バイアスの推測と除去」
- 種類: causal inference
- 学会: CVPR2019 Workshop
概要
問題設定: 画像内に映る人物の性別によって, ラベル分類精度を合わせる.
結果
データセット: MSCOCO, imSitu
55本目の論文: SensitiveNets: Learning Agnostic Representations with Application to Face Recognition
wataokaの日本語訳「SensitiveNets: 顔認識の応用とagnostic表現の学習」
- 種類: fairness
- 学会: CVPR2019 Workshop
- 日付: 20190201
- URL: https://arxiv.org/abs/1902.00334
概要
問題設定: 顔認識, 画像分類において, 潜在空間で性別情報を消した上で精度を下げない.
結果
データセット: CelebA, VGGFace2, LFW
56本目の論文: Discovering Fair Representations in the Data Domain
wataokaの日本語訳「データドメインにおける公平表現の学習」
- 種類: fairness
- 学会: CVPR2019
概要
問題設定: 画像から性別を判断できない画像を生成する.
結果
データセット: CelebA, Diversity in Faces, Adult income (タブラー)
57本目の論文: CAN: Creative Adversarial Networks, Generating "Art" by Learning About Styles and Deviating from Style Norms
wataokaの日本語訳「CAN: 敵対的創造ネット, スタイルノルムからスタイルと多様を学習することで芸術を生成する.」
- 種類: GAN
- 学会: ICCC2017
- 日付: 20170621
- URL: https://arxiv.org/abs/1706.07068
概要
アートを生成するCANを提案.
与えられたart distributinoからは外れないように, styleは逸脱するように学習する.
結果
CANが生成したものとアーティストが作ったものを人間に見せた反応を比べた.
58本目の論文: Cost-Effective Incentive Allocation via Structured Counterfatual Inference
wataokaの日本語訳「反実仮想推論による費用対効果の高いインセンティブ配分」
- 種類: counterfactual
- 学会: AAAI2020
- URL: https://aaai.org/Papers/AAAI/2020GB/AAAI-LopezR.787.pdf
概要
従来のpolicy最適化フレームワークとは違った, 報酬構造と予算の制約を考慮に入れるという反実仮想policy最適化問題を解く手法を提案した.
59本目の論文: Evaluating the Disentanglement of Deep Generative Models through Manifold Topology
wataokaの日本語訳「多様体トポロジーを用いた深層生成モデルのdisentanglementの評価」
- 種類: disentanglement
- 日付: 20200605
- URL: https://arxiv.org/abs/2006.03680
概要
学習された表現の条件付きsubmanifoldsのトポロジカルな類似度を測定することで, disentanglementを定量化する手法を提案.
wataokaのコメント
全然理解できてない.
60本目の論文: Understanding image representations by measuring their equivariance and equivalence
wataokaの日本語訳「同変性と等価性を測定することによる画像表現の理解」
- 種類: general
- 学会: CVPR2015
- 日付: 20141121
- URL: https://arxiv.org/abs/1411.5908
概要
equivariance:入力画像の変換がどう埋め込まれるか. invariance:その変換が影響を与えいない. equivalence:CNNの2つの異なるパラメータが同じ情報を見ているか. これらの特性を確立するための方法はあるが, どの層で達成されているかなどを見る.
61本目の論文: Gauge Equivariant Convolutional Networks and the Icosahedral CNN
wataokaの日本語訳「ゲージ同変な畳み込みネットと20面体CNN」
- 種類: general
- 学会: ICML2019
- 日付: 20190211
- URL: https://arxiv.org/abs/1902.04615
概要
対象変換に対する等変量の原理により, 理論的根拠のあるニューラルネットの設計ができる. (equivariant networks). この論文では, この原理が大域的な対称性を超えて, 局所的なゲージ変換にまで拡張できることを示した.
手法
球体の合理的な近似でらう正20面体の表面上で定義された信号に対してゲージ等変なCNNを実装した. 単一のconv2d呼び出しを用いてゲージ等変畳み込みを実装することができ, 球形CNNに変わる非常にスケーラブルな手段となる.
結果
全方位画像や地球規模の気候パターンのセグメンテーションタスクにおいて従来手法を大きく上回った.
62本目の論文: Invertible Conditional GANs for image editing
wataokaの日本語訳「画像編集のための可逆な条件付きGAN」
- 種類: GAN
- 学会: NeurIPS2016
- 日付: 20161119
- URL: https://arxiv.org/abs/1611.06355
概要
cGANで条件付け生成はできたが, 実画像に対する画像編集はできない. IcGANsはencoderを利用することでそれを可能にした.
手法
属性付き顔画像データセットを用いて, G(z, y), zを推論するE_z, yを推論するE_yを学習させる. 学習が終わったら, 推論されたyを編集することで画像編集ができる.
63本目の論文: Detecting Bias with Generative Counterfactual Face Attribute Augmentation
wataokaの日本語訳「反実な顔属性の生成増強によるバイアスの検知」
- 種類: fairness, gan,counterfactual
- 学会: ICML2019 Workshop
- 日付: 20190618
- URL: https://arxiv.org/abs/1906.06439
概要
InterFaceGANの前進で, ほとんど同じ. 顔属性の編集を行う研究. InterFaceGANのように条件付き編集には言及してないが, Counterfactual imageの考え方はInterFaceGANに無い部分.
手法
InterFaceGANと同じ手法で属性をいじり, 生成された画像をcounterfactual imageだと見なす. 元画像と反実画像を分類器に推論させることで, counterfactual fairnessを測定できる.
結果
属性ベクトルで画像操作した際に, どれほど予測結果が変化するかを, 属性毎に調べた.
wataokaのコメント
他の手法との精度の比較が全くない.
64本目の論文: Counterfactual Visual Explanations
wataokaの日本語訳「反実的視覚説明」
- 種類: counterfactual
- 学会: PMLR2019
- URL: https://arxiv.org/abs/1904.07451
概要
画像の一部を変化させると別クラスに分類されるという可視化を行うことによって画像の分類根拠を説明するという試み.
手法
分類器を前半fと後半gにわけ, 2つのサンプルそれぞれからfで抽出される特徴マップのどこを入れ替えたら別クラスに分類されるのかという情報からAttentionで可視化する.
結果
野鳥分類を用いた.
65本目の論文: MemNet: A persistent Memory Network for Image Recognition
wataokaの日本語訳「MemNet: 画像認識のための永続的メモリーネットワーク」
- 種類: general
- 学会: ICCV2017
- 日付: 20170807
- URL: https://arxiv.org/abs/1708.02209
概要
MemNetを提案. 再起的ユニットとゲートユニットからなるメモリブロックを持ち, 前のメモリブロックからの出力と表現を連結してゲートユニットにろくり, ゲートユニットは前の状態をどれだけ保存し, 現在の状態をどれだけ保存するのかを決定する.
結果
超解像などに適用した.
66本目の論文: Examining CNN Representations With Respect To Dataset Bias
wataokaの日本語訳「データセットバイアスに関するCNN表現の検証」
- 種類: general
- 学会: AAAI2018
- 日付: 20171029
- URL: https://arxiv.org/abs/1710.10577
概要
CNNが共起パターンを学習し, ある属性の有無をその属性と関係のない部分から判断していることを発見する手法を提案. (例) 顔画像においてリップをしているかどうかを判断するためにアイシャドウをみている.
手法
属性間の関係性をデータから学習し, 真の関係と矛盾するなら表現に問題ありとする.
wataokaのコメント
真の関係にバイアスがないことを前提としたequal opportunity的な手法.
67本目の論文: README: REpresentation learning by fairness-Aware Disentangling MEthod
wataokaの日本語訳「README: 公平なdisentangleによる表現学習」
- 種類: fairness
- 日付: 20200707
- URL: https://arxiv.org/abs/2007.03775
概要
protected attribute, target attribute(分類ラベル), mutual attributeそれぞれに関する情報に別れるように潜在変数を埋め込むFD-VAEを提案.
68本目の論文: Fader Networks: Manipulating Images by Sliding Attributes
wataokaの日本語訳「Fader Networks: 属性スライドによる画像編集」
- 種類: image manipulation
- 学会: NeurIPS2017
- 日付: 20170601
- URL: https://arxiv.org/abs/1706.00409
概要
画像の属性変換をするための手法Fader Networksを提案.
手法
xからEncoderでE(x)に埋め込み, そのE(x)から属性aをDiscriminatorに予測させる. 敵対的学習により, E(x)から属性aの情報を消す. 属性aとE(x)を入力とするDecoderで画像D(E(x), a)を生成する. 結果, 属性aをいじることで属性aを編集した画像を生成することができる.
wataokaのコメント
近年の画像編集のほぼ始祖
69本目の論文: AttGAN: Facial Attribute Editing by Only Changing What You Want
wataokaの日本語訳「AttGAN: 変えたいものだけ変えられる顔属性編集」
- 種類: image manipulation, gan
- 学会: IEEE TIP2018
- 日付: 20171129
- URL: https://arxiv.org/abs/1711.10678
概要
タイトルの通り, 変えたい属性のみを編集した顔画像を生成できるGANを提案.
手法
入力データをzに埋める. zとある属性の真の値aをGに入力し, 生成した画像と元画像で再構成誤差. また, zからその属性の編集値bをGに入力し, 生成した画像をDとCに入力. Dはreal or fakeを見抜く. Cはその属性の値を分類. GはDには見抜かれないように学習し, Cには分類されるように学習する.
wataokaのコメント
code: https://github.com/LynnHo/AttGAN-Tensorflow
70本目の論文: Inverting The Generator Of A Generative Adversarial Network
wataokaの日本語訳「GANのGeneratorの逆変換」
- 種類: GAN inversion
- 学会: NIPS2016 Workshot
- 日付: 20161117
- URL: https://arxiv.org/abs/1611.05644
概要
- xlog{G(z)} - (1-x)log{1-G(z)}を損失関数として, xに対する最適なzを勾配法で探索する.
71本目の論文: Invertibility of Convolutional Generative Networks from Partial Measurements
wataokaの日本語訳「部分測定からの畳み込み生成ネットの逆変換」
- 種類: GAN inversion
- 学会: NIPS2018
- 日付: 20181202
- URL: https://papers.nips.cc/paper/8171-invertibility-of-convolutional-generative-networks-from-partial-measurements
概要
CNNのinverseは非常に非凸で, 困難な計算である. この研究は2層の畳み込み生成ネットと単純な勾配降下を用いて, 潜在ベクトルを出力から効率的に推論できることを厳密に証明した. この理論敵発見は低次元潜在空間から高次元の画像空間への写像は単射であることを示唆している.
wataokaのコメント
code: https://github.com/fangchangma/invert-generative-networks
72本目の論文: Disentangled Inference for GANs with Latently Invertible Autoencoder
wataokaの日本語訳「潜在的可逆オートエンコーダを用いたGANのためのdisentangledな推論」
- 種類: GAN inversion
- 学会: ICLR2020
- 日付: 20190619
- URL: https://arxiv.org/abs/1906.08090
概要
GAN inversion手法のLIA(Latently invertible autoencoder)を提案.
手法
x→[f]→y→[φ]→z→[φ^-1]→y→[g]→x~ (y:中間潜在表現, z:潜在表現, φ:可逆関数) stage1: Dを騙すようにφとgを訓練. stage2: φを取り外し, Dを騙す訓練と特徴量距離を最小化する訓練をする.
wataokaのコメント
code: https://github.com/genforce/lia
idinvertとinterfaceganと同じgithubグループ
73本目の論文: Image Processing Using Multi-Code GAN Prior
wataokaの日本語訳「複数のGANの事前コード(z)を用いた画像処理」
- 種類: GAN inversion
- 学会: CVPR2020
- 日付: 20201216
- URL: https://arxiv.org/abs/1912.07116v2
概要
既存手法は単一のzからinvertしようとしていたが限界がある. 複数のzからinvertする手法mGANpriorを提案した.
手法
複数のzから複数の中間表現を得る. 中間表現のチャネルに対してベクトルαで重みづけをして, 全ての中間表現を足し合わせる. その結果得られた画像を元画像に近づけるようにz達とα達を最適化する. objectはピクセルのL2と特徴量のL1.
結果
単一のzを最適化するorEncoderを用いて単一のzを推論する手法よりも定性的にも定量的にも良い精度になり, 単一zではやりにくかった色付けタスクや高解像タスクなどもできるようになった.
wataokaのコメント
code: https://github.com/genforce/mganprior
74本目の論文: StyleFlow: Attribute-conditioned Exploration of StyleGAN-Generated Images using Conditinoal Continuous Normalizing Flows
wataokaの日本語訳「StyleFlow: 条件付き連続Flowを用いたStyle-GANの生成画像の属性条件付け」
- 種類: image manipulation/ Flow
- 日付: 20200806
- URL: https://arxiv.org/abs/2008.02401
概要
StyleFlowを提案. 属性条件付けsampleと属性編集のタスクをシンプルかつ効率的かつロバストに行える.
手法
zとw(全ての重みWのサブスペース)をflowで繋ぐ. flowは属性aで条件付けできるようにする. そして, 画像からaを分類し, aで条件付けて, 初期値w0からz0を生成, z0から編集したatで条件付けてwtを生成, wtを用いてStyleGANで編集画像を生成.
wataokaのコメント
website: https://rameenabdal.github.io/StyleFlow/
75本目の論文: A Linear Non-Gaussian Acyclic Model for Causal Discovery
wataokaの日本語訳「因果探索のための線形非ガウス非巡回モデル」
- 種類: causal inference
- 学会: Journal of Machine Learning Research 2006
- 日付: 20061006
- URL: https://www.cs.helsinki.fi/group/neuroinf/lingam/JMLR06.pdf
概要
LiNGAMを提案
76本目の論文: Bayesian estimation of causal direction in acyclic structual equation models with individual-specific confounder variables and non-Gaussian distributions.
wataokaの日本語訳「個別交絡因子と非ガウスを用いた非巡回構造方程式における因果方向のベイズ推定」
- 種類: causal inference
- 学会: Journal of Machine Learning Rearch 2014
- 日付: 20130000
- URL: https://jmlr.org/papers/volume15/shimizu14a/shimizu14a.pdf
概要
BMLiNGAMを提案.
wataokaのコメント
BMLiNGAM, python code, 混合モデルベース (未観測共通原因を明示的にモデルに組み込まない)
77本目の論文: Causal discovery of linear non-Gaussian acyclic models in the presence of latent confounders
wataokaの日本語訳「潜在交絡因子のある線形非ガウス非巡回モデルの因果探索」
- 種類: causal inference
- 学会: AISTATS2020
- 日付: 20200113
- URL: https://arxiv.org/abs/2001.04197
概要
RCDを提案.
手法
RCDは少数の観測変数間の因果方向の推論を繰り返し, その関係がlatent confounderの影響を受けているかを判断する. 最終的に因果グラフを作成し, 双方向矢印はlatent confounderをもつ変数ペアを示し, 有効矢印はlatent confounderに影響を受けない変数ペアの因果を表す.
wataokaのコメント
RCD
78本目の論文: Causation, Prediction, and Search
wataokaの日本語訳「因果関係, 予測, 探索」
- 種類: cuasal inference
- 学会: Springer
- 日付: 19930000
- URL: https://books.google.com/books/about/Causation_Prediction_and_Search.html?id=oUjxBwAAQBAJ&printsec=frontcover&source=kp_read_button&hl=en#v=onepage&q&f=false
概要
FCIを提案
(Fast Causal Inference)
手法
adjacency phaseとorientation phaseの2つのフェーズがある. adjacency phaseは完全無効グラフから始まり, 条件付けして独立したらエッジを削除する. orientation phaseでは, 条件付けした変数セットを用いてエッジに方向をつける.
79本目の論文: Learning high-dimensional directed acyclic graphs with latent and selection variables
wataokaの日本語訳「潜在選択変数のある高次元の有向非巡回グラフの学習」
- 種類: causal inference
- 日付: 20110429
- URL: https://arxiv.org/abs/1104.5617
概要
RFCIを提案.
(Really Fast Causal Inference)
wataokaのコメント
FCIの派生系
80本目の論文: A Hybrid Causal Search Algorithm for Latent Variable Models
wataokaの日本語訳「潜在変数モデルのためのハイブリッド因果探索アルゴリズム」
- 種類: causal inference
- 学会: JMLR2016 workshop
- 日付: 20160000
- URL: http://proceedings.mlr.press/v52/ogarrio16.pdf
概要
GFCIを提案.
(Greedy Fast Causal Inference)
wataokaのコメント
FCIの派生系
81本目の論文: Independent Component Analysis
wataokaの日本語訳「独立成分分析」
- 種類: ICA
- 学会: Wiley Interscience 2001
- 日付: 19970000
- URL: https://www.cs.helsinki.fi/u/ahyvarin/papers/bookfinal_ICA.pdf
概要
Hyvarinenの最初のICAの本
手法
様々な分布を足し合わせばガウスに近づくことから, 逆に非ガウスにすることを目的とする. 非ガウス性を測る関数(例:tanh)を最大化するように重みWを探索する. (先にXに対して白色化を行なっておくことも重要)
wataokaのコメント
overcomplete ICAにも言及しているが, 簡単な尤度最大化手法とかしか書かれていない.
82本目の論文: Independent Factor Analysis
wataokaの日本語訳「独立要素解析」
- 種類: ICA
- 学会: Neural Computation 1999
- 日付: 19990000
- URL: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.49.62&rep=rep1&type=pdf
概要
IFAを提案.
(Independent Factor Analysis)
LvLiNGAMが用いたovercomplete ICA手法.
手法
独立成分の分布に混合ガウスを仮定し, EMアルゴリズムで尤度最大化.
83本目の論文: Mean-Field Approaches to Independent Component Analysis
wataokaの日本語訳「ICAのためのMean-Fieldアプローチ」
- 種類: ICA
- 学会: Neurla Computation 2002
- 日付: 20020500
- URL: https://www.researchgate.net/publication/11428922_Mean-Field_Approaches_to_Independent_Component_Analysis
概要
MFICAを提案.
(Mean-Field Approaches to ICA)
wataokaのコメント
LFOICAの比較手法
84本目の論文: ICA with Reconstruction Cost for Efficient Overcomplete Feature Learning
wataokaの日本語訳「効率的な過完備特徴学習のための再構成コスト付きICA」
- 種類: ICA
- 学会: NeurIPS2011
- 日付: 20111212
- URL: http://www.robotics.stanford.edu/~ang/papers/nips11-ICAReconstructionCost.pdf
概要
RICAを提案.
(Reconstruction ICA)
wataokaのコメント
LFOICAの比較手法
85本目の論文: Discovering Temporal Causal Relations from Subsampled Data
wataokaの日本語訳「サブサンプルデータからの時間的因果関係の発見」
- 種類: ICA
- 学会: ICML2015
- 日付: 20150000
- URL: https://mingming-gong.github.io/papers/ICML_SUBSAMPLE.pdf
概要
NG-EMとNG-MFを提案.
(Non-Gaussian EMとNon-Gaussian Mean-Field)
wataokaのコメント
LFOICAの比較手法
86本目の論文: overcomplete Independent Component Analysis via SDP
wataokaの日本語訳「SDPを用いた過完備ICA」
- 種類: ICA
- 学会: AISTATS2019
- 日付: 20190124
- URL: https://arxiv.org/abs/1901.08334
概要
overcomplete ICAを半正定値計画問題に落とし込み, それをprojected accelerated gradient descent methodで解いた.
wataokaのコメント
matlab code: https://github.com/anastasia-podosinnikova/oica
87本目の論文: From Softmax to Sparsemax: A Sparse Model of Attention and Multi-Label Classification
wataokaの日本語訳「SoftmaxからSparsemaxへ: attentionのスパースモデルとマルチラベル分類」
- 種類: general
- 学会: ICML2016
- 日付: 201602205
- URL: https://arxiv.org/abs/1602.02068
概要
softmaxに変わる出力層の関数sparsemaxを提案. アイディアとしては, 小さい値は0に, 大きい値はキープ, そしてもちろん微分可能.
手法
1より大きければ1, -1より小さければ0, 間の値は両端を繋ぐような線形の関数.
結果
[0.1, 1.1, 0.2, 0.3]とかをsoftmaxに入力すると,
[0.165, 0.45 , 0.183, 0.202]
sparsemaxに入力すると,
[0. , 0.9, 0. , 0.1]
88本目の論文: Density estimation using Real NVP
wataokaの日本語訳「Real NVPを用いた密度推定」
- 種類: Flow
- 学会: ICLR2017
- 日付: 20160327
- URL: https://arxiv.org/abs/1605.08803
概要
Flowの一種のRealNVP(real-valued non-valume presering)を提案. NICEでは, detが1であるので, スケーリングができない. そこで スケールング関数sを含んだアフィンカップリングを用いた.
手法
次元分割し, 一方をxとし, もう一方をx'とした時, y = x, y' = x'⊙exp(s(x))+t(x')とした. これで可逆かつスケーリング可能な変換となる.
結果
まだ高画質画像には弱そう
89本目の論文: Glow: Generative Flow with Invertible 1x1 Convolutions
wataokaの日本語訳「Glow: 1x1の可逆な畳み込みを用いた生成Flow」
- 種類: Flow
- 学会: NeurIPS2018
- 日付: 20180709
- URL: https://arxiv.org/abs/1807.03039
概要
Flowの一種のGlowを提案. RealNVPに1x1の畳み込みとactnormを加えたFLow. RealNVPに比べ, 高画質画像の生成に成功した.
手法
ActNorm(Activation Normalization): channel-wiseなNormalization. 1x1の畳み込み: 入力と出力のwidth, heightはかえず, channel方向に畳み込む. なので正確には1x1xcのカーネルで畳み込む. 逆変換時に計算するlogdetはLU分解などを用いて計算量をO(c)にできる.
wataokaのコメント
code: https://github.com/openai/glow,
日本語記事: https://qiita.com/exp/items/4f562ec788f2ac5241dc#3-%E7%94%9F%E6%88%90%E7%9A%84flow%E3%81%AE%E6%8F%90%E6%A1%88
90本目の論文: Learning Non-Discriminatory Predictors
wataokaの日本語訳「差別のない予測器の学習」
- 種類: fairness
- URL: https://arxiv.org/abs/1702.06081
概要
Group Fairnessの学習理論. EOに関する汎化誤差を評価した.
wataokaのコメント
日本語記事: https://www.slideshare.net/kazutofukuchi/ai-197863181
91本目の論文: Training Well-Generalizing Classifiers for Fairness Metrics and Other Data-Dependent Constraints
wataokaの日本語訳「公平性指標とデータ依存制約のための一般化分類器の学習」
- 種類: fairness
- URL: https://arxiv.org/abs/1807.00028
概要
Group Fairnessの学習理論. 上の論文を一般化. 分類誤差を目的関数, 公平性を製薬として最適化したい問題において, 汎化誤差を評価した.
wataokaのコメント
日本語記事: https://www.slideshare.net/kazutofukuchi/ai-197863181
92本目の論文: Probably Approximately Metric-Fair Learning
wataokaの日本語訳「確率近似的メトリック公平学習」
- 種類: fairness
- URL: https://arxiv.org/abs/1803.03242
概要
Individual Fairnessの学習理論.
wataokaのコメント
日本語記事: https://www.slideshare.net/kazutofukuchi/ai-197863181
93本目の論文: Why Normalizing Flows Fail to Detect Out-of-Distribution Data
wataokaの日本語訳「なぜFlowは分布外データの検知に失敗するのか」
- 種類: flow
- URL: https://arxiv.org/abs/2006.08545
概要
Normalizing Flowがout of distributionなデータに弱い(帰納バイアスがかかっている)ことを示した.
wataokaのコメント
code: https://github.com/PolinaKirichenko/flows_ood
94本目の論文: Achieving Causal Fairness in Machine Learning
wataokaの日本語訳「機械学習における因果的公平性を達成すること」
概要
Causal Fairness全般のことが書かれている. Counterfactual Fairness→Path-specific Counterfactual Fairness→複雑さとバウンドの流れが書かれていて読み応えがある.
wataokaのコメント
Counterfactual Fairnessの汎化バウンドに関する理論的な論文を書いた人の博士論文
95本目の論文: A causal framework for discovering and removing direct and indirect discrimination
wataokaの日本語訳「直接/間接差別を発見し, 取り除くための因果フレームワーク」
- 種類: fairness
- 学会: IJICAI2017
- 日付: 20161122
- URL: https://arxiv.org/abs/1611.07509
概要
直接/間接差別を因果モデルにおけるpath-specific effectであるとした. それを発見し, 取り除くアルゴリズムを提案した. 取り除いたデータを用いて予測モデルを構築すると差別しなくなる.
96本目の論文: Counterfactual Data Augmentation using Locally Factored Dynamics
wataokaの日本語訳「局所的に分解されたダイナミクスを用いた反実仮想データ増強」
- 種類: counterfactual
- 学会: NeurIPS2020
- 日付: 20200706
- URL: https://arxiv.org/abs/2007.02863
概要
RLなどにおいて多くの動作プロセスはサブプロセス同士が繋がっているのに, 非常にスパースなので独立的に考えられがち. そこで, この論文では, LCMsとしてダイナミクスを定式化し, データ増強アルゴリズムCoDAを提案した.
wataokaのコメント
code: https://github.com/spitis/mrl
97本目の論文: Deep Structural Causal Models for Tractable Counterfactual Inference
wataokaの日本語訳「反実仮想推論のためのディープ階層的因果モデル」
- 種類: counterfactual
- 学会: NeurIPS2020
- 日付: 20200611
- URL: https://arxiv.org/abs/2006.06485
98本目の論文: CelebA-Spoof: Large-Scale Face Anti-Spoofing Dataset with Rich Annotations
wataokaの日本語訳「CelebA-Spoof: リッチなアノテーション付きなりすまし防止大規模顔画像データセット」
- 種類: general
- 学会: ECCV2020 Workshop
- 日付: 20200724
- URL: https://arxiv.org/abs/2007.12342
概要
CelebAを作成した香港大の新しいデータセット. 62万枚という大規模な顔画像データで, 多様な場所での写真やリッチなアノテーションと謳っている.
wataokaのコメント
data: https://github.com/Davidzhangyuanhan/CelebA-Spoof
99本目の論文: Adversarial Vertex Mixup: Toward Better Adversarially Robust Generalization
wataokaの日本語訳「敵対的頂点Mixup: より良い敵対的に頑健な生成に向けて」
- 種類: adversarial attack
- 学会: CVPR2020
- 日付: 20200305
- URL: https://arxiv.org/abs/2003.02484v3
概要
ATは最適なポイントを通り過ぎがち.(やりすぎ) これをAFO(Adversarial Feature Overfitting)とした. AFOを防ぐために, AVmixupというソフトラベル化されたデータ増強手法を提案した.
100本目の論文: Mode Seeking Generative Adversarial Networks for Diverse Image Synthesis
wataokaの日本語訳「多様性のある画像生成のためのモードシーキングGAN」
- 種類: GAN
- 学会: CVPR2019
- 日付: 20190313
- URL: https://arxiv.org/abs/1903.05628v6
概要
zを変化させても画像が変化しないことをmode collapseといい, 逆にうまく反映できていることをmode seekingという. mode seekingするためのGANであるMSGANを提案した.
手法
mode collapseが起きている時, 異常に(画像空間での距離)/(潜在空間での距離)という比率が大きくなることに注目し, その比率のマイナスを損失関数に入れる正則化を行った.
結果
画像の品質を下げずに多様性を向上することに成功した.
wataokaのコメント
code: https://github.com/HelenMao/MSGAN
終わりに
この記事をご覧くださったあなたへ
一文字でも読んでいただき誠にありがとうございました. あなたにとって2020年はどのような1年だったでしょうか. 私は来年から社会人になりますので, 言わば学生最後の1年間を過ごしました. もしかすると, もう二度とアカデミアな機関で自分の好奇心のもと研究を行うことができないかもしれないと思い, 悔いの残らないように毎日を過ごしました. 指導教官の方とアイディアを出し合い盛り上がれる最高に楽しい時間も経験しましたし, 結果が出せない苦しい数ヶ月間も経験しました. そのような日々の中で私は学べる楽しさを一度も忘れることはありませんでした. 世界中の研究者が長い間考え抜いた研究を数時間で脳にインストールできるこの世の中は僕にとって最高の遊び場のようでした. 上記の通りたくさんの論文を読み, たくさんのコードを書きました. そんな中で私はこう思います. 「2020年もきっと人類は前に進んだ.」 地球上をパンデミックが襲おうとも人類は前を向いていると確信しています. 来たる2021年も私は世界中の皆さんと共に未来を作りたいと思っています. 来年もどうぞよろしくお願いいたします. それでは, 良いお年を.
綿岡晃輝より