前書き
論文読むならQiitaを書こう。
そんな善良な精神の元、当記事を書きました。要約をしていこうかと思って書いたのですがほとんど和訳になってしまいましたので、この記事を読むとほとんど元論文を読んだことになります。
元論文へのリンク(Sequence to Sequence Learning with Neural Networks)
概要

言わずとしれたSeq2Seqってやつ。
RNNを用いたEncoderDecoderモデル。詳解ディープラーニングでは第6章で紹介されている。はず。このモデルをうまく利用すると、チャットロボットを作ったり自動翻訳ができる。
書いていることはほとんど詳解ディープラーニングの第5章と同じ。先に本を読んでいれば論文を読む良い練習になるし、読んでいなければ時間はかかるがRNNの勉強も一気にできる。
Abstract
DNN(ディープニューラルネットワーク)は素晴らしいモデルだが、流れのあるデータは処理をしにくい。流れとは時間に依存していて刻一刻と変化していくことでシーケンス(Sequence)と呼ぶ。この論文ではそのような流れのあるデータを処理するモデル, Sequence learningを示す。
LSTM(Long Short-Term Memory) という手法を使用し、最終的に英語からフランス語への翻訳を試みる。使用するデータセットはWMT-14で翻訳の精度はBLEUで34.8に達する。WMT-14とはmnistみたいなもので、BLEUとはどれだけ翻訳できているかを示すもので値域は1~100で高い方が精度が良い。定義では値域は0~1であるが百分率で用いられることが多い。
BLERの論文
「BLER: a Method for Automatic Evaluation of Machine Translation」
http://www.aclweb.org/anthology/P02-1040.pdf
比較のために、SMT(Statistical Machine Translation)という手法ではBLEUは33.3だった。さらに、SMTによって前処理を施したLSTMを使用したところBLEUは36.5を記録した。最終的に、入力の際に語順を逆にすると精度が向上することも発見した。
1 Introduction
DNNはパワフルで並列計算もしっかりやってのける。だから、従来の統計処理ができて膨大なデータにも対応できる。誤差逆伝播法がすぐに最適なパラメータを発見してくれるからだ。
DNNは入力をエンコードした特定された次元のベクトルを出力することしかできなかった。深刻な問題であるのが先に長さがわからない入力を処理したり出力を生成したすることが難しいことだ。例えば音声認識や質問に答えることだ。この論文ではLSTMがそのような問題, つまりSequence to Sequenceを解決できることを示す。アイディアはこうだ、まず1つのLSTMが入力シーケンスを読み取る。それを一旦固定された次元のベクトルに変形する。そして別のLSTMが出力シーケンスを生成する。二つ目のLSTMはRNN(Recurrent nerral network)モデルである。RNNとは時系列データを処理するためのモデルで、例えば言語を生成する時は「Thisの次はisが来ることが多い」などの時間に依存した関係性があるため、RNNのようなモデルを使用する。
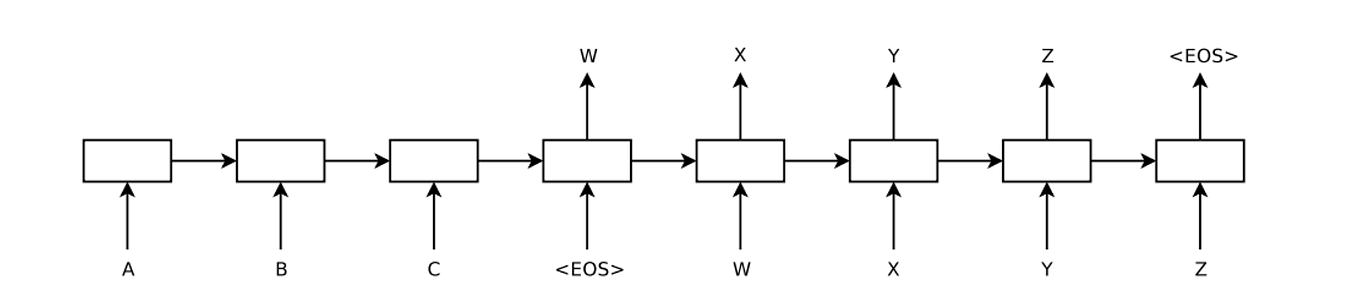
2 The model
RNN(Recurrent Neural Network)はシーケンス向けのニューラルネットワークで、入力されたシーケンスを下の式を繰り返すことでシーケンスで出力する。
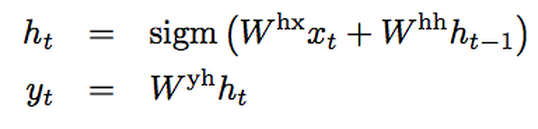
RNNでは入力・出力がどんなならびにあったとしても簡単にシーケンスからシーケンスへと計算することができるが、入力と出力の長さが決まっていない問題はやはり対処が難しい。一般的なRNNでの対処法は入力シーケンスを特定のベクトルに表現し直し、ベクトルで出力するという方法だが、この方法では長い時間に依存した情報は失われてしまう。そこでLSTM(Long Short-Term Memory)という方法を導入すれば長い時系列データにも対処することができる。
LSTMの目標は条件付き確率を求めることである。(あるシーケンスが入力された際の、出力されるシーケンスの確立)ここで、入力シーケンスと出力シーケンスの長さは異なる場合が多いことには注意しておきたい。
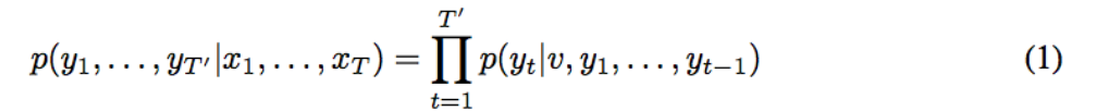
ここでのy_tはボキャブラリの中にある全ワードに対して分布される。また、我々はシーケンスの終わりを表現するためにEnd Of Sequence の略でという記号を使うことも気をつけてほしい。初めの表ではLSTMがA, B, C, を計算し、そしてW, X, Y, Z, の剥離つを計算していくところを表現している。
我々の使用する実際のLSTMは表にあるものとは3つの重要な違いがある。それは、
1.入力層と出力層を少し異なる構造を持たせる。(理由)勾配消失を防ぐため
2.4層のLSTMを使用すること。(理由)深いSLTMの方が性能が良いため
3.入力の語順を反転させること。(理由)a, b, c → α, β, γとしたいときに、c, b, aの順で入力した方が、aとα, bとβ, cとγの近接関係が統一的になり、性能が向上すると知られているから。
3 Experimants
我々は二つの方法でWMT'14 English to French MT taskを解く。一つはSMT(Support Vector Machine)システム。そしてもう一つはSMTベースのn-best listsだ。n-best listとは、解析した時にスコアが良い順に1-best, 2-best, ・・・としたリスト。そしてそれらの方法でのaccuracy(確からしさ)を記録し、サンプル翻訳を記載し、結果を可視化する。
3.1 Dataset details
我々はWMT'14 English to Frenchのデータセットを使用する。データセットのうち1200万の文章、3億4800万単語のフランス語と3億400万単語の英語を使用してモデルをトレーニングする。このデータセットを使用した理由は1000-bestlistsなどが一緒に提供されているからだ。
典型的なニューラルネットワークはそれぞれの単語をベクトルで表現するため、我々も限られたボキャブラリを使用する。具体的には、ソース言語(英語)では16万の頻出単語を、そしてターゲット言語(フランス語)では8万の頻出単語を使用する。そのごキャブラリにない言葉は"UNK"(unknown)とする。
3.2 Decoding and Rescoring
ソース言語とターゲット言語のペアを用いてLSTMを学習させる。その方法は下の式を最大化させることにある。
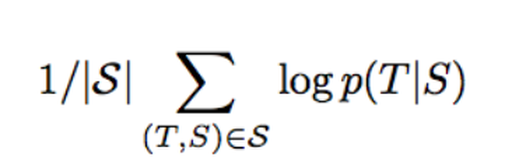
ここでのSはソース言語の文章で、Tは正しい訳のこと。また、シグマの右下にあるSはトレーニング用の文章セットである。計算が完了すればすぐにそのうちの最大値を見つける。

この時、少ない候補を維持する方法, left-to-right beam serch decoder を使用する。ビームサーチとは、探索アルゴリズムの一種で条件分岐の際、確率が閾値より高い分岐のみ探索することでメモリの消費を抑える。それぞれのステップごとにbeam内の候補を拡張し続ける。これをする事で候補の数が肥大してしまう。なので、確率のログに従って残すものは残し、他の候補は全て削除する。そして、が来た瞬間他の候補は削除し、文章を完了させる。興味深いことに、beamのサイズが1の時でさえ良い成績であり、beamのサイズが2の時には最も成績が良い。(後述のTable[1]参照)
また1000-bestで整理したLSTMを使用すると、平均スコアもLSTMのスコアも上回った。
3.3 Reversing the Source Sentences
LSTMはソース言語を逆転させた時に性能が向上することを発見した。(ただし、訳語は反転させない) これをする事でperplexityは5.0から4.7に減少し、BLEUは25.9から30.6に上昇した。
この現象は完璧には解明されていないが、データセットに対する短い期間依存の導入によるものだと考えられている。一般的な手段でソース言語とターゲット言語を連結させると、ソースの単語とターゲットの単語同士が遠くなってしまう。結果として"minimal time lag"と呼ばれる問題が発生する。だが、語順を逆にする事で各単語間の平均距離が変化し、minimal time lagが解消される。このようにして誤差逆電晩報は短い時間で計算ができ、結果全体的な性能の向上に繋がる。
当初、入力文の語順を逆転させることは文の前半の性能は上がり、文の後半の性能は下がると思われていた。だが、結果は入力文の語順を逆転させることは普通より良い結果を産んだのだ。
3.4 Training details
4層で1000個のcell, 1000次元のword embeddingsのLSTMを使用した。word embeddingとは低次元なベクトルで単語の語義や統語的な情報を表現しているもの。最終的な詳細は以下。
・LSTMのパラメータの初期設定は-0.08~0.08の範囲で一様分布
・学習率0.7の確率的勾配効果法を使用し、5エポックの後から0.5エポックごとに学習率を半減させる。これを7.5エポック繰り返す。
・バッチ数は128
・LSTMは勾配消失問題を被りにくいが、勾配が無限に発散し得る。なので勾配の値が閾値を超えたならばそれをスケーリングし直すという制約を設ける。
・短い文章ばかりを選択し、長い文章はほとんどトレーニングに使わない。
3.5 Parallelization
C++で計算すると1秒間に約1700単語を計算した。これは我々の経験的には遅すぎる結果だ。なので8つのGPUマシンを使用する。それぞれのLSTMレイヤーは異なるGPUで計算され、次のGPUで活性化関数を計算する。四つのGPUはsoftmaxを並列処理する。つまり1000×20000の行列となる。結果、1秒間に6300単語を計算できるようになり、計算が完了するまで10日間かかった。
3.6 Experimental Results
翻訳精度を計測するためにBLUEを使用した。BLUEはmulti-bleu.plというプログラムを用いて計算する。そして我々わ37.0というスコアをマークした。この結果はTable1, 2に示した。この結果は初期値やミニバッチの順が異なる複数のLSTMのアンサンブルによって得られた結果である。この結果は最先端には優っていないものの、純粋なニューラルネットワークによる翻訳システムがSMTに優った初めてのケースです。
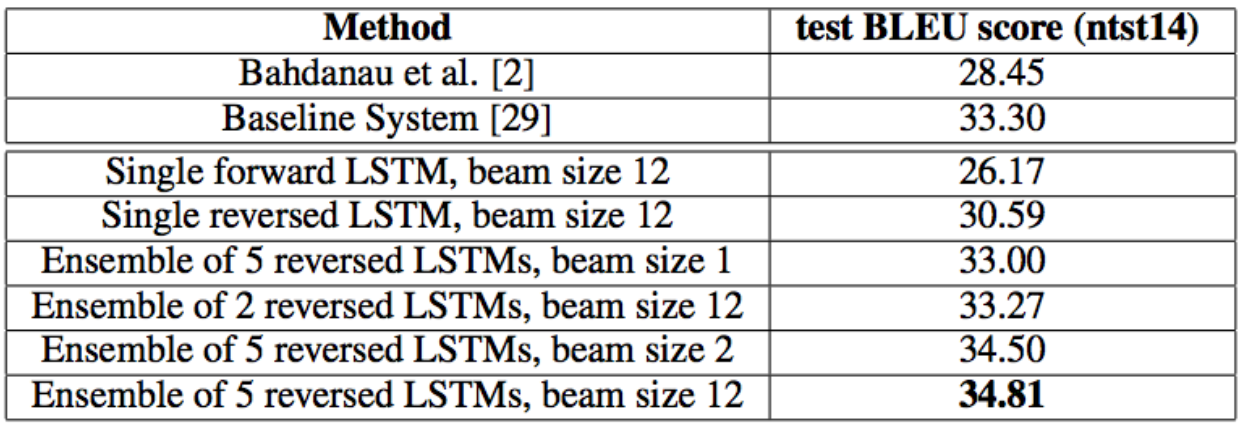
Table1 : WMT'14 English to Frenchテストに置けるLSTMのパフォーマンス
 Table2:WMT'14 English to Frenchテストに関してSMTを用いたニューラルネットワークで使用したメソッド
Table2:WMT'14 English to Frenchテストに関してSMTを用いたニューラルネットワークで使用したメソッド
LSTMは最先端に0.5にまで迫ったのだ。
3.7 Performance on long sentences
自分たちでも驚いたのだが、このLSTMは長い文章でもうまく機能する。その結果は下のfidure3で示す。Table3はいくつかの長い文章とそれに対応する翻訳を示した。
3.8 Model Analysis
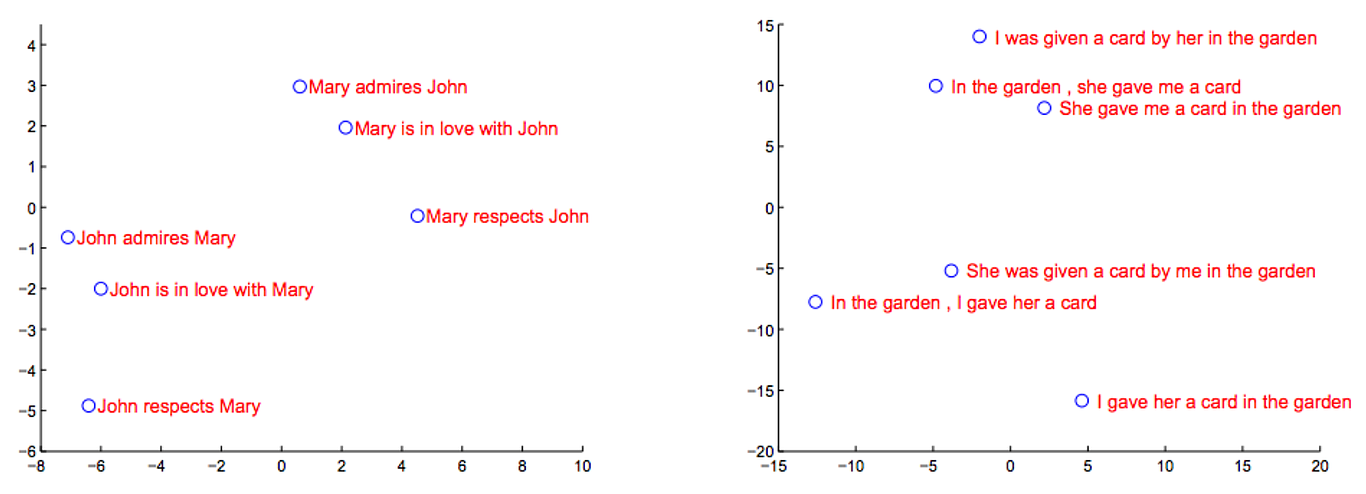
Figure 2: この図はLSTMの隠れ層の状態を2次元で主成分分析したもの。
我々のモデルにある興味深い特徴として言葉のシーケンスを固定された次元のベクトルに落とし込めるという特徴だ。能動態が受動態に置き換わっているものに関しては敏感ではないが、語順に関しては敏感であることが図2から見て取れる。

Table3: LSTMによって生成された翻訳と正しい翻訳の例
 Figure3: 左のグラフは文章の長さに関する精度。右のグラフは平均単語頻出ランクに基づいた精度
Figure3: 左のグラフは文章の長さに関する精度。右のグラフは平均単語頻出ランクに基づいた精度
4 Related work(関連する研究)
機械翻訳に関する試みは今まで多く存在する。今までのところ、最も簡単で効率的なRNN-Language Model(RNNLM)はMTベースのn-best listsによってスコアリングされた物ばかりである。
最近の研究ではソース言語に関する情報をNNLM(Nueral Network Language Model)に付加する方法が注目されている。例えばAuli et al.氏が入力文章のトピック情報を追加したことだ。
Kalchbrenner氏とBlunsom氏が行った研究もこれに近く、初めにベクトルの中に文章情報を付加させたが、シーケンスをベクトルにマップする際に畳み込みニューラルネットを使ったことから成績はあまりよくなかった。
5 Conclusion
この研究で我々はdeep LSTMが標準的なSMTより優ったことを示した。この成功は十分なデータさえあればLSTMが他のシーケンス学習問題に関してもうまく行くことを期待させるであろう。
語順を逆に入力することで性能が向上することには大変驚いた。問題をエンコードする大切さを痛感した。特に、語順を逆にしていない翻訳を標準RNNではトレーニングできていない。語順を逆にすればできると考えている。(これに関しては検証していないのだが)
また、LSTMが長い文章にも適切な翻訳を示せたことについても大変驚いた。初めは長い文章にはメモリ不足で失敗すると考えられていたし、他の研究でも長い文章にはいい結果が得られなかった。しかし、入力語順を逆にしたLSTMは難なく長い文章を翻訳したのだ。
最も重要なことは、簡単で, 直感的で, 比較的最適化されていない方法でSMTに勝ったことだ。つまり、この方法をより強化すればより良い翻訳が期待できる。結果、我々のアプローチはSequence to Sequence問題に良いアプローチだったのだ。
英単語
元論文を読む際に、僕が調べた英単語です。
assumption 仮定
aforementioned 前述の
sensible 感覚的
representation 表現(ここでは言語表現)
invariant 不変の
arbitrary 任意の
parallel computing 並列計算
quadratic 二次の
conventional 従来の
intricate 複雑な
backpropagation 誤差逆伝播法
a-priori 演繹的に、先験的に
likewise 同様に
pose 姿勢、形をとる、提案する
straightforward まっすぐな
temporal 時制の、時間的な
novel いい意味で新しい、奇抜な
assume 当然のことと思う
alignment 一直線にすること
iterate 反復
map (数学的な要素または集合を)確立する
non-monotonic 非線形
correspond 対応する
negligible わずかな
prozimity 近接
token ソースコードを解析する際にそれ以上細かい単位に分解できない文字列の並びの最小単位のこと
prefix 接頭辞
approximate 近似
state of art 最先端
concatenate 連結
perplexity 困惑、機械学習では予想性能の指標で少ない方が良い
substantially 実質的
confident 自信を持った
fairly かなり
embed 埋め込む
halve 半減させる
exceed 超える
threshold 敷居(ここでは閾値)
address (動詞で)本気取り掛かる、処理する
PCA Principal Component Analysisの略で、主成分分析のこと。
verify 検証する
degradation 分解