背景
ガウス過程回帰はデータ数nが増えると、n×nの行列計算が必要になりメモリや計算量を圧迫してしまうという欠点が存在する。
実務上どの程度影響するのかを把握するため、疑似データでモデル構築の時間を計測した結果をまとめる。
環境
Google Colab
実験コード
GPR.py
import time
import warnings
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import WhiteKernel, RBF, ConstantKernel, Matern, DotProduct
warnings.filterwarnings('ignore')
list_time = []
# 自身で検討したい範囲を設定
# なおデータ数・次元数のどちらかが1000を超えると深層学習並みに時間がかかったので今回は割愛
list_samplesize = [10, 20, 50, 70, 90, 100, 200, 300, 400, 500, 600]
list_dimension = [3, 5, 7, 9, 10, 15, 20, 50, 100, 120, 150, 200, 300]
for i in list_samplesize:
start = time.time()
list_tmp = []
for j in list_dimension:
# データの用意
data = pd.DataFrame(np.random.randn(i, j))
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
kernel = ConstantKernel() * RBF(np.ones(X.shape[1])) + WhiteKernel() + ConstantKernel() * DotProduct()
# モデル作成
start_ = time.time()
model = GaussianProcessRegressor(alpha=0, kernel=kernel)
model.fit(X, y)
end_ = time.time()
list_tmp.append(end_ - start_)
list_time.append(list_tmp)
end = time.time()
df_time = pd.DataFrame(list_time,
index=list_samplesize,
columns=list_dimension)
# 可視化
plt.plot(df_time, label=df_time.columns)
plt.legend(title='number of dimension')
plt.title('GPR calculation time \n when changing number of data and dimension')
plt.xlabel('number of data')
plt.ylabel('cal. time (sec.)')
plt.savefig('GPR_calculation_time.png')
plt.show()
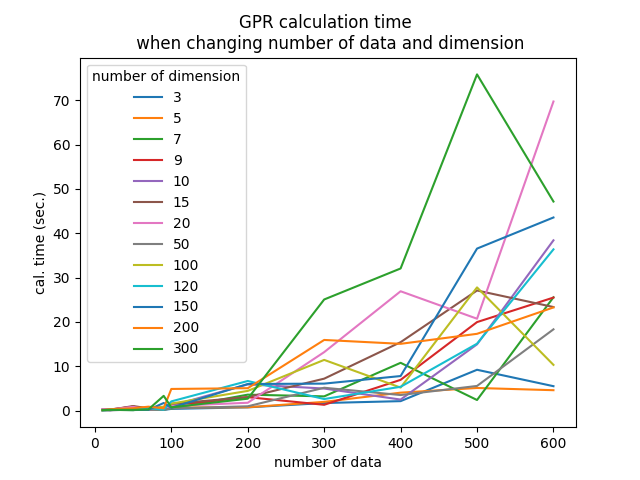
結果・所感
- 概ねデータ数と次元数が増えればモデル作成にかかる時間も伸びる傾向が見られた
- 200データ以下であれば、10秒以内に計算が終わる
- 300データ以上でもほぼ1分前後で計算できる
- 例えば600データ・300次元でモデル作成を行ったときのように、データ数・次元数が大きいにもかかわらずモデル作成時間が短い場合も存在
- scikit-learnの仕様?
- 今回はやらなかったが、よりデータ数・次元数が多い場合はGPyTorchというGPUで演算可能なライブラリを利用することも検討か
参考資料
- ガウス過程の基礎 https://www.jstage.jst.go.jp/article/isciesci/62/10/62_390/_pdf
- GPyTorch公式ドキュメント https://gpytorch.ai/