TL;DR
3つのデータセットでGoogleのAutoML TableとH2OのAutoMLを比較しました。
結果はこちら
前置き
AutoML Table
今年、構造化データに対する機械学習モデルを自動作成するAutoML Tableが公開されました。
ハッカソン形式のkaggleコンペティションでは、kaggle MasterやGrand Masterを抑えてAutoML Tableが2位に輝きました。また、長期のkaggleコンペティションでも高成績相当の記録を出したそうです。
(Google の AutoML が KaggleDays での表形式データのコンペで第 2 位に)
複数のブログ記事でもAutoML Tableの性能検証が行われ、Twitterでも話題を集めました。
AutoMLといえば、pythonのlibraryでもいくつかあったな~~と思い出したので、
AutoML Tableと比較してみようと思います。
AutoML Library
「python automl library」とググると以下のようなライブラリがヒットします。
automl
auto-sklearn
auto-keras
H2O
今回は、H2Oを用います。1
H2Oは強kagglerたちが開発しているAutoML Libraryで、
作成したモデルと精度がLeader Board形式で表示されます。
kagglerっぽい。
以下、
AutoML_GCPはGoogleのAutoML Table,
AutoML_H2OはH2OのAutoMLを指すことにします。
検証
検証方法
ブログ等に掲載されているAutoML Table適用したタスクをH2OのAutoMLでも行い、精度を比較します。
AutoML_GCPはお金がかかる(参考: AutoMLで破産しないように気をつけたいポイント)ので、
自分では使用せず他の方が記事に上げている精度を信じることにします。
AutoML_H2Oは、kaggle kernel上で8 hour学習させ、精度を確認します。2
以下の3つのデータセットで検証しました。
検証1. オンラインニュース人気度のデータセット(UCI ML Repository)
検証2. House Prices (kaggle)
検証3. Porto Segro (kaggle)
それでは、やっていきます。
検証1: オンラインニュースシェア数予測 3
参考記事はこちら
データ数: train 3万5000行, test 5000行 (holdout)
評価指標: RMSE (低いほど良い)
AutoML_H2Oの学習に用いたコードです。
import pandas as pd
import h2o
from h2o.automl import H2OAutoML
# data load
train = pd.read_csv("../input/ONP_train.csv")
# h2oで使えるように変換
htrain = h2o.H2OFrame(train)
# 予測対象変数 (y) と予測に用いる変数 (x)
x = htrain.columns
y = 'shares'
x.remove(y)
# AutoML, 学習時間8hour (max_runtime_secs=28800) と乱数シード以外はデフォルト
aml = H2OAutoML(seed=42, max_runtime_secs=28800)
aml.train(x=x, y=y, training_frame=htrain)
# 結果表示
lb = aml.leaderboard
lb.head(rows=lb.nrows) # 全ての結果
作成したモデルのLeader Boardが以下のように表示されます。
Stacking のアンサンブルモデルやXGBが良いらしいです。
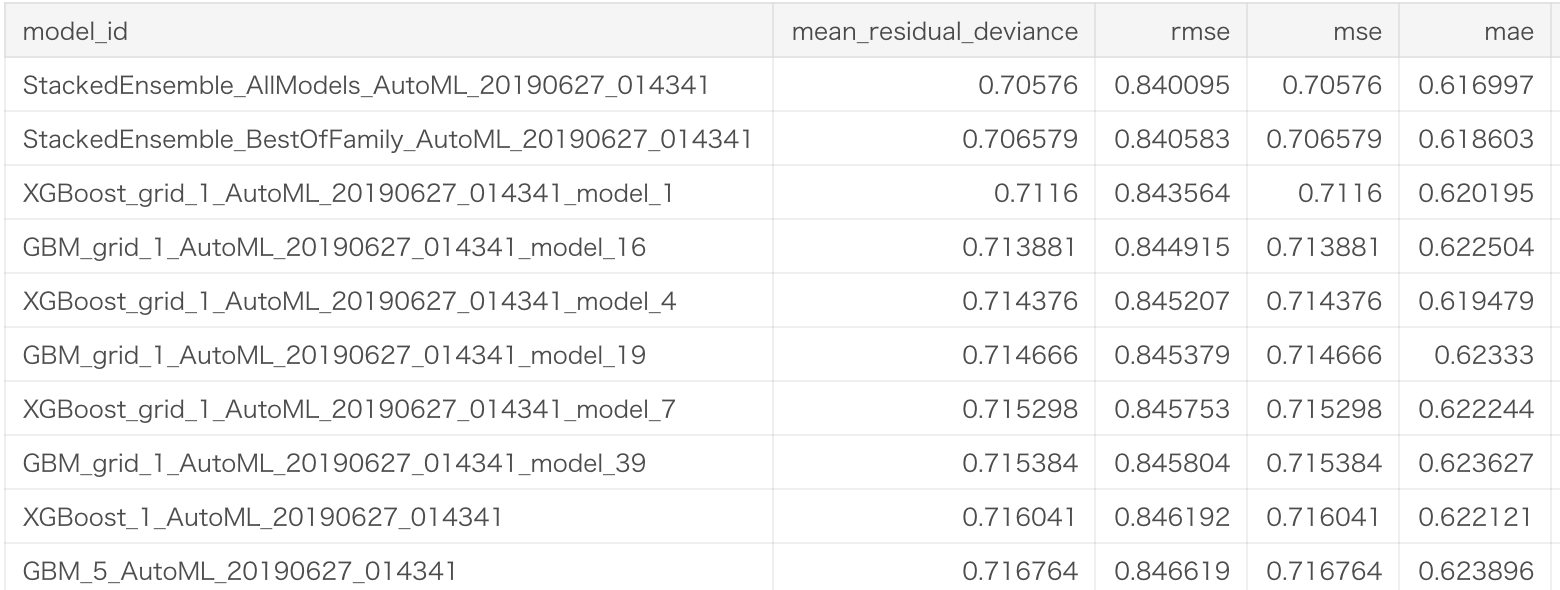
詳細はこちらのkaggle kernelにあります。
結果
AutoML_GCP: 0.86349
AutoML_H2O: 0.85903
→ H2Oの勝ち
検証2: 住宅価格の予測
参考記事はこちら
データ数: train 1460行, test 1459行
評価指標: RMSLE (低いほど良い)
コードは検証1とcsvファイル名以外同じなので割愛。
詳細はこちらのkaggle kernelにあります。
結果
AutoML_GCP: 0.15001
AutoML_H2O: 0.13372
→ H2Oの勝ち
検証3: 保険請求の予測
参考記事はこちら 4, 5
データ数: train 595212行, test 892816行
評価指標: Normalized Gini Coefficient (高いほど良い)
import pandas as pd
import h2o
from h2o.automl import H2OAutoML
# data load
train = pd.read_csv("../input/train.csv")
# h2oで使えるように変換
htrain = h2o.H2OFrame(train)
# 予測対象変数 (y) と予測に用いる変数 (x)
x = htrain.columns
y = 'shares'
x.remove(y)
# class分類の場合は以下の処理を追加
htrain[y] = htrain[y].asfactor()
# AutoML, 学習時間8hour (max_runtime_secs=28800) と乱数シード以外はデフォルト
aml = H2OAutoML(seed=42, max_runtime_secs=28800)
aml.train(x=x, y=y, training_frame=htrain)
# 結果表示
lb = aml.leaderboard
lb.head(rows=lb.nrows) # 全ての結果
作成したモデルのLeader Boardは以下です。2値分類タスクのため、評価指標が検証1と若干異なっています。
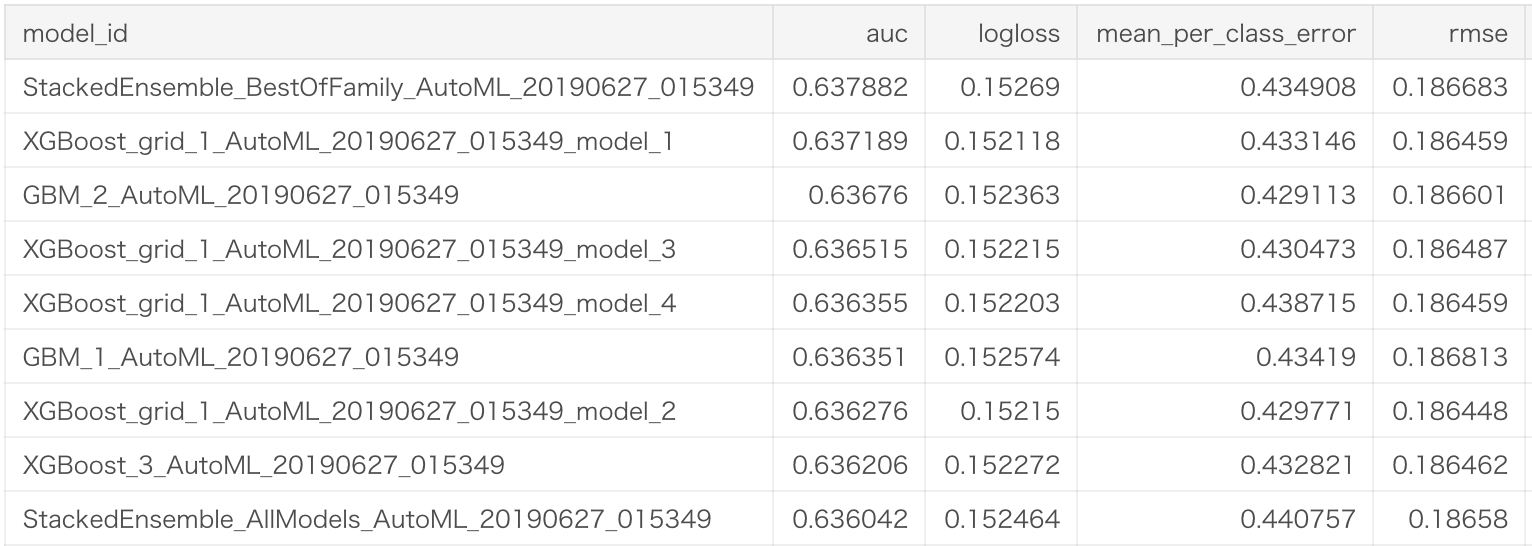
詳細はこちらのkaggle kernelにあります。
結果
AutoML_GCP: 上位50-60%相当(?)
AutoML_H2O: 上位70%相当
→ Googleの勝ち
結果まとめ
| シェア数予測 (RMSE) |
住宅価格予測 (RMSLE) |
保険請求予測 (Normalized Gini Coefficient) |
|
|---|---|---|---|
| AutoML_GCP | 0.86349 | 0.15001 | 上位50-60% |
| AutoML_H2O | 0.85903 | 0.13372 | 上位70% |
| AutoML_H2Oの勝ち | AutoML_H2Oの勝ち | AutoML_GCPの勝ち |
データが少数ならH2OのAutoMLが、データが一定量以上ならGoogleのAutoML Tableが強いらしい。6
H2OのAutoMLはLeader Board形式でモデルを表示してくれてうれしい。7
GoogleのAutoMLは、pythonやRコードを経由しなくても学習を実行できるのがめちゃくちゃ嬉しいはず。
感想
AutoMLすごい
-
kaggleでよく見かけるため ↩
-
Seed固定以外はデフォルト設定です。また、kernelの連続実行時間は9hourです。 ↩
-
このタスクは他の方も検証を行っていて、catboost: 0.86257, データノールックLightGBM by Kaggle Grand Master: 0.86099らしい。ノールックH2O AutoML強い。 ↩
-
他にも複数コンペで比較されていますが、次の理由で検証していません。Mercariコンペ, テキスト処理をどれだけしていいかわからず却下。Walmart, データセットをkernel上で使おうとすると何故か落ちるため却下。残り, kaggle上でなかったり古すぎてデータが無くなっていたので却下。Porto Segroの上位50-60%は目で測っています。 ↩
-
AutoML_H2Oも学習時間が足りてない可能性があるので、AutoML_GCPとAutoML_H2Oを同時間回した結果を知りたい。そもそも何時間回したんだろう。 ↩
-
見方がよくわかってないので、GBDT単体で強いのか黒魔術(stacking)が強いのかくらいしかわからないが ↩