はじめに
LLMで思考モード/モデルがどのように学習されているか知りたく、散文的なメモを残します。
Qwen3 思考モード(Thinking ModeとNon-Thinking Mode)の統合 及び Thinking Budgetの導入
参考情報
Abstract (原文)
In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models—–such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ32B)—–and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
Thinking Mode Fusion and General RL
思考モード(Thinking ModeとNon-Thinking Mode)の統合は、事後学習の第3ステージ(Thinking Mode Fusion)と第4ステージ(General RL)で実現しました (下図参照)。
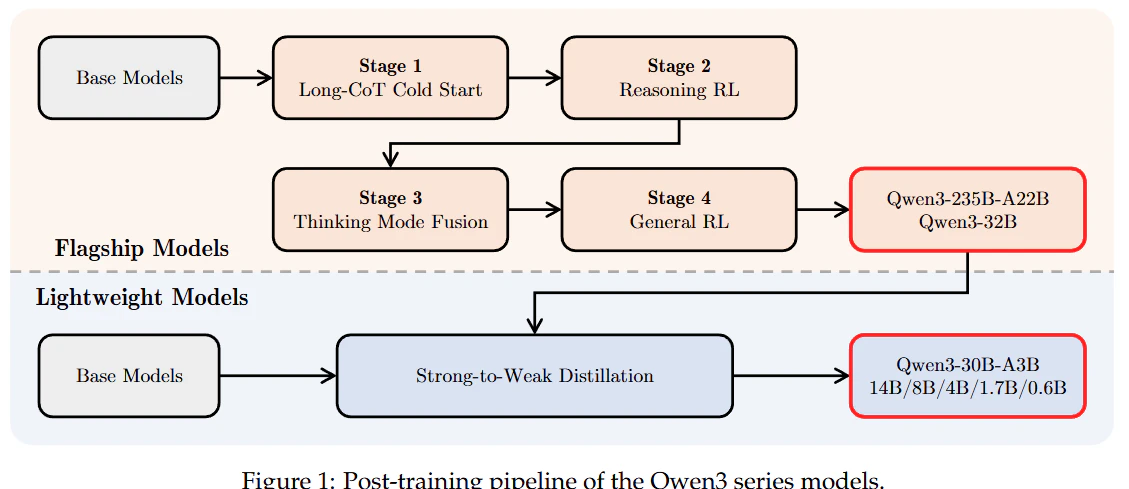
第3ステージ(Thinking Mode Fusion)
第3ステージ(Thinking Mode Fusion)では、思考モードごとに(Thinking ModeとNon-Thinking Modeで)、Chatテンプレートを以下のように切り替えたトレーニングデータを用意してSFTを行いました。

Thinkingの場合の学習データとNon-Thinkingの場合の学習データには以下の違い・特徴があります。
Thinking:
- ユーザークエリもしくはシステムプロンプト(下表では省略)にて"/think"フラグを追加
- 一部"/think"フラグを入れないデータも用意する(事前学習で推論モデルになるように学習しているのでdefault(タグ無)ではthinkingするようにする)
- 推論過程を入れたthinkタグ
Non-Thinking:
- ユーザークエリもしくはシステムプロンプト(下表では省略)にて"/no_think"フラグを追加
- 空のthinkタグ
Thinking と Non-thinking の両方:
- 複雑なマルチターンの会話に、"/think"フラグと"/no_think"フラグの両方をランダム複数個に挿入し、会話中の最新のフラグに従って出力を返す
このようなデータセットを用いて、二つのモードの使いわけをモデルに学習させました。
また、Thinkタグを出力するように学習したことで、Thinking Budget(全出力トークンの上限)のコントロールがルールベースできるようになりました。Thinking Budgetを設定したうえで一度生成させます。その際、出力トークンが上限を下回ったらそのまま回答に用います。一方、出力トークンが上限を上回ったら、出力トークン中のThinkタグの有無をチェックし、Thinkタグがあればその出力トークンをインプットに続きを生成し、Thinkタグがなければその出力トークンにThinkタグ(と思考をクローズするコメント)をつけてインプットにして続きを生成させます。このようにThinking Budget内で出力を完結できなかった場合は、2段階目の生成で追加のThinkingなしで回答を出させるようにすることでThinking Budgetをきかせています。厳密に、思考のトークン数のみを制限してない点は注意点だと思います。
言葉だとわかりにくいので、Thinking Budgetを導入する際のコーディング方法を参考にするのが良いです。
Thinking Budgetを上げていくことで、Thinking Modeでは推論が重要なタスクでの性能向上が確かにみられています(下図)。
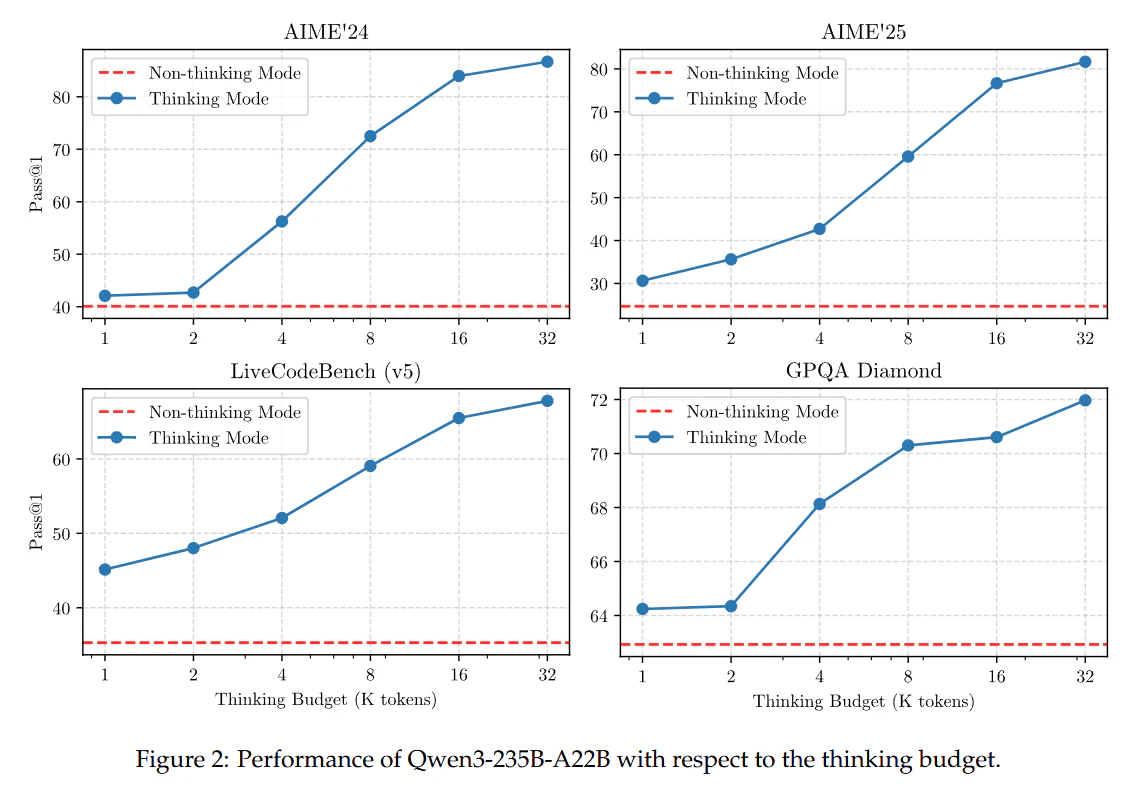
「思考モードの統合を行うことで(明示的に学習していないが)思考が途中の状態で切り上げてもうまく回答ができるようになった」(意訳)とありますが、本当に統合が大事なの?Thinking Modeの学習だけで十分じゃないの?と思ってしまいます。Thinki Modeに特化したモデルも公開されているので、このモデルでもThinkig Budgetがうまく機能するかみたいところです。
意訳前の原文
An additional advantage of Thinking Mode Fusion is that, once the model learns to respond in both non-thinking and thinking modes, it naturally develops the ability to handle intermediate cases—generating responses based on incomplete thinking.
第4ステージ(General RL)
第4ステージ(General RL)では、20種類以上のタスクでRLを行いました。その中に、指示追従(Instruction Following)とフォーマット追従(Format Following)能力を評価するタスクがあります:
原文抜粋
• Instruction Following:
This capability ensures that models accurately interpret and follow user instructions, including requirements related to content, format, length, and the use of structured output, delivering responses that align with user expectations.
• Format Following:
In addition to explicit instructions, we expect the model to adhere to specific formatting conventions. For instance, it should respond appropriately to the /think and / no think flags by switching between thinking and non-thinking modes, and consistently use designated tokens (e.g., and ) to separate the thinking and response parts in the final output.
これらのタスクで学習することにより、思考モードの統合がよりうまくいくようになりました(下表)。
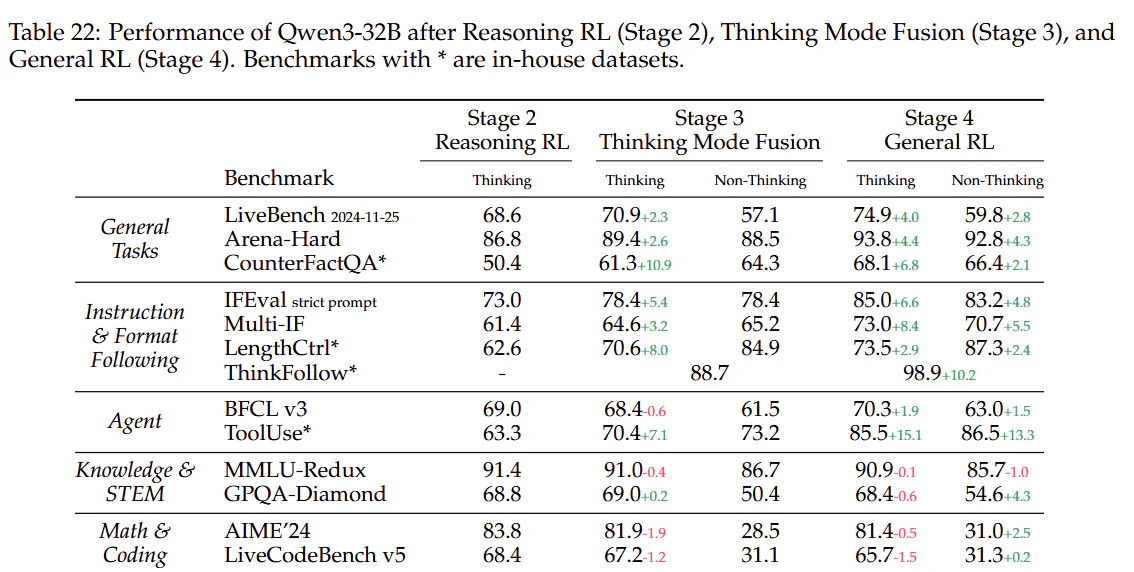
ThinkFollowが思考モードの統合に関するタスクです。マルチターンの対話でランダムに/think or /no_think flagを入れたときに、そのフラグに応じて思考モードをの切り替えがうまくいくか評価しています。ステージ3で思考モードの切り替え能力が一定身に付き、ステージ4でより向上しています。ただ、100%ではなくうまく思考モードを切り替えられないケースもあります。
gpt-oss: Reasoning Effortの導入
参考情報
Reasoning effort と RL
2.5 Post-Training for Reasoning and Tool Use
After pre-training, we post-train the models using similar CoT RL techniques as OpenAI o3. This procedure teaches the models how to reason and solve problems using CoT and teaches the model how to use tools. Because of the similar RL techniques, these models have a personality similar to models served in our first-party products like ChatGPT. Our training dataset consists of a wide range of problems from coding, math, science, and more.
2.5.2 Variable Effort Reasoning Training
We train the models to support three reasoning levels: low, medium, and high. These levels are configured in the system prompt by inserting keywords such as "Reasoning: low". Increasing the reasoning level will cause the model’s average CoT length to increase.
学習データに、system prompt内でReasoning:low/medium/highを指定したものを用意して、CoT RLを行うことで、Reasoning Effortを効かせるようにしたのだと推測される。Qwen3のInstruction FollowingタスクのRLに近いことを行っていると推察。