メリークリスマス!
この記事は検索エンジンプロダクトを一緒に開発してた同窓会 Advent Calendar 2023の25日目の記事になります。
はじめに
今年の3月ごろからQdrantを扱っており、Lexical Search や Dense Search いろいろ試していました。今回は Qdrant v1.7.0 から Sparse Vector の検索機能が導入されたので、この記事を参考に、Dense, Sparse, Hybrid のベクトル検索を紹介します。
とりあえず試したい方はこちらからどうぞ!
Qdrant とは
- Rust製のベクトル類似検索エンジン
- ベクトルに加えペイロードを用いた絞り込み検索もできる
- local, on-premise, cloud 環境で利用可能
- Python, Javscript/TypeScript, Rust, Go で利用可能
ベクトル検索
ベクトル検索は、ベクトル空間内で類似性を基にしてデータを検索する手法で、情報検索、機械学習、データベースなどのさまざまな分野で使用されています。ベクトル検索は以下の手順で処理されます。
-
ベクトルの表現
データベース内の各アイテムや文書は、数値のベクトルとして表現されます。例えば、テキストデータの場合は単語の埋め込みベクトルや画像データの場合は特徴量ベクトルなどです。 -
類似性計算
ユーザーがクエリとして与えたベクトル(例えば、検索したい文書や画像のベクトル表現)とデータベース内の各アイテムのベクトルとの類似性を計算します。類似性は、通常、ユークリッド距離、コサイン類似度、マンハッタン距離などを用いて計算されます。 -
検索結果のランキング
類似性が計算されたら、類似性の高いものから順に検索結果がランク付けされます。これにより、ユーザーが最も関連性の高いデータを最初に受け取ることができます。
Dense Vector と Sparse Vector
Dense Vector(密ベクトル)とSparse Vector(疎ベクトル)は、ベクトルの表現方法に関する概念です。
Dense Vector (密ベクトル)
- 密ベクトルは、通常のベクトル表現であり、ほとんどの要素がゼロ以外の値で埋められています。
- 例えば、[1.2, 3.5, 0.8, -2.1] のようなベクトルが密ベクトルです。この場合、ほとんどの要素がゼロ以外の実数値を持っています。
Sparse vector(疎ベクトル)
- 疎ベクトルは、ほとんどの要素がゼロであるベクトルです。非ゼロの要素が限られている場合、そのベクトルは疎ベクトルと見なされます。
- 例えば、[0, 0, 2.5, 0, 0, 0, 1.3, 0] のようなベクトルが疎ベクトルです。この場合、非ゼロの要素は2.5と1.3だけです。
これらの表現方法にはそれぞれ利点があります。Dense Vector 計算効率が高く、メモリを効率的に使用しますが、非ゼロの要素が多い場合には無駄が生じることがあります。一方、Sparse Vector は非ゼロの要素だけを保持するため、メモリの使用効率が向上しますが、計算がやや複雑になることがあります。どちらを使用するかは具体的なタスクやデータの性質によります。
Dense Vector Search
Qdrant で Dense Vector を用いたベクトル検索するときは、HNSW が使われます。(Qdrant: Vector-Index)
HNSW(Hierarchical Navigable Small World Graph)は、グラフベースの索引アルゴリズムです。特定の規則に従って、画像に対して多層のナビゲーション構造を構築します。この構造では、上位の層はより疎でノード間の距離が遠く、下位の層はより密でノード間の距離が近いです。検索は最上位の層から始まり、この層で目標に最も近いノードを見つけ、次の層に進んで別の検索を開始します。複数の反復の後、素早く目標位置に近づくことができます。
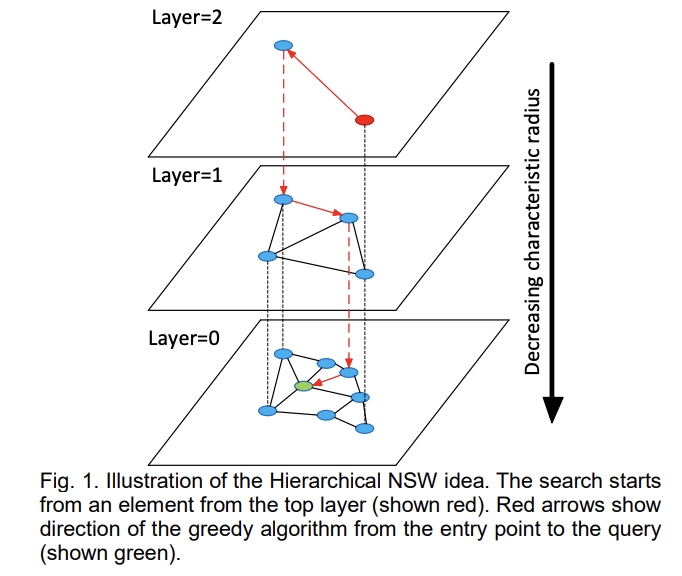
以下、Qdrant のインデックス構築から検索までの流れになります。
Index を作成します。Qdrant では Collection と呼ばれています。
Dense Vector の検索を利用する際は、ベクトルのサイズと類似計算方法を設定します。今回は、BERT を用いるため size=768 に設定し、類似計算は cosine-similarity を使います。
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams
client = QdrantClient()
collection_name = "sample-search"
vectors_config = vectors_config = {
"dense": VectorParams(
size=768,
distance=Distance.COSINE,
on_disk=False,
),
}
client.recreate_collection(
collection_name=collection_name,
vectors_config=vectors_config,
)
データを挿入し、HNSW で探索するグラフを構築します。
ここでは こちら の BERT モデルを用いてベクトル作成を想定して進めます。(余談ですが、payload に属性値を設定することができます。)
from typing import List
from qdrant_client.models import PointStruct
text = "Tamagoyaki is one of the egg dishes"
dense_vector: List[float] = compute_dense(text)
point = PointStruct(id=1, payload={}, vector={"dense": dense_vector})
client.upsert(
collection_name=collection_name,
points=[point],
)
HNSWで構築したグラフを探索します。SearchParams を用いることで、探索時に保持するポイント数を設定することができます。また、ここでは紹介してませんが、payload に設定した属性値を用いてフィルタリングも併用することもできます。(フィルタは pre-filter です。)
from qdrant_client.models import SearchPrams
query_vector: List[float] = compute_dense(query_text)
search_params = SearchParams(
hnsw_ef=128,
exact=False,
)
response = client.search(
collection_name=collection_name,
query_vector=query_vector,
search_params=search_params,
with_vectors=True,
)
以上で、Dense Vector を用いたインデックス作成と検索までの手順になります。
こちらにサンプルのプログラムを作成しましたので、詳細が気になる方は是非みてください。
Sparse Vector Search
Sparse Vector の生成はなんでもよいですが、ここではブログで紹介されている SPLADE を使ってみましょう。SPLADE とは、Neural Retriever Model の1つで、Query と Document を BERT Masked Language Model で sparse 表現に展開します。
以下の手順でプログラムを実装します。
import torch
from transformers import AutoModelForMaskedLM, AutoTokenizer
# model load
model_name = "naver/splade-cocondenser-ensembledistil"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForMaskedLM.from_pretrained(model_name)
# sample text
text = "Tamagoyaki is one of the egg dishes"
# vectorize
def compute_vectors(text: str) -> torch.Tensor:
tokens: dict = tokenizer(text, return_tensors="pt")
output = model(**tokens)
embeddings = torch.log(1 + torch.relu(output.logits)) * tokens.attention_mask.unsqueeze(-1)
vectors, _ = torch.max(embeddings, dim=1)
return vectors
vectors = compute_vectors(text)
indices = vectors.nonzero().squeeze().cpu().tolist()
weights = vectors[indices].cpu().tolist()
# create token and vector pairs
vocabs = tokenizer.get_vocab()
index2token = dict(zip(vocabs.values(), vocabs.keys()))
result: Dict[str, float] = {
index2token.get(index): weight for index, weight in zip(indices, weights)
}
SPLADE の出力例
# text = "Tamagoyaki is one of the egg dishes"
{
"the": 0.22991976141929626,
"is": 0.7032573223114014,
"one": 0.48617222905158997,
"##i": 0.0423058420419693,
"part": 0.14577321708202362,
"species": 0.40340670943260193,
"india": 0.08262555301189423,
"god": 0.35137075185775757,
"style": 0.16710789501667023,
"food": 0.908564031124115,
"character": 0.18830366432666779,
"china": 0.02727614901959896,
"japan": 0.6141868233680725,
"##ya": 1.2373383045196533,
"##ki": 1.5214265584945679,
"culture": 0.6643863320350647,
"variety": 0.6308894157409668,
"##ko": 0.0779687762260437,
"fish": 0.08073794841766357,
"dinner": 0.0924849659204483,
"restaurant": 0.39914095401763916,
"rice": 0.1837901622056961,
"fruit": 0.020662883296608925,
"meat": 0.32374438643455505,
"eggs": 1.4436782598495483,
...
}
上記のように、各 token に対して重みが設定されます。SPLADEは、他の関連する用語を含めるためのクエリ/ドキュメントの拡張を学習するため、テキストに出現しない単語も関連付けされます。これは、正確な単語を含む他の疎な手法と比べて、文脈に関連するものを完全に見逃さないメリットがあります。
それでは、Dense Vector Search と同じように、Index 作成から検索までやってみましょう!
from qdrant_client.models import SparseVectorParams
sparse_vectors_config = {
"sparse": SparseVectorParams(
index=SparseIndexParams(on_disk=False),
),
}
client.recreate_collection(
collection_name=collection_name,
vectors_config={},
sparse_vectors_config=sparse_vectors_config,
)
Sparse Vector を挿入してインデックスを構築します。Qdrant の Sparse Vector Search は、転置インデックス構造を採用しています。
以下、インデックス構築の処理になります。
from qdrant_client.models import PointStruct
point_id = 1
text_vector = compute_vectors(text)
text_indices = text_vector.nonzero().numpy().flatten()
text_values = text_vector.detach().numpy()[text_indices]
point = PointStruct(
id=point_id,
payload={},
vector={
"sparse": SparseVector(
indices=text_indices.tolist(),
values=text_values.tolist(),
)
}
)
client.upsert(collection_name, [point], with_vector=True)
転置インデックスを探索します。こちらも属性値のフィルタを利用することができます。
from qdrant_client.models import SparseVector, NamedSparseVector
keyword = "Tamagoyaki"
query_vector = compute_vectors(keyword)
query_indices = query_vector.nonzero().numpy().flatten()
query_values = query_vector.detach().numpy()[query_indices]
query = NamedSparseVector(
name="sparse",
vector=SparseVector(
indices=query_indices.tolist(),
values=query_values.tolist(),
),
)
response = client.search(
collection_name=collection_name,
query_vector=query_vector,
with_vectors=True,
)
以上で、Sparse Vector を用いたインデックス作成と検索までの手順になります。
こちらに Sparse Vector Search の全体のプログラムがありますので、Dense Vector のプログラムと合わせて確認していただければ幸いです。
Hybrid Search
Dense Vector と Sparse Vector の検索結果を Reciprocal Rank Fusion を用いて、再スコアリングをしてみましょう。Reciprocal Rank Fusion は、複数の検索結果ランキングを組み合わせ、総合的なランキングを生成する手法の一つです。逆数順位で各検索結果のスコアを計算します。
$$ RRF_{score}(d \in D)=\sum_{r\in R} \frac{1}{k+r(d)} $$
以下、Reciprocal Rank Fusion を用いて Qdrant から得られた複数の検索結果を1つにするプログラムになります。
from collections import defaultdict
from typing import Dict, List
from qdrant_client.models import ScoredPoint
def reciprocal_rank_fusion(search_results: List[List[ScoredPoint]], k: int=60) -> List[ScoredPoint]:
scores = defaultdict(int)
points: Dict[int, ScoredPoint] = dict()
for documents in search_results:
for rank, document in enumerate(documents, start=1):
scores[document.id] += 1.0 / (k + rank)
points[document.id] = document
results = []
for document_id in scores.keys():
result = points[document_id]
result.score = scores[document_id]
results.append(result)
results.sort(reverse=True, key=lambda result: result.score)
return results
Dense Vector と Sparse Vector の検索結果を1つにするまでのプログラムを順を追って紹介します。今回は、1つの collection に sparse と dense のベクトルを入れます。以下の config で保持するベクトルを設定します。
client.recreate_collection(
collection_name=collection_name,
vectors_config={"text-dense": vectors_config},
sparse_vectors_config=sparse_vectors_config,
)
設定した collection に対して、dense vector と sparse vector を挿入します。
point = PointStruct(
id=point_id,
payload={},
vector={
"text-sparse": SparseVector(
indices=sparse_indices.tolist(),
values=sparse_values.tolist(),
),
"text-dense": dense_values.tolist(),
}
)
client.upsert(collection_name=collection_name, points=[point])
検索結果を取得します。今回は2つのリクエストをまとめて送ります。(パフォーマンスを考慮するとクラスタを分けた方が好ましいかもしれません。)
top_n = 10
# create search requests
sparse_request = SearchRequest(
vector=NamedSparseVector(
name="text-sparse",
vector=SparseVector(
indices=query_sparse_indices.tolist(),
values=query_sparse_values.tolist(),
),
),
limit=top_n,
)
dense_request = SearchRequest(
vector=NamedVector(
name="text-dense",
vector=query_dense_values.tolist(),
),
limit=top_n,
)
# search
requests = []
response: List[List[ScoredPoint]] = client.search_batch(
collection_name=collection_name,
requests=[sparse_request, dense_request],
)
dense と sparse の結果を RRF アルゴリズムを用いてまとめます。
hybrid_results = reciprocal_rank_fusion(response)
Hybrid Search の全体のプログラムはこちらになります。
動作確認
ChatGPT で作ったサンプルのテキストに対して、ベクトル検索を試してみました。(ChatGPT便利ですね)
以下サンプルデータと texts[0] で検索した結果になります。
## サンプルデータ
texts = [
"Lorem ipsum dolor sit amet, consectetur adipiscing elit.",
"Python is a versatile programming language used for web development, data analysis, and artificial intelligence.",
"The quick brown fox jumps over the lazy dog.",
"Coding is like solving puzzles; each line of code contributes to the bigger picture.",
"In a world full of technology, staying curious and learning new things is essential.",
"Science is organized knowledge. Wisdom is organized life.",
"Artificial intelligence is reshaping the way we live and work, opening up new possibilities and challenges.",
"The journey of a thousand miles begins with a single step.",
"Life is what happens when you're busy making other plans.",
"The only way to do great work is to love what you do.",
"Imagination is more important than knowledge. For knowledge is limited, whereas imagination embraces the entire world.",
"Success is not final, failure is not fatal: It is the courage to continue that counts.",
"Programming is not about typing, it's about thinking.",
"The more you know, the more you realize you don't know.",
"Coding is an art of turning caffeine into code.",
"The best way to predict the future is to create it.",
"Keep calm and code on.",
"Every great developer you know got there by solving problems they were unqualified to solve until they actually did it.",
"It always seems impossible until it's done.",
]
検索結果
sparse result:
1-th: id=0, score=32.638237
2-th: id=9, score=1.4775581
3-th: id=18, score=1.1485143
4-th: id=6, score=0.93051076
5-th: id=5, score=0.64576685
6-th: id=11, score=0.63611734
7-th: id=1, score=0.35484803
8-th: id=10, score=0.3346569
9-th: id=12, score=0.29486114
10-th: id=3, score=0.18156186
dense result:
1-th: id=16, score=0.50693345
2-th: id=5, score=0.3935973
3-th: id=14, score=0.37463832
4-th: id=2, score=0.33893123
5-th: id=18, score=0.31138548
6-th: id=12, score=0.30645102
7-th: id=0, score=0.25058436
8-th: id=7, score=0.24551488
9-th: id=13, score=0.2382121
10-th: id=8, score=0.2091488
hybrid result (reciprocal rank fusion):
1-th: id=5, score=0.0315136476426799
2-th: id=0, score=0.03131881575727918
3-th: id=18, score=0.03125763125763126
4-th: id=12, score=0.02964426877470356
5-th: id=16, score=0.01639344262295082
6-th: id=9, score=0.016129032258064516
7-th: id=14, score=0.015873015873015872
8-th: id=6, score=0.015625
9-th: id=2, score=0.015625
10-th: id=11, score=0.015151515151515152
まとめ
Qdrant を用いて Dense, Sparse, Hybrid の検索を試してみました。ここでは触れませんが、Qdrant のパフォーマンス改善の話や、embeddings の作成、モデルの改善なども試しており、機会があればどこかで紹介したいなと思います。
最後に、最近ベクトル検索の影響でいろんな検索エンジンが盛り上がっていますが、Qdrant っていうベクトル検索エンジンもあるんだぞ!とアピールになれば良いなと思います。
参考