特定グループごとに、ランキングを出すなどは通常のクエリではできないのですが、BigQueryのウィンドウ関数を使うとできます。(ちなみにMySQLではウィンドウ関数はないので、以前、Redshift(Postgres互換)を使ったときにはじめてウィンドウ関数を知りました)
ウィンドウ関数は、ぱっと見わかりにくいのでサンプルとともにまとめます。
累計
-- クエリ
SELECT name, value, SUM(value) OVER (ORDER BY value) AS RunningTotal
FROM
(SELECT "a" AS name, 0 AS value),
(SELECT "b" AS name, 1 AS value),
(SELECT "c" AS name, 2 AS value),
(SELECT "d" AS name, 3 AS value),
(SELECT "e" AS name, 4 AS value);
-- 実行結果
+------+-------+--------------+
| name | value | RunningTotal |
+------+-------+--------------+
| a | 0 | 0 |
| b | 1 | 1 |
| c | 2 | 3 |
| d | 3 | 6 |
| e | 4 | 10 |
+------+-------+--------------+
<window-frame-clause>を省略しているので、RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROWが使用されています。つまり、valueでソートし、その行のvalueまでの値をSUM(value)で合計した結果を行とともに出しているので、累計が出力されます。
移動平均
-- クエリ
SELECT
name,
value,
AVG(value)
OVER (ORDER BY value
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW)
AS MovingAverage
FROM
(SELECT "a" AS name, 0 AS value),
(SELECT "b" AS name, 1 AS value),
(SELECT "c" AS name, 2 AS value),
(SELECT "d" AS name, 3 AS value),
(SELECT "e" AS name, 4 AS value);
-- 実行結果
+------+-------+---------------+
| name | value | MovingAverage |
+------+-------+---------------+
| a | 0 | 0.0 |
| b | 1 | 0.5 |
| c | 2 | 1.5 |
| d | 3 | 2.5 |
| e | 4 | 3.5 |
+------+-------+---------------+
1日移動平均を出しています。ROWS BETWEEN 1 PRECEDING AND CURRENT ROWなので1つまえの行と現在の行の平均をMovingAverageに出力しています。
現在行の相対順位(CUME_DIST)
-- クエリ
SELECT
name, category, value,
cume_dist() OVER (PARTITION BY category ORDER BY value DESC RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS cume_dist,
FROM
(SELECT "a" AS name, 1 AS category, 0 AS value),
(SELECT "b" AS name, 1 AS category, 1 AS value),
(SELECT "c" AS name, 2 AS category, 2 AS value),
(SELECT "d" AS name, 2 AS category, 3 AS value),
(SELECT "e" AS name, 2 AS category, 4 AS value);
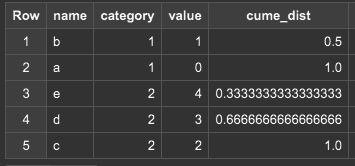
cume_dist()では(処理する行数) / (総行数)という計算式で相対順位を計算します。
PERCENT_RANK
-- クエリ
SELECT
name, category, value,
PERCENT_RANK() OVER (PARTITION BY category ORDER BY value DESC RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS PERCENT_RANK,
FROM
(SELECT "a" AS name, 1 AS category, 0 AS value),
(SELECT "b" AS name, 1 AS category, 1 AS value),
(SELECT "c" AS name, 2 AS category, 2 AS value),
(SELECT "d" AS name, 2 AS category, 3 AS value),
(SELECT "e" AS name, 2 AS category, 4 AS value);
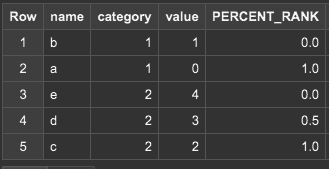
cume_distと似ていますが、percent_rank()では、順位の”位置”ではなく、(rank – 1) / (全行数 – 1)という計算をして順位の割合を出します。
ランキング(RANK, DENSE_RANK)
-- クエリ
SELECT name, value, RANK() OVER (ORDER BY value DESC) AS rank
FROM
(SELECT "a" AS name, 0 AS value),
(SELECT "b" AS name, 1 AS value),
(SELECT "c" AS name, 2 AS value),
(SELECT "d" AS name, 3 AS value),
(SELECT "e" AS name, 4 AS value);
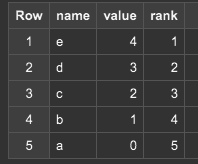
ランキングを返します。Partitionで分割するとパーティションごとのランキングが出せます。同点順位で例えば2位が2つあると、次のランクは4位になります。次の値を3位にしたい場合は、dense_rank()を使います。
FIRST_VALUE, LAST_VALUE, NTH_VALUE
-- クエリ
SELECT name, category, value, FIRST_VALUE(value) OVER (PARTITION BY category ORDER BY value DESC RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS first
FROM
(SELECT "a" AS name, 1 AS category, 0 AS value),
(SELECT "b" AS name, 1 AS category, 1 AS value),
(SELECT "c" AS name, 2 AS category, 2 AS value),
(SELECT "d" AS name, 2 AS category, 3 AS value),
(SELECT "e" AS name, 2 AS category, 4 AS value);
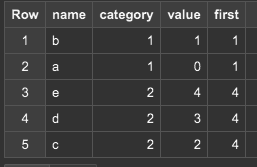
FIRST_VALUEはウィンドウ内の最初の値を返します。たとえば、category内のトップの値はないかというのに使うことができます。LAST_VALUEは最後の値、NTH_VALUEはN番目の値が出せます。
LAG, LEAD
-- クエリ
SELECT
name, category, value,
LAG(value, 1) OVER (PARTITION BY category ORDER BY value DESC RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS lag,
LEAD(value, 1) OVER (PARTITION BY category ORDER BY value DESC RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS lead,
FROM
(SELECT "a" AS name, 1 AS category, 0 AS value),
(SELECT "b" AS name, 1 AS category, 1 AS value),
(SELECT "c" AS name, 2 AS category, 2 AS value),
(SELECT "d" AS name, 2 AS category, 3 AS value),
(SELECT "e" AS name, 2 AS category, 4 AS value);
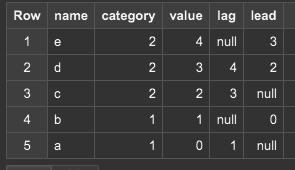
LAG(value, x)でウィンドウ内でx個前のものを取得。LEADはx個後のものを取得します。
NTILE(<num_buckets>)
-- クエリ
SELECT
name, category, value,
NTILE(2) OVER (PARTITION BY category ORDER BY value DESC RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS ntile,
FROM
(SELECT "a" AS name, 1 AS category, 0 AS value),
(SELECT "b" AS name, 1 AS category, 1 AS value),
(SELECT "c" AS name, 2 AS category, 2 AS value),
(SELECT "d" AS name, 2 AS category, 3 AS value),
(SELECT "e" AS name, 2 AS category, 4 AS value);
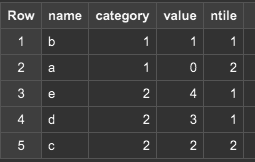
ウィンドウ内での数にデータを分割します。が2で、5行あったら3行と2行の2つのバケットにわけられます。
RATIO_TO_REPORT
値の合計に対する個々の値の割合を表す 0~1 の double 型の値を返します。
これは、例えば世界の富豪がどのくらいの富の割合をもっているのかに使えそうです。
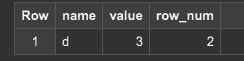
ROW_NUMBER
ウィンドウ内のクエリ結果の現在の行番号を返します。番号の先頭は 1 です。
WHERE句でその行番号を指定してやれば2行目だけ返すとかができそうです。
-- クエリ
SELECT
*
FROM
(
SELECT name, value, ROW_NUMBER() OVER (ORDER BY value DESC) AS row_num
FROM
(SELECT "a" AS name, 0 AS value),
(SELECT "b" AS name, 1 AS value),
(SELECT "c" AS name, 2 AS value),
(SELECT "d" AS name, 3 AS value),
(SELECT "e" AS name, 4 AS value)
)
WHERE
row_num = 2