今回の記事について
この記事はAWS初学者を導く体系的な動画学習サービス
「AWS CloudTech」の課題カリキュラムで作成しました。
https://aws-cloud-tech.com
前回の続き
前回の記事の続きになります。
前回作成した環境に構築していきますので、まずはこちらをご覧ください。
今回やること
・起動テンプレートの作成
・ELBの配下にAutoScalingGroupを紐付ける
・CloudWatchでAutoScalingのCPU使用率を監視するアラームの作成
(CPU使用率70%以上、CPU使用率30%以下)
・作成したアラームとAutoScalingのスケーリングポリシーを紐づける
・検証(意図的にEC2のCPUに負荷をかけてAutoScalingによりEC2が増減するか確認)
環境
macOS Big Sur バージョン11.2.2
構成図
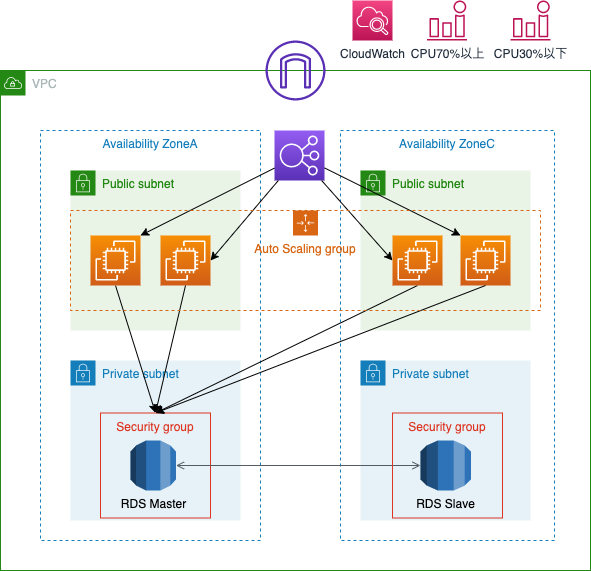
起動テンプレートの作成(AutoScalingで起動するEC2インスタンスの設定)
*起動設定でも出来ますが、Amazonは起動テンプレートの利用を推奨しているようです。
EC2コンソールを開き、左ペインからテンプレートの起動を選択
↓
起動テンプレートを作成
起動テンプレート名: LaunchTemplate1 (任意の名前)
テンプレートバージョンの説明:1.0.0 (任意)
AutoScalingのガイダンス: このテンプレートをAutoScalingで使用するのでチェックを入れる
AMI:以前のハンズオンで作成しているEC2を設定
インスタンスタイプ:検証用であれば無料枠でOK
キーペア:すでに作成してあるものを使用
セキュリティグループ:後で設定するのでここでは空白でOK
リソースタグ:リソースタイプをインスタンスに設定すると、AutoScalingによって立ち上がったインスタンスにタグ付けできる
ネットワークインターフェイスの設定
セキュリティグループ:既存のEC2に紐付けているものと同じSGを選択
パブリックIPの自動割り当て:有効化
他デフォルトで起動テンプレートの作成
*ちなみに既存のEC2を選択してアクション→イメージとテンプレート→インスタンスからテンプレートを作成から簡単に作れます。
ELBの配下にAutoScalingGroupを紐付ける
前回までのハンズオンで作成したEC22台を停止しておく。RDSは起動してる状態。
AutoScalingGroupの作成
ステップ1 起動テンプレートまたは起動設定を選択する
Auto-Scaling グループ名:Test-AutoScaling1 (任意)
起動テンプレート:先ほど作成した起動テンプレートを設定
ステップ2 設定の構成
インスタンスの購入オプション:起動テンプレートに準拠する
VPC、サブネット選択
(今回の場合、パブリックサブネット2つ選択)
ステップ3 詳細オプションを設定
ロードバランシング:前回までのハンズオンで作成したELBのターゲットグループを設定
ヘルスチェック:ヘルスチェックのタイプをELBにチェックを入れる
その他の設定(モニタリング):後で変更できるのでひとまず飛ばして次へ進む
ステップ4 グループサイズとスケーリングポリシーを設定する
希望する容量:2 (任意)
最小キャパシティ:2 (任意)
最大キャパシティ:4 (任意)
スケーリングポリシー:後から設定するのでひとまず飛ばして次へ
ステップ5 通知を追加
AutoScaling内のEC2が起動、終了するたびに、SNSなどで通知が欲しければ設定する
ステップ6 タグを追加
任意で設定
ステップ7 確認
確認して問題なければ作成
*作成後、現在EC2を2台とも停止してるので、AutoScalingで設定した希望する容量2台を維持するために、起動テンプレートで設定した2台のEC2インスタンスが新しく起動される。
CloudWatchでAutoScalingのCPU使用率を監視するアラームの作成
作成するアラーム
・CPU使用率が70%以上になった場合に起動するアラーム
・CPU使用率が30%以下になった場合に起動するアラーム
早速、CloudWatchコンソール画面で、アラームの作成を選択
ステップ1 メトリクスと条件の指定
メトリクスの選択⇨EC2⇨AutoScalingグループ別⇨先ほど作成したAutoScalingのCPU Utilization⇨メトリクスの選択
統計:平均値
期間:5分(デフォルト)
しきい値の種類:静的
アラーム定義:70 より大きい
その他の設定:欠落したデータを不正(しきい値を超えている)として処理
*CPU使用率が極端に高まると、EC2がCloudWatchにメトリクスを送れないと予想されるから
ステップ2 アクションの設定
SNSトピックで作成したメールアドレス宛に通知が届く設定
(SNSトピックを作成してなければ作成する)
ステップ3 名前と説明を追加
アラーム名:CPU_high(任意)
ステップ4 プレビューと作成
確認して問題なければ作成
*省略
もう一つのアラーム(CPU使用率30%以下)も同じように作成しましょう。
(設定)
アラーム定義:30 より小さい
その他の設定:欠落データを見つかりませんとして処理
アラーム名:CPU_low(任意)
*設定後のステータス
CPU_high OK
CPU_low アラーム状態
となっていることを確認する
作成したアラームとAutoScalingのスケーリングポリシーを紐づける
作成したAutoScalingのタブ⇨自動AutoScaling⇨スケーリングポリシー⇨ポリシーを追加
ポリシータイプ:シンプルなスケーリング
スケーリングポリシー名:CPU_add(CPU_remove)
CloudWatchアラーム:CPU_high(CPU_low)
アクションを実行:追加(削除) 1 キャパシティユニット
スケーリングアクティビティを許可するまでの秒数:30(任意)
highとlowのスケーリングポリシーをそれぞれ作成する
これでアラームに応じてAutoScalingによるEC2インスタンスが増減する仕組みができた。
検証(意図的にEC2のCPUに負荷をかけてAutoScalingによりEC2が増減するか確認)
・どちらか片方のEC2インスタンスへssh接続する
・EC2インスタンスに負荷をかける
負荷をかけるコマンド:yes >> /dev/null &
*4つほど実行する
・Linuxサーバーの負荷を確認する
Linuxサーバーの負荷を確認するコマンド:topでCPU使用率を確認できる
(抜けるにはctrl+c)
*もう一つのインスタンスでも同じように負荷をかける
しばらくしてAutoScalingのグラフを確認するとCPU使用率が高まってるのが確認できる
また、設定したCloudWatchアラームのCPU_highもアラームになってるのがわかる
さらに、EC2インスタンスが新しく立ち上がっているのが確認できるはず
(AutoScalingグループのアクティビティログでも確認できる)
*負荷がかかってる以上、設定した最大インスタンス数までインスタンスが立ち上がる
負荷を戻す
再びインスタンスに戻り、先ほど負荷をかけたyesコマンドをkillする
kill プロセスIDで負荷を解除できる
*kill {3974..3977}とすれば複数のIDをまとめて解除できる
最後にtopコマンドでCPU使用率が0%になっていることを確認
*もう一つのインスタンスでも同じように解除する
しばらくするとCPU使用率が30%を下回り、インスタンスが削除される動きになるが、ELBのConnection drainingの設定(デフォルトで300秒後)により、その時間経過後に削除される。
*ELBのConnection drainingとは
ELBから何らかの理由(障害など)でEC2が切り離されると、設定した時間経過後にEC2が削除される。
急に削除するとサーバーを使用しているユーザーに迷惑がかかるためこの機能がある。
(AWS SAAやSOAの資格試験にも出ます)(1〜3600秒の間で設定可能)
最終的に希望の容量(EC2インスタンス2台)に戻ってれば今回のハンズオンは終了。
お疲れ様でした。