初めてQiitaに投稿します。
2018年12月に「ユカイ工学」社から音声対話キット「Codama」が発売さました。
音声認識サービスを使うのに、面倒な利用登録申請などは不要なようで、価格も個人でも何とか手の届きそうなので、早速購入して音声によるデバイス制御がどの程度可能なのかの実験を行いました。(対話は考えていません)
最終的には写真のような実験装置を作りました。

動作ビデオ : Youtube:「Codama」ボードを使った音声によるデバイス制御実験
記事が長くなったので3つ+1つに分けることにしました。
- Part-1 :サンプルプログラムの動作確認と認識結果表示への改造
- Part-2 :音声によるWindowsアプリケーションの自動起動例
- Part-3 :音声による定番のLEDとサーボの動作例
- おまけ :認識結果・カメラ映像のモニタリング
1.とりあえずサンプルプログラムを動かしてみる
■ 用意したもの
- ラズパイ3 B+(新品)
- 「Codama」ボード(マイク付き)
- 8Ωのスピーカー
■ 組立方法とソフトウェアのインストール
組立方法や初期設定などは、GITHUBのcodama-doc-rc2 Codeやcodama-doc-rc2 Wikiを参考にして下さい。

※注記
動かすまで色々やらなければならない事がありますので、サイトに書かれている手順を数回読んでから始めた方がよろしいかと思います。
また、このボードに限ったことでは無いのですが、ラズパイで新しいことを始める場合は以下のことを考慮したらいいと思います。
- 電源:2.5A以上(ラズパイ3 B+では、消費電流が増えているようです)
- maicro SDカード(相性の良いもの)
- 「VNC」や「SSH」などでのリモート接続
- 「samba」を入れておくとWindowsでファイル操作できます
- 「固定IP」化
- Linuxのコマンドラインにコピペする方法
- Linuxのviやnanoなどのテキストエディタの最低限の操作
■ サンプルプログラムの動作
サンプルプログラムのあるフォルダに移動して、コマンドラインから以下のようにタイプします。
$ python3 main.py
起動すると、misakiさんが「ロボスタロボです・・・・」と喋って、ウェイク・アップ・ワード待ちとなる。
ウェイク・アップ・ワードを認識すると、待機状態になります。
何か発話すると、その音声データがSebastien-aiに送られて、認識処理後に以下のような文字列が表示されます。
発話例:「音声認識のテストを行います」
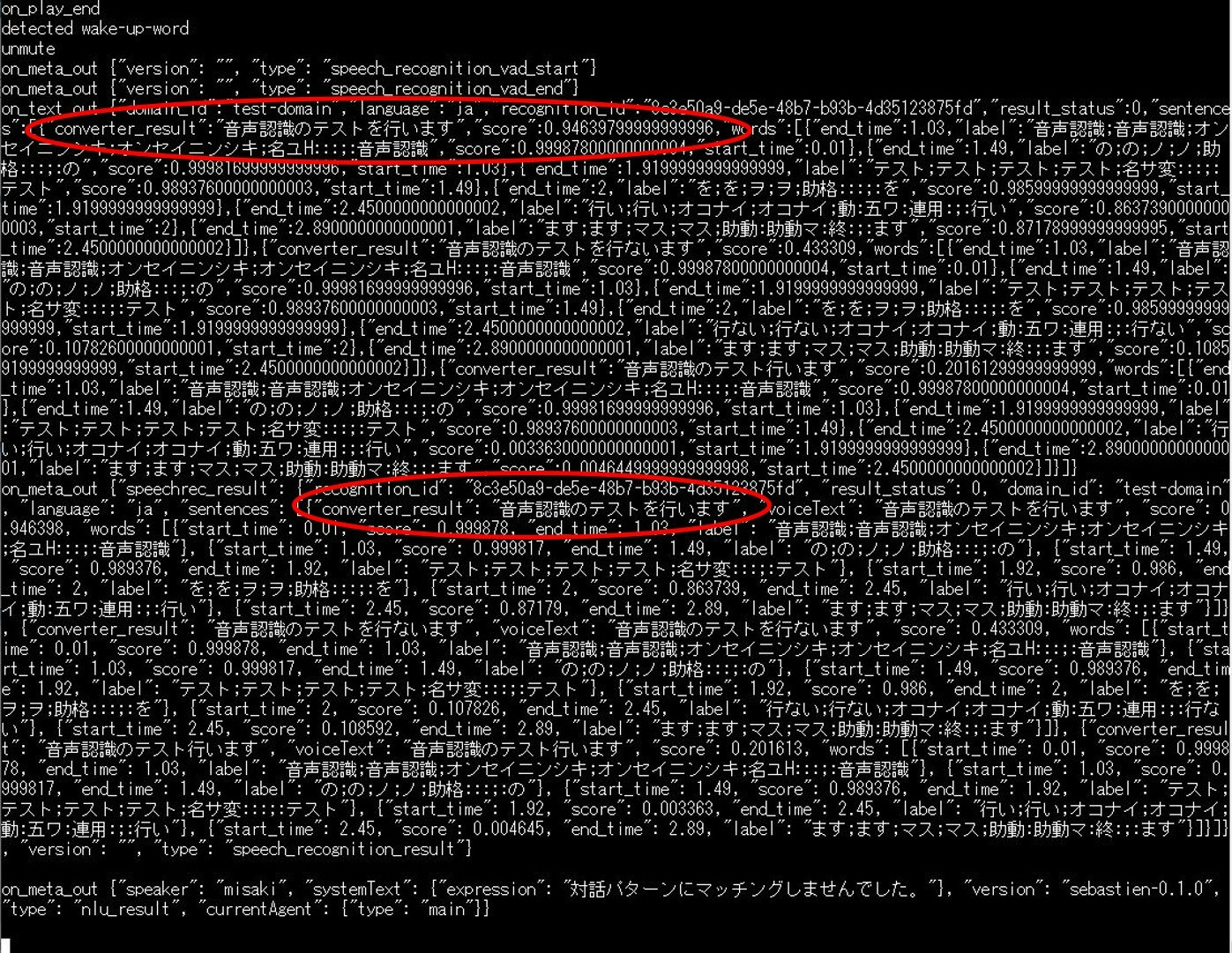
サンプルプログラムの動作は、この繰り返しです。
これでは全く分かりませんが、「生データを返すので、後は勝手にやってくれ」ということでしょうか?
2.認識結果の解析
認識結果文字列の説明が無いので途方に暮れるのですが、気を取り直してよく見るとこれはJson形式であることが分かります。
よって、pythonのjson.dumps()を使って on_text_out()から出力される文字列を整形すると、以下のような構造であるようです。
{
"domain_id": "test-domain",
"language": "ja",
"recognition_id": "7f4dc353-3e89-4f4e-b84d-de25d55ee693",
"result_status": 0,
"sentences": [
{
"converter_result": "音声認識のテストを行います",
"score": 0.983065,
"words": [
{
"end_time": 0.99,
"label": "音声認識;音声認識;オンセイニンシキ;オンセイニンシキ;名ユH:::;:音声認識",
"score": 1,
"start_time": 0.01
},
{
"end_time": 1.43,
"label": "の;の;ノ;ノ;助格:::;:の",
"score": 1,
"start_time": 0.99
},
{
"end_time": 1.83,
"label": "テスト;テスト;テスト;テスト;名サ変:::;:テスト",
"score": 1,
"start_time": 1.43
},
{
"end_time": 1.93,
"label": "を;を;ヲ;ヲ;助格:::;:を",
"score": 0.986903,
"start_time": 1.83
},
{
"end_time": 2.33,
"label": "行い;行い;オコナイ;オコナイ;動:五ワ:連用:;:行い",
"score": 0.877616,
"start_time": 1.93
},
{
"end_time": 2.73,
"label": "ます;ます;マス;マス;助動:助動マ:終:;:ます",
"score": 1,
"start_time": 2.33
}
]
},
{
"converter_result": "音声認識のテストを行ないます",
"score": 0.886866,
"words": [
{
"end_time": 0.99,
"label": "音声認識;音声認識;オンセイニンシキ;オンセイニンシキ;名ユH:::;:音声認識",
"score": 1,
"start_time": 0.01
},
{
"end_time": 1.43,
"label": "の;の;ノ;ノ;助格:::;:の",
"score": 1,
"start_time": 0.99
},
{
"end_time": 1.83,
"label": "テスト;テスト;テスト;テスト;名サ変:::;:テスト",
"score": 1,
"start_time": 1.43
},
{
"end_time": 1.93,
"label": "を;を;ヲ;ヲ;助格:::;:を",
"score": 0.986903,
"start_time": 1.83
},
{
"end_time": 2.33,
"label": "行ない;行ない;オコナイ;オコナイ;動:五ワ:連用:;:行ない",
"score": 0.108024,
"start_time": 1.93
},
{
"end_time": 2.73,
"label": "ます;ます;マス;マス;助動:助動マ:終:;:ます",
"score": 1,
"start_time": 2.33
}
]
},
{
"converter_result": "音声認識のテストをおこないます",
"score": 0.875158,
"words": [
{
"end_time": 0.99,
"label": "音声認識;音声認識;オンセイニンシキ;オンセイニンシキ;名ユH:::;:音声認識",
"score": 1,
"start_time": 0.01
},
{
"end_time": 1.43,
"label": "の;の;ノ;ノ;助格:::;:の",
"score": 1,
"start_time": 0.99
},
{
"end_time": 1.83,
"label": "テスト;テスト;テスト;テスト;名サ変:::;:テスト",
"score": 1,
"start_time": 1.43
},
{
"end_time": 1.93,
"label": "を;を;ヲ;ヲ;助格:::;:を",
"score": 0.986903,
"start_time": 1.83
},
{
"end_time": 2.33,
"label": "おこない;おこない;オコナイ;オコナイ;動:五ワ:連用:;:おこない",
"score": 0.01436,
"start_time": 1.93
},
{
"end_time": 2.73,
"label": "ます;ます;マス;マス;助動:助動マ:終:;:ます",
"score": 1,
"start_time": 2.33
}
]
}
]
}
必要なのは、認識結果ですので"score:"の一番大きな最初の
"converter_result": "音声認識のテストを行います"
を採用することにして、この文字列から取り出すことを考えます。
※後で分かったことですが、認識結果である"converter_result"以外にも非常に重要なデータがあることが分かりました。 ”label:"キーは、認識結果を形態素解析したものと推測します。Part-2・3で認識結果をMecabを使って形態素解析を行い、実際にデバイスを動かすプログラムを提示しますが、"label:"キーの値をそのまま使えば新たに形態素解析を行わなくても済むようです。
(始めたころは、形態素解析などという言葉すら知りませんでしたので・・・)
しかしながら、認識結果に数字が含まれるようなものですと形態素解析を行う前後で何らかの文字列処理が必要になるかと思いますので、やっぱり使えないか??
3.サンプルプログラムの改造
サンプルプログラムでは、Json文字列がダラダラと表示されるだけで、このままでは使えません。応用するには内容の把握が必要となりますので、少し改造して分かりやすい表示を試みます。
細かなテストを繰り返したのですが、最終的には図のように認識結果をアプリケーションに渡す構造としました。
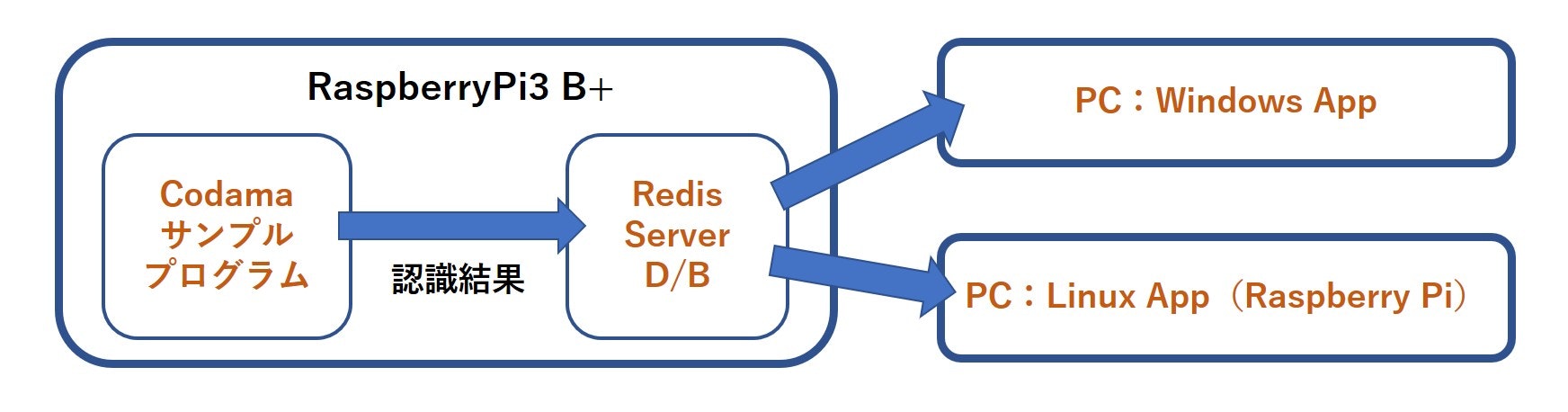
このような構造にした理由は、
- サンプルプログラムにアプリケーションを組込むとデバッグが難しい
- 認識結果をオンメモリで使えるNo SQL/KVS形式のD/BであるRedis経由で渡すことにより、LAN上のPCで結果を取得できる
- 処理の分散が可能となり拡張性が増す
よって、Codamaボードをハットしたラズパイには最低限の改造を加えることで**「音声認識センサー」**として機能させ、ひたすら認識結果をRedis D/Bに出力するだけに専念してもらいます。
■ Redis Serverの導入
ラズパイにRedis Serverをインストールして、ラズパイ上のPythonで動くことを確認しておきます。
インストール方法は、ググれば沢山出てきますので、そちらを参考にしてください。
■ ファイル構成
適当なフォルダを作成し、サンプルプログラムのフォルダから必要なものをコピーしておきます。
- main.py
- sebastien.py
- config.json
- appfunc.py (新しく作ります)
■ main.pyの修正
特に無し
■ sebastien.pyの修正
このプログラムでは、on_text_out()が呼ばれると、認識結果文字列をAppIfFunc() Classに渡します。
# coding:utf-8
・・・(省略)
import speak
from speak import Speak, NluMetaData
# ------------------------
# ハイスコアの認識結果表示とRedis D/Bへの格納用
from appfunc import AppIfFunc # <-- 追加
set_result = None # <-- 追加
# ------------------------
sdk = None
・・・(省略)
def on_text_out( data):
#print ("on_text_out", data) # <-- コメントにする
print ("on_text_out") # <-- 追加
# ------------------------
# ハイスコアの認識結果の解析とRedis D/Bへの格納
global set_result # <-- 追加
set_result.store_result( data) # <-- 追加
# ------------------------
return
def on_meta_out(data):
#print ("on_meta_out", data) # <-- コメントにする
print ("on_meta_out") # <-- 追加
return
・・・(省略)
def init( configname=None):
・・・(省略)
# コールバック先の設定
sdk.set_on_meta_out(on_meta_out)
・・・(省略)
sdk.set_on_play_end(on_play_end)
# ------------------------
# 認識結果表示のインスタンス
global set_result # <-- 追加
set_result = AppIfFunc() # <-- 追加
# ------------------------
■ appfunc.pyの追加
Redis D/Bに認識結果を書き込むための AppIFFunc Class を新たに追加する。
動作としては、受け取った認識結果文字列から、ハイスコアの「"converter_result"」キーの値を音声認識結果として、識別子(「"Rec_id"」キー:値は乱数)と供にRedis D/Bに格納します。
# coding:utf-8
import os
import json
import redis
#
# Codamaボードをハットしたラズパイは1つの「音声認識センサー」と考える。
# よって、音声認識結果をRedis D/Bに格納することにより、LAN上のPCで
# 取得可能となる。
#
# Redis ServerのIPアドレス
hostname = '192.168.xxx.xxx'
# ------------------------
# 認識結果のRedisへの格納と表示
#
# Codamaの認識結果は、on_meta_out()で出力される文字列からでも得られるが
# on_meta_out()は複数回出力されるので、1回しか出力されないon_text_out()のものを採用
#
class AppIfFunc():
def __init__( self):
self.result = None
pool = redis.ConnectionPool( host = hostname, port = 6379, db = 0)
self._r = redis.StrictRedis( connection_pool = pool)
self._r.flushall()
def store_result( self, data):
dicjson = json.loads( data)
#print( "Type : data=%s dicjson=%s" % (type(data), type(dicjson)))
# 「on_text_out()」から出力される文字列から抽出
if "sentences" in dicjson:
self.result = dicjson[ "sentences"][0][ "converter_result"]
# Redis D/Bへの登録
# 認識結果
self._r.set( "Result", self.result)
# 識別フラグ(128Bit 乱数)
self._r.set( "Rec_id", os.urandom( 4))
print( "Result : " + self.result)
# 値を初期化して、次の認識結果に備える
self.result = None
# --------------------
■ Windows PC で認識結果を取得してCSVファイルを作成する
別にWindowsで無くても構いませんが、LAN上のPCで認識結果の表示及びCSVファイルの作成を行います。
- pythonが動作する環境を構築します
- Redis Serverをインストールしpython上で動くことを確認しておきます
インストール方法は、ググってください。
(多少、ハマってもハマるのを楽しむつもりでお願いします・・・)
私の場合は、Anacondaをインストールすると使えるようになるSpyderというIDEを使用しています。
適当なフォルダを作成して以下のプログラムを保存します。
動作としては、更新フラグを見て認識結果を表示して配列に格納しているだけです。
Control-Cで終了すると「codama.csv」というファイルが作成されます。
# -*- coding: utf-8 -*-
import redis
import csv
hostname = '192.168.xxx.xxx' # <-- Codama(ラズパイ)のIPアドレス
# r = redis.StrictRedis( host = hostname, port = 6379, db = 0)
pool = redis.ConnectionPool( host = hostname, port = 6379, db = 0)
r = redis.StrictRedis( connection_pool = pool)
prec_id = None
rec_data = []
print( "「Codama」ボードによる認識結果 :\n")
try:
while True:
if r.exists( "Rec_id"):
rec_id = r.get( "Rec_id")
# 更新されたか?
if rec_id != prec_id:
# byte型を文字列型に変換
result = r.get( "Result").decode( 'utf-8')
# 認識結果表示
print( "Result : ", result)
# 認識結果の作成(writerrowsを使うために配列の中に配列を作る)
rec_data.append( [result])
prec_id = rec_id
# --------
# ---------
# ---------
except KeyboardInterrupt:
with open( "codama.csv", "w") as f:
writer = csv.writer( f, lineterminator='\n')
writer.writerows( rec_data)
print( "\n認識結果を codama.csv で保存しました。")
■ 起動方法
ラズパイ及びWindowsで作成したそれぞれのフォルダに移動して、以下のプログラムを起動します。
| ラズパイ側 | Windows側 |
|---|---|
| main.py | codama_result.py |
ウェイク・アップ・ワードを認識すると音声認識処理を開始され、認識結果が表示されます。
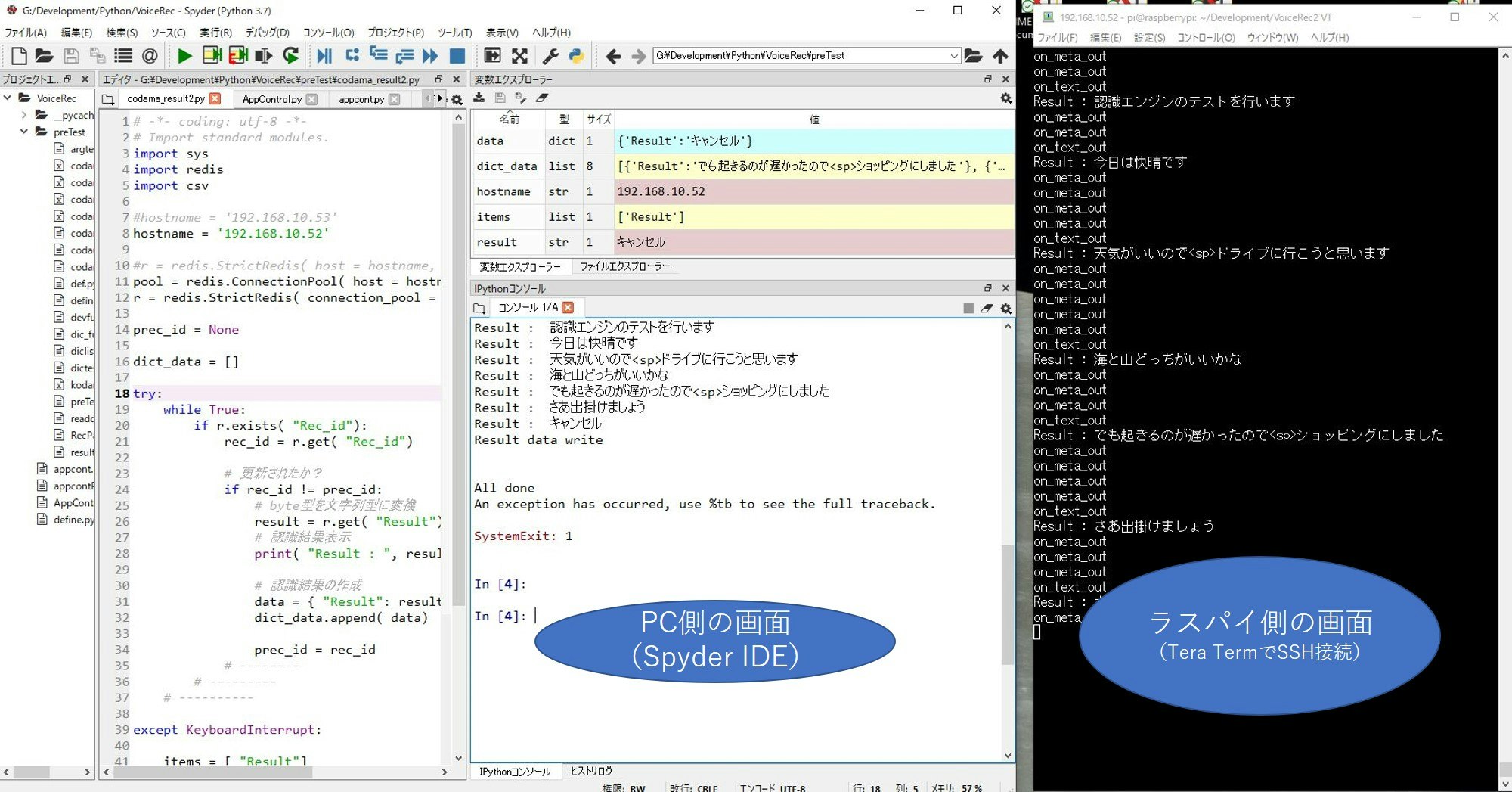
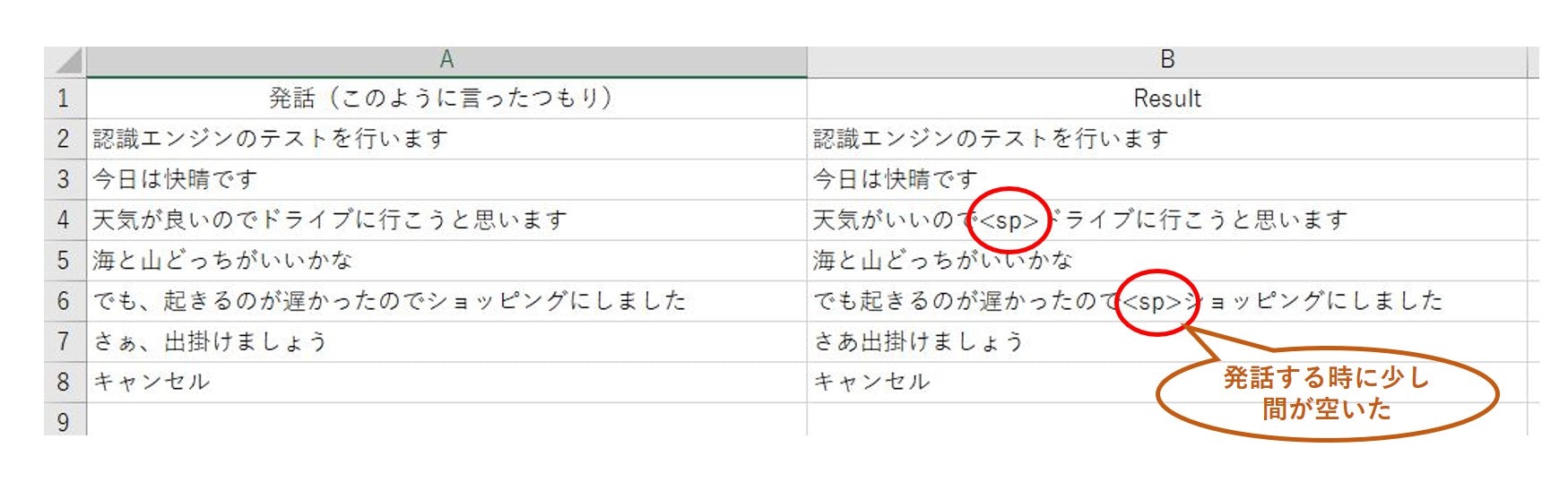
■ 発話内容と認識結果例
発話内容(言ったつもり)と認識結果(codama.CSV)との比較です。
■ Part-1のまとめ
今回の実験機の製作目的は「Codama」ボードによる音声認識が使えそうかどうかを判断するものです。
- 認識結果は、もちろん周囲環境(部屋の大きさや構造、周囲騒音、マイクとの距離など)に影響を受けるかと思いますが私のような「だみ声」でも発話をはっきり行えば、そこそこの認識力と評価しました。
- 実験環境を整備しただけなので性能評価(周囲環境の影響など)や応用アプリケーションに関しては、これからかな?
- 反応が鈍いのは認識エンジンがローカルに無いからで、現在の4Gのネットワーク環境では仕方が無いのかもしれません。 5Gになればリアルタイム性が期待できるかも??
- 「Codama」ボードは、一言でいうと「音声認識サービスが利用できる高性能マイク」かな?
Part-2では、声によるWindowsアプリケーションの自動起動を行ってみたいと思います。