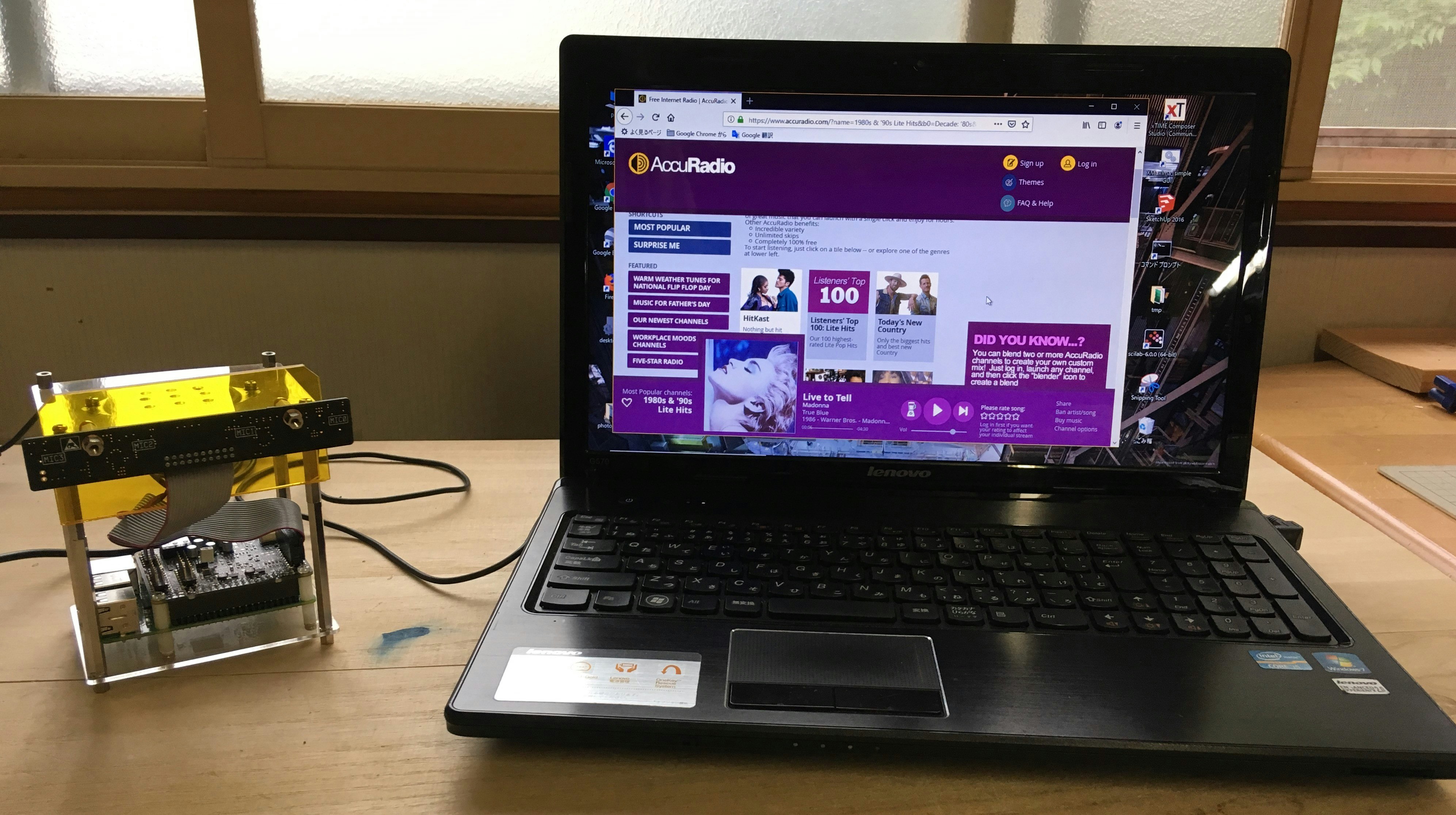
Part-1では、サンプルプログラムの動作確認と改造を行い、LAN上の他のPCから認識結果を得る方法を考えました。
Part-2では、得られた認識結果をMecabを使って形態素解析を行い、Windowsアプリケーションの自動起動を考えます。
■ 発話により何かを動かす原理を考える
■ 辞書の仕様
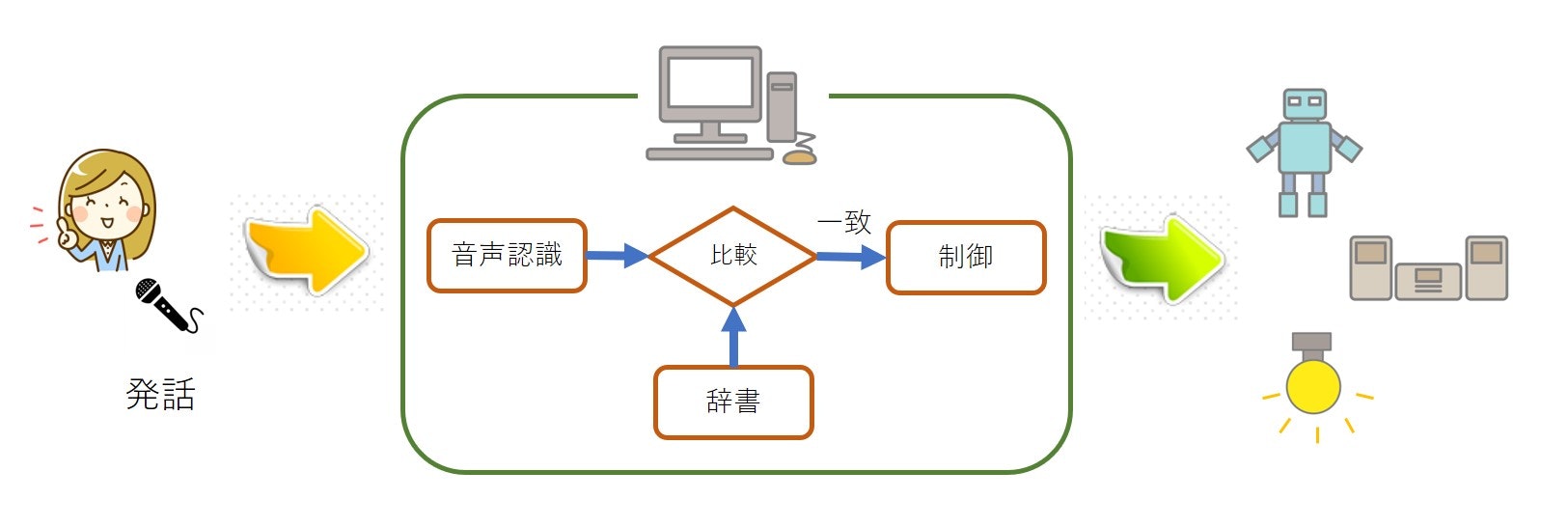
発話(アナログ)した内容が音声認識され、得られた文字列(デジタル)が、予め用意した制御対象の辞書内容と一致すれば、動作可能なように思えます。
そこで、以下のような辞書を用意することにしました。
Pat_dic = [
{ "Keyword": 比較文字列, "Func": 動作関数, "Arg": パラメータ}
]
動作としては、認識結果文字列と辞書内の「Keyword」で定義した「比較文字列」と一致すれば、「Func」の「動作関数」が「Arg」のパラメータと供に呼び出されというものです。
具体的には、「青のLEDを点灯させる」ことを考えた場合、辞書を以下のように定義します。
Pat_dic = [
{ "Keyword": '青のLEDを点けてください', "Func": blue_led, "Arg": ON}
]
発話内容が辞書の「Keyword」と一致すれば、blue_led()がパラメータ「ON」と供に呼び出されます。
しかしながら、これだと目的の動作をさせるのに、複数の発話内容が存在しますし、認識結果にノイズが混じる場合があり現実的ではありません。(語尾が欠けたり、助詞が異なったり・・・)
- 発話 : 青のLEDを点けてください
- 発話 : 青いLEDを点けて
- 発話 : LEDの青を点けやがれー
- ・・・・
■ 形態素解析
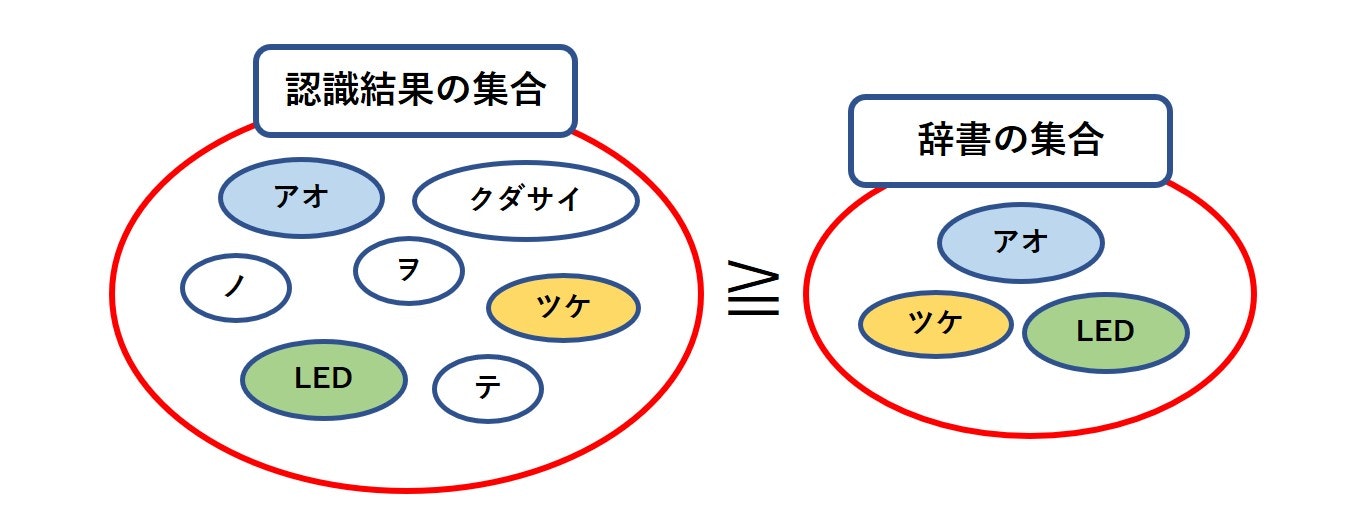
上記の例ですと、認識結果文字列に「青」又は「青い」・「LED」・「点け」の文字が含まれていることが確認できれば要件を満たします。
このように、文字列をバラバラに分解していくれる処理を「形態素解析」と言われているようで、自然言語処理の前処理としては古くからある手法だそうです。
そこで、形態素解析の有名なモジュールである「MeCab」を用いると以下のようになります。
MeCab.Tagger()
青 名詞,一般,*,*,*,*,青,アオ,アオ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
LED 名詞,一般,*,*,*,*,*
を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ
点け 動詞,自立,*,*,五段・カ行イ音便,命令e,点く,ツケ,ツケ
て 助詞,接続助詞,*,*,*,*,て,テ,テ
ください 動詞,非自立,*,*,五段・ラ行特殊,命令i,くださる,クダサイ,クダサイ
EOS
オプションの「wakati」を指定すると、スペースで区切った文字列が出力されます。
MeCab.Tagger(“-Owakati”)
青 の LED を 点け て ください
辞書を再検討します。
Pat_dic = [
{ "Keyword": ['青','LED','点け'], "Func": blue_led, "Arg": ON},
{ "Keyword": ['青い','LED','点け'], "Func": blue_led, "Arg": ON}
]
※ 「青」と「青い」は名詞と形容詞の違いなので、一緒にはなりません。
これで動作精度はかなり向上しますが、まだ問題があります。
それは、認識結果が「点ける」や「つける」と返される場合があるからです。(辞書が大きくなる)
これを避けるためには、辞書のKeywordを「カタカナ」で定義します。
MeCabには「chasen」というオプションがあるので、読みであるカタカナ部分を採用することにします。
MeCab.Tagger(“-Ochasen”)
青 アオ 青 名詞-一般
の ノ の 助詞-連体化
LED LED LED 名詞-一般
を ヲ を 助詞-格助詞-一般
点け ツケ 点く 動詞-自立 五段・カ行イ音便 命令e
て テ て 助詞-接続助詞
ください クダサイ くださる 動詞-非自立 五段・ラ行特殊 命令i
EOS
辞書の再再検討をします。
Pat_dic = [
{ "Keyword": ['アオ','LED','ツケ'], "Func": blue_led, "Arg": ON},
{ "Keyword": ['アオイ','LED','ツケ'], "Func": blue_led, "Arg": ON}
]
■ 認識結果と辞書の内容の比較方法
MeCabから出力される文字列は、各要素をタブと改行コードで区切られた1つの文字列です。
よって、以下の手順で認識結果と辞書の内容との比較を行います。
- 得られた認識文字列をMeCab(chasen)で処理する。
- タブと改行コードを頼りに2次元配列を作る。
- 配列の2番目がカタカナの読みであるので、それを取出して1次元配列にする。
- 辞書の「Keyword」の要素を1次元配列にする。
- それぞれの配列を集合に変換する。
- 集合演算で包含関係を調べる。
Pythonは集合演算が使えるので便利ですね!
■ 音声によるWindowsアプリケーションの起動
以上の原理の考察を踏まえて、具体的なデバイスの自動起動を考えます。
まずは、半田付けが不要な、発話によるWindowsアプリケーションの自動起動を検討します。
■ 新たなモジュールの追加
- MeCab
- selenium (Chromeの自動操作)
※seleniumは、Chromeで表示した特定サイト内の操作を自動化するもので、サイト内検索や特定ボタンを押すなどプログラムから制御できるドライバです。
よって、単にアプリケーションを立ちあげることを確認するだけなら必要ありません。
どちらもインストール後に簡単なプログラムを作成し、Windows上のPythonで動作確認しておきます。
(多少ハマるかも?? ググって下さい。)
■ 作成したログラム
- define.py
- appcont.py
- AppControl.py
ここでは、発話により以下のアプリケーションを起動することにします。
| アプリケーション | 発話例 | 辞書の要素 |
|---|---|---|
| Excel | "エクセル立ちあげて" | 「Excel」「タチ」「アゲ」 |
| Word | "ワード起動して" | 「ワード」「キドウ」 |
| Browser | "ブラウザ立ちあげて" | 「ブラウザ」「タチ」「アゲ」 |
| AccuRadio | "ミュージック・スタート" | 「ミュージック」「スタート」 |
※ 「AccuRadio」は、私が毎日BGMで利用しているインターネットラジオサイトです。
■ define.py
定数を定義するのにpythonではやりにくいですね!!
C言語みたいな#define文が使えないのでファイルが分かれる場合、同じ定数をファイル毎に変数定義しなければなりません。 仕方が無いので、以下のような定数クラス作り、定義したファイルを使っています。
もっと良い方法があればと思います。
※ 各アプリケーションのインストール場所(PATH)は使用する環境に依存しますので、予め調べておきます。
# -*- coding: utf-8 -*-
# -------------------------------------
# 定数の定義
# 使い方:
# from define import Const
# c = Const() : 最初の方で記述する
# -------------------------------------
class Const:
# ---------------------
# Redis Server address
HOSTNAME = '192.168.xxx.xxx' # ラズパイ(Codama)のIPアドレス
# ---------------------
# Windows Application : Excel/Word/Browser
#
EXCEL_PATH = r'C:\Program Files (x86)\Microsoft Office\root\Office16\EXCEL.EXE'
WORD_PATH = r'C:\Program Files (x86)\Microsoft Office\root\Office16\WINWORD.EXE'
CHROME_PATH = r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe'
CHROME_DRV_PATH = r'C:\Tools\Driver\chromedriver.exe'
# ---------------------
■ AppControl.py
Redis D/Bから取得した認識結果を形態素解析して、辞書の要素と比較して一致したら実際に起動する関数を呼び出します。
辞書に登録する単語要素の決め方は、ページの最後に書きました「■ 補足説明」のツールを使うなりして登録します。
# !/usr/bin/python
# -*- coding: utf-8 -*-
#
# 音声によるWindowsアプリケーションの起動
#
import MeCab
import redis
from define import Const
from appcont import AppControl
# ------------------
# 定数の定義クラス
# ------------------
c = Const()
# ------------------
# アプリケーションコントロールクラス
# ------------------
app = AppControl()
# ------------------
# MeCab
# ------------------
mcab = MeCab.Tagger("-Ochasen") # 認識結果をカタカナで使いたいため
# ------------------
# コールバックの実行
# ------------------
def handler( func, *args):
return func( *args)
# ------------------
# Redis
# ------------------
pool = redis.ConnectionPool( host = c.HOSTNAME, port = 6379, db = 0)
r = redis.StrictRedis( connection_pool = pool)
prec_id = None
# ------------------
# 認識パターン辞書
# ------------------
Pat_dic = [
{ "Keyword": [ 'Excel', 'タチ', 'アゲ'], "Func": app.exec_excel},
{ "Keyword": [ 'ワード', 'タチ', 'アゲ'], "Func": app.exec_word},
{ "Keyword": [ 'ブラウザ', 'タチ', 'アゲ'], "Func": app.exec_chrome},
{ "Keyword": [ 'ミュージック', 'スタート'], "Func": app.exec_1980_LiteHits_channel}
]
# ------------------
# 認識パターンの検索
# ------------------
def find_action( ss):
mcab.parse( '') #空でパースする必要がある
chasenText = mcab.parse( ss)
chasenList = chasenText.split( '\n')
# カタカナの読みリスト作成
# カタカナにすることにより、変換ノイズを除去 (例:「上げる/揚げる/あげる」など)
yomi = []
for ll in chasenList:
parts = ll.split( '\t')
# 2番目が「カタカナの読み」
if ( len( parts) > 1) and ( parts[ 0] != "EOS"):
yomi.append( parts[ 1])
# 認識文字列のchasen配列を集合に変換
yomi_set = set( yomi)
for x in Pat_dic:
# Keyword配列を集合に変換
pat_set = set( x[ "Keyword"])
# Keywordが認識結果に含まれるか?(部分集合か?)
if pat_set <= yomi_set:
handler( x[ 'Func'])
break;
# ------------------
# 音声認識入力によるデバイス制御
# ------------------
try:
print( "App Voice controll start !!")
while True:
if r.exists( "Rec_id"):
rec_id = r.get( "Rec_id")
if rec_id != prec_id:
rst = r.get( "Result")
if rst is not None:
# byte型を文字列型に変換
result = rst.decode( 'utf-8')
# デバイス制御の検索と実行
find_action( result)
prec_id = rec_id
# --------
# --------
# ---------
except KeyboardInterrupt:
pass
■ appcont.py
実際のアプリケーション起動は、subprocess()を使っています。
但し、exec_1980_LiteHits_channel()は、AccuRadioの「1980s & '90s Lite Hits」チャンネルの自動起動で、chrome専用の selenium のWebdriverを使って起動後にそのチャンネルのボタンを探して押す動作を行います。
最大の難関は、ごちゃごちゃのHTMLソースコードからボタンの場所(XPATH)を探すことかな?
コツを掴むのに時間がかかります。
もっとも、Web サイトの構成が変更になれば使えませんが・・・
# !/usr/bin/python
# -*- coding: utf-8 -*-
from __future__ import division
import time
import subprocess
from selenium import webdriver
from define import Const
# 定数の定義
c = Const()
# アプリケーションの起動
class AppControl:
def __init__( self):
pass
def exec_excel( self):
subprocess.Popen( c.EXCEL_PATH)
time.sleep( 0.5)
def exec_word( self):
subprocess.Popen( c.WORD_PATH)
time.sleep( 0.5)
def exec_chrome( self):
subprocess.Popen( c.CHROME_PATH)
time.sleep( 0.5)
def exec_1980_LiteHits_channel( self):
driver = webdriver.Chrome( executable_path = c.CHROME_DRV_PATH)
driver.get( 'https://www.accuradio.com/')
time.sleep(2)
element = driver.find_element_by_xpath( "//*[@id='navRightColContent']/div[7]/a")
element.click()
■ プログラムの実行
- 「Codama」をハットしたラズパイでPart-1で作成した認識プログラムを起動します。「main.py」
- PC側で「AppControl.py」を起動します。
ウェイク・アップ・ワードを発話して音声認識処理を起動し、
「ワードを立ち上げるのじゃ」
などと喋って下さい。
■ Part-2のまとめ
- 今回のやり方が良いのかどうか分からないが、制御対象を限定すれば案外簡単に音声認識結果を利用できた。
- 認識結果をMeCab(chasen)で形態素解析することにより、多少認識結果にノイズが混じっていても動作精度を向上させることが可能である。
- Part-1のまとめでも述べたが、反応が多少鈍いのは5Gの登場を待たなければならないのか?
Part-3では、定番のLED及びサーボモータを発話により動かしてみるが、基本的なプログラム構造は今回のものと同じで、異なるのは辞書と動作プログラムの内容である。
■ 補足説明
発話により同じ自動動作をさせるにも、複数の発話方法や認識結果にノイズが混じることもあります。それらを全て辞書に登録するのは現実的ではありませんので、動作に必要な共通の単語を決める必要があります。
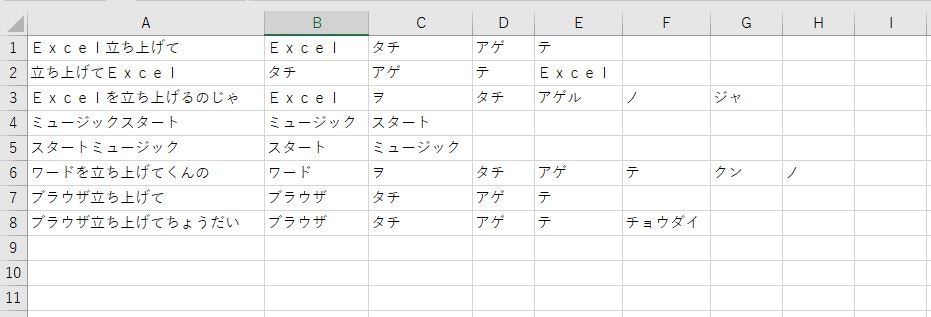
下記のプログラムは、上記の「AppControl.py」を多少改造して、MeCab(chasen)で形態素解析したカタカナリストと認識文字列をCSVで書き出すようにしただけのものですが、こうゆうものを利用して共通の単語を決めたら良いかと思います。
■ 出力例
辞書に追加する単語は、下の例でも分かるように発話の仕方により「アゲ」だけでは無く「アゲル」も必要なようです。
■ make_dic_tool.py
# -*- coding: utf-8 -*-
#
# 辞書作成補助ツール
#
import MeCab
import redis
import csv
# ------------------
# MeCab
# ------------------
mcab = MeCab.Tagger("-Ochasen") # 認識結果をカタカナで使いたいため
# ------------------
# Redis
# ------------------
HOSTNAME = '192.168.xxx.xxx'
pool = redis.ConnectionPool( host = HOSTNAME, port = 6379, db = 0)
r = redis.StrictRedis( connection_pool = pool)
prec_id = None
dic_list = []
# ------------------
# 認識パターンの検索
# ------------------
def make_dic_list( ss):
mcab.parse( '') #空でパースする
chasenText = mcab.parse( ss)
chasenList = chasenText.split( '\n')
# カタカナの読みリスト作成
# カタカナにすることにより、変換ノイズを除去 (例:「上げる/揚げる/あげる」など)
yomi = []
for ll in chasenList:
parts = ll.split( '\t')
# 2番目が「カタカナの読み」
if ( len( parts) > 1) and ( parts[ 0] != "EOS"):
yomi.append( parts[ 1])
print( "認識文字: ", ss)
print( 'カタカナ読み: ', yomi, "\n")
yomi.insert( 0, ss)
dic_list.append( yomi)
# ------------------
# 音声認識入力
# ------------------
try:
print( "辞書作成補助ツール 開始 !!")
while True:
if r.exists( "Rec_id"):
rec_id = r.get( "Rec_id")
if rec_id != prec_id:
rst = r.get( "Result")
if rst is not None:
# byte型を文字列型に変換
result = rst.decode( 'utf-8')
# デバイス制御の検索と実行
make_dic_list( result)
prec_id = rec_id
# --------
# --------
# ---------
# ----------
except KeyboardInterrupt:
with open( "dic_tool.csv", "w") as f:
writer = csv.writer( f, lineterminator='\n')
writer.writerows( dic_list)
print( "CSVで保存しました")