前書き
ユニットテスト(特に自動的に行ってくれるテスト)は、継続的にコーディングを行っていく上では欠かせないものです。各言語でユニットテストを書くためのツールやライブラリがあり、大抵ワンコマンドを叩くだけで結果が得られるように出来ていると思います(そうでないものもあるかも?)。ユニットテストがあると無いとでは、開発体験が大きく変わってくるはずです。
ユニットテストが無いと
ユニットテストが無いと、プログラムを起動させ、手動で動作確認を行うことになります。開発が初期の頃はプログラムが行えることは限られており、パターンも把握できるほど少なく、実際の動作を確認できている安心感もあってそれで満足するでしょう。しかし開発を進めていくとパターンが増え、テストするための前提条件が増え、確認を見落とすレアケースも現れ、手動でテストすることが億劫になってくるはずです。そうなってくると、ステージング環境にアップされて総合的なテストを行う段階で次々バグが見つかり…という未来が待っています。
ユニットテストを書くために
よく「実装は疎結合に」や「責務を明確に」という指針が示されますが、これらは「ユニットテストを書きやすくするため」にも非常に大事です。むしろユニットテストを書くためにこういったことが意識されるようになったとも思えるほどです。
「DB接続部分は隠ぺいして、MySQLでもPostgreSQLでも問題無いように…」という疎結合の例がありますが、実際にMySQLで組まれていたものが途中からPostgreSQLに変わるなんていう事はほとんど無いはずなので、DB接続部分を隠ぺいする意義が今一つピンと来ません。しかしユニットテストを書く段になるとDB接続部分を隠ぺいすることがとてもありがたく思えます。DB接続部分を隠ぺいしないと、テスト用のDBを構築して、そちらに接続先を書き換える、ということをテストの度に行うことになるからです(接続先の書き換えを忘れると、テスト用でないDBを書き換えてしまって大惨事になりかねません)。つまり先ほどの文言は「DB接続部分は隠ぺいして、MySQLでもPostgreSQLでもテスト用のDBモックでも問題無いように…」と言い換えるのが良いでしょう。
個人的な体験ですが、様々なプログラミング的な知識に触れ始めた頃は「一体どんな場面で役に立つの?」という疑問しか持てず終わることが多かったのですが、ユニットテストを書き始めると、多くのことが意味を持つように見えるようになったと思います。
やってはいけないこと
ユニットテストの期待値を実装の挙動に従わせてはいけません。言い換えると、「今の挙動がこうだから」という理由で期待値を決めてはいけません。ユニットテストは実装を仕様・設計の観点から試験するものであるべきです(仕様に誤りがある場合はどうでしょう。それはユニットテストのカバーする範囲ではありません。ウォークスルー等の疑似体験によって試験されるものです)。
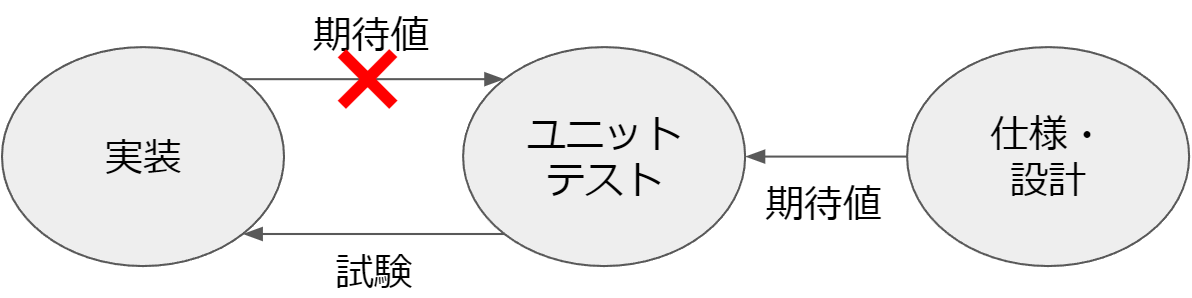
より良いユニットテストに
以下のようなユニットテストがあるとします。
actual = fnc(true, true, 1)
if (actual != true) {
assert("funcの結果が違います 期待値:true, 返り値:%b", actual)
}
3つの引数をfncという関数に与えた結果をtrueと比較し、一致しているかというテストになります。引数はワンパターンだけという事は無く、複数のパターンを取りうると思います。例えば引数の取りうる値として
| 第一引数 | 第二引数 | 第三引数 | 戻り値 |
|---|---|---|---|
| true | true | 1 | true |
| false | true | 1 | true |
| true | false | 1 | true |
| false | false | 1 | false |
| true | true | 2 | true |
| false | true | 2 | true |
| true | false | 2 | false |
| false | false | 2 | false |
という事が事前にわかっているとします。引数がわかれば、その戻り値も仕様から導き出されます(あるいは相談して決めます)。今回は2パターンの値を取る変数が3つで8つのケースがあります。これを網羅するユニットテストを書けば、もうfncについては恐れることは無いはずです。
actual1 = fnc(true, true, 1)
if (actual1 != true) {
assert("funcの結果が違います 期待値:true, 返り値:%b", actual1)
}
actual2 = fnc(false, true, 1)
if (actual2 != true) {
assert("funcの結果が違います 期待値:true, 返り値:%b", actual2)
}
actual3 = fnc(true, false, 1)
if (actual3 != true) {
assert("funcの結果が違います 期待値:true, 返り値:%b", actual3)
}
actual4 = fnc(false, false, 1)
if (actual4 != false) {
assert("funcの結果が違います 期待値:false, 返り値:%b", actual4)
}
actual5 = fnc(true, true, 2)
if (actual5 != true) {
assert("funcの結果が違います 期待値:true, 返り値:%b", actual5)
}
actual6 = fnc(false, true, 2)
if (actual6 != true) {
assert("funcの結果が違います 期待値:true, 返り値:%b", actual6)
}
actual7 = fnc(true, false, 2)
if (actual7 != false) {
assert("funcの結果が違います 期待値:false, 返り値:%b", actual7)
}
actual8 = fnc(false, false, 2)
if (actual8 != false) {
assert("funcの結果が違います 期待値:false, 返り値:%b", actual8)
}
という事で網羅しましたが、1つのテストケースに4行使っています。これはまだ単純なテストなので4行で済んでいますが、1つのテストケースを増やす事に掛けるコストはなるべく小さくすることを心掛けるのが良いでしょう。そうしないと、すぐにユニットテストは行数が爆発的に増え、後から読む人にとって苦痛なものになってしまいます。新たなテストケースを後から追加することに対しても尻込みしてしまうでしょう。
メンテしやすいテストに
まずは単純に重複を取り除きます。
sub(true, true, 1, true)
sub(false, true, 1, true)
sub(true, false, 1, true)
sub(false, false, 1, false)
sub(true, true, 2, true)
sub(false, true, 2, true)
sub(true, false, 2, false)
sub(false, false, 2, false)
func sub(input1, input2, input3, expected) {
actual = fnc(input1, input2, input3)
if (actual != expected) {
assert("funcの結果が違います 期待値:%d, 返り値:%d", expected, actual)
}
}
これも確かに重複を取り除いていますが、もう一つの方法があります。
testCases = [
{input1: true, input2: true, input3: 1, expected: true},
{input1: false, input2: true, input3: 1, expected: true},
{input1: true, input2: false, input3: 1, expected: true},
{input1: false, input2: false, input3: 1, expected: false},
{input1: true, input2: true, input3: 2, expected: true},
{input1: false, input2: true, input3: 2, expected: true},
{input1: true, input2: false, input3: 2, expected: false},
{input1: false, input2: false, input3: 2, expected: false},
]
foreach tc in testCases {
actual = fnc(tc.input1, tc.input2, tc.input3)
if (actual != tc.expected) {
assert("funcの結果が違います 期待値:%d, 返り値:%d", tc.expected, actual)
}
}
テストケースを配列の1要素にまで落とし込む事が出来ました。テストケースを増やすコストは配列の要素を増やすというレベルに出来ており、こうなるともうテストケースが新たに増えても恐れることは無いはずです(配列の行を追加するだけなので)。
ロジックとパラメータを分離出来ているのも、メンテのしやすさにつながっていると思います。
読めるテストに
ユニットテストを読めるようにしていきます。ユニットテストを読めるようにしていって何が嬉しいかと言うと、何がテストされているかが分かるというのはもちろん、何が実装されていてどういう動きをするのかが見えてくるようになります。新しくプロジェクトに参入する人に「ここは〇〇というメソッドが使えます。使い方はユニットテストを見てください」という情報伝達が可能です。きっと別に用意されたドキュメントに目を通すより、同じ言語で書かれ、様々な実装パターンが用意されているユニットテストを見る方がずっと得るものが多いはずです。もしその人から「△△の場合はどうなりますか」という質問が出た場合、それは漏れているテストケースという事になります。追加を検討しましょう。
テストメソッドの命名
まずはユニットテストそのものに名前を付けます。大抵はユニットテストを定義したメソッド名を、テスト対象のメソッドにすることで、何のテストかはわかるようになるでしょう。
func TestLoginCheck() ...
もしテスト対象のメソッド名を見ても今一つよくわからないテスト名になってしまう場合、それはテスト対象メソッドの命名、もしくはメソッドとしての切り方が良くないという事になります。責務が明確なメソッドに適切な命名が出来ていれば、自ずとわかりやすいテストの命名ができるはずです。
テストケースの命名
次に各テストケースに名前を付けます。testCasesの行の中にnameという要素を増やし、これをテストケースの名前とします。与えるパラメータをそのまま説明するような名前よりは、ユースケースで説明できると良いです。
testCases = [
{name: "第一引数にtrue、第二引数にtrue、第三引数に1を与えるケース", input1: true, input2: true, input3: 1, expected: true},
...
]
testCases = [
{name: "有料ユーザーが許諾チェックを有効にしつつ1つ目のボタンを押したケース", input1: true, input2: true, input3: 1, expected: true},
...
]
このnameを、失敗時のメッセージに出すようにすれば、どういうケースで失敗したかがわかるようになります。
...
if (actual != tc.expected) {
assert("%s: funcの結果が違います 期待値:%d, 返り値:%d", tc.name, tc.expected, actual)
}
テストパラメータの命名
最後に、テストケースの各パラメータもinput~よりも良い命名にします。
testCases = [
{name: "有料ユーザーが許諾チェックを有効にしつつ1つ目のボタンを押したケース", isPaid: true, isAccept: true, buttonNum: 1, expected: true},
...
]
これらでずっと読みやすいテストになったと思います。
もしユニットテスト自体が膨大なコード量や、膨大なテストケースになってしまう場合、それは一つのメソッドにたくさんのことをさせすぎているサインなので、分割を検討しましょう。ユニットテストの健全性は、テスト対象の健全性につながります。
まとめ
ユニットテストが問題無く実装されていれば、それによって現在の実装は担保され、またこれから起こるであろう変更や機能追加についても守ってくれるはずです。プロジェクトの人員の入れ替わりが起こったとしても、ユニットテストを読めばコードが何を期待されて実装されているかがわかり、知見は引き継いでいけるはずです。
ユニットテスト、書きたくなったでしょうか?