原論文
- CvT: Introducing Convolutions to Vision Transformers
https://arxiv.org/abs/2103.15808
日本語解説
- Transformerに畳み込みを!新たに誕生した画像認識モデルCvTを解説!
https://qiita.com/omiita/items/01687855d7891bcf5fed
関連研究
Vison Transformerの解説
https://qiita.com/wakanomi/items/55bba80338615c7cce73
CNN+ViTモデルの傾向【サーベイ】
https://qiita.com/wakayama_90b/items/96bf5d32b09cb0041c39
結論
ViTの構造にパッチ特徴量と,クエリ,キー,バリューの変換(キー,バリューはストライド2)を線形射影から畳み込みに変更する.計算量の削減と位置埋め込みが要らなくなる.
概要
画像認識分野のViTは爆発的な人気を誇り,その派生モデルは多く発表されている.しかし,ViTが持つ問題点はいくつかある.主に,計算量が膨大であることと,大規模なデータセットで学習しなければ精度が向上しない.この問題点を解決するためにViTの構造に畳み込み処理を加えて解決する.具体的には,ViTの最初に行われる処理であるパッチ特徴量変換を畳み込み処理で行い.SAの処理の計算量を削減するために,キーとバリューを畳み込み処理で出雲サンプリングする(SAの出力はクエリの特徴マップサイズに依存するため,キーとバリューの特徴マップのサイズが小さくても出力の特徴マップサイズは変わらない).
モデル構造
階層型の3ステージで構成されており,他研究ResNet,Swin傾向と同様に,ステージ3を深く設定する.また,ステージ3にだけクラストークンを追加する.ステージ3で追加したクラストークンを用いてMLPに入力して識別器とする.また,ステージ間のダウンサンプリングには$3 \times 3$のストライド2の畳み込みを採用する.また,最初の処理として$7 \times 7$のストライド4で畳み込みを行う.
ViTの特性として,浅い層では局所的な認識,深い層で大局的な認識を好む傾向であり,本来,大局的な認識を得意とするViTは局所的な認識での有効性が低いため,浅い層(最初の処理)で局所的な認識を得意とする畳み込み処理を導入することでViTの弱点を補完する.また,最初に畳み込み処理でダウンサンプリングすることで,計算量の削減につながる.
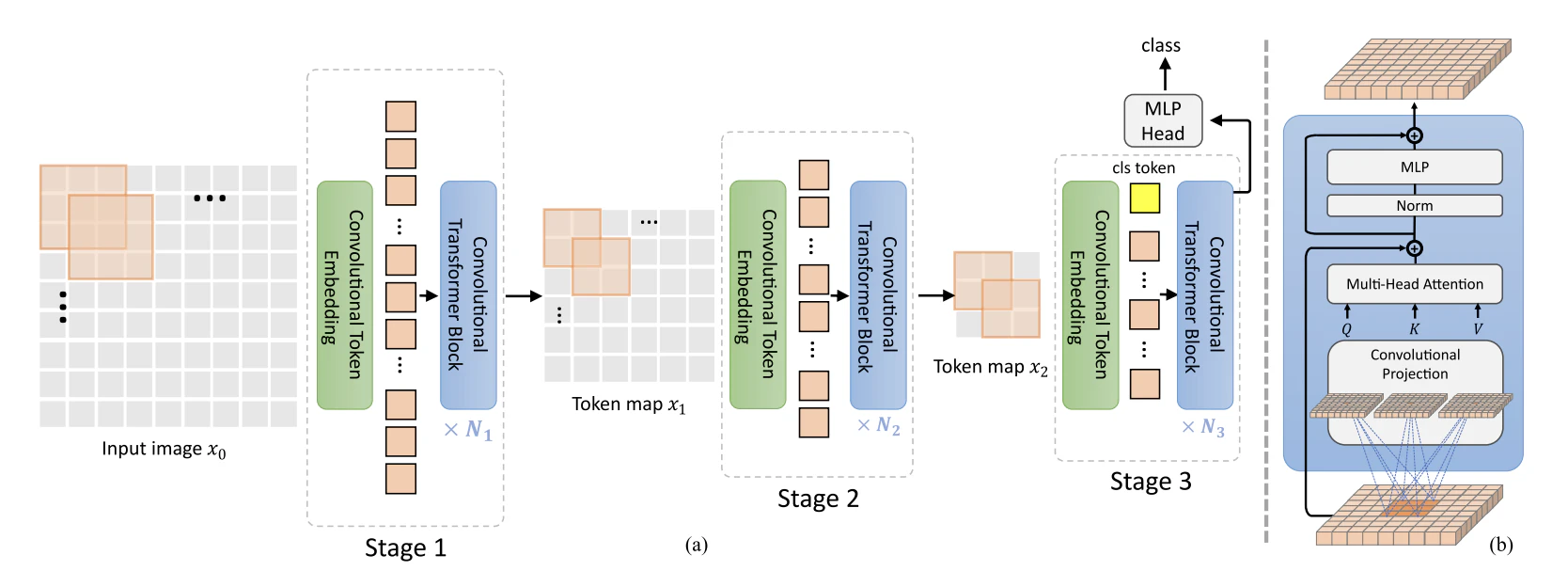

クエリ,キー,バリューの変換方法
キーとバリューのダウンサンプリングは$3 \times 3$のストライド2の畳み込みを採用している.
-
下図(a)にViTのクエリ,キー,バリュー変換を示し,線形射影の処理を行い変換している(SAは類似度計算を行い,クエリ,キーバリューは同じ特徴マップから入力されるため,同じ特徴マップ同士で内積計算をしても意味ないので,入力の特徴マップを変換してクエリ,キー,バリューとする).
-
下図(b)では,線形射影の処理を,パッチ特徴量変換を変更(線形射影から畳み込み)したように,畳み込み処理を使用してクエリ,キー,バリューに変換する.これによって,SAの大局的な認識の前に局所的な認識を行う畳み込みを交互に行い,ViTの全体を捉えるような認識と,ViTの苦手な認識である細かい認識を畳み込みの局所的な認識で補完する.
-
下図(c)では,(b)のキー,バリューの畳み込みストライドを2に設定し,ダウンサンプリングを行う.これにより,その後の処理のSAの計算量を削減する.SAの構造上,SAの出力特徴マップはクエリの大きさに依存する.そのため,キー,バリューをダウンサンプリングしても出力の特徴マップのサイズは変化しない.
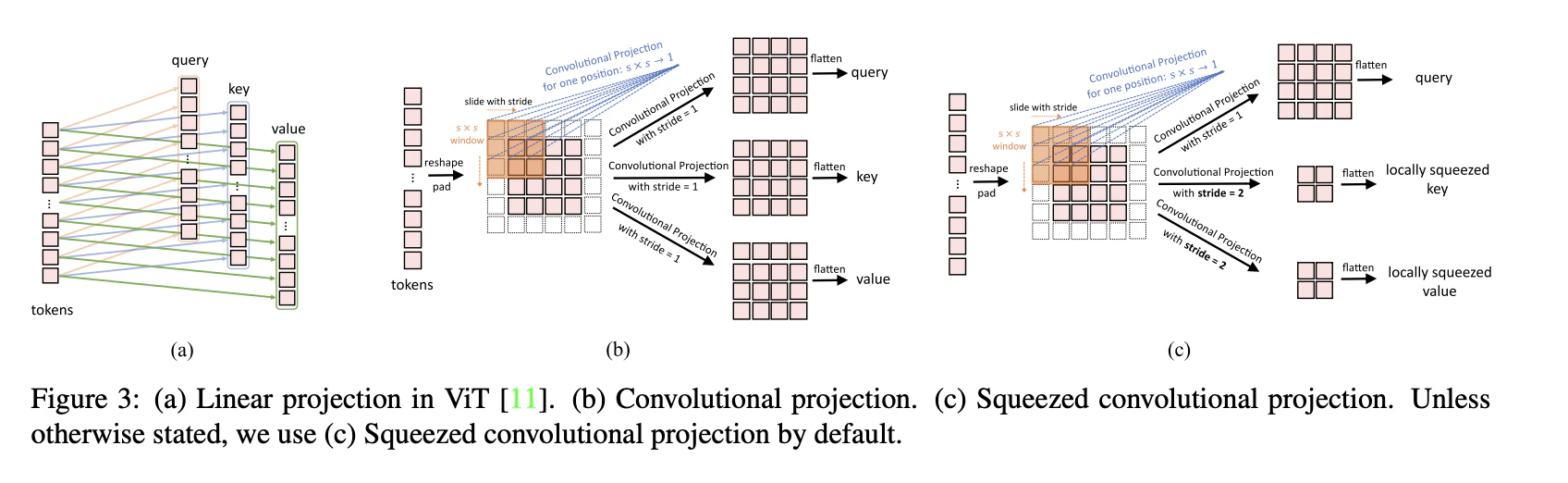
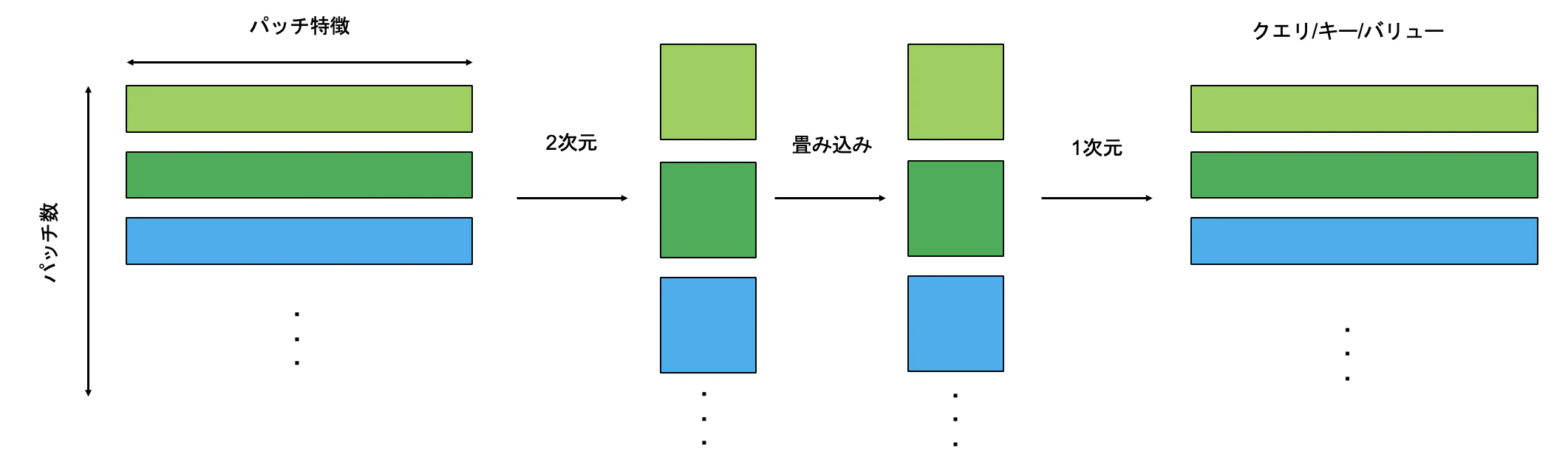
畳み込みの変換方法
クエリ,キー,バリューは畳み込みによって変換されるが,変換の元となる特徴量は1次元に格納されている.この状態では畳み込み処理が十分に行えないため,1次元の特徴マップを2次元にreshape(形を変える)し畳み込み処理を行い,その後,flatten(1次元化)する処理を行う.これを各,クエリ,キー,バリューで変換を行う(キー,バリューはストライド2).
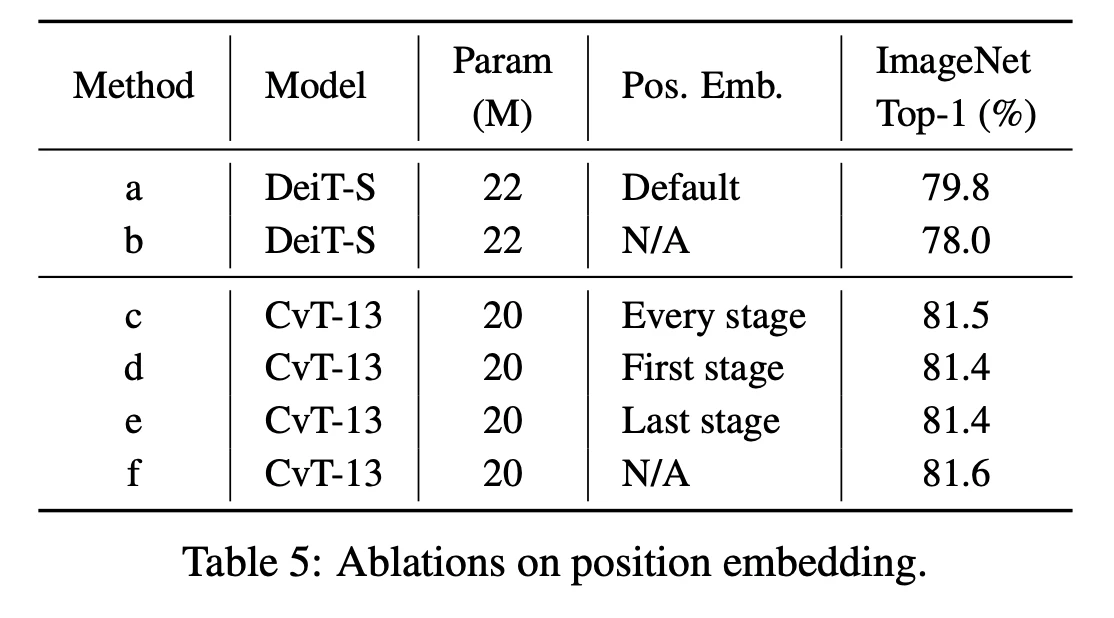
位置埋め込み
ViTはパッチ情報を並列に処理するため,そのパッチが元々どこの位置にあったかが保存できない.これを位置埋め込みを使用して,元の位置を保存する.CvTではこの位置埋め込みを必要としない.下表からCvTは位置埋め込みを削除したとしても精度に変化がなく,比較として,DeiT(ViTモデル)は位置埋め込みを削除すると精度が1.8%低下する.CvTが位置埋め込みに影響されない理由として畳み込み処理が有効に働いていると考えている.位置埋め込みの改善として再設計することなく,また,入力する画像サイズの影響を受けない優れた可能性を残す.
実験
画像分類精度
CvTはImageNet-1k,ImageNet-21kにおいてViTとCNNベースモデルのBiTと比較して,パラメータを削減しながらも精度が向上した.
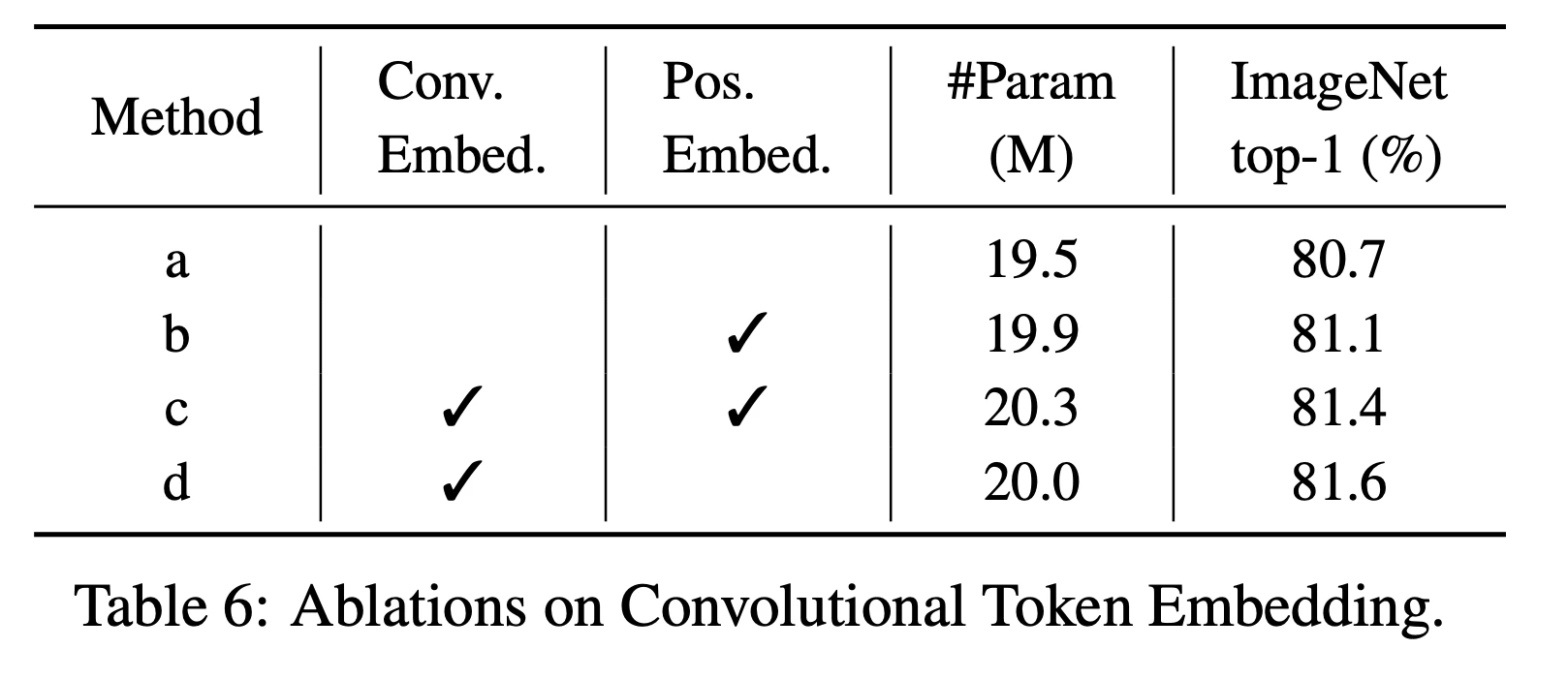
ステージ間の畳み込みと位置埋め込み精度
ステージ間の畳み込み(Convolutional Token Embedding)と位置埋め込みの精度で,ステージ間の処理でチェックが無い処理は線形射影を採用する.
(b)は位置埋め込みを採用すると(a)を上回り,(c)のConv.Embed.も採用すると精度がさらに向上する.面白いのが,Conv.Embed.を採用した場合,(d)の位置埋め込みがない方が精度が高い結果になる.Conv.Embed.は精度向上することに加えて,位置埋め込みの導入をしなくてもよい結果にも繋がった.
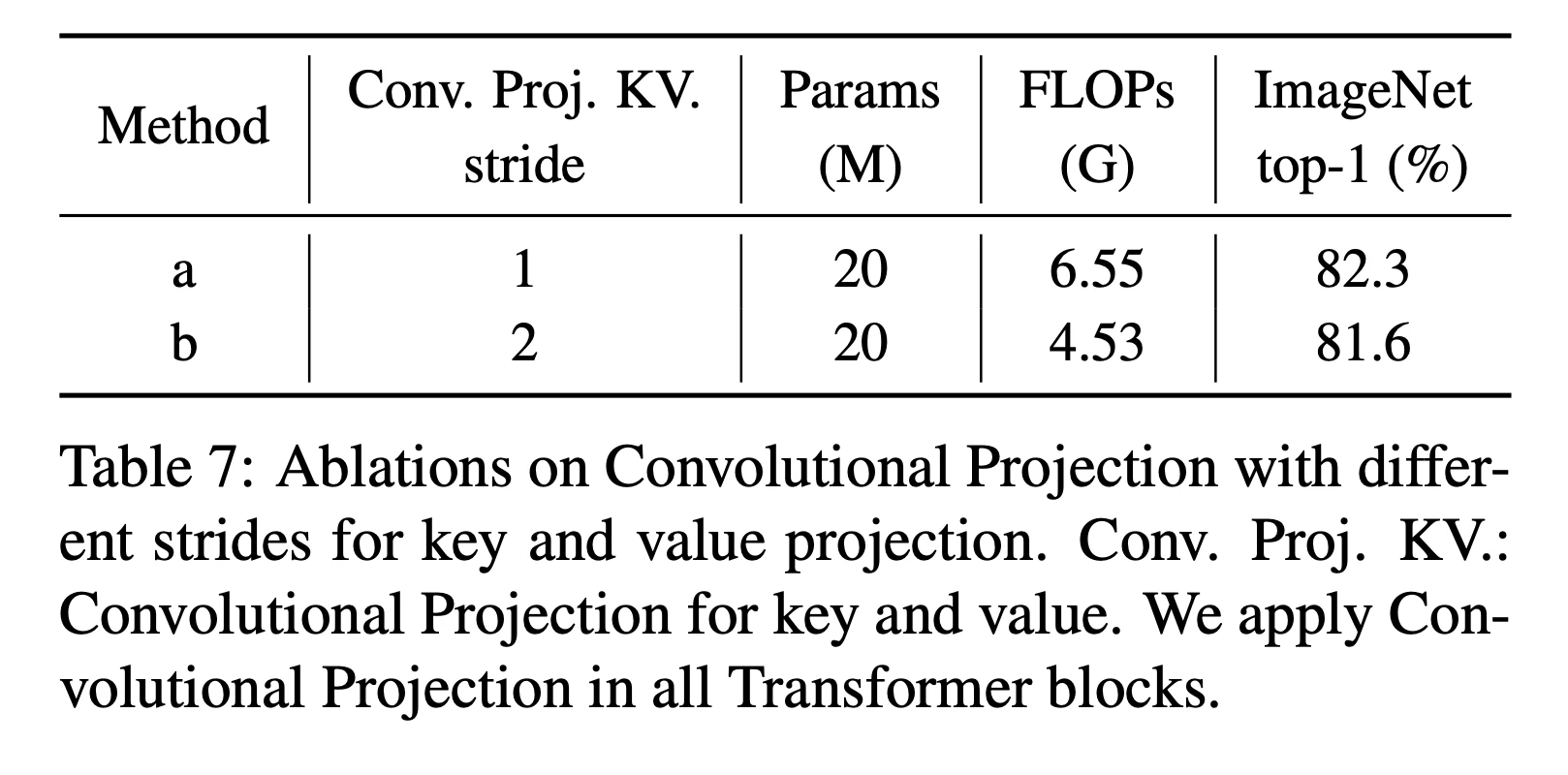
キー,バリューのダウンサンプリング精度
(a)にダウンサンプリングなし(ストライド1),(b)にダウンサンプリングあり(ストライド2)を示す.ダウンサンプリングを採用すると,精度が多少低下したが,計算効率の面からダウンサンプリングを採用する.
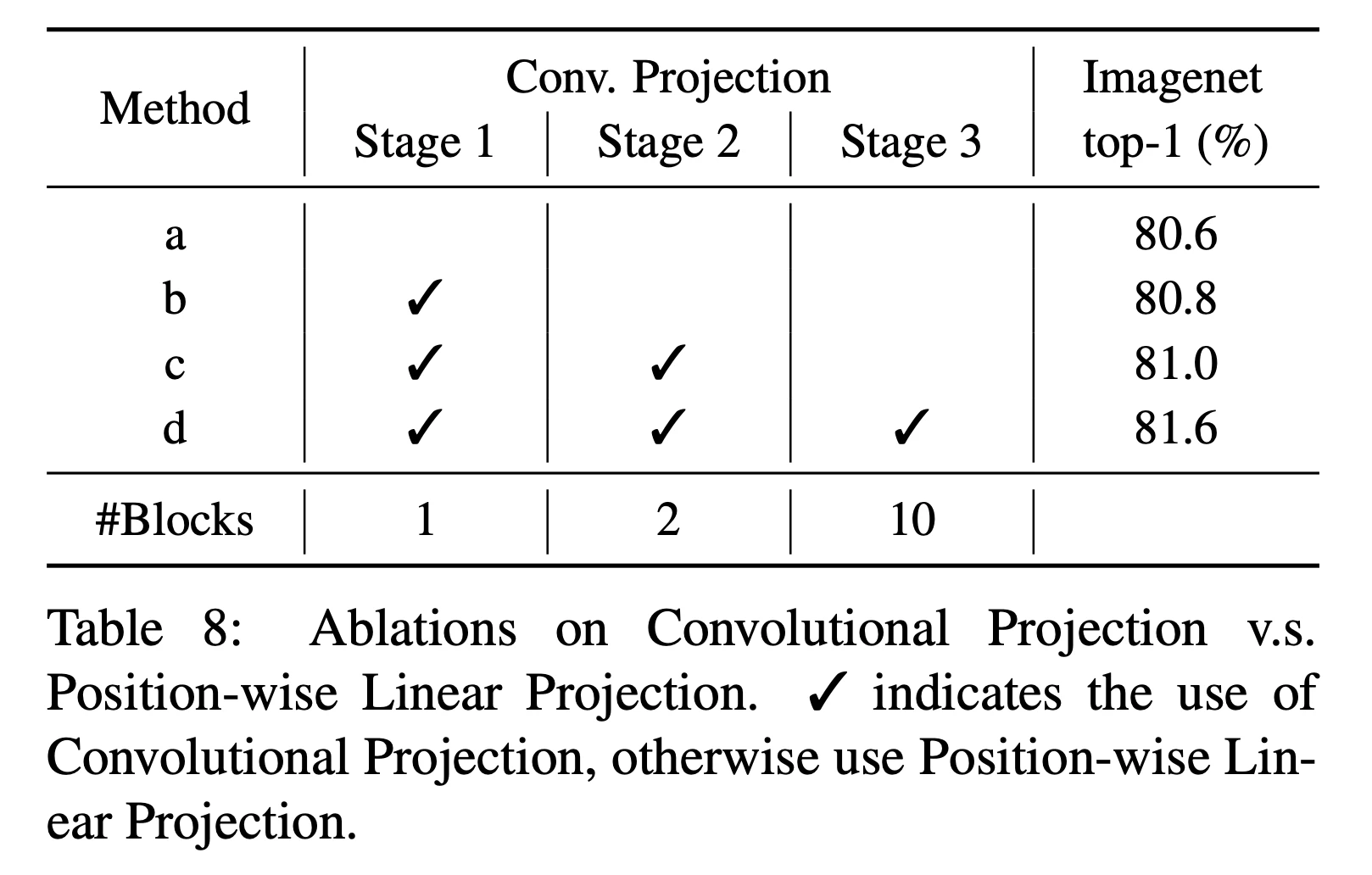
クエリ,キー,バリューの変換方法精度
クエリ,キー,バリューの変換方法を畳み込みか線形射影かで精度を比較する.チェックが畳み込みを採用しており,畳み込みの採用数と比例するように精度が向上する.このことから,畳み込みが有効に働くことがわかる.
考察
ViTの線形変換は畳み込みのような低次元フィルタが生成されるとViTの原論文に示してあり,畳み込みのようなことをしているなら畳み込みでいいじゃんってことかな?確かに!
まとめ
今回は,CvT: Introducing Convolutions to Vision Transformersについて解説した.
ViTの構造にパッチ特徴量と,クエリ,キー,バリューの変換に畳み込み(キー,バリューはストライド2)を導入することによって,精度向上と計算量の削減を達成した.また,位置埋め込みの必要性もなくなった.