原論文
On the Connection between Local Attention and Dynamic Depth-wise Convolution
https://arxiv.org/pdf/2106.04263.pdf
結論
ローカルSAとDWConvの情報集約範囲は似ているので,ローカルSAをローカルSAに似せた動的なDWConvへ置き換える.
概要
画像認識分野でCNNやViTがある.それぞれのモデル構造がどのような位置の情報を取り入れているかを下図に示す.
- (a) 通常の畳み込み
- (b) グローバルSA
- (c) DWconvとローカルSA
- (d) チャンネルMLP(FFN)と1x1Conv
- (e) 全結合層MLP

(c)のDWConvとローカルSAの違いは,静的か動的なパラメータを持っているかの違いである.なら,動的なパラメータを持つDWConvは,ローカルSAとほとんど一緒なんじゃない?の動機で,SwinのローカルSAの構造を動的なパラメータをもつDWConvに置き換える.これにより,計算量が削減でき,精度向上する.
モデル構造
SwinのローカルSAの構造を動的なパラメータをもつDWConvに置き換える.動的なパラメータは主に2つある.1つめは,SENetのように,空間情報をGAPで圧縮して,各チャンネルの重要度付けを行う(SE).2つめは,動的なカーネルで,より関連度の高い画素の情報を集約するために,正方形のカーネルを変化させる(オフセット).
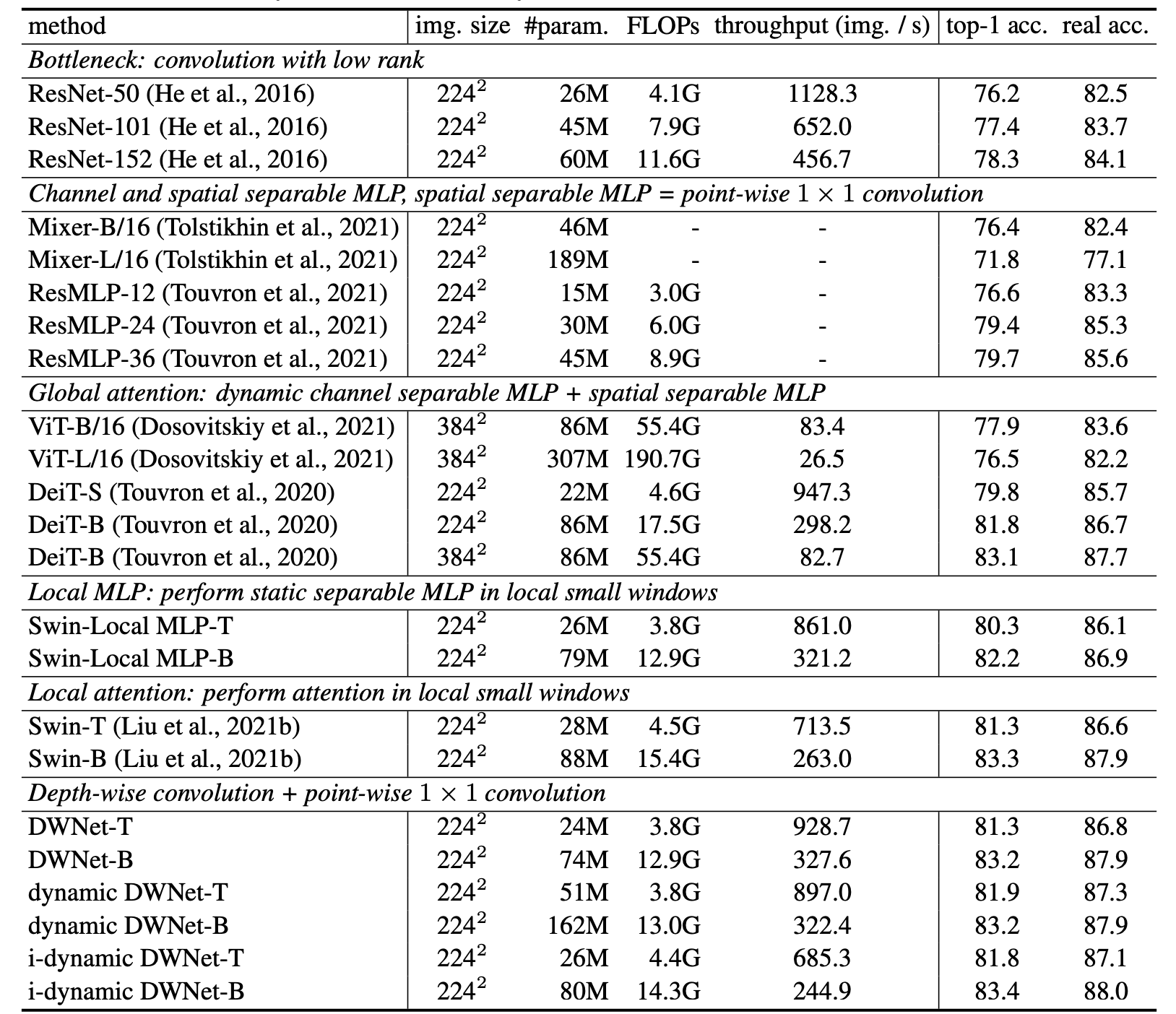
実験
dynamic DWNet(SE導入).i-dynamic DWNet(オフセット導入)のImageNet精度は良い結果.
まとめ
今回は,ローカルSAとDWConvはよく似てる【dynamic DWNet】について解説した.ローカルSAは,畳み込みに寄せて設計しているので,畳み込み側がさらにSAに寄せて,置き換えた.SAの計算が大きいので計算量削減に良い.