原論文
CoAtNet: Marrying Convolution and Attention for All Data Sizes
https://arxiv.org/abs/2106.04803
日本語解説
畳み込み+Attention=最強?最高性能を叩き出した画像認識モデル「CoAtNet」を解説!
https://qiita.com/omiita/items/b97e68e1bbfdfa71ba79
関連研究
Vison Transformerの解説
https://qiita.com/wakanomi/items/55bba80338615c7cce73
CNN+ViTモデルの傾向【サーベイ】
https://qiita.com/wakayama_90b/items/96bf5d32b09cb0041c39
結論
浅い層でCNN,深い層でViTをやる.
概要
ViTの分析により,浅い層では局所的な認識を好み,深い層では大局的な認識を好む傾向がある.この傾向を引き継ぐように浅い層の局所的な認識を局所的な認識が得意な畳み込みに置き換える.具体的には,4ステージ構造の階層型で最初の1,2ステージを畳み込み,3,4ステージをself-attentionを採用する.CoATはImageNetかた3億枚の画像データセット(JFT-300M)においても高精度を叩き出した.
モデル構造
CoATのモデル構造を下図に示す.1,2ステージを畳み込み,3,4ステージをself-attentionを採用する.これにより,ViTの苦手な局所的な認識を補助する.また,前半の畳み込みによって特徴量がダウンサンプリングされるため,SAの計算量を削減する.ステージ0として,畳み込みを使用して入力画像をダウンサンプリングする.ステージ間のダウンサンプリングにはmax poolingが採用する.
畳み込みブロックは,逆ボトルネックを採用する.1x1畳み込みによって,チャンネル数を4倍にして3x3DWConvを行う.その後,1x1畳み込みでチャンネル数を元に戻す.従来研究から,畳み込み認識は層を深くすることより,チャンネル数を増やすことが高い性能につながることが分かっている.

畳み込みブロックとSAブロックの組み合わせ
深層学習モデルの性能は以下の点で決まる.
- 汎化性能
- モデルのキャパシティ(大きいデータセットでも高精度)
- 転移学習時の性能
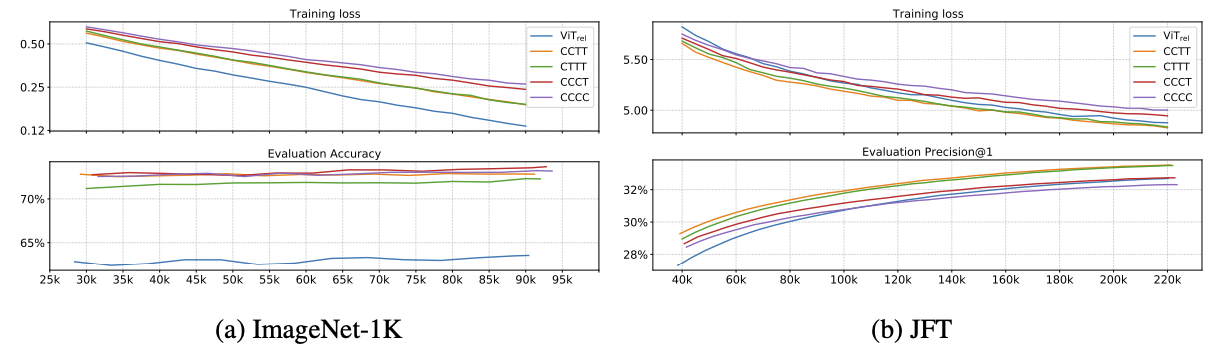
汎化性能
ImageNetの性能の順位.ここで,Cは畳み込みブロック,TはSAブロックを示す.CNNの認識を多め.
- C-C-C-C,C-C-C-T
- C-C-T-T
- C-T-T-T
モデルのキャパシティ(大きいデータセットでも高精度)
JFT-300Mの超大規模データセットの順位.データセットが大きい場合はViTの認識を多め.
- C-T-T-T,C-C-T-T
- ViT
- C-C-C-T
転移学習時の性能
JFTで事前学習してImageNet-1Kにファインチューニングの順位.半分ずつが良い.
- C-C-T-T
- C-T-T-T

最終的に「C-C-T-T」を採用した.
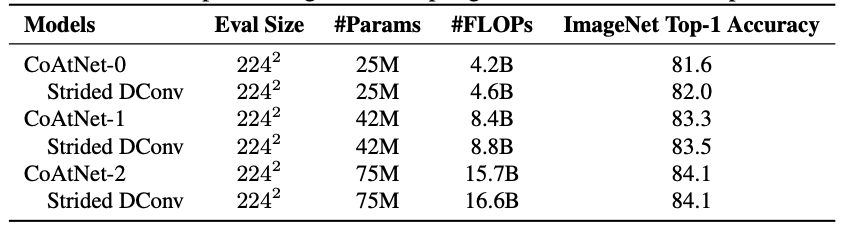
実験
CoATはImageNet,Imaget-21k,JFT-300Mで高精度を達成した.
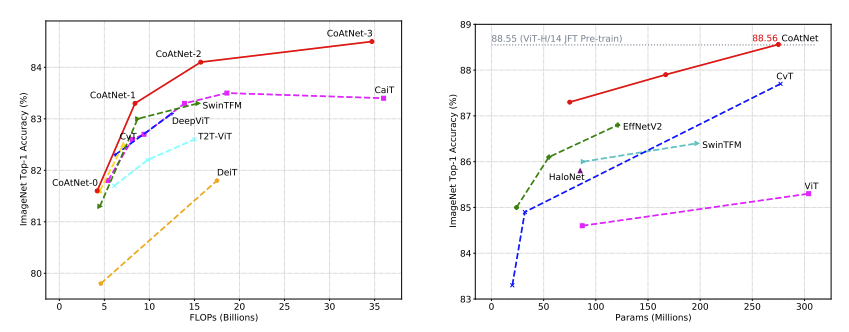
まとめ
今回は,CNNとViTのハイブリッドモデルのCoATNetについて解説した.浅い層では畳み込み,深い層では畳み込みが有効になることが分かった.