随時更新中
はじめに
- Week2で学習すること
- エラー分析(Error Analysis)
- 天井分析(Ceiling Analysis)
- 転移学習(Tranfer Learning)
- マルチタスク学習(Multi-task Learning)
- End-to-End Learning
Error Analysis
Carrying Out Error Analysis
Carrying Out Error Analysis (C3W2L01) https://t.co/8VBtkIytQE @YouTubeさんから
— wakame (@wakame1367) 2018年1月22日
エラー分析、天井分析についてはCoursera MachineLearning Course Week11でも言及されている。
詳しくは下記リンクが詳しい。
Coursera MachineLearning Course Week11 Application Example: Photo OCR
Coursera Machine Learning Week11 人工的なデータ生成と天井分析
Coursera Machine Learning (11): 写真の光学文字認識 (Photo OCR)
MachineLearningコースでは画像から文字を認識するシステム(Photo OCR)を構築する際
テキスト検出、文字分割、文字認識とそれぞれのパフォーマンスの上限(天井)を見積り、どの程度改善できるかで注力する時間、人力をかけるかの優先度を決めるという話だった。
今回は猫画像の分類器を例にあげ、分類器の精度改善手順について説明している。
例えば、精度90%の猫分類器が完成した場合を考える。10%の誤認識したケースを見てみるとどうも犬と猫を間違えたことがわかったとする。
-
エラー分析
- DevSetから100枚の画像を取り出す
- 犬と判別した画像を数える
-
100枚中5枚であった場合
- 5%の誤認識率、誤認識率全体(10%)からみると0.5%
-
100枚中50枚であった場合
- 50%の誤認識率、誤認識率全体(10%)からみると5%
後者の場合改善したほうが効果が高そうだと言える。
さらにエラーを分析すると、100枚の画像内に以下のような誤認識要因があった。
- 猫を犬と誤認識
- 大型のネコ科の動物(ライオン、豹など)への誤認識(Great Cats)
- もやがかかった画像の誤認識(Blurry Images)
- Instagramのフィルターがかかった画像の誤認識(Instagram)
それらの枚数を数え、図にまとめると以下のようになった。

この結果からBluurに注力したほうが効率良く精度を改善できそうだとわかる。
ただし、Bluuryの誤認識への対応にかなり時間がかかりそうだという見通しがあれば
GreatCatsの誤認識に切り替えるべき。
Cleaning Up Incorrectly Labelled Data
Cleaning Up Incorrectly Labelled Data (C3W2L02) https://t.co/IcpPGPtUDc @YouTubeさんから
— wakame (@wakame1367) 2018年1月22日
訓練データセットにラベルミスが含まれた場合
ディープラーニングアルゴリズムは堅牢であるためラベルミスはただちに影響はない。
DeepLearning Algorizm quite robust to random errors in the training set.
Devlopmentセットにラベルミスが含まれた場合
テストデータセットにラベルミスが含まれた場合
Build First System Quickly, Then Iterate
Build First System Quickly, Then Iterate (C3W2L03) https://t.co/NZZNqVzAR3 @YouTubeさんから
— wakame (@wakame1367) 2018年1月22日
今回のテーマはタイトルの通り「素早く実装して、評価してそれを繰り返す」
タスクは考えればたくさんあるがまずは以下の手順でシステムを構築する。
- Dev/TestSetとメトリクスを用意する
- 最終到達点を決める
- システムをできるだけ早く実装
- TrainingSetを用意、学習させる
- DevSetを使ってパラメータの調整
- TestSetを使ってパフォーマンスを評価
- ErrorAnalysis、システムを改良する
- Bias、Varianceであるかを調べ、次のステップに優先順位をつける
これらを早く繰り返す。
Mismatched training and dev/test set
Training and Testing on Different Distributions
Training and Testing on Different Distributions (C3W2L04) https://t.co/a3dmki8xvZ @YouTubeさんから
— wakame (@wakame1367) 2018年1月23日
Bias and Variance With Mismatched Data
Bias and Variance With Mismatched Data (C3W2L05) https://t.co/ecaDANWjsg @YouTubeさんから
— wakame (@wakame1367) 2018年1月25日
Addressing Data Mismatch
Addressing Data Mismatch (C3W2L06) https://t.co/8JWhWa7TPK @YouTubeさんから
— wakame (@wakame1367) 2018年1月25日
Learning from multiple tasks
Transfer Learning
Transfer Learning (C3W2L07) https://t.co/5sVl9dBz2u @YouTubeさんから
— wakame (@wakame1367) 2018年1月25日
転移学習とは既に学習済みのモデルを利用して別のラベルの予測に利用する手法のこと。両モデルの低次元で共有可能な画像のエッジ検出、カーブ検出などをそのまま利用するという考え方。
(エッジ検出と説明しやすくするために言ったが具体的に何を再利用しているか、なぜうまくいっているかはよくわかっていない)
転移学習を行う目的は動画での例に挙げられていたX線写真などの収集するのが難しい・特殊な環境でしか収集できない画像や音声などを学習に用いるため。また、転移学習を行う上で注意点がある。
- 動画では猫判別器から放射線診断へ転移学習させたように同種(画像なら画像)のモデルでなくてはならない
- モデルはそのまま利用するが出力層の構成を変える必要がある
- 既存の出力層の重みをランダムに再度初期化し、新しい訓練データを使って学習し直す
- 訓練データが少ない場合、出力層のみを再学習し(FineTuning)、多い場合は全層を学習し直す(PreTuning)
参考
Multitask Learning
Multitask Learning (C3W2L08) https://t.co/oE7MqMLldf @YouTubeさんから
— wakame (@wakame1367) 2018年1月25日
マルチタスク学習は主に物体検出に用いられる、例えば自動運転で使われる車載カメラ、画像内に存在する交通標識や車、歩行者などの複数のオブジェクトを認識する必要があるためこの技術が用いられる。
- マルチタスク学習を使う場合気をつける点
- 転移学習のように下層部分で共通のエッジ、カーブ等を学習する
- データセットサイズはそれぞれのタスクごとに同じくらいにする
- 複数タスクへ対応するためニューラルネットワークの構造を大きくする
参考
Facebook、Deep learningベースのコンピュータビジョン物体検出アルゴリズム「Detectron」をオープンソース化。活用した研究論文も多数公開済み
Github - facebookresearch/Detectron
Facebook open sources Detectron
What is end-to-end deep learning?
What is end-to-end deep learning? (C3W2L09) https://t.co/Sff1sgKBOD @YouTubeさんから
— wakame (@wakame1367) 2018年1月27日
End-to-End学習とは端つまり入力と出力だけ渡して、途中で発生する処理全てを学習してしまうというもの。
OCRを例に挙げると、入力の画像から途中の処理を細かいタスクに分け最終的に文字認識に到るという構造が
一般的、しかしEnd-to-End学習では中間の処理も全て学習させる。
注意点としてデータセットがたくさん必要になる点、逆に言うとデータセットが少ないなら今までの手法を使えばよい。
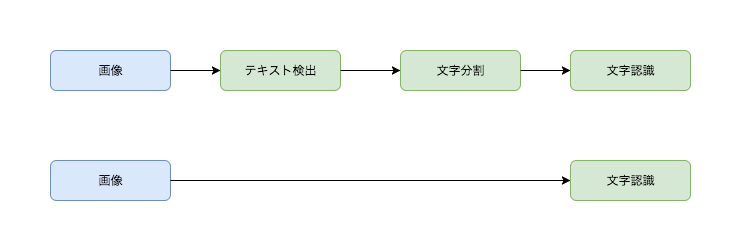
- End-to-End学習がよく使われる分野
- 音声翻訳
- 自動運転のステアリング
- 機械翻訳
- 画像合成
Whether to Use End-To-End Deep Learning
Whether to Use End-To-End Deep Learning (C3W2L10) https://t.co/mxoiwTpaki @YouTubeさんから
— wakame (@wakame1367) 2018年1月27日
あとがき
Andrew先生はCourse3でしきりに言及されているがどれくらいそのタスクに時間をかけられるのか
という疑問にノウハウを紹介することで答えていると思った。