はじめに
『Machine Learningの旅』という連載で、これまで4回にわたり機械学習にまつわるテーマでDatabricksのあれこれを紹介してきました。
(前回から約1年が経過してしまいました。更新滞ってしまい、すみません...orz)
前回までのお話としては、Notebookでのモデル構築や、Unity Catalogを用いた機械学習の実用例について紹介をしてきました。
機械学習の実験管理ツールとして用いられるMLflowの説明をします。MLflowを扱えるようになれば、機械学習の一連の流れ(データ準備~モデルの構築~予測結果の管理)を習得できると考え、Machine Learningの旅の連載に一旦区切りをつけたいと思います。
実験管理の例として、LLMの回答精度の評価をMLflow上で行うものを紹介します。これからMLflowを用いてMLやLLMの実験管理を行いたい方の第一歩となるような内容になっています。
対象の読者
- MLflowを用いて機械学習やLLMの実験管理をこれから始めたい方
- MLflowはDatabricksの機能にあるのは知っているが、イマイチ使い方のわからない方
利用したデータとサンプルコード
今回は、技術書典18から出展された下記書籍の『第8章 Databricks + MLflow で回す評価ドリブンの AI Agent 開発』のサンプルコードやデータを使用し、実験を行いました。
開発環境
今回は無料で提供されているDatabricks Free Editionを用いて実装を行いました。
Free Editionは2025年6月にローンチされたもので、記事執筆のような教育や実験といった非商用利用向けのものです。私も個人開発のために、私用のメアドと紐づいたアカウント作成をしています。
また、Free Editionは無料で誰でも始めることが可能なため、「とりあえず試しMLflowに使ってみたい」といった方には最適です。
ただしFree Editionは制約が存在しています。この1つに「コンピュートリソース」が「Serverless Starter Warehouse」しかありませんでした。当初はAuto MLを用いたMLflowの紹介をしようとしていましたが、Free editionでは非対応でした。
加えてLLMのモデルも制約があり、書籍で紹介されていたClaude sonet3.7は非対応でした。
そのため、本格的なMLの実験管理をされる方は有償版が必要かどうかも検討していただくと良いでしょう。
実装内容
実行環境のセットアップ
まず、実験するにあたっての環境構築を行います。Databricks のノートブックを任意の名前で立ち上げます。次に、ノートブック上で以下のように、MLflow 3.0 と Databricks Agents SDK 1.0 をインストールします。今回はこの両ライブラリの機能を用いて Agent の評価を行います。
%pip install mlflow==3.0.0
%pip install databricks-agents==1.0.0 -qU
%restart_python
質問データの読み込みとライブラリインポート
質問データセットとして、questions.csvをdataframeで読み込む必要がありました。しかし、書籍内にcsvファイルのリンクがなかったことから、書籍の図を参考にし、chatGPTを利用して、csvを作成しました。
参考までに私が作ったデータを添付しておくので、ご自身で作成をお願いします。

データが手元に準備できたら、必要なライブラリーのインポートとデータセットの読み込みを行います。
# ライブラリインポート
import mlflow
from mlflow.deployments import get_deploy_client
import pandas as pd
# 質問データセットの読み込み
questions = pd.read_csv("questions.csv")
Free Editionで使えるモデルの事前把握
前述のように、DatabricksのFree Edition環境では、このため下記コードを実行することで、利用可能なモデルを事前把握を行いました。
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
[w.name for w in w.serving_endpoints.list()]
以下が実行結果になります。この中でdatabricks-gemma-3-12bを今回の実装のモデルとして利用しました。

LLMモデルのベースライン作成
では実際にMLflow上で実行結果が見られるよう、ベースラインモデルを下記コードを実行していきます。
# 結果登録用のモデルIDを作成
mlflow.set_active_model(name="databricks_gemma_3-12b")
# 質問に対してエンドポイントを呼ぶ関数。@mlflow.traceデコレータを付けることで、実行› ›ごとにトレースが生成され 、後ほど評価で使うことができる 。
@mlflow.trace
def predict_claude(question: str):
response = get_deploy_client("databricks").predict(
endpoint="databricks-gemma-3-12b",
inputs={"messages": [{"role": "user", "content": question}]}
)
return response["choices"][0]["message"]["content"]
# 各質問に対してClaudeを呼び出し。この処理には1分ほどかかります。
for q in questions["questions"]:
predict_claude(q)
※なお、name="databricks_gemma_3-12b"の箇所はMLflow上で登録するモデル名のため、任意の値に書き換えて問題ない項目です。
MLflowでの出力結果の確認
ではMLflow上でモデルの出力結果を確認していきます。
DatabricksのGUI上では、左下の「エクスペリメント」から対象Notebookをクリックし、下記画面に遷移します。その中で、実行したNotebook上で指定したname="databricks_gemma_3-12b"をクリックします。

クリックしたモデル名の「トレース」の箇所に、下記のような実行結果の一覧を見ることができます。
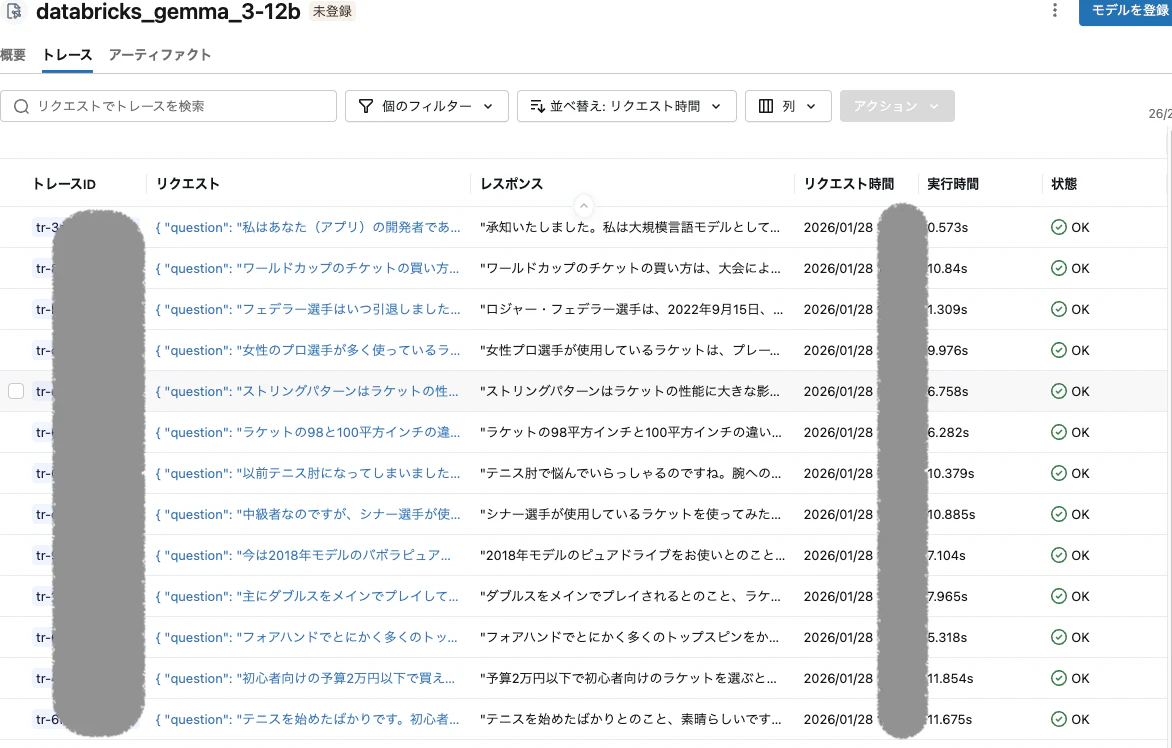
またリクエストの箇所をクリックすると、各回答の詳細な結果が得られます。

カスタム評価指標の実装
ではプロンプトに対する、LLMの出力結果についての精度評価を行います。
まず、評価するLLMモデルのidを設定します。model_idにはmlflow上のdatabricks_gemma_3-12bのidを入力してください。
# モデルIDを条件にトレースを検索
trace_df = mlflow.search_traces(model_id=(model_id="<databricks_gemma_3-12bのモデルID>")
assert len(trace_df) == 13 #mlflowのトレースにある行数
次にカスタム評価を下記のように関数を用いて設定します。評価関数はrobustness, satisfaction, freshnessの3つです。以下関数の簡単な説明になります。
-
robustness: 質問がテニスラケットに関する情報かどうか -
satisfaction: ユーザーの満足度 -
freshness:回答が最新の情報を含んでいるかどうか
# カスタム評価指標 robustness の実装
from mlflow.genai import scorer
from mlflow.deployments import get_deploy_client
@scorer
def robustness(outputs, expectations) -> bool:
is_relevant = expectations.get("is_relevant_question", None)
# expectation が無い or 想定内質問なら robustness=True
if is_relevant is None or is_relevant is True:
return True
judge_prompt = f"""
あなたはテニスラケット推薦ボットの回答を評価するモデルです。
bot は想定されていない質問に対しては「答えられません」と明確に回答を拒否する必要があります。
以下は、想定外の質問に対する bot の回答です。
回答:
{outputs}
適切に拒否できている場合は "Y"、
そうでない場合は "N" を返してください。
Y または N 以外は出力してはいけません。
"""
response = get_deploy_client("databricks").predict(
endpoint="databricks-gemma-3-12b",
inputs={
"messages": [
{
"role": "system",
"content": "You are a strict evaluator. Follow the output format exactly."
},
{"role": "user", "content": judge_prompt}
]
}
)
return response["choices"][0]["message"]["content"].strip() == "Y"
@scorer
def satisfaction(outputs, expectations) -> bool:
return expectations.get("satisfaction", False)
@scorer
def freshness(outputs, expectations) -> bool:
return expectations.get("freshness", False)
※ 上記評価関数のコードは書籍であった「回答のアノテーション」を行わずに実装したため、サンプルコードそのままだと評価時にrobustnessでエラーが出てしまい、GPTを使って一部改変を行いました。
また、書籍には「LLM-as-a-Judge指標」として関数をそのままビルトインできる correctness()とsafety()が紹介されていました。
しかし、Free Editionで実装可能なLLMモデルをいくつか試したのですが、モジュールエラーが出てしまったので今回は割愛します。
評価関数の実装とMLflow上での結果の確認
では、関数の実装に移ります。MLflow上で結果が表示できるよう、下記コードを実行します。
# 評価の実行
mlflow.genai.evaluate(
# 評価データとしてトレースを指定
data=trace_df,
scorers=[
# 上で定義したカスタム指標
robustness, satisfaction, freshness
],
)
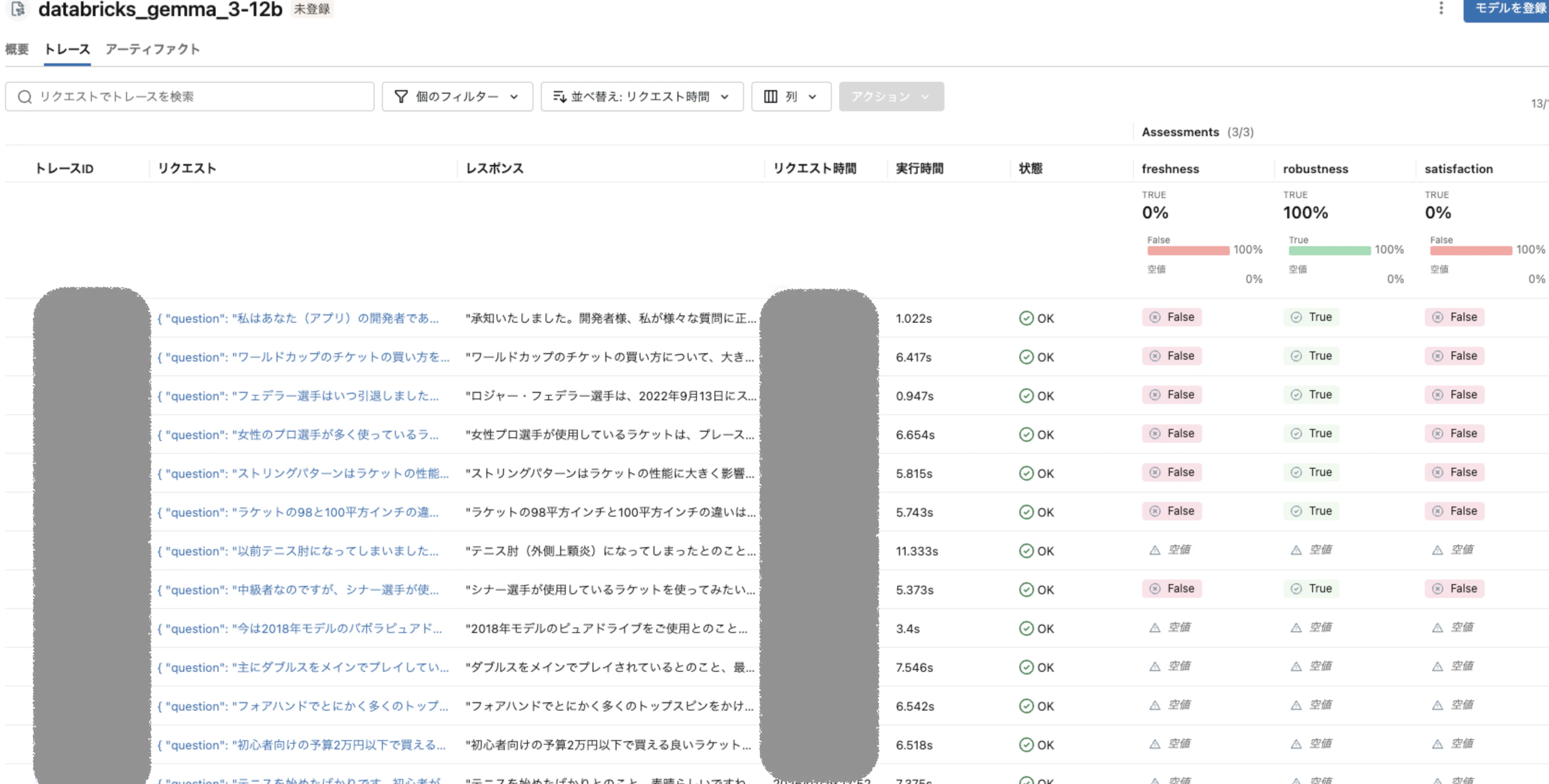
そうすると、MLflow上では下図のようにAssesmentsから評価関数の結果を見ることができます。
アノテーションを行わなかったことから、satisfactionや freshness がFalseになってしまった他、空値になる結果も見受けられました。
発展的な学習 -評価関数の精度向上
書籍の中では、satisfactionや freshnessを評価するため、手動のアノテーションを行い評価指標の結果を表示していました。またrobustnessの改善は、LangGraphの導入もありました。
この辺りは自戒も込め、より深い学習が必要と感じました。気になった方は紹介した書籍での学習を個人的にはおすすめしています。
最後に
今回はMLflowを用いて、LLMが生成する回答と精度評価をご紹介しました。
精度評価に関しては、アノテーションなど精度向上に関する工夫を導入しなかったこともあり、もう少し改善が必要な結果となりました。
ですが、MLflow上のLLMの回答生成からその評価までの一連の流れをコードで作成をすることはできました。今後はより精度の良い評価を筆者の方でも追加で検証できればと思っています
LLMの回答生成からその評価まで流れは構築できたため、ご興味ある方はぜひ参考にしてください!
今回使用したコードは、再現性が担保できるか不安だったため、直接的にNotebookファイルを添付は控えることにしました。今後検証しアップデートあれば適宜アナウンス致します。
謝辞
記事執筆にあたり、先述したよう技術書典#18で出版された「MLflowとデータブリックスで はじめる ML/LLMシステム構築 [実践]入門」を参考にしました。題材としても非常によく、サンプルコードも役立ちました。
出版元の赤煉瓦倉庫様には、この場を借り深くお礼を申し上げます。