はじめに
本記事はDatabricks アドベントカレンダー2024 9日目の記事です。
「Databricks経由Machine Learningの旅」の3回目になります。
(前回の更新から、約3ヶ月半が経ってしまいました.....楽しみにしていた方、すみません)
前回はNoteBookを触って、データを読み込んだり、pythonで実装できるAutoMLから簡易的な機械学習モデル構築を行いました。
この連載の最終的なゴールとして、特徴量の拡張や膨大な学習データのインプットを行い、本格的なモデル構築を行いたいと考えております。
その中でデータカタログについて、大量のデータを使用する機械学習においてとても重要な要素の1つであり、予測モデルの構築にも影響を及ぼします。
今回は本格的な機械学習モデル構築を行う前準備として、DatabricksのデータカタログであるUnity Catalogについて整理をしたいと思います。
対象の読者
- Unity Catalogを使いたいけど、まだ触ったことのない方
- Databricksで機械学習モデルの構築をこれから始めたい方
機械学習モデル構築に有用な3つの特徴
機械学習モデルを構築する上で、非常に有用な3つの特徴を取り上げます。
この特徴があると、モデル構築を行う上でかなり有利に働くことが多いと考えます。
1. 非構造化データと構造化データを同時に扱える
1つ目の特徴として、非構造化データが構造化データをUnity Catalog上で同時に扱えることにあります。
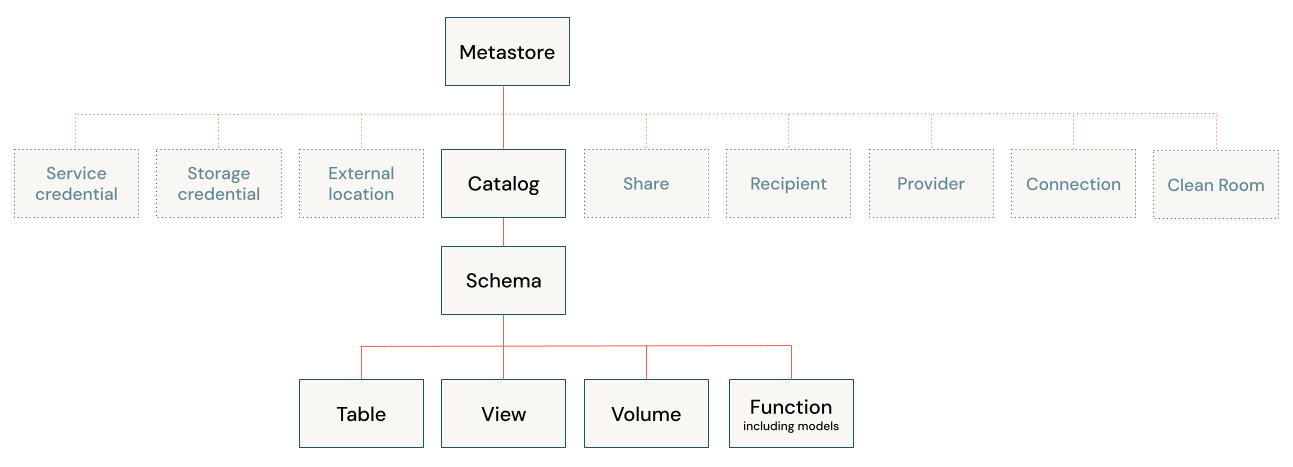
引用元 :「Unity Catalogのベストプラクティス」databricks公式より
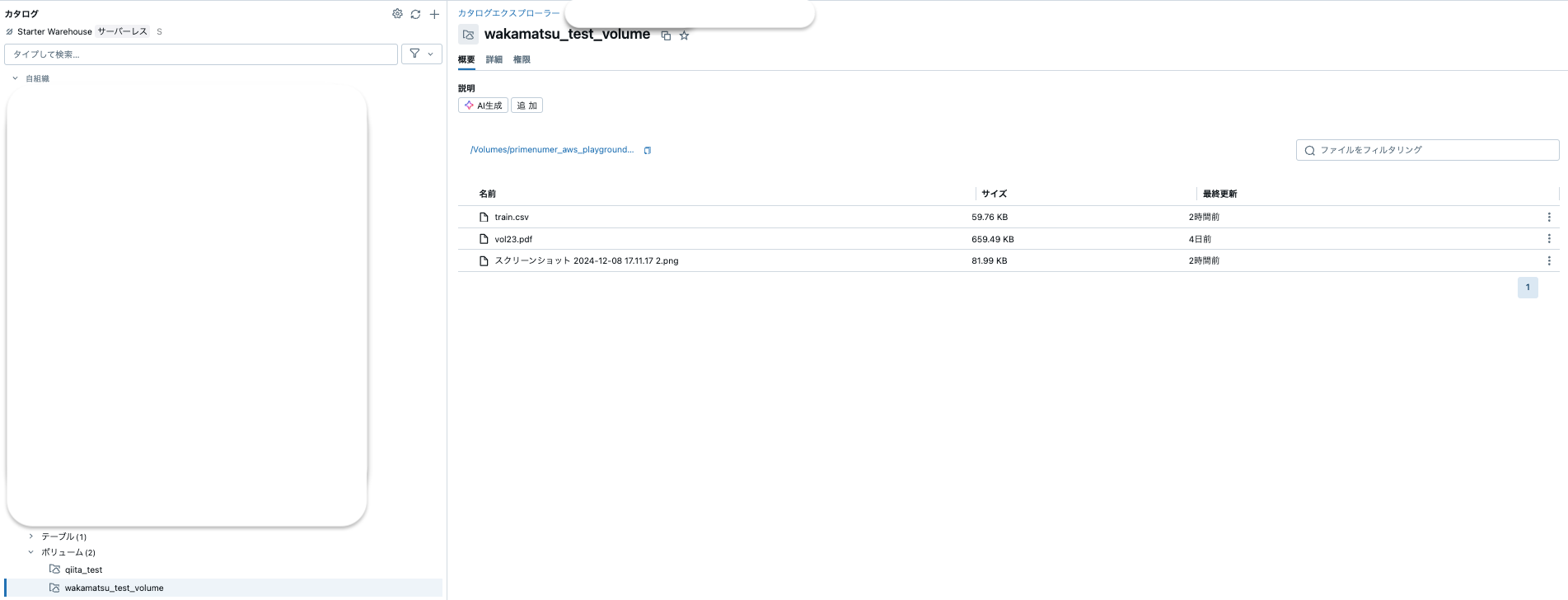
まず非構造データに関してはボリュームに保存することが可能で、下記のように画像解析で使える.pngや自然言語処理で使えそうな.pdfも同時に扱えます。
以下のように、csvファイルと同じ置き場所で取り扱うことができます。
また構造化データについても、非構造化データと同じスキーマに入れることが可能で、カタログ機能としてコメントやデータの説明を記載することが可能です。
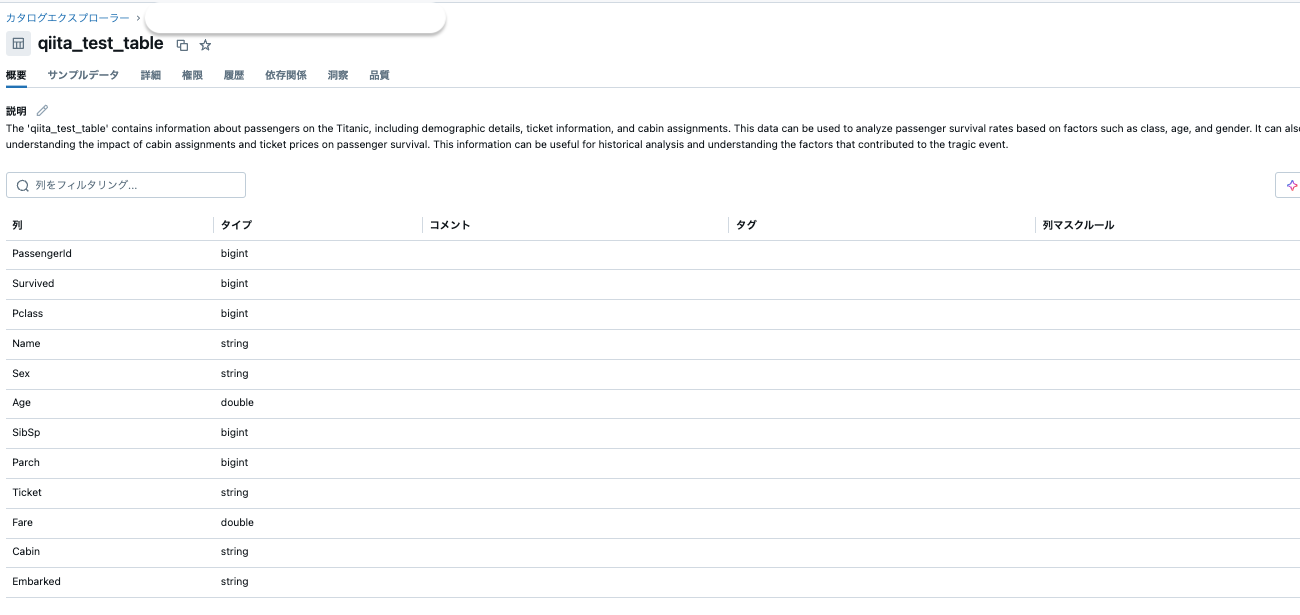
非構造と構造データを同じ場所で扱うことは、利用できるデータ幅を広げることが可能になります。
2. データの置き場が点在していてもカタログ機能が使える
1.の機能に加え、置き場所が点在していた場合でも、Unity Catalogで一元的に管理ができます。
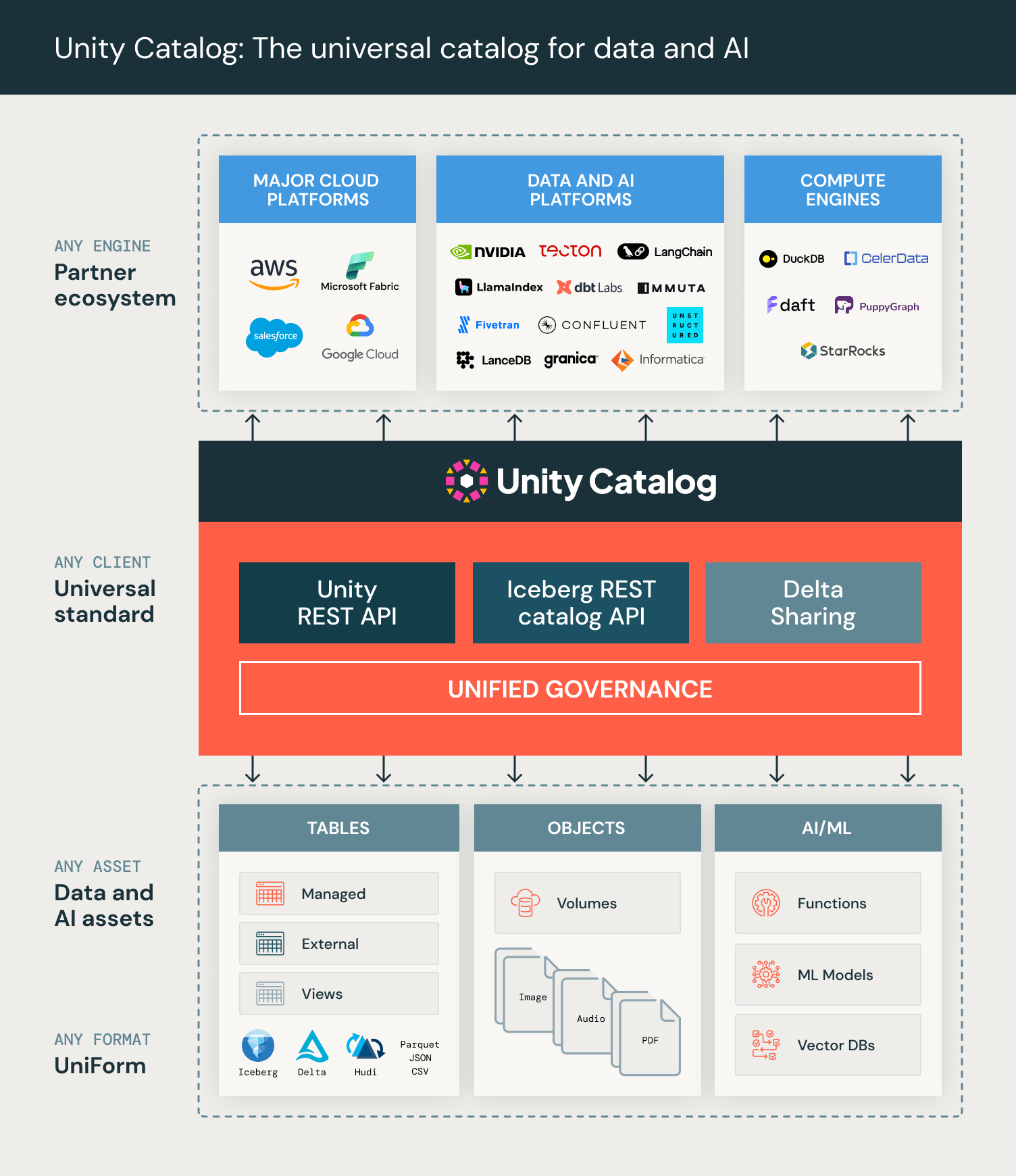
引用元:「Unity Catalogのオープンソース化を発表します!」databricks公式より
例えば、AWSのS3やAzureの環境にあるデータだったとしても、Unity Catalogと紐付けることができます。
下記のように、S3のpathを設定すればUnity catalog上にS3のデータを表示させることができます。
また、パートナーコネクタでもあるFivetranを活用し、対応コネクタのデータをDatabricksに転送することで、Unity Catalog上でデータを扱うことができます。

なお、TROCCOも転送先databricksに対応しておりSaaSを中心とした多様なデータをUnity Catalogで管理できるよう連携できます。
3. データリネージ機能の充実
最後にリネージの機能が整備されていることです。
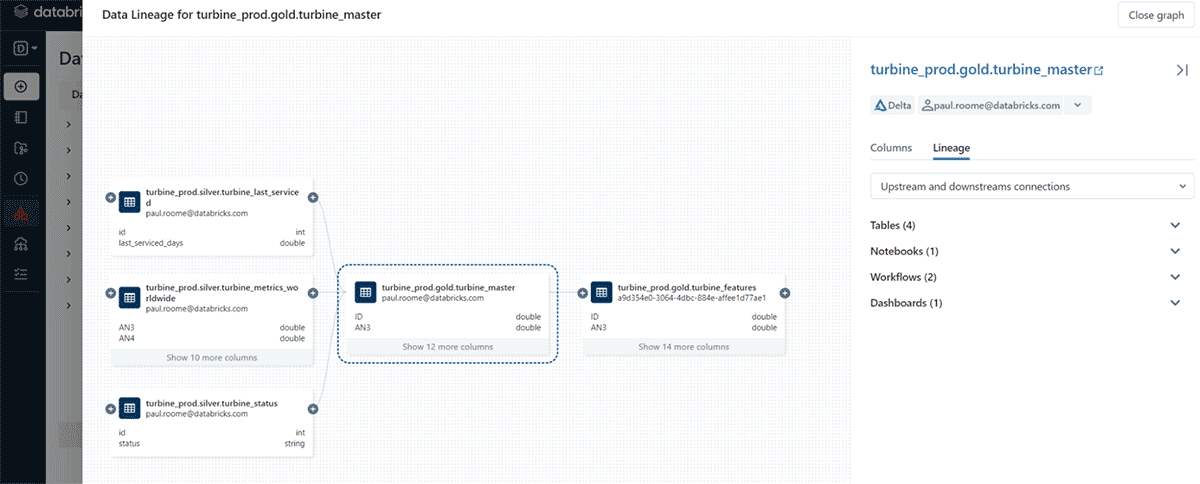
引用元「一般提供を発表:Unity Catalog でのデータリネージ」 databricks公式より
該当テーブルがどのテーブルとjoinしてできたのか?だけでなく、使用されているNotebookやworkflowについても特定することができます。
また、dbtとの連携が可能でもあり、dbtで作成したデータリネージをそのまま使うことができます。
まとめ
今回はUnity Catalogについて機械学習モデルの構築に有用な機能についての整理を行いました。
取り上げた3つの機能からいえることとして「膨大なデータを扱う機械学習」に適しているなと考えています。
非構造化データを構造化データと同じ場所で扱えることもそうなのですが、AWSなどの外部にあるデータをDatabricks上で扱えることもデータのバリエーションを増やす上でとても重要だなと考えています。
次回はいよいよ本格的な機械学習モデルの構築に移っていきます。
細かい内容や予測対象は鋭意検討中です、お楽しみに!