はじめに
「Databricks経由Machine Learningの旅」2回目になります。
前回は、ETLツールのTROCCO®を用いて外部データを取得し、Databricksにデータを準備するお話をしました。
今回から複数回に渡り、実際にNotebookを用いて機械学習モデルの構築をしていきたいと思います。
今回はまずNotebookの使い方に焦点を当てて説明します。
いきなり難しいモデルの説明を....となると学習の敷居が上がってしまうと感じました。
なのでPythonのAutoMLライブラリであるPyCaretを使用します。
このライブラリでは「データの取り込み〜モデル構築〜パラメータチューニング〜予測」といった機械学習の流れを、比較的簡素なコーディングで実行することができます。
筆者自体もDatabricks環境でNotebookを初めて触ることから、PyCaretを用いてNotebookの基本的な操作方法について、今回はご紹介したいと思います。
対象読者
- DatabricksのNotebookをこれから触ってみたい方
- 機械学習の一連の流れの外観を知りたい方
やったこと
① サンプルコードをNotebookで動かす
まず、お手本としてWEBで公開されているサンプルコードがDatabricksのNotebook上でも回るかを検証してみようと思います。
今回はQiitaで紹介されていた、「簡単にできる機械学習 ~PyCaretを使ってみた~」に添付されているコードを抜粋し、Notebook環境で回したいと思います。
なお今回、機械学習のモデルや評価指標の細かな説明は省きます。
詳しく知りたい方は、参考にしたQiitaの記事をベースに専門書等での深い学習をお勧めします。
新規Notebookの作成
まずNotebookの作成です。「新規>ノートブック」から新規のNotebookを作成します。
※jupyterが提供するNotebookと同様のUIになっています。

なお、コンピューティングリソースが未選択な方は、下記のように求められるため設定をお願いいたします。

ライブラリインポート、データ取得と前処理
まずライブラリのインポートとデータの読み込み、前処理を行います。下記スクショのように回します。
デフォルトで入っているdiamondのデータを読み込んでおります。

次にモデル構築とモデルの選定を行います。
PyCaretでは同じ特徴量を使って、複数のモデルで複数の評価指標を表示してくれます。
その中で精度の良さそうなモデルを選定し、最終的な予測に使っていきます。

※モデル・評価指標の説明は、参考Qiita記事の「予測モデル分析、選定」をご確認ください。
パラメータチューニング、残差確認、特徴量プロット
次にパラメータチューニングと、モデル設定後の残差確認と特徴量プロットを実行します。
scikit-learnや可視化のmatplotlib等に比べ、非常に少ないコーディングで確認することができますね。
予測結果を素早くみることができます。

予測結果の出力
最後に構築したモデルを、testデータで予測結果を出力する処理をすれば完成です。

②Databrick上のデータをPyCaretに読み込む
①ではPyCaretのデフォルトで入っているデータを使ってみました。
では実際にDatabricks上のデータを読み込めるか?について検証したいと思います。
読み込むデータは、第一話でTROCCO®を用いてDatabricksに転送した、Titanicのデータを使います。
csvファイルの場合
pandasを用いて機械学習する方も多くいると思いますので、まずcsvファイルでできないか?について検証してみようと思います。
上記Titanicデータをローカルにcsvでダウンロードし、 スキーマに「ボリューム」を作成したのち、csvデータをアップロードしていきます。

データの読み込みについてですが、Dataframe型であれば対応できたので、pandasでread_csv関数を使えばいけました。
ディレクトリーのパスは以下のように指定すればできました。
import pandas as pd
dataset = pd.read_csv('/Volumes/{catalog_name}/{schema_name}/{table_name}/train.csv'
,encoding='utf-8')
写真のようにモデル間の比較までできたので、予測モデルの出力まで可能だと思います。

テーブルの場合
第一話でTROCCO®のHTTPコネクタを活用して転送したテーブルの場合でも実施してみます。
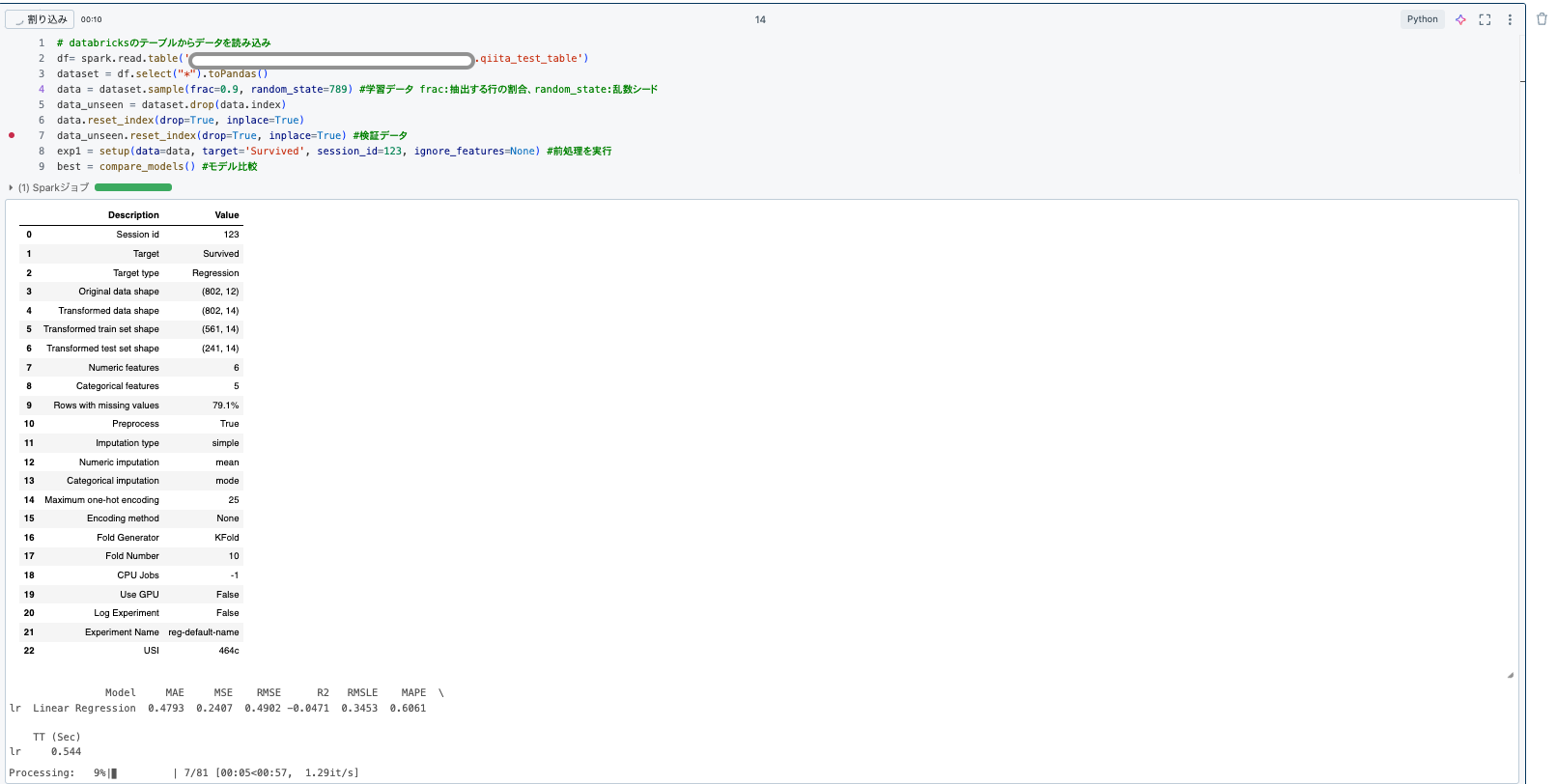
下記のように、テーブルを読み出して、Pyspark.DataframeからPandas.Dataframeに変換します。(直接データを読み出せなかったのでやや面倒でした。)
df= spark.read.table('{catalog_name}.{schema_name}.{table_name}')
dataset = df.select("*").toPandas()
ただし今回の処理がベスプラとは限らないと思っております。
Pyspark.Dataframeの場合、csvデータ読み込みと同じコードでは失敗しました。
そのため、.toPandas()で変換したのち、csvと同じ処理で実施しました。
PyCaretで、PySpark.DataFrame用のコーディングが存在している可能性も考えられます。
CSVファイルの時と同様に、モデル間の比較までできたため、予測モデルの出力まで可能だと思います。
実装したコードについて
今回実装したコードは下記GitHubのqiita_2nd_test_notebook.pyになります。
ご興味ある方は参考にしてみてください!
DatabricksのNotebookに初めてふれた感想
筆者自身、今回初めてDatabricksのNotebookを触ってみました。
他の環境下でNotebookを4-5年使ってきたため、個人的に特徴的な機能だな感じた点について紹介したいと思います。
AIによるコーディングアシスト機能が存在し、エラー修正を手伝ってくれる
エラーがでたコードに関して、AIが解決策を提示してくれました。こちらに関してはデフォルトで入っている機能となります。
例えば下記写真のようにimport pycaretと実行してもモジュールなしのエラーが出てしまいます。
しかし、右のようにAIが「モジュールがないので下記コードを実行してください」といったアシストをしてくれ、こちらを実行すると無事にimportすることができました。

Databricks環境のNotebookでどのように pip installすべきか?若干迷っていたので、このようなアシストがあるとかなり便利に感じました。
また何も設定することなく、この機能が使えるの点も良いなと感じました。
簡便的なGitHub連携
GitHubとの連携も比較的やりやすいなと感じました。
まず、「新規>Gitフォルダー」から作成したGitHubのリポジトリの登録を行います。
GitHub上にリポジトリが存在するのを前提とします。
またGitHubとの連携についても、「設定>リンク済みのアカウント」でGitHub連携するのと、GitHub側の設定で「Integration>Application」でDatabricksを設定する、たったの二つだけの設定でできました。


また、設定が足りない部分に関しては、Push時にエラーが出力され、具体的にどこでエラーになっているのか?(どこが不足しているのか?)を教えてくれます。
上記二つについても、こちらから設定方法がわかりました。

※Pushした後、GitHub上には一般的なNotebookの拡張子である.ipynbではなく、.py
で設定されました。
そのまま実行できるか?は未検証ですが、運用に載せる際、わざわざpyファイルに書き換える手間も省けるのでいい機能だなと思っています。
まとめと次回予告
今回はPythonで実装されている、PyCaretを用いて、DatabricksのNotebook環境で実行できるか?についてやってみました。
PyCaretも使ってみたいと思っていたので触れて良かったですし、GitHubとの簡便的な連携やAIアシスト機能についても気がつくことができ、いいNotebookの操作練習となりました。
次回は、特徴量エンジニアリングを題材に、予測精度がどこまで向上するかについてお話ししたいと思います。
またその際には、データガバナンスのカタログ機能についても併せて紹介していきたいと思っております。
次回のお話をお楽しみに!!