はじめに
簡単に機械学習ができる、PythonのAutoMLライブラリである 「PyCaret」 について紹介いたします。
初めてのqiita投稿なので、温かい目で読んでいただけると嬉しいです。
機械学習は開発に時間がかかったり、専門的で難しいと感じる方もいると思いますが、AutoML を利用することで、効率よく機械学習を行うことができます。
AutoML とは、データの前処理やモデルの作成を自動化し、少ないコードで行うことができる仕組みです。
その一つに PyCaret というPythonベースのライブラリがあります。
PyCaret は以下のような方におすすめだと思います。
- 時間や手間をかけず機械学習をしたい方
- 「機械学習の勉強をしたいけれど、実装とか難しそう」と不安を抱えている方
PyCaret とは
PyCaret は、PythonのAutoMLライブラリです。OSSで、MITライセンスに従って使用することができます。
Pythonを既に利用していれば、モジュールのインポートだけで扱うことができます。
基本的に以下のような流れで、PyCaretのモジュールを実行していきます。

本記事では、公式サイトのチュートリアルである、「ダイヤモンドの価格予測」を例として、上記の流れを紹介していきたいと思います。
事前準備
以下の実行環境をご準備ください。
実行環境
- Python 3.7.9 (3.6以上であれば大丈夫です)
- Pycaret 2.3.6
- Jupyter Notebook
PyCaretをインストールします。以下のコマンドを実行してください。
pip install pycaret今回は、Jupyter Notebookを使用したいと思いますので、必要に応じてご準備ください。
やってみた
今回は、ダイヤモンドの価格予測を行うため、回帰を試していきます。
PyCaretでは、他にもさまざまな機械学習を扱うことができます。(インポートコマンドは後に出てきます。)
| 手法 | インポートコマンド |
|---|---|
| 分類 | pycaret.classification |
| 回帰 | pycaret.regression |
| クラスタリング | pycaret.clustering |
| 異常検知 | pycaret.anomaly |
| 自然言語処理 | pycaret.nlp |
| アソシエーションルールマイニング | pycaret.arules |
※アソシエーションルールマイニングとは...ある事象が発生した時に、別の事象が発生するといった関係性を分析する手法
データの準備
PyCaretのインポートとデータセットを準備していきます。Jupyter Notebook上で、以下のコマンドを実行します。
今回は回帰を行うので、pycaret.regressionをインポートしてください。
import pycaret #必要なパッケージの読み込み
from pycaret.regression import * #回帰のインポート
from pycaret.datasets import get_data #データセットの読み込み
dataset = get_data("diamond") #ダイヤモンドのサンプルデータを取得データの前処理
データを学習用と検証用に9:1に分割したいと思います。
検証用データは、学習データによって作成した予測モデルの検証に使用します。
data = dataset.sample(frac=0.9, random_state=789) #学習データ frac:抽出する行の割合、random_state:乱数シード
data_unseen = dataset.drop(data.index)
data.reset_index(drop=True, inplace=True)
data_unseen.reset_index(drop=True, inplace=True) #検証データ次に、目的変数に「Price」を設定し、前処理を実行します。
exp1 = setup(data = data, target = 'Price', session_id=123,ignore_features = None, ) #前処理を実行setupの主な引数
| パラメータ | 概要 |
|---|---|
| data | サンプル数×特徴量のデータ |
| target | 目的変数 |
| session_id | 後で再現できるように設定しておく疑似乱数 |
| ignore_features | 無視したい特徴量 |
| normalize | Trueにするとデータが正規化される |
| train_size | 学習データのサイズ、例:=0.7で70%学習データに使われる |
| log_data | Trueにすると学習、テストデータをcsvで保存する |
前処理は、自動でデータ型が推測され、データを成形してくれます。
また、欠損値の処理やカテゴリのエンコードも自動で実行されます。
デフォルトでは、カテゴリ特徴は最頻値、数値特徴は平均値が代入されます。
コマンドを実行すると、下記の画面が出力され、ここで問題がなければ、Enterキー押下、間違いがあれば「quit」を入力し、修正を行います。
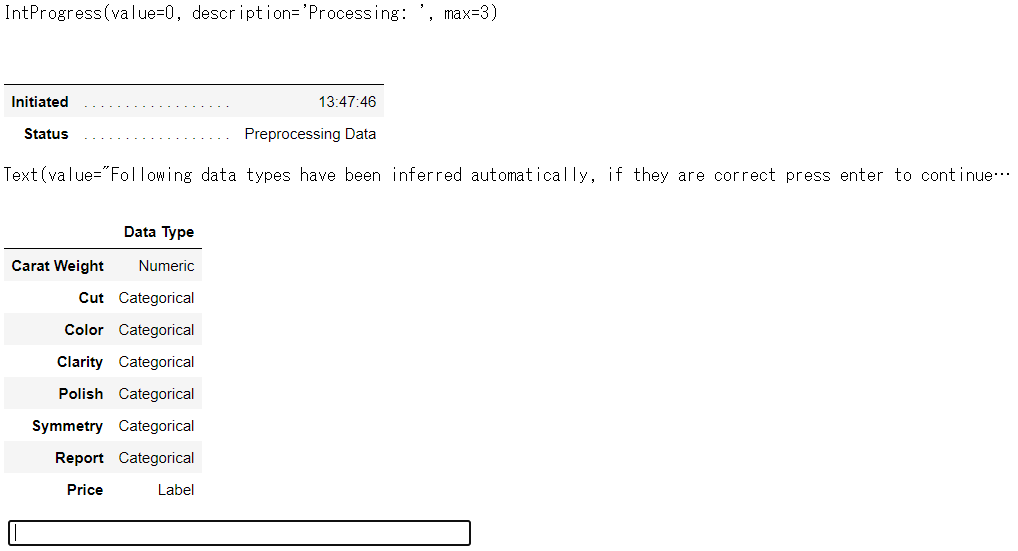
修正する場合は、以下のようにコマンドを実行することで、データ型を指定することができます。
exp1 = setup(data = data, target = 'Price', categorical_feature=["○○"], numeric_feature=["△△"], session_id=123) # categorical_feature:カテゴリの識別子, numeric_feature:数値データ, ○○,△△はデータの列名予測モデル分析、選定
PyCaretではコマンド1つで複数の予測モデルを分析することができます。
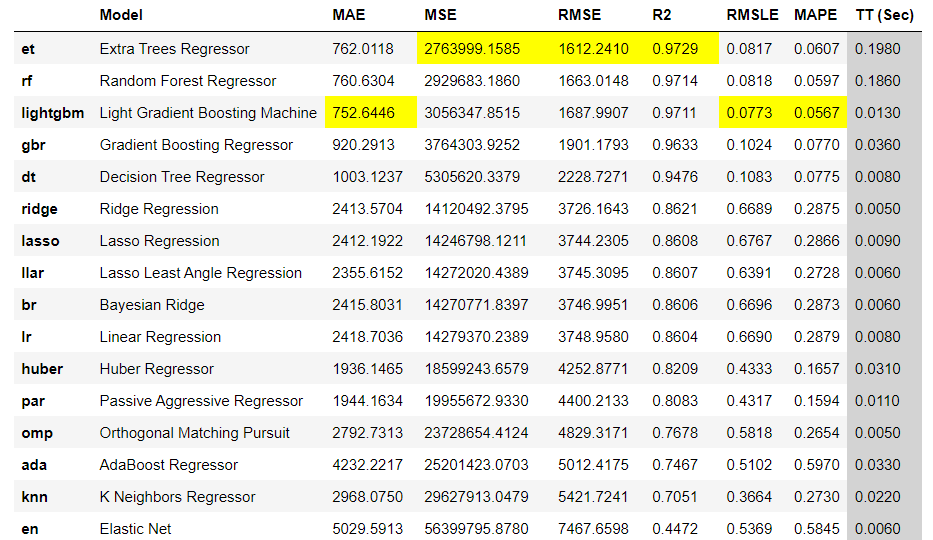
best = compare_models() #モデル比較実行すると、以下のような結果が出力されます。
出力された結果から良さそうな手法を選択します。
黄色でマーカーされている値が、各指標の良い結果です。
回帰で実行される予測モデルは以下のようなものがあります。
| word | モデル名 |
|---|---|
| ridge | リッジ回帰 |
| lda | 線形判別分析 |
| gbc | 勾配ブースティング |
| ada | アダブースト |
| lightgbm | LightGBM |
| rf | ランダムフォレスト |
| xgboost | XGBoost |
| et | ExtraTree |
| lr | ロジスティック回帰 |
| knn | K近傍法 |
| svm | サポートベクターマシン |
| et | ExtraTree |
| dt | 決定木 |
| qda | 二次判別分析 |
| nb | ナイーブベイズ |
| catboost | CatBoost |
予測モデルの選定方法は、R2が1に最も近いものや、RMSEが小さいものを選ぶと良いと言われています。
今回は、R2が1に近く、RMSEが最も小さい「Extra Trees Regressor」という手法を選択します。
0からモデルの選定を行う場合、使いたい手法をそれぞれ準備し、同じデータ、同じ条件で行う必要がありますが、PyCaretでは、1行でまとめて行うことができるので、短時間で楽に手法を比較することができます。
【補足】
評価指標について
| 略称 | 指標名 |
|---|---|
| MAE | 平均絶対誤差 |
| MSE | 平均二乗誤差 |
| RMSE | 平均二乗平方根誤差 |
| R2 | 決定係数 |
| RMSLE | 対数平均二乗平方根誤差 |
| MAPE | 平均絶対誤差率 |
モデル作成
予測モデル比較で選んだ手法で、モデル作成を行います。
引数に予測モデルを設定します。
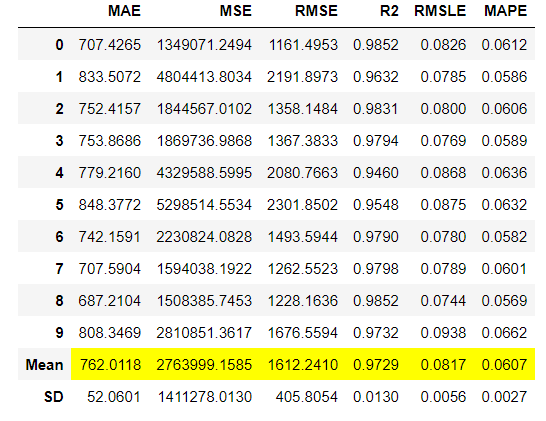
model = create_model("et") #予測モデルに Extra Trees Regressor を選択実行すると自動で、10分割交差検証が行われ、各評価指標と、平均値、標準偏差が出力されます。
ハイパーパラメータのチューニング
予測モデルが決まったら、ハイパーパラメータのチューニングを行います。
デフォルトでは、R2が最適化されるようにランダムグリッドで自動調整が行われます。
パラメータ指定で他の評価指標が最適化されるようにすることも可能です。
tuned_model = tune_model(model) #パラメータチューニングRMSEを最適化する場合。
tuned_model = tune_model(model, optimize='rmse') #RMSEで最適化
モデルの評価、可視化
モデルのチューニングができたので、パラメータ確認や可視化、モデルの検証を行い、モデルを評価します。
以下のコードで、パラメータの確認ができます。
evaluate_model(tuned_model) #パラメータ確認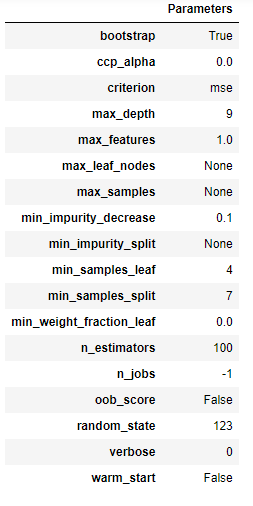
可視化も少ないコードで実施することができます。いくつか紹介いたします。
残差プロット
横軸が予測値、縦軸が残差をプロットしています。
縦軸が0の直線に集まっているほど良いモデルといえます。
plot_model(tuned_model) #残差プロット 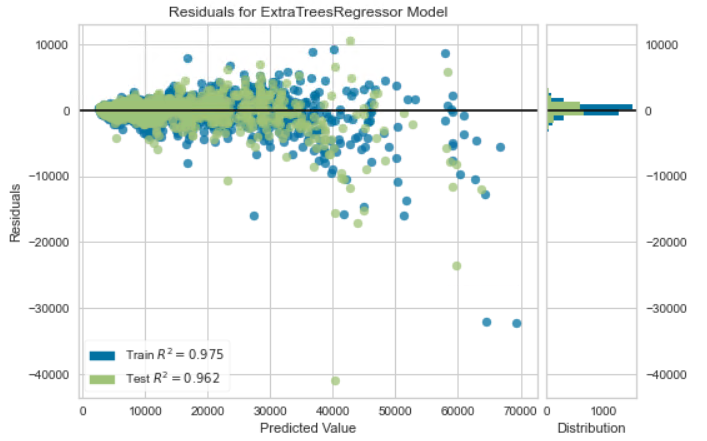
予測誤差プロット
横軸が実際の値、縦軸が予測値をプロットしています。
プロットが傾き1の直線に集まっているほど良いモデルといえます。
plot_model(tuned_model, plot='error') #予測誤差プロット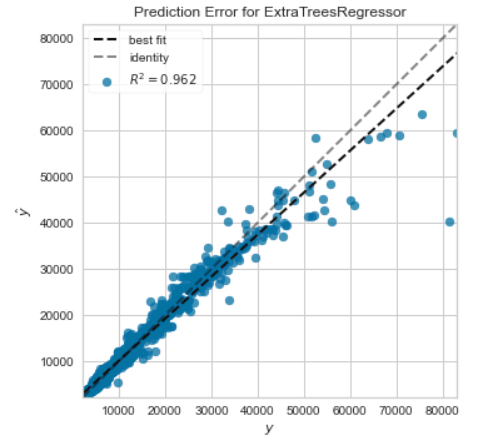
特徴量プロット
横軸が重要度、縦軸が特徴量をプロットしています。
重要度が大きい特徴量の順に表示されます。
結果を見てみると、ダイヤモンドの重さが価格に大きく作用していることがわかります。
plot_model(tuned_model, plot='feature') #特徴量プロット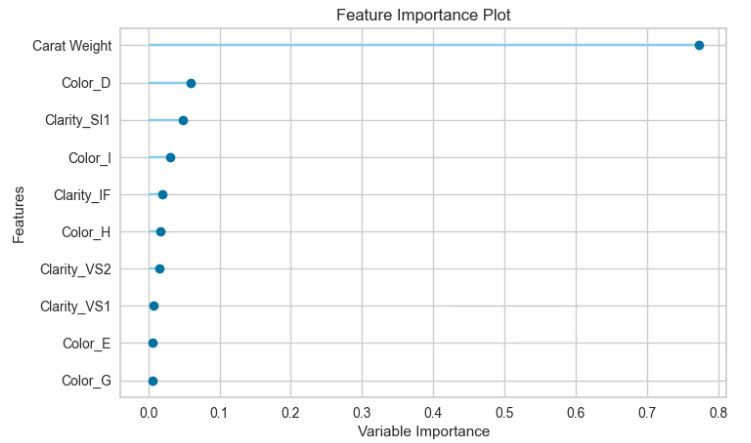
モデルの確定
評価指標や可視化結果を踏まえ、これまでに使用されていないホールドアウトデータを使用して、モデルのパフォーマンスを確定します。
※ホールドアウトは学習データを学習用、評価用で分割して、モデルを評価するテスト手法です。PyCaretではデフォルトで30%のデータが確保されています。
final_model = finalize_model(tuned_model) #モデルの確定予測
作成した学習モデルを使用し、予測を行います。引数にモデル、予測対象のデータを記述します。
result = predict_model(final_model, data = data_unseen) #テストデータで予測実行すると、以下のような結果が出力されます。
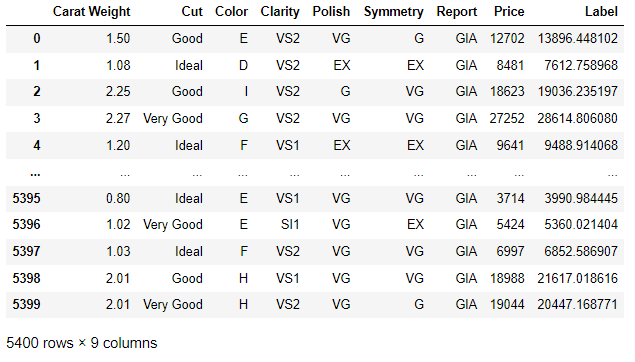
Priceが実際のダイヤモンドの値段、Labelが予測した値段です。
この結果を見てみると、結構いい感じに値段の予測ができていることがわかります。
モデルの保存と読込
最後に、作成したモデルを保存します。また、読み込みも以下のコードで実施することができます。
save_model(final_model,"final_model") #モデルの保存
final_model = load_model("final_model") #モデルの読込保存しておくことで、アプリに組み込んだり、予測の再実験を行うことができます。
以上、PyCaretの扱い方でした。
まとめ
PyCaretの基本的な使い方について紹介させていただきました。
簡単なまとめです!
- AutoMLとは... 簡単に時間をかけず機械学習ができるようになるツール
- PyCaretとは... OSSでpythonベースのAutoMLライブラリ、簡単!!数行で機械学習ができる!
PyCaretのようなAutoMLツールを利用することで、誰でも簡単に機械学習に触れられるので、
初心者をはじめ、普段から機械学習を扱っている方にもおすすめだと思い、記事を書かせていただきました。
最後までお読みいただきありがとうございました。
参考文献
- Pycaret 公式サイト
- PyCaret 公式チュートリアル 「ダイヤモンドの価格予測」
- PyCaret 公式サイト「クイックスタート」