はじめに
Autonomous Databaseにはデータ・ロードを一定間隔で継続的に行うデータ・パイプライン機能があります。本記事では、データ・パイプライン機能を使った定期的な自動データ・ロード、またそのデータを元に、SQL関数としてデータベース内機械学習を行うOML4SQLでの時系列予測をOML Notebooksで定期実行してみました。
1. データ準備
まずは使用するデータを準備します。
今回はAutonomous Databaseのサンプルスキーマ、Sales History(SH)スキーマのsales表を使用します。
sales表のTIME_IDとAMOUNT_SOLDのみの以下のようなデータです。
TIME_ID AMOUNT_SOLD
――――――――――― ――――――――――――――――
20-JAN-98 1205.99
05-APR-98 1250.25
sales表にはTIME_IDが1998年~2001年までのデータがあるので、sales_data_1998.csvのように年ごとのcsvファイルとしてオブジェクト・ストレージに格納し、定期的にADBにロードしていきます。
また、OML用のユーザーOMLをこちらの記事を参考に作成しておきます。
ロード先の表として, OMLユーザーに以下のSALES_DATA表を用意しておきます。
CREATE TABLE SALES_DATA(
TIME_ID DATE,
AMOUNT_SOLD NUMBER(10,2)
);
まだSALES_DATA表にはデータが何も入っていない状態ですが、最終的にはsales_data_1998.csvからsales_data_2001.csvの4年分の時系列データ(約90万行)がロードされます。
2. パイプラインの作成
継続的なデータロードを行うパイプラインをADMINユーザーで以下のSQLで作成します。
BEGIN
DBMS_CLOUD_PIPELINE.CREATE_PIPELINE(
pipeline_name => 'ESM_SALES_FORECAST_PIPELINE',
pipeline_type => 'LOAD',
description => 'Sales data from object store into a table'
);
END;
/
DBMS_CLOUD_PIPELINE.SET_ATTRIBUTEプロシージャで詳細設定を行います。
BEGIN
DBMS_CLOUD_PIPELINE.SET_ATTRIBUTE(
pipeline_name => 'ESM_SALES_FORECAST_PIPELINE',
attributes => JSON_OBJECT(
'credential_name' VALUE 'OCI$RESOURCE_PRINCIPAL',
'location' VALUE 'https://objectstorage.ap-seoul-1.oraclecloud.com/n/xxxxx/b/xxxx/o/',
'table_owner' VALUE 'OML',
'table_name' VALUE 'SALES_DATA',
'format' VALUE '{"type": "csv", "delimiter": "|"}',
'priority' VALUE 'MEDIUM',
'interval' VALUE '60')
);
END;
/
SALES_DATA表の所有者はOMLなので、table_ownerで指定しています。また、今回は1時間毎にロードしたいので、intervalで60と指定します。
3. パイプラインのテスト実行
現在はオブジェクトストレージのバケット内には、sales_data_1998.csvのみ格納されています。
ファイル・フォーマット等に問題がないか確認するため、1度テスト実行します。パイプラインのテスト実行を行うためのプロシージャDBMS_CLOUD_PIPELINE.RUN_PIPELINE_ONCEが用意されています。
BEGIN
DBMS_CLOUD_PIPELINE.RUN_PIPELINE_ONCE(
pipeline_name => 'ESM_SALES_FORECAST_PIPELINE'
);
END;
/
SALES_DATA表のデータを確認してみます。
SELECT * FROM OML.SALES_DATA WHERE ROWNUM <= 5;
TIME_ID AMOUNT_SOLD
____________ ______________
02-JAN-98 24.08
02-JAN-98 24.08
02-JAN-98 24.08
02-JAN-98 24.08
02-JAN-98 24.08
このように、1998年分のデータがSALES_DATA表にロードされたことが分かります。
テスト実行ですので、DBMS_CLOUD_PIPELINE.RESET_PIPELINEプロシージャを使用して、一度パイプラインをリセットし、SALES_DATA表にロードされたデータを削除します。
BEGIN
DBMS_CLOUD_PIPELINE.RESET_PIPELINE(
pipeline_name => 'ESM_SALES_FORECAST_PIPELINE',
purge_data => TRUE
);
END;
/
4. パイプラインの開始
データ・ロードが継続的に行われるようにDBMS_CLOUD_PIPELINE.START_PIPELINEプロシージャを使用してパイプラインの実行を開始します。
BEGIN
DBMS_CLOUD_PIPELINE.START_PIPELINE(
pipeline_name => 'ESM_SALES_FORECAST_PIPELINE'
);
END;
/
SALES_DATA表のデータを確認してみます。
SELECT * FROM OML.SALES_DATA WHERE ROWNUM <= 5;
TIME_ID AMOUNT_SOLD
____________ ______________
02-JAN-98 24.08
02-JAN-98 24.08
02-JAN-98 24.08
02-JAN-98 24.08
02-JAN-98 24.08
この後、1時間ごとにsales_data_1999.csv~sales_data_2001.csvをオブジェクトストレージに格納していきます。
パイプライン機能により、SALES_DATA表に継続的にこれらのcsvファイルのデータをロードしていきます。
5. 時系列予測
今回ロードしたデータを使い、時系列予測を行います。
予測はOML4SQLを使い、環境にはOML Notebooksを使います。
OML Notebooksは、Autonomous Databaseで機械学習を実行するためのユーザー・インタフェースです。詳しくはこちらのチュートリアルをご参照ください。
ESM_SALES_FORECASTというノートブックを作成し、以下のPL/SQLで実行します。
モデル作成はDBMS_DATA_MININGパッケージのCREATE_MODEL2プロシージャで作成します。また、その中のSET_LISTパラメータに指定するSETTING_LISTを作成します。
%script
call DBMS_DATA_MINING.DROP_MODEL (model_name => 'ESM_SALES_FORECAST'); -- 既に同名のモデルが存在する場合はdrop
DECLARE
v_setlst DBMS_DATA_MINING.SETTING_LIST;
BEGIN
v_setlst(dbms_data_mining.ALGO_NAME) := dbms_data_mining.ALGO_EXPONENTIAL_SMOOTHING;
V_setlst(dbms_data_mining.EXSM_INTERVAL):= dbms_data_mining.EXSM_INTERVAL_QTR;-- Quarter間隔指定
V_setlst(dbms_data_mining.EXSM_PREDICTION_STEP) := '4'; -- 4ステップ先の予測を行う
V_setlst(dbms_data_mining.EXSM_MODEL) := dbms_data_mining.EXSM_HW; -- Holt-Winters三重指数平滑法モデル、加法型傾向、積乗型季節性が適用
V_setlst(dbms_data_mining.EXSM_SEASONALITY) := '4'; -- 季節性循環の長さは四半期ごと
DBMS_DATA_MINING.CREATE_MODEL2(
MODEL_NAME => 'ESM_SALES_FORECAST',
MINING_FUNCTION => 'TIME_SERIES',
DATA_QUERY => 'select * from sales_data',
SET_LIST => v_setlst,
CASE_ID_COLUMN_NAME => 'TIME_ID',
TARGET_COLUMN_NAME =>'AMOUNT_SOLD');
END;
- ALGO_NAME:アルゴリズム名を指定します。今回は時系列予測なので、指数平滑法(Exponential Smoothing)とします。
- EXSM_INTERVAL:累積される等間隔時期列の間隔区間を指定します。今回は四半期ごとに予測を行うので、EXSM_INTERVAL_QTRとします。
- EXSM_PREDICTION_STEP:予測を先に進めるステップ数を指定します。1~30で指定できますが、今回はその次の年の四半期の予測を行うので、4とします。
- EXSM_MODEL:指数平滑法モデルを指定します。今回はHolt-Wintersの三重指数平滑法モデル、加法的傾向、乗法的季節性が適用されるEXSM_HWとします。
- EXSM_SEASONALITY:季節的な周期の長さとして正の整数値を指定します。今回は4つの観測グループごとに1回の季節的な周期が形成されるよう4とします。
指数平滑法の設定については、こちらのドキュメントをご参照ください。
DBMS_DATA_MINING.CREATE_MODEL2プロシージャの各設定は以下です。
- MODEL_NAME:モデル名を指定します。一意の必要があるため、モデル作成前にDBMS_DATA_MINING.DROP_MODELで既に同名のモデルが存在する場合はdropします。
- MINING_FUNCTION:機械学習ファンクションを指定します。今回は時系列予測なのでTIME_SERIESとします。他には、分類(Classification)、回帰(Regression)、クラスタリング(Clustering)などがあります。詳細はこちらのドキュメントをご参照ください。
- DATA_QUERY:モデルを構築するための学習データを提供するクエリを指定します。CREATE_MODEL2プロシージャでは、入力はクエリなので、ユーザーはそのような一時データベース・オブジェクトを作成する必要がありません。一方CREATE_MODELプロシージャの入力は表またはビューであり、そのようなオブジェクトがまだ存在しない場合はユーザーが作成する必要があります。今回はすでに存在するSALES_DATA表をクエリしているので、CREATE_MODELプロシージャで
data_table_name => 'SALES_DATA'の形でも実行できます。 - SET_LIST:作成した設定リストを指定します。
- CASE_ID_COLUMN_NAME:一連のターゲット値を指定します。今回は時系列予測なのでTIME_ID列です。
- TARGET_COLUMN_NAME:観測された時系列値の計算に使用される列を指定します。今回はAMOUNT_SOLD列です。
上記を実行しモデル作成後、以下で各設定を確認します。
%sql
SELECT SETTING_NAME, SETTING_VALUE
FROM USER_MINING_MODEL_SETTINGS
WHERE MODEL_NAME = UPPER('ESM_SALES_FORECAST')
ORDER BY SETTING_NAME;
_______________________________ _____________________________
ALGO_NAME ALGO_EXPONENTIAL_SMOOTHING
EXSM_ACCUMULATE EXSM_ACCU_TOTAL
EXSM_CONFIDENCE_LEVEL .95
EXSM_INTERVAL EXSM_INTERVAL_QTR
EXSM_MODEL EXSM_WINTERS
EXSM_NMSE 3
EXSM_OPTIMIZATION_CRIT EXSM_OPT_CRIT_LIK
EXSM_PREDICTION_STEP 4
EXSM_SEASONALITY 4
EXSM_SETMISSING EXSM_MISS_AUTO
ODMS_DETAILS ODMS_ENABLE
ODMS_MISSING_VALUE_TREATMENT ODMS_MISSING_VALUE_AUTO
ODMS_SAMPLING ODMS_SAMPLING_DISABLE
PREP_AUTO ON
また、以下で指数平滑法モデル(ESM)のモデルグローバル情報(DM$VGmodel_name)を確認します。
詳しくはこちらのドキュメントをご参照ください。
%sql
SELECT NAME, round(NUMERIC_VALUE,4), STRING_VALUE
FROM DM$VGESM_SALES_FORECAST
ORDER BY NAME;
NAME ROUND(NUMERIC_VALUE,4) STRING_VALUE
____________________ _________________________ _______________
-2 LOG-LIKELIHOOD -53.0369
AIC 116.0739
AICC
ALPHA 0.0001
AMSE 59656349575.7181
BETA 0.0001
BIC 113.0053
CONVERGED YES
INITIAL LEVEL 6315751.4228
INITIAL TREND -115056.5622
MAE 238712.2716
MSE 84281023625.6994
NUM_ROWS 178834
SIGMA 0.0549
STD 0.0549
実際のモデル出力はDM$VPmodel_nameで確認できます。
以下では四半期の最初の月と、その月に対応する実際の値(ACTUAL_SOLD)と予測値(FORECAST_SOLD)、下限値、上限値を問合せています。
%sql
SELECT TO_CHAR(CASE_ID,'YYYY-MON') DATE_ID,
round(VALUE,2) ACTUAL_SOLD,
round(PREDICTION,2) FORECAST_SOLD,
abs(round(VALUE,2) - round(PREDICTION,2)) GAP
FROM DM$VPESM_SALES_FORECAST
ORDER BY CASE_ID DESC;
DATE_ID ACTUAL_SOLD FORECAST_SOLD GAP
___________ ______________ ________________ ____________
1999-OCT 5395280.39
1999-JUL 5510339.81
1999-APR 5625399.24
1999-JAN 5740458.66
1998-OCT 5937413.71 5855509.86 81903.85
1998-JUL 6071823.1 5970567.32 101255.78
1998-APR 5593994.14 6085694.46 491700.32
1998-JAN 6480684 6200694.86 279989.14
まだ1998年分のデータしかロードされていないため、1999年のACTUAL_SOLDはありません。
6. ノートブックのジョブの作成
パイプラインによる自動データ・ロードに合わせて、モデルの作成も定期実行させることができます。OML UIのホーム画面のジョブをクリックします。
以下のように設定します。
- 名前:ESM_SALES_FORECAST
- ノートブック:先ほど作成したESM_SALES_FORECASTを選択
- 繰返し頻度:1時間
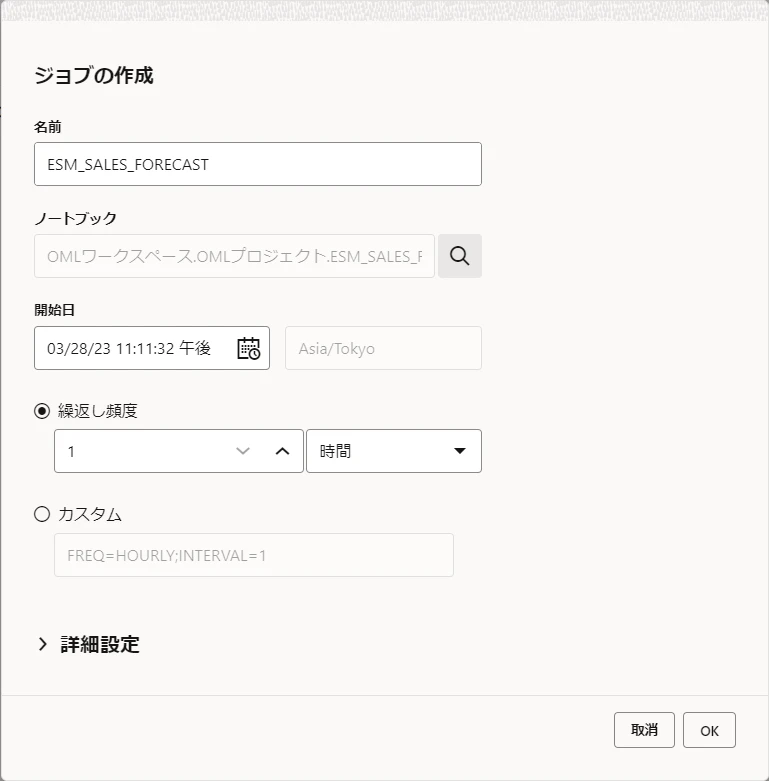
こちらで作成を行い、1時間ごとにオブジェクトストレージへsales_data_1999.csv~sales_data_2001.csvをアップロードします。
7. 予測の変化
1時間ごとに各年のデータを追加していくことで、予測にどのような変化があるか見てみます。
OML Notebooksで以下のSQLを実行し、Line Chartをクリックすることで実行結果をチャート化することができます。
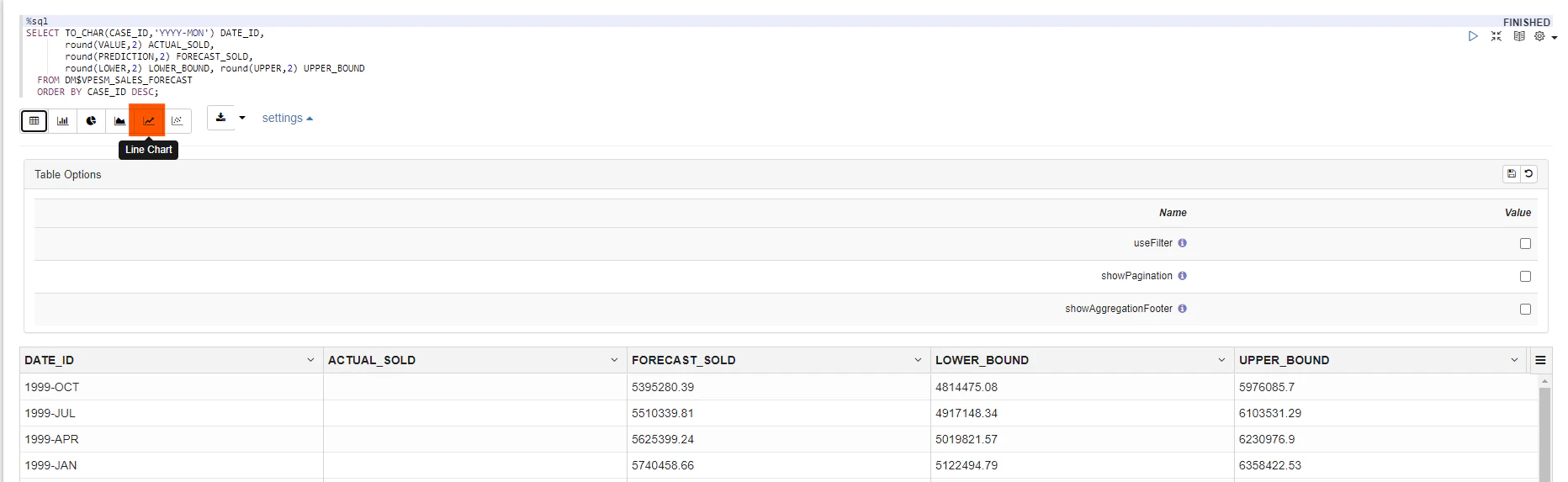
各年のモデル出力とチャートは以下のようになりました。
- 1998年~1999年
DATE_ID ACTUAL_SOLD FORECAST_SOLD GAP
___________ ______________ ________________ ____________
2000-OCT 4827041.87
2000-JUL 5111805.69
2000-APR 4520296.68
2000-JAN 5444595.44
1999-OCT 5373678.67 5400813.22 27134.55
1999-JUL 5827050.15 5697747.75 129302.4
1999-APR 4925471.63 5029139.3 103667.67
1999-JAN 6093747.21 6038093.86 55653.35
1998-OCT 5937413.71 5975395.32 37981.61
1998-JUL 6071823.1 6297301.51 225478.41
1998-APR 5593994.14 5534104.5 59889.64
1998-JAN 6480684 6632453.34 151769.34

- 1998年~2000年
DATE_ID ACTUAL_SOLD FORECAST_SOLD GAP
___________ ______________ ________________ ____________
2001-OCT 5741159.79
2001-JUL 5847814.21
2001-APR 5157881.22
2001-JAN 6025411.47
2000-OCT 6287646.92 5837431.55 450215.37
2000-JUL 6121239.29 5939647.78 181591.51
2000-APR 5371730.92 5234134.47 137596.45
2000-JAN 5984889.49 6118465.02 133575.53
1999-OCT 5373678.67 5960787.38 587108.71
1999-JUL 5827050.15 6078520.78 251470.63
1999-APR 4925471.63 5374830.2 449358.57
1999-JAN 6093747.21 6283667.64 189920.43
1998-OCT 5937413.71 6106915.06 169501.35
1998-JUL 6071823.1 6223325.23 151502.13
1998-APR 5593994.14 5483867.05 110127.09
1998-JAN 6480684 6401774.46 78909.54

- 1998年~2001年
DATE_ID ACTUAL_SOLD FORECAST_SOLD GAP
___________ ______________ ________________ ____________
2002-OCT 7821557.48
2002-JUL 7907806.5
2002-APR 7151013.4
2002-JAN 7819637.04
2001-OCT 7470897.52 7154087.56 316809.96
2001-JUL 7195998.63 7376866.6 180867.97
2001-APR 6922468.39 5930069.14 992399.25
2001-JAN 6547097.44 6500126.23 46971.21
2000-OCT 6287646.92 5920687.51 366959.41
2000-JUL 6121239.29 5845169.13 276070.16
2000-APR 5371730.92 5317402.43 54328.49
2000-JAN 5984889.49 5644291.53 340597.96
1999-OCT 5373678.67 5601170.87 227492.2
1999-JUL 5827050.15 5515472.1 311578.05
1999-APR 4925471.63 5535877.14 610405.51
1999-JAN 6093747.21 6223664.95 129917.74
1998-OCT 5937413.71 5978510.78 41097.07
1998-JUL 6071823.1 6205873.36 134050.26
1998-APR 5593994.14 5868257.56 274263.42
1998-JAN 6480684 6402750.9 77933.1

まとめ
今回はAutonomous Databaseのデータ・パイプライン機能を使って、データ・ロードの定期実行を自動化し、さらにOML4SQLとOML Notebooksでの時系列予測も定期実行する方法をご紹介しました。オブジェクトストレージにデータを入れておくだけで、Autonomous Database側で予測まで自動で行ってくれる便利な機能です。さらに付属のOracle APEXを使えば、Webアプリの形でモデル出力とチャートを確認することもできます。