今回は多段の処理を行うFLOWをデザインしてみます。
今回は完結編の後半として多段構成のFLOWをデザインして検証します。
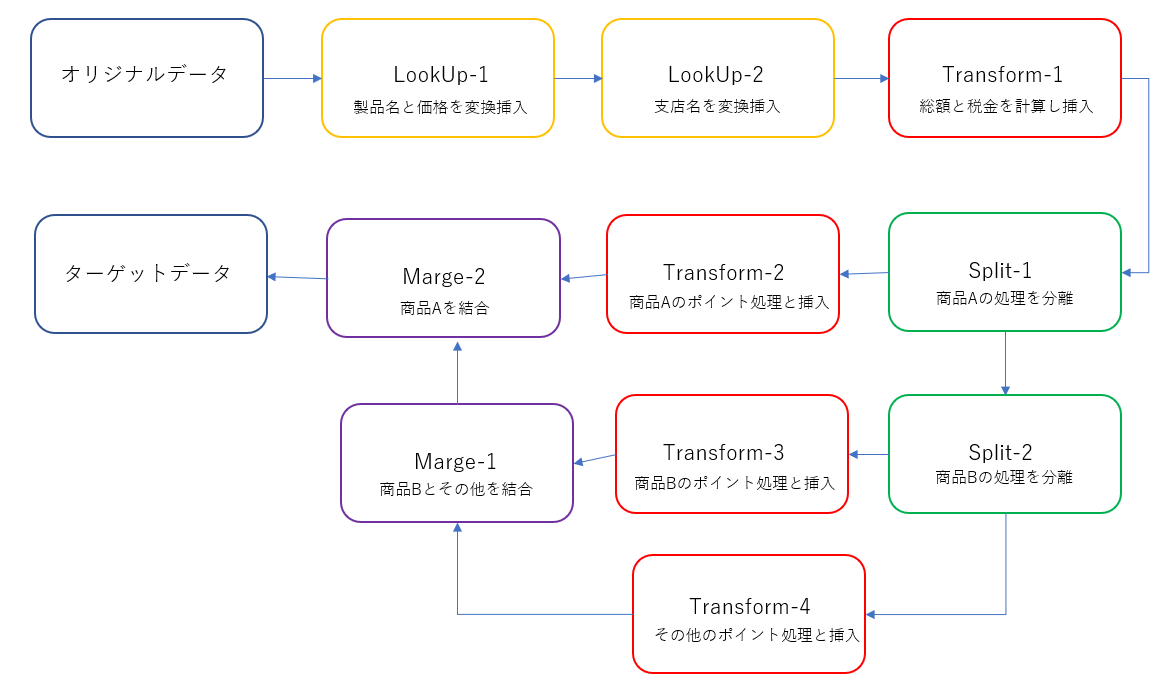
ザクっとした流れ的なものはこんな感じを想定します。厳密にデザインしたデータベースであれば、**「そもそもそんな事・・・」**と厳しいご指摘を頂くかとは思いますが、今回はこの流れでご勘弁ください。
今回初登場の設定を紹介
今まで幾つかの設定項目に関する検証を行ってきましたので、ここでは今回の検証で初登場の新参者に関する設定項目を確認します。
SplitとMerge
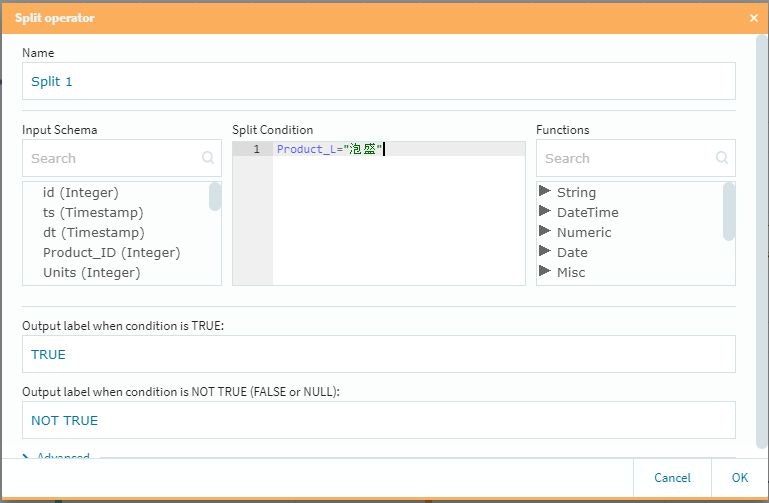
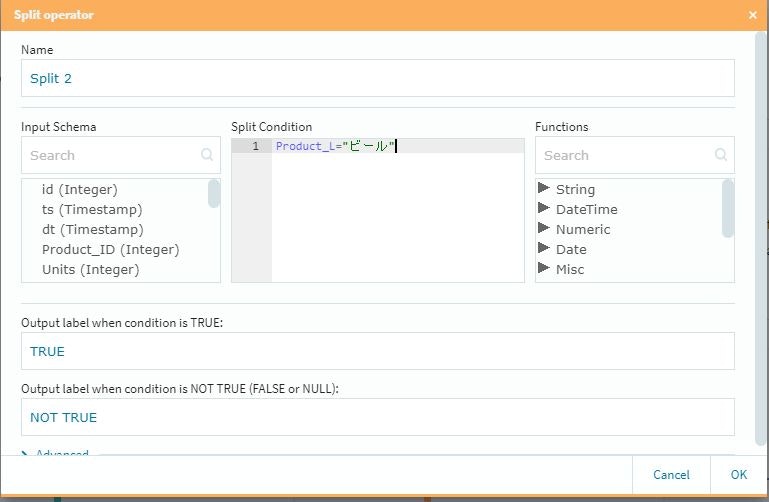
この2つは対で使用する形になります。また設定項目はSplit側にのみ存在していて、いわゆる**「条件分岐」の仕事を行います。今回は泡盛とビールに対して個別のポイントを付与し、それ以外の商品に対しては一律のポイントを「後付け」**で追加する事にしました。
Transformの設定
また、今回の検証では複数のTransformを仕掛けましたので、それぞれの内容を確認しておきます。
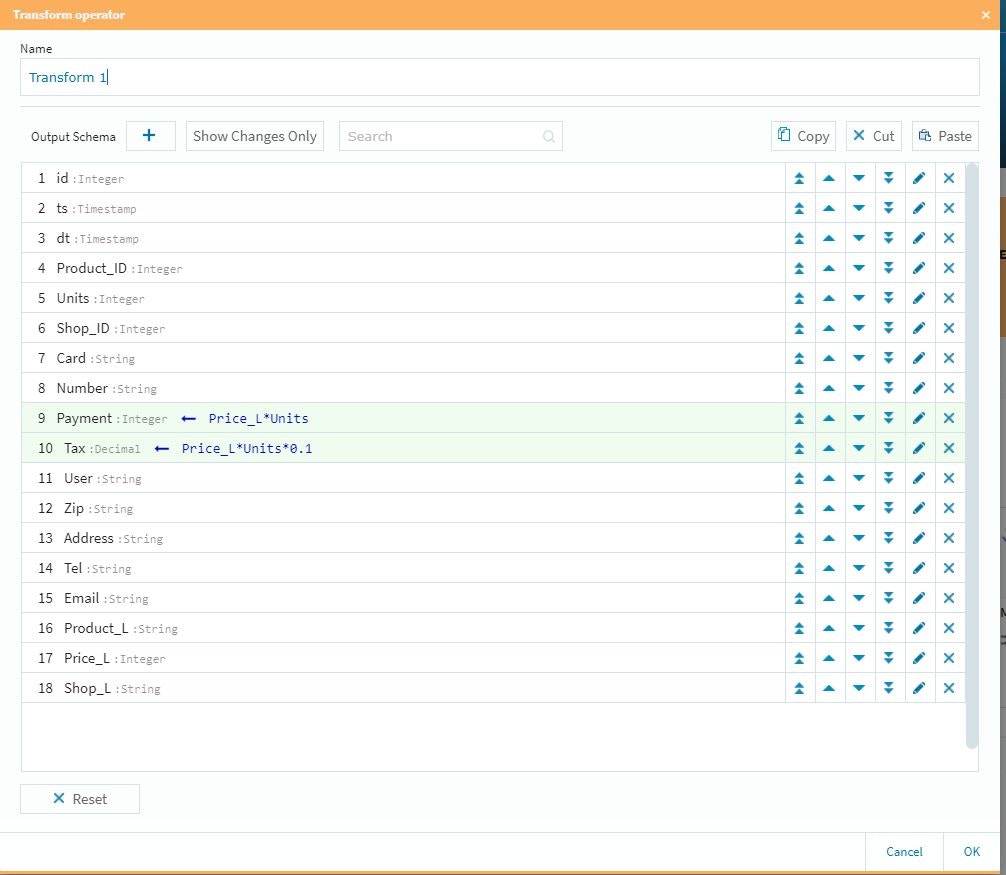
まずは、個数と単価から購入総額と税金を計算して新規のデータとしてテーブルを拡張させます。
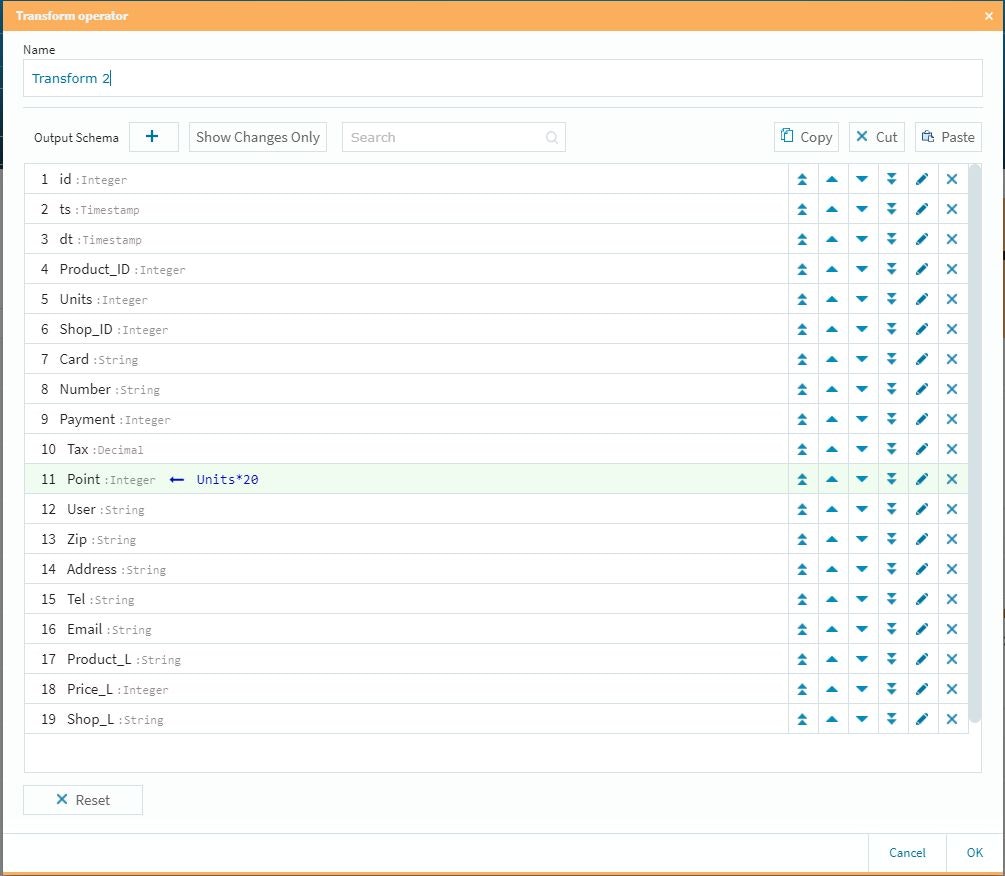
次に分岐後の仕掛けとして想定ポイント付与を行います。今回は泡盛20ポイント、ビール15ポイント、その他10ポイントにしています。
これらの仕掛けを行った全体のFLOWがこの形になりました。
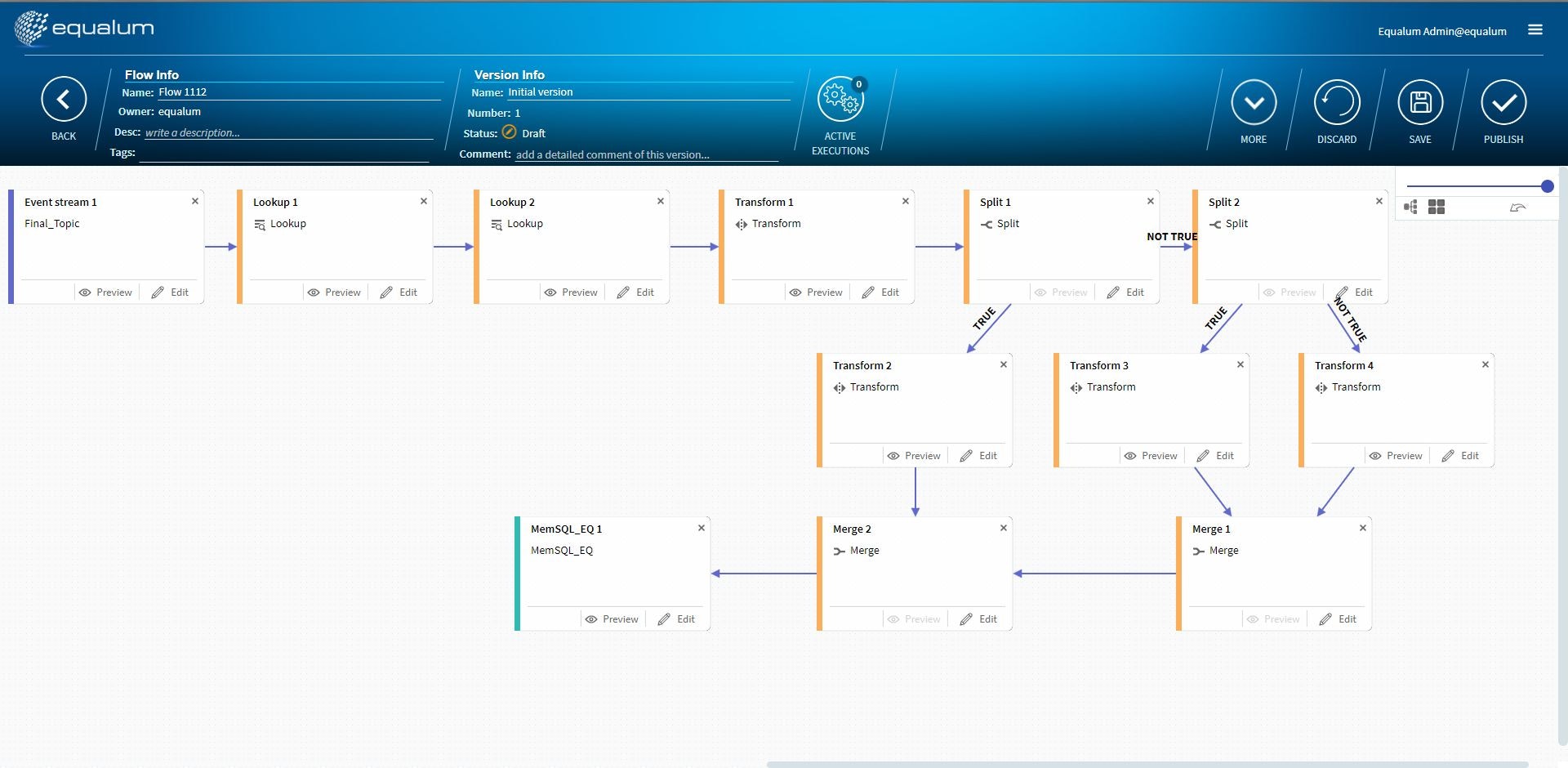
少し重要な点を・・・
前回までの検証で得られた情報と、今回の新規分を合わせれば此処までのデザイン所要時間は15分程度で行けると思います。(デザインツールの見た目を調整する時間の方が長かったです・・・)
また、最終的に収めるテーブルの設定に関して、今回のFLOWでは途中に新規設定のカラムが幾つか出てきますので(オリジナルのデータでは整数データのID経由の参照データ変換等)最後のMemSQL上へ書き出すテーブル設定は、少し慎重に確認作業を行う必要があります。
作業的には、新規に入ってきたデータをアクティブにする作業になりますので、以下の設定を忘れないように実施します。
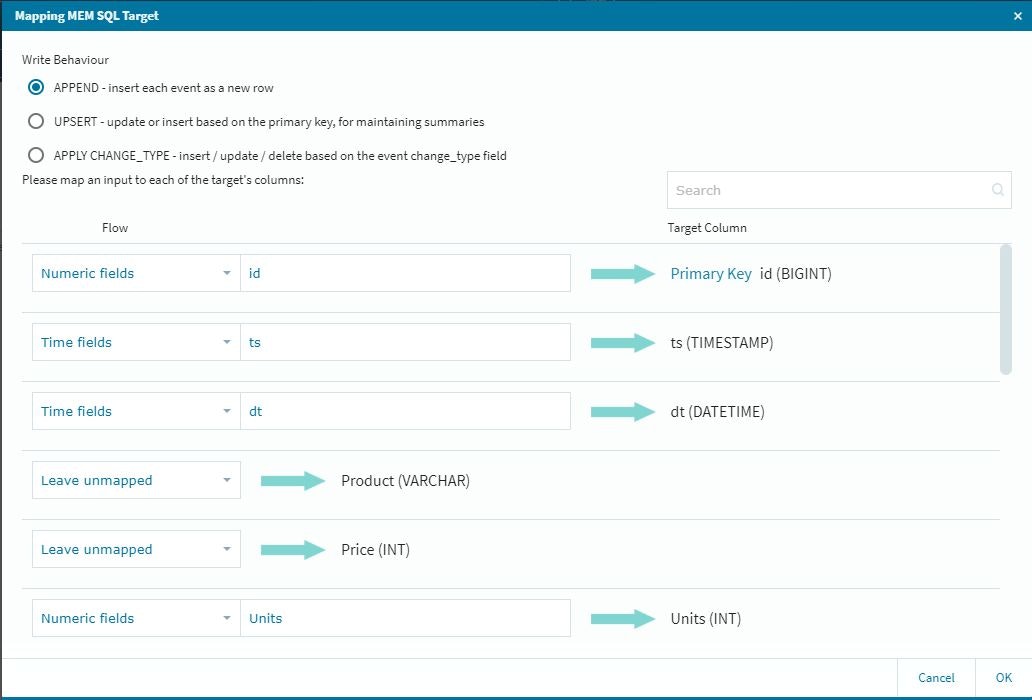
この段階では参照してきた情報がアクティブになっていませんので、それぞれの項目に関して適切な設定作業を行います。
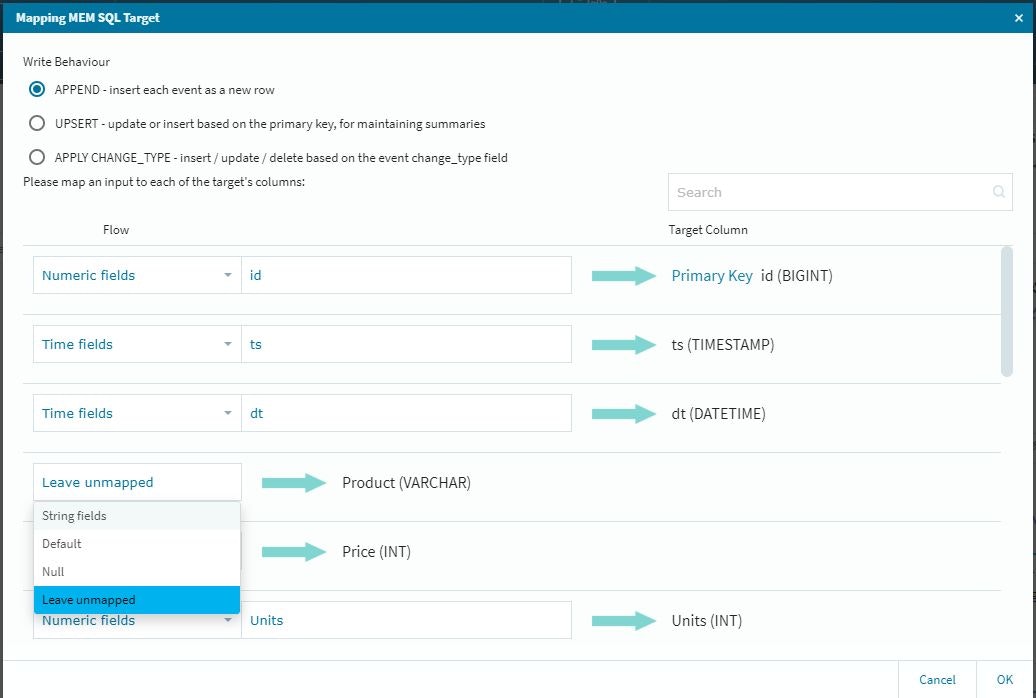
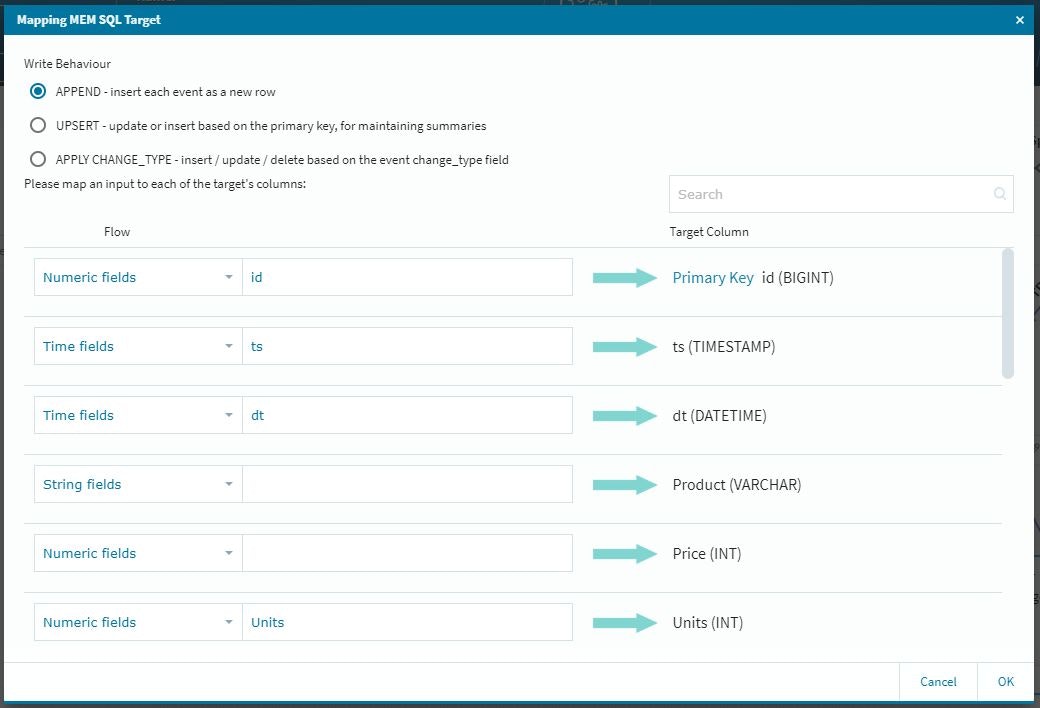
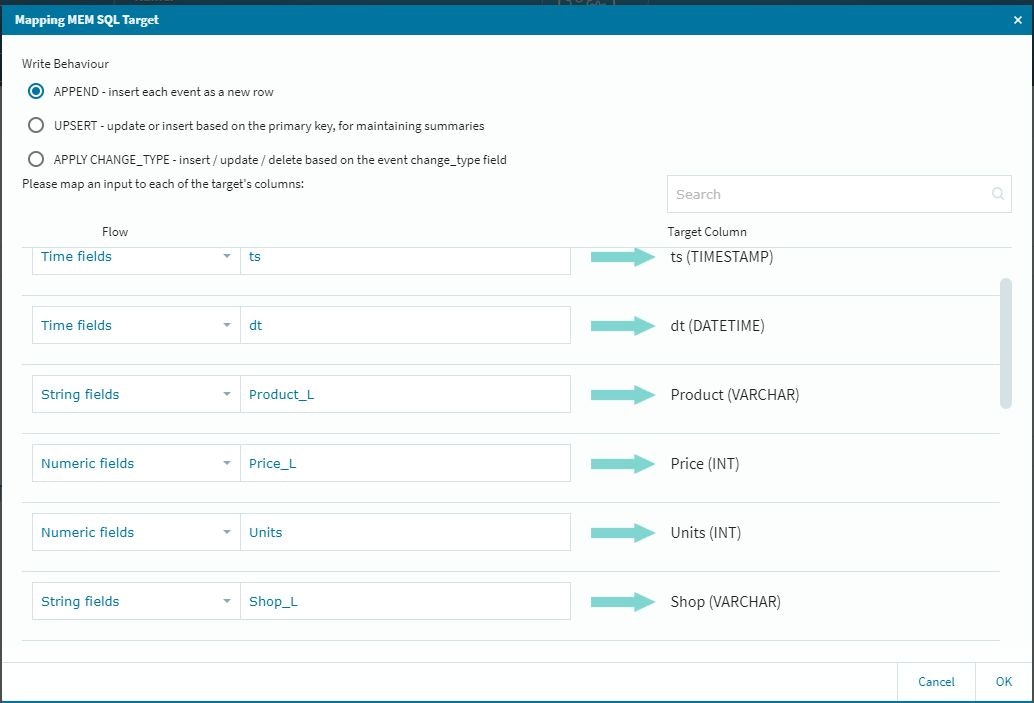
これで、テーブルに参照データが納まる形になります。(前回のルックアップの際に補足しておけば良かったのですが・・・)
さて実行!!
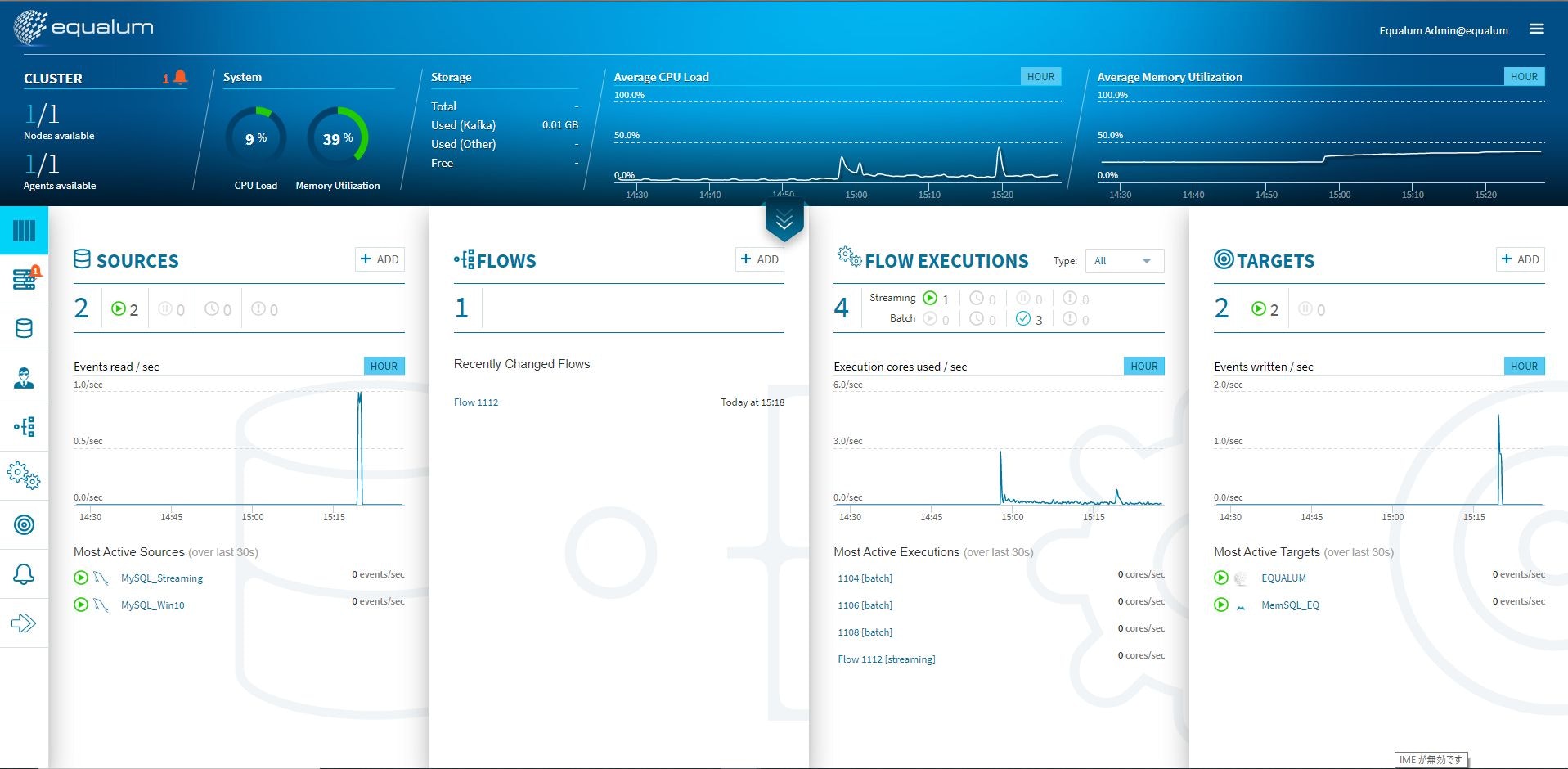
今までの検証手順通りに配備が出来たら、Pythonで作成した自動データ生成スクリプトを実行します。
既に口を開けた状態でkafkaが待っていますので、データ更新が始まったと同時に定義したFLOWを自動的に実行していきます。
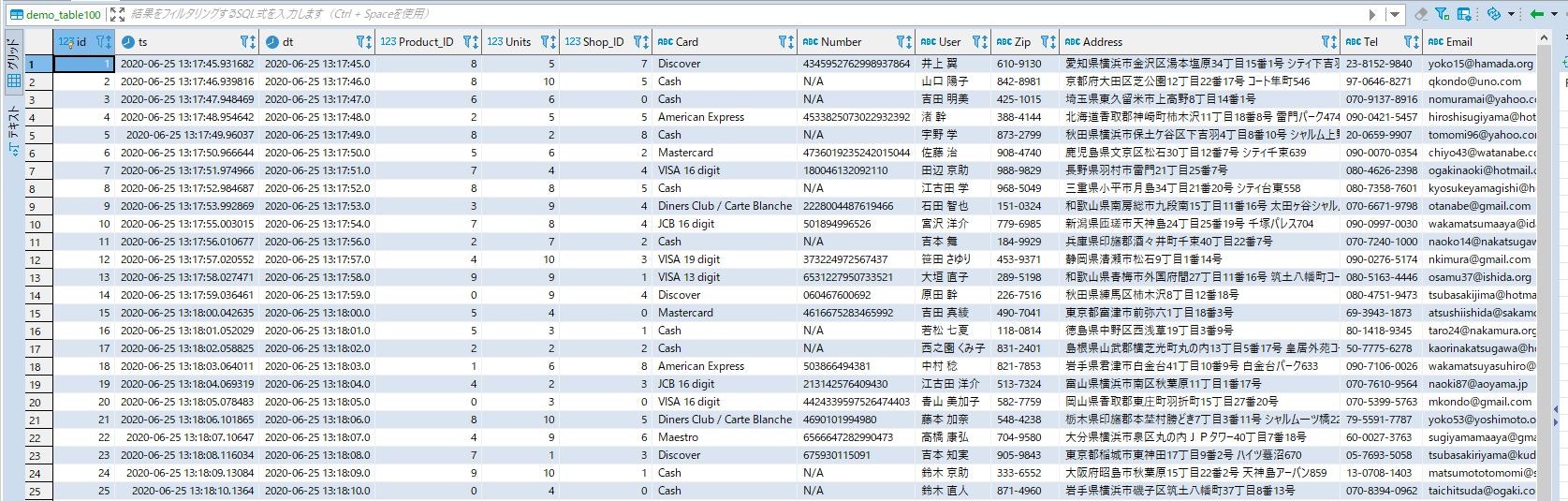
これが上流側のデータソースに流れ込んだデータの状況です。
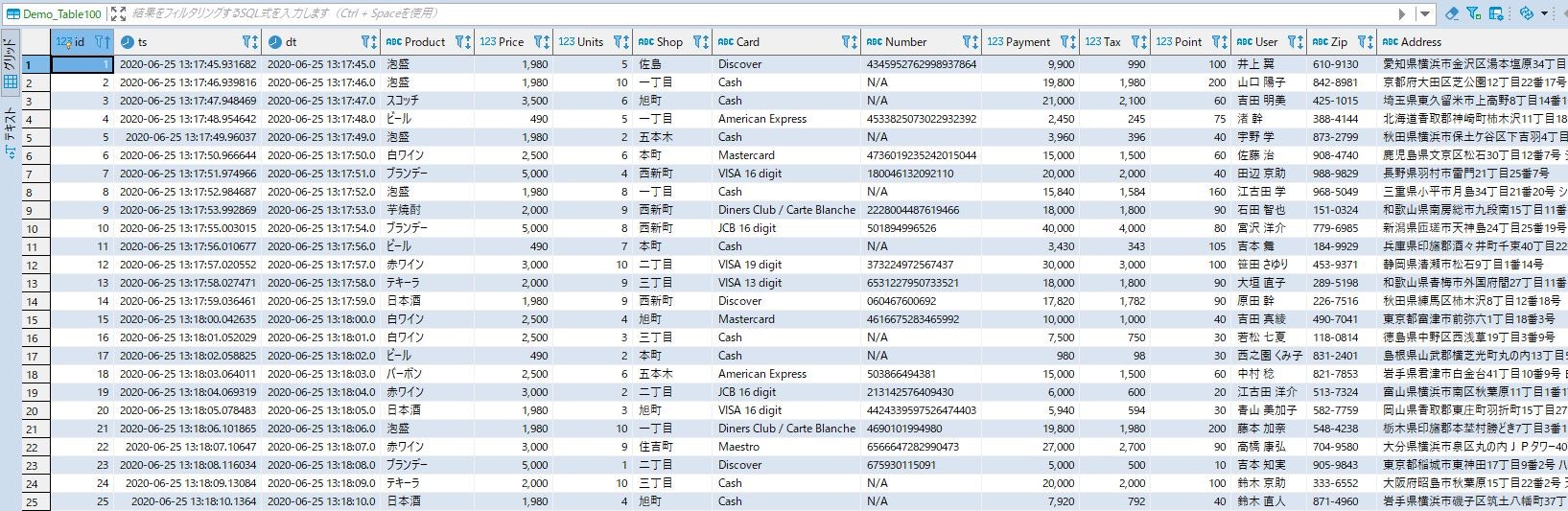
こちらが今回処理をFLOW定義して生成されたデータの状況になります(今回、タイムゾーンの設定を見直して再度検証しました)
また、特筆すべき点は、上流側のMySQLが付与したタイムスタンプと、EqualumのFLOWオペレーション後の下流側MemSQLが付与したタイムスタンプが・・・・(汗)
上流側のMySQLに記録されたデータ(タイムスタンプ値周辺)
1|2020-06-25 13:17:45.931682|2020-06-25 13:17:45.0| 8| 5| 7|Discover
2|2020-06-25 13:17:46.939816|2020-06-25 13:17:46.0| 8| 10| 5|Cash
3|2020-06-25 13:17:47.948469|2020-06-25 13:17:47.0| 6| 6| 0|Cash
4|2020-06-25 13:17:48.954642|2020-06-25 13:17:48.0| 2| 5| 5|American Express
5| 2020-06-25 13:17:49.96037|2020-06-25 13:17:49.0| 8| 2| 8|Cash
6|2020-06-25 13:17:50.966644|2020-06-25 13:17:50.0| 5| 6| 2|Mastercard
7|2020-06-25 13:17:51.974966|2020-06-25 13:17:51.0| 7| 4| 4|VISA 16 digit
8|2020-06-25 13:17:52.984687|2020-06-25 13:17:52.0| 8| 8| 5|Cash
9|2020-06-25 13:17:53.992869|2020-06-25 13:17:53.0| 3| 9| 4|Diners Club / Carte Blanche
下流側のMemSQLに記録されたデータ(タイムスタンプ値周辺)
1|2020-06-25 13:17:45.931682|2020-06-25 13:17:45.0|泡盛 | 1980| 5|佐島 |Discover
2|2020-06-25 13:17:46.939816|2020-06-25 13:17:46.0|泡盛 | 1980| 10|一丁目 |Cash
3|2020-06-25 13:17:47.948469|2020-06-25 13:17:47.0|スコッチ | 3500| 6|旭町 |Cash
4|2020-06-25 13:17:48.954642|2020-06-25 13:17:48.0|ビール | 490| 5|一丁目 |American Exp
5| 2020-06-25 13:17:49.96037|2020-06-25 13:17:49.0|泡盛 | 1980| 2|五本木 |Cash
6|2020-06-25 13:17:50.966644|2020-06-25 13:17:50.0|白ワイン | 2500| 6|本町 |Mastercard
7|2020-06-25 13:17:51.974966|2020-06-25 13:17:51.0|ブランデー | 5000| 4|西新町 |VISA 16 di
8|2020-06-25 13:17:52.984687|2020-06-25 13:17:52.0|泡盛 | 1980| 8|一丁目 |Cash
9|2020-06-25 13:17:53.992869|2020-06-25 13:17:53.0|芋焼酎 | 2000| 9|西新町 |Diners Club
また、処理が最初にMySQLに挿入された最初のデータ起点で開始され、その後ストリーミングで連続処理されて行きますので、データの量にはあまり関係ない(貯めてドン!のバッチ系は・・・)ので、複数のFLOWも並行して処理しても問題無いでしょう。
今回のまとめ
今回は前回の続きで少し複雑なFLOW定義をして検証を行いました。データの最新動向を手軽に取り扱えるという点においては、Equalumのゼロコーディング技術は大変興味深く、データの民主化にとって非常に心強い手助けになるという事を確実にご理解頂けたかと思います。
従来からのCDC技術に最新のメッセージ制御技術であるkafkaと、高速・高効率な処理を提供するSparkをプログラム不要で組み合わせて誰でも使える環境として、Equalumが今後もたらすこの領域に対する影響は、非常に大きいと思いますし同時に新しいアイディアをデータ起点で創りだせる環境としても非常に使い勝手の良い製品だと言えるでしょう。
基本的なSQLとデータの意味(カラムの内容)が判れば、非常に高度なリアルタイム性でデータをストリーミングしながら処理を行う事が可能になる・・・AI/BIといった活用系のソリューションに対する投資対効果をさらに向上させると同時に、その先に新しいアイディアや問題解決の糸口をデータ・ドリブンで獲得出来るということは・・・
Dx時代のデータ・ドリブンはEqualumで変わる・・・
データを貯めてから考えるか?
データを流しながら適時対応していくか?
これは、データを諦めずに**「変化に強い高速なデータ・ドリブン環境」**を実現する上で非常に重要なポイントであると同時に、データを貯めてから考えるか?データを貯めながら適時対応していくか?という、新しい2者択一が求められる時代になった事を意味しています。
次回は番外編としてEqualumにもれなく付いてくるバッチ系の簡単な検証を追加して前半戦を終了させて頂きます。
謝辞
本検証は、Equalum社の特別の許可を得て実施しています。この貴重な機会を設定して頂いたEqualum社に対して感謝の意を表すると共に、本内容とEqualum社の公式ホームページで公開されている内容等が異なる場合は、Equalum社の情報が優先する事をご了解ください。