Equalumの処理能力を探る・・?!
基本的に今回の一連の検証に関しては、約1秒(Pythonのsleep関数を使って設定)間隔で、上流側のCDC設定を行っているMySQL側にPython経由でデータを送り込んで作業を実施していますが、ここで少し0-400m的なチャレンジ企画を行ってみようと思います。
設定環境
環境としては
(1)Equalumサーバ Core i7 (4C8T) 32GB 256GB SSD CentOS7
(2)MemSQLサーバ Core i7 (4C8T) 32GB 256GB SSD CentOS7
(3)MySQLサーバ Core i7 (4C8T) 32GB 512GB SSD Windows10
> Windows版のMySQLを利用し、同環境上にPythonを稼働
> PCはベアボーンで構成した自作マシン
> ネットワークはGbE(WiFiと兼用の市販汎用品)
になります。
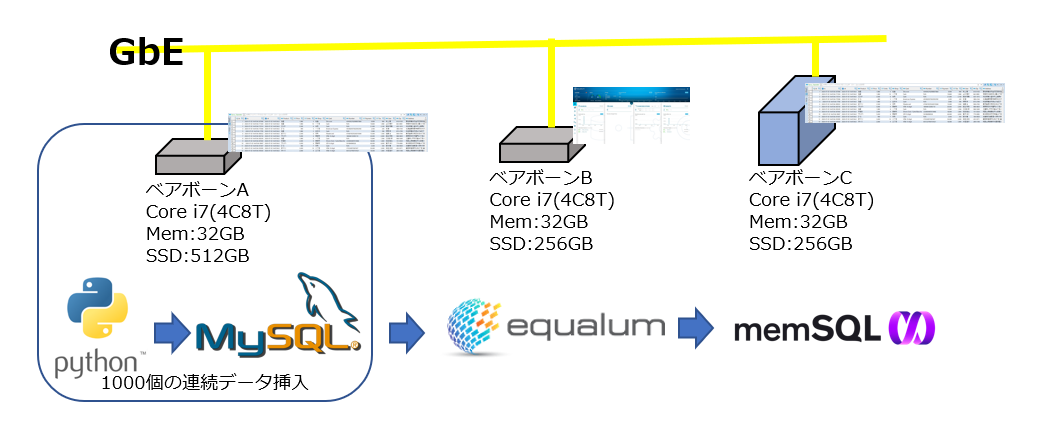
使ったPythonスクリプトは以前の物から時間稼ぎの処理を取り除き、上流側のデータソースへ1000個のデータ生成を設定して一気に連続して挿入処理を実施し、ターゲット側のデータソースにそのままの形(レプリケーションと同じ)でEqualumに処理させる形の検証を行いました。
では検証結果を・・・
MySQL側の処理結果
1|2020-07-03 14:47:04.167946|2020-07-03 14:47:04.0|泡盛 | 1980| 5|佐島 |
2|2020-07-03 14:47:04.171034|2020-07-03 14:47:04.0|泡盛 | 1980| 10|一丁目 |
3|2020-07-03 14:47:04.173314|2020-07-03 14:47:04.0|スコッチ | 3500| 6|旭町 |
4|2020-07-03 14:47:04.175366|2020-07-03 14:47:04.0|ビール | 490| 5|一丁目 |
5| 2020-07-03 14:47:04.17785|2020-07-03 14:47:04.0|泡盛 | 1980| 2|五本木 |
>>> 途中省略
498|2020-07-03 14:47:05.363334|2020-07-03 14:47:05.0|日本酒 | 1980| 8|一丁目 |
499|2020-07-03 14:47:05.365319|2020-07-03 14:47:05.0|テキーラ | 2000| 10|三丁目 |
500|2020-07-03 14:47:05.367315|2020-07-03 14:47:05.0|テキーラ | 2000| 3|住吉町 |
501|2020-07-03 14:47:05.369285|2020-07-03 14:47:05.0|テキーラ | 2000| 6|佐島 |
502|2020-07-03 14:47:05.371346|2020-07-03 14:47:05.0|芋焼酎 | 2000| 7|住吉町 |
>>> 途中省略
996|2020-07-03 14:47:06.487793|2020-07-03 14:47:06.0|テキーラ | 2000| 6|五本木 |
997|2020-07-03 14:47:06.489917|2020-07-03 14:47:06.0|泡盛 | 1980| 2|二丁目 |
998|2020-07-03 14:47:06.491941|2020-07-03 14:47:06.0|日本酒 | 1980| 9|古橋 |
999|2020-07-03 14:47:06.493771|2020-07-03 14:47:06.0|バーボン | 2500| 8|西新町 |
1000|2020-07-03 14:47:06.495692|2020-07-03 14:47:06.0|スコッチ | 3500| 7|旭町 |
MemSQL側の処理結果
1|2020-07-03 14:47:04.167946|2020-07-03 14:47:04.0|泡盛 | 1980| 5|佐島 |
2|2020-07-03 14:47:04.171034|2020-07-03 14:47:04.0|泡盛 | 1980| 10|一丁目 |
3|2020-07-03 14:47:04.173314|2020-07-03 14:47:04.0|スコッチ | 3500| 6|旭町 |
4|2020-07-03 14:47:04.175366|2020-07-03 14:47:04.0|ビール | 490| 5|一丁目 |
5| 2020-07-03 14:47:04.17785|2020-07-03 14:47:04.0|泡盛 | 1980| 2|五本木 |
>>> 途中省略
498|2020-07-03 14:47:05.363334|2020-07-03 14:47:05.0|日本酒 | 1980| 8|一丁目 |
499|2020-07-03 14:47:05.365319|2020-07-03 14:47:05.0|テキーラ | 2000| 10|三丁目 |
500|2020-07-03 14:47:05.367315|2020-07-03 14:47:05.0|テキーラ | 2000| 3|住吉町 |
501|2020-07-03 14:47:05.369285|2020-07-03 14:47:05.0|テキーラ | 2000| 6|佐島 |
502|2020-07-03 14:47:05.371346|2020-07-03 14:47:05.0|芋焼酎 | 2000| 7|住吉町 |
>>> 途中省略
996|2020-07-03 14:47:06.487793|2020-07-03 14:47:06.0|テキーラ | 2000| 6|五本木 |
997|2020-07-03 14:47:06.489917|2020-07-03 14:47:06.0|泡盛 | 1980| 2|二丁目 |
998|2020-07-03 14:47:06.491941|2020-07-03 14:47:06.0|日本酒 | 1980| 9|古橋 |
999|2020-07-03 14:47:06.493771|2020-07-03 14:47:06.0|バーボン | 2500| 8|西新町 |
1000|2020-07-03 14:47:06.495692|2020-07-03 14:47:06.0|スコッチ | 3500| 7|旭町 |
各ポイントでの数値比較
# 最初のデータに関するタイムスタンプ情報
MySQL 1|2020-07-03 14:47:04.167946|2020-07-03 14:47:04.0
MemSQL 1|2020-07-03 14:47:04.167946|2020-07-03 14:47:04.0
# 中間データに関するタイムスタンプ情報
MySQK 500|2020-07-03 14:47:05.367315|2020-07-03 14:47:05.0
MemSQL 500|2020-07-03 14:47:05.367315|2020-07-03 14:47:05.0
# 最終データに関するタイムスタンプ情報
MySQL 1000|2020-07-03 14:47:06.495692|2020-07-03 14:47:06.0
MemSQL 1000|2020-07-03 14:47:06.495692|2020-07-03 14:47:06.0
1000個のデータ処理時間 2.327746秒 MySQLとMemSQL間の平均TIMESTAMP(6)の差 0.000000秒
TIMESTAMP(6)における時間差0.000000秒の衝撃・・・
Fakerでデータを作成する際に、最初に秒単位までの日時情報を文字列化して上流側のMySQLに設定しているDemoテーブルのdtカラムに書き込んでEqualumに引き渡ししており、その情報は着地地点のMySQLまで引き継がれていますので、以前の検証の様に綺麗に1秒間隔にはならずに、1000個のデータにおけるこの部分は、かなりの数で同じ秒数を占めるdt情報が連続する形になっています。ですので、今回の「リミッター無し」の状況では、Equalumのコアにおけるkafka連携の性能がそのまま出る形になっていると考えられ(途中の計算処理等を外している関係上、Sparkエンジンを深く叩くことは無いと思われますので・・・)、まさに1000個の連続処理を超高速で行う仕組みを、誰でもプログラム不要で構成出来るポテンシャルが有る・・という事を明確に示していると言えるでしょう。
約2秒で1000個のデータ処理をプログラム不要で実現するという事・・・・
また、今回は自動車の世界でいうところの・・・0-400mやドラッグレース的な感じの検証にはなるかと思いますが、速さの余裕は何度も申し上げている通りに、諦めていた仕様の実現可能性を一気に引き上げると同時に、新たなデータ・コンピューティングのアイディアを創出出来るという事です。そしてこの事は、データセントリックという考え方で、データドリブンの為のデータコンピューティング・・・そしてその可能性を飛躍的に高めるポテンシャルをEqualumは持っているという事を、明確かつ如実に示してくれたのかもしれません。
今回のまとめ
今回は、暴走編としてEqualumに0-400m的なベンチマーク検証を行ってみました。結果としては、複雑な処理FLOWをデザインして間に入れても良し、単純にレプリケーション的に利用する事(例えば現業に影響を及ぼさずに、レプリカ側にAIとかBIとか各種のデータ・ソリューションを連携させ、同じ時間帯でより高度なデータ連携作業を可能にする(現場の仕事を、今のデータでバックエンド側から能動的にサポートする事が可能になります)という、データドリブンの時間軸を極めて今に近い今!で実施することが出来るようになる事を明確に示しています。
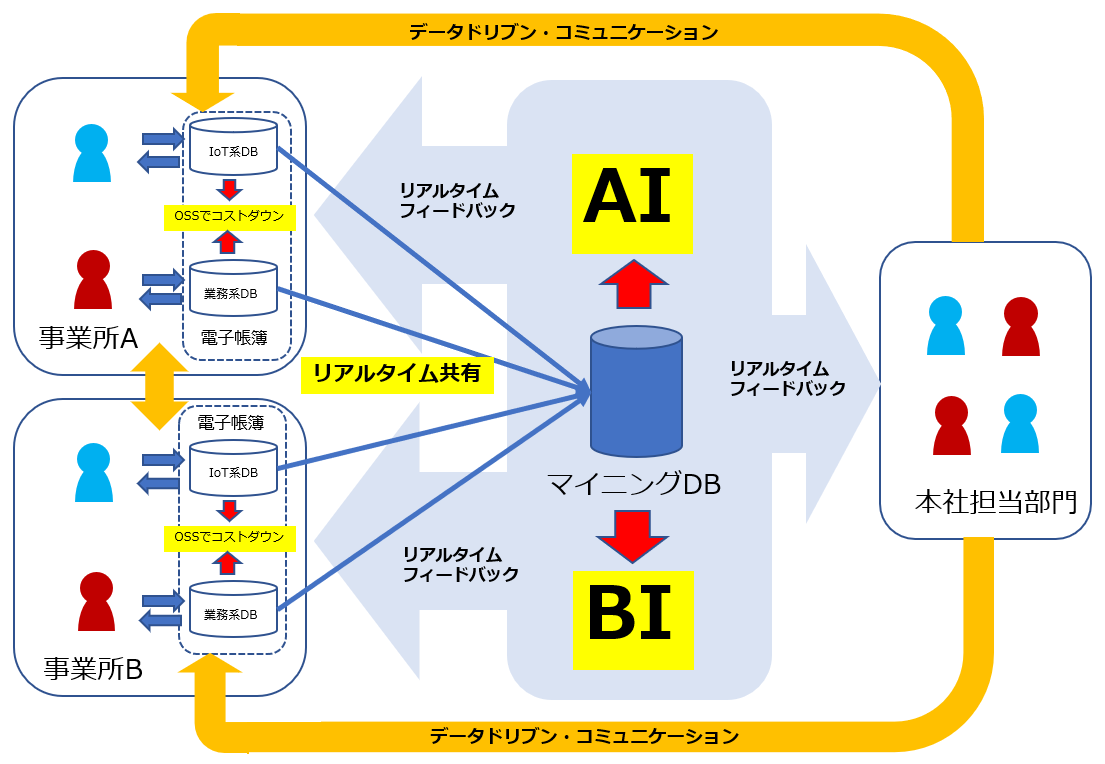
現場で稼働している既存業務系のデータベース絡みの仕組みは、設計段階からキチンとサイジングされている状況が普通だと思いますので、昨今脚光を浴びている「後付けのトランザクション製造機」的なデータ・コンピューティング系のソリューションを連携させる事・・・かなり現場側への負担が増加する方向になってしまい、結局現場の業務の後とか合間に・・・という利用になっているのではないでしょうか?
現場が忙しい時に、そのデータを即時活用してサポートや展開する作業も忙しくなる・・・
まさに、データドリブンでDx時代における「ジレンマの一つ」かもしれません。
また、従来からのバッチ処理に関しても、データの流れを上手くデザインする事により、今までのような「かなり昔に遡っての作業」ではなく、処理の間隔を短時間化させる事が出来るようになると思いますので、良い意味での「小計」確認とそれに対する適切な施策等が可能になるでしょう。
ちなみに、今回のベンチマーク的な時間計測に関するEqualum側の設定でも・・・当然一切のプログラミング作業は発生しなかった事を最後に報告させて頂きます。
誰でもkafka/Spark使いに「プログラミング無しでなれる」・・・
データは結果の一つではあるが、その結果のすぐ後には新しいデータが発生している
データに関わる時間軸への柔軟性を積極的に活用する事で、より戦略的なドリブンを可能に出来る
xxオンラインシステム・・的な年ベースのBigプロジェクトではなく、データサイエンティストの方や、プログラミングは・・・でも社内の業務関連DBのテーブルとカラム位の意味は分かる(どのテーブルに何のカラムが有るかでOKです)。。。という方であれば、最前線のkafkaベースの出高度なリアルタイム・データ・システムが作れる時代になったという事が、一連のEqualum検証で見えてきた事実かもしれません。
次回こそは番外編としてEqualumにもれなく付いてくるバッチ系の簡単な検証を追加して前半戦を終了させて頂こうかと思います。
・・・新しいネタが有れば、暴走編2になるかもしれませんが・・・・
謝辞
本検証は、Equalum社の特別の許可を得て実施しています。この貴重な機会を設定して頂いたEqualum社に対して感謝の意を表すると共に、本内容とEqualum社の公式ホームページで公開されている内容等が異なる場合は、Equalum社の情報が優先する事をご了解ください。