さて、今回は何をするか・・・
前回の暴走編では、1000個のデータを一気に上流側のMySQLに挿入して、その変化を一気に下流側のMemSQLに反映させる検証を行いました。データの形式的には、間に何もオペレータを設定しない状況でしたので、流れ的には通常のレプリケーション作業になってしまうのですが、今回は暴走のさらに上を行く、「爆走編」と称して、少し複雑なオペレータを配置して、FLOW処理にも少し負荷を掛けた状態での検証を行ってみました。
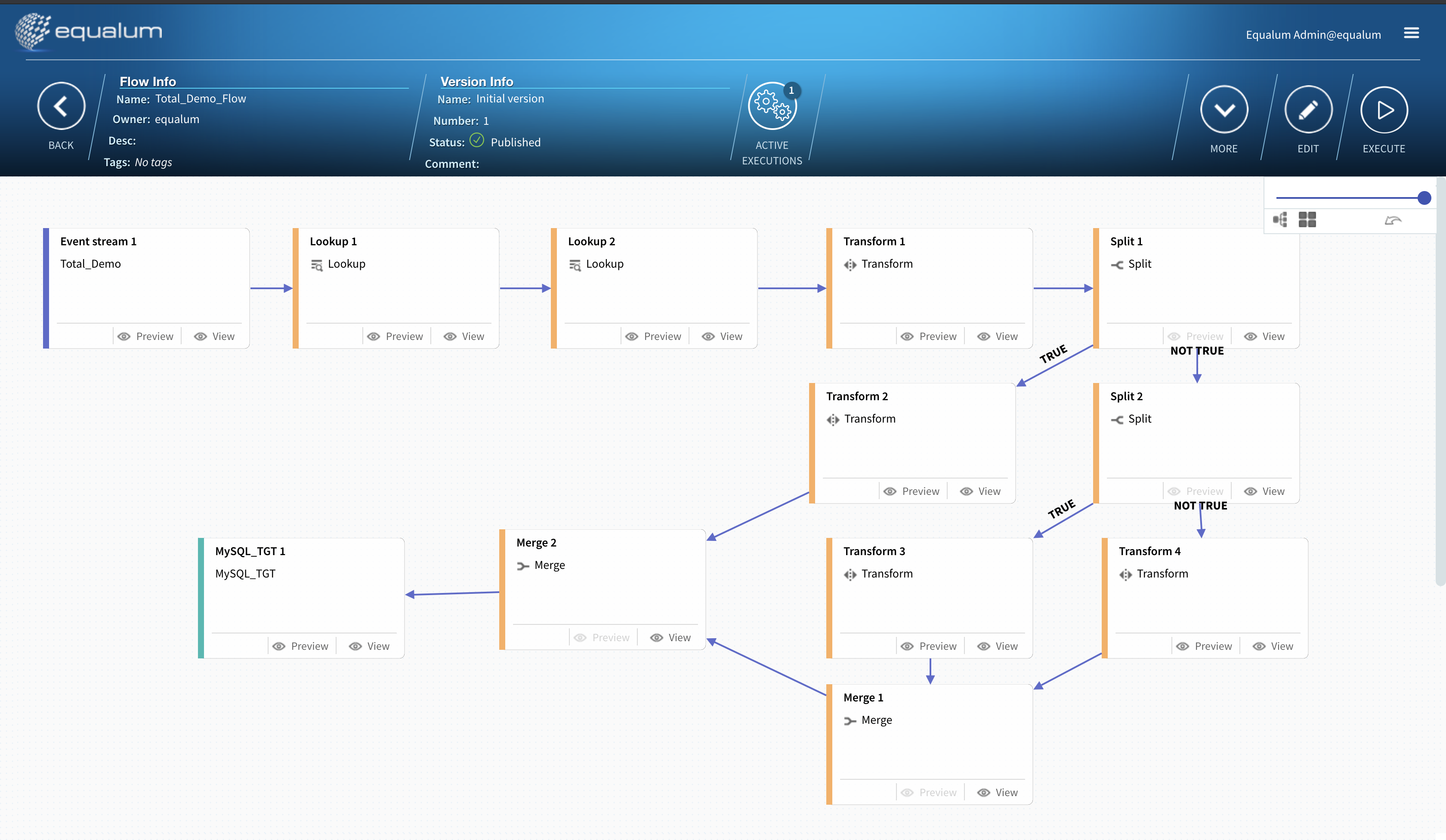
FLOWの構成
今回設定したFLOWは以下の通りです。
(1)ルックアップ処理を2段(IDコードから製品名と価格、支店名を引っ張ってきて置き換える)
(2)トランスフォーム1(販売個数と価格から総計、消費税を計算し新しいカラムとして途中追加する)
(3)条件分岐(製品名で後段のポイント計算の式を割り振る)
(4)トランスフォーム2(商品に対応するポイント計算を行い、新規のカラムとして途中追加する)
(5)マージ処理
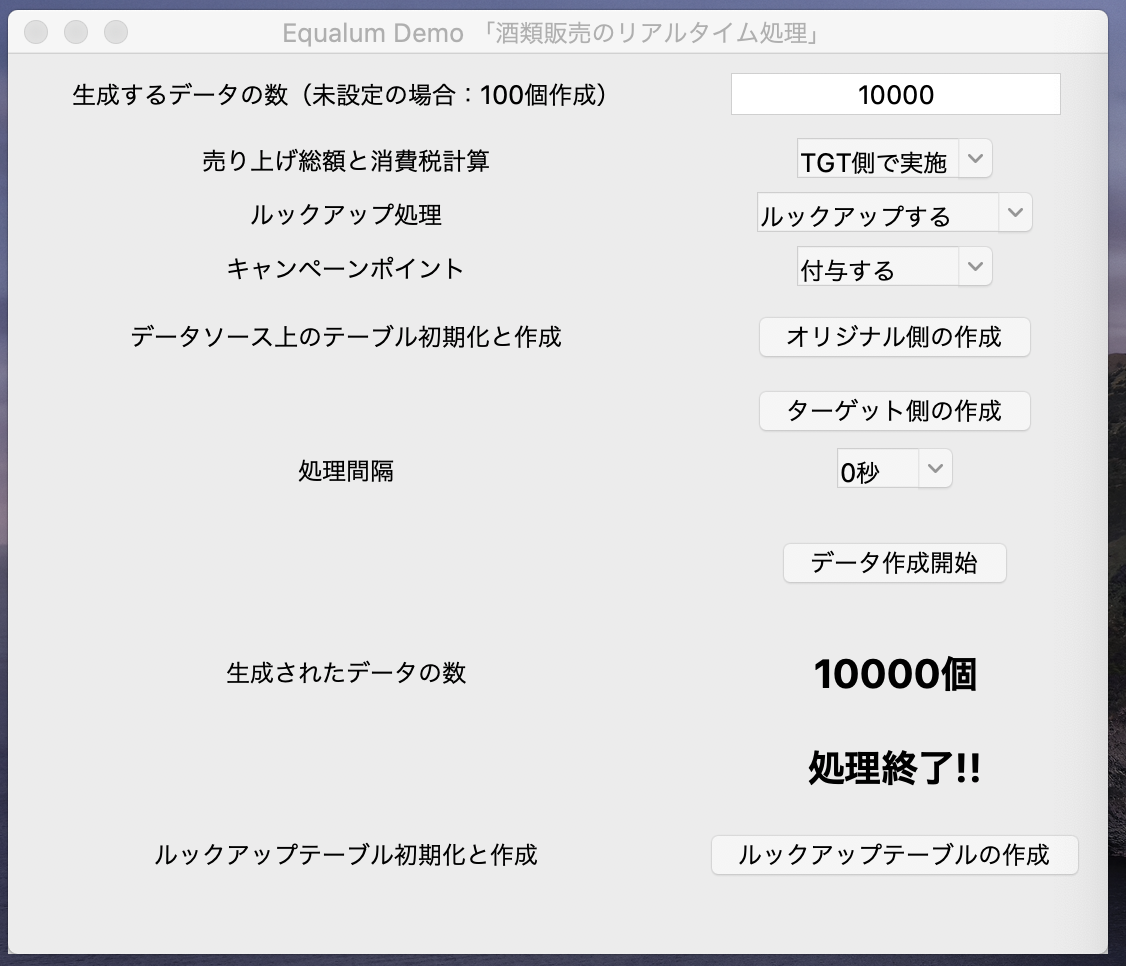
今回作成したGUI付きPythonの検証ツールで連続10000個(一万個)のデータ生成をリミッター無しで実施します。
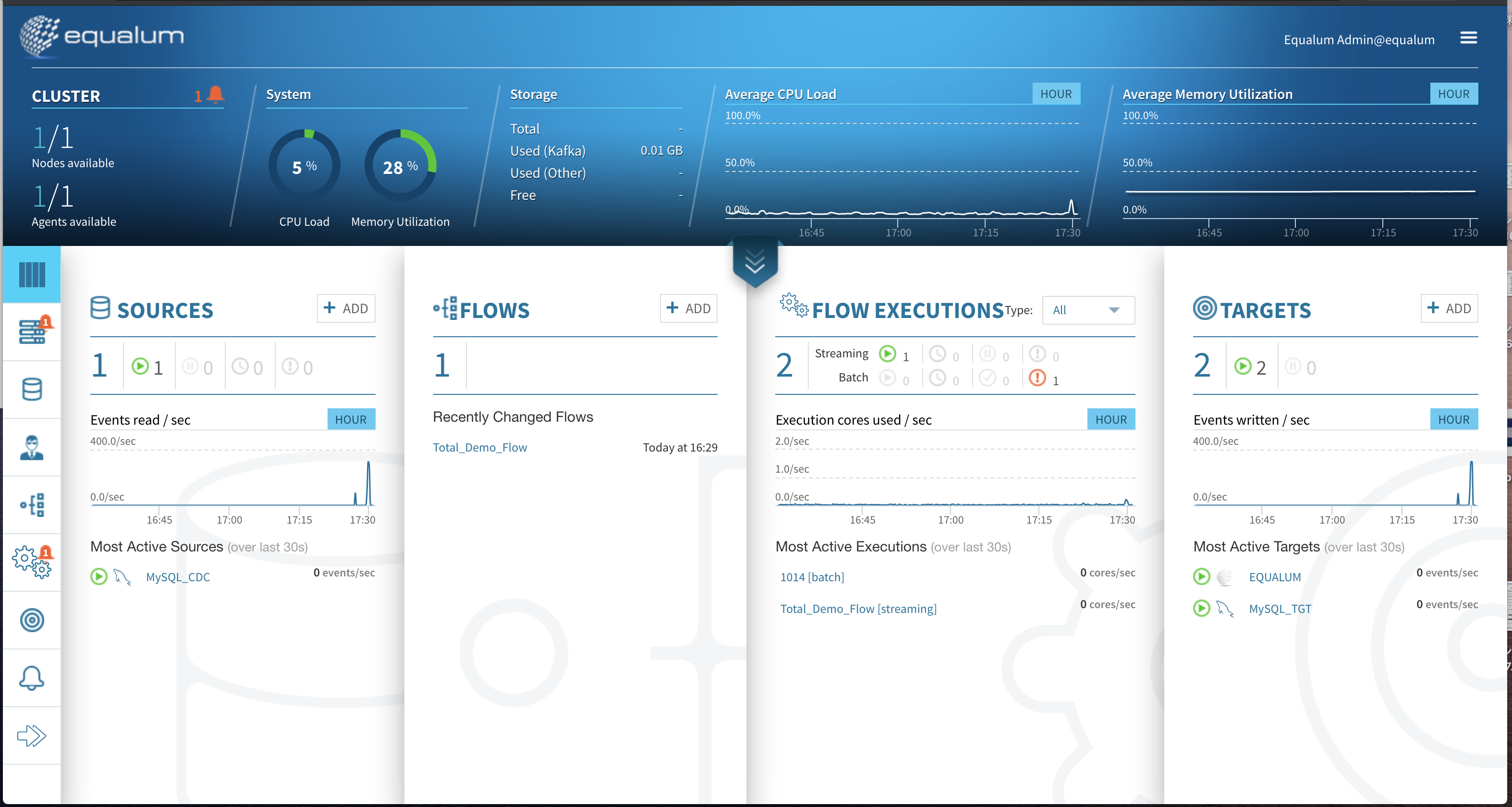
Equalumでの処理状況はこんな感じでした(先にテストで小規模なケースを行っています)
因みに今回の環境は・・・
今回は、MBP上に仮想環境(Equalumを稼働)とDocker(MySQLを2個稼働)を使って、同じ環境上からPythonを走らせて検証を実施しています。前回の場合は試用環境とはいえリッチな環境でもありましたので、今回はポータブル環境で何処まで行けるか・・・にも興味が有り企画してみました。
でっ、検証結果は??
本人的には、前回の検証とは違って「かなり負荷を掛けたつもり・・」だったのですが、想定外にサクッと終わってしまい約32秒で終了しました。前回の1000件が約2.3秒少々でしたので、まあコンピュータの性能差を考えて想定の範囲内。。。という事ですね。
取り敢えずは、スケール出来そうな感触なので推奨構成での運用に期待が持てると思います。
上流側のMySQL
1|2020-07-07 17:29:22.830892|2020-07-07 17:29:22.0| 8| 8| 4|Discover
2|2020-07-07 17:29:22.834864|2020-07-07 17:29:22.0| 8| 6| 9|Cash
3|2020-07-07 17:29:22.837617|2020-07-07 17:29:22.0| 6| 1| 5|Cash
4|2020-07-07 17:29:22.840575|2020-07-07 17:29:22.0| 2| 6| 4|American Express
5|2020-07-07 17:29:22.843461|2020-07-07 17:29:22.0| 8| 9| 1|Cash
6| 2020-07-07 17:29:22.84688|2020-07-07 17:29:22.0| 5| 3| 5|Mastercard
7|2020-07-07 17:29:22.850733|2020-07-07 17:29:22.0| 7| 5| 3|VISA 16 digit
8|2020-07-07 17:29:22.854262|2020-07-07 17:29:22.0| 8| 6| 7|Cash
9|2020-07-07 17:29:22.857108|2020-07-07 17:29:22.0| 3| 5| 8|Diners Club / Ca
10|2020-07-07 17:29:22.860963|2020-07-07 17:29:22.0| 7| 5| 7|JCB 16 digit
9990|2020-07-07 17:29:54.794126|2020-07-07 17:29:54.0| 3| 1| 7|JCB 16 digit
9991|2020-07-07 17:29:54.797143|2020-07-07 17:29:54.0| 7| 7| 1|Cash
9992|2020-07-07 17:29:54.800135|2020-07-07 17:29:54.0| 2| 1| 0|VISA 16 digit
9993| 2020-07-07 17:29:54.80318|2020-07-07 17:29:54.0| 5| 2| 9|Maestro
9994|2020-07-07 17:29:54.806082|2020-07-07 17:29:54.0| 6| 6| 9|Cash
9995| 2020-07-07 17:29:54.80908|2020-07-07 17:29:54.0| 6| 2| 3|JCB 15 digit
9996|2020-07-07 17:29:54.811969|2020-07-07 17:29:54.0| 1| 8| 9|Cash
9997|2020-07-07 17:29:54.815026|2020-07-07 17:29:54.0| 1| 4| 0|VISA 16 digit
9998|2020-07-07 17:29:54.818157|2020-07-07 17:29:54.0| 4| 3| 8|Cash
9999|2020-07-07 17:29:54.821021|2020-07-07 17:29:54.0| 1| 4| 7|JCB 15 digit
10000|2020-07-07 17:29:54.823901|2020-07-07 17:29:54.0| 4| 4| 8|Discover
下流側のMySQL
1|2020-07-07 17:29:22.830892|2020-07-07 17:29:22.0|泡盛 | 1980| 8|西新町 |Discover
2|2020-07-07 17:29:22.834864|2020-07-07 17:29:22.0|泡盛 | 1980| 6|古橋 |Cash
3|2020-07-07 17:29:22.837617|2020-07-07 17:29:22.0|スコッチ | 3500| 1|一丁目 |Cash
4|2020-07-07 17:29:22.840575|2020-07-07 17:29:22.0|ビール | 490| 6|西新町 |American
5|2020-07-07 17:29:22.843461|2020-07-07 17:29:22.0|泡盛 | 1980| 9|三丁目 |Cash
6| 2020-07-07 17:29:22.84688|2020-07-07 17:29:22.0|白ワイン | 2500| 3|一丁目 |Masterc
7|2020-07-07 17:29:22.850733|2020-07-07 17:29:22.0|ブランデー | 5000| 5|二丁目 |VISA 1
8|2020-07-07 17:29:22.854262|2020-07-07 17:29:22.0|泡盛 | 1980| 6|佐島 |Cash
9|2020-07-07 17:29:22.857108|2020-07-07 17:29:22.0|芋焼酎 | 2000| 5|五本木 |Diners C
10|2020-07-07 17:29:22.860963|2020-07-07 17:29:22.0|ブランデー | 5000| 5|佐島 |JCB 16
9990|2020-07-07 17:29:54.794126|2020-07-07 17:29:54.0|芋焼酎 | 2000| 1|佐島 |JCB 16 digit
9991|2020-07-07 17:29:54.797143|2020-07-07 17:29:54.0|ブランデー | 5000| 7|三丁目 |Cash
9992|2020-07-07 17:29:54.800135|2020-07-07 17:29:54.0|ビール | 490| 1|旭町 |VISA 16 digit
9993| 2020-07-07 17:29:54.80318|2020-07-07 17:29:54.0|白ワイン | 2500| 2|古橋 |Maestro
9994|2020-07-07 17:29:54.806082|2020-07-07 17:29:54.0|スコッチ | 3500| 6|古橋 |Cash
9995| 2020-07-07 17:29:54.80908|2020-07-07 17:29:54.0|スコッチ | 3500| 2|二丁目 |JCB 15 digit
9997|2020-07-07 17:29:54.815026|2020-07-07 17:29:54.0|バーボン | 2500| 4|旭町 |VISA 16 digit
9998|2020-07-07 17:29:54.818157|2020-07-07 17:29:54.0|赤ワイン | 3000| 3|五本木 |Cash
9999|2020-07-07 17:29:54.821021|2020-07-07 17:29:54.0|バーボン | 2500| 4|佐島 |JCB 15 digit
10000|2020-07-07 17:29:54.823901|2020-07-07 17:29:54.0|赤ワイン | 3000| 4|五本木 |Discover
今回のまとめ
今回は、短編検証として10000個の連続挿入に対してEqualumがどの様に動くか・・・を見てみました。
検証環境も性能範囲を縮小気味にして実施し、間に多段の処理ステップを設定しましたが、依然としてTIMESTAMP(6)では差が出てこない状況・・・(汗)、次回以降では少しこの辺を検討してみたいと思います。
Equalumの神髄は、
ストリーミングしながらデータ処理を行い、
着地した瞬間から次の作業が開始できる・・
という点にあります。
レプリケーションを実施する目的も幾つか存在しているかとは思いますが、複製してから処理をするのではなく、しながら処理を行うという点で新しいデータ・コンピューティングの可能性を与えてくれるのではないでしょうか?
kafkaに加えてSpark連携を最大限に活用できる・・・・この点もEqualumのアドバンテージになると確信できた検証でした。
何とか詐欺状態になりましたが、次回こそは番外編としてEqualumにもれなく付いてくるバッチ系の簡単な検証を追加して前半戦を終了させて頂こうかと思います。
謝辞
本検証は、Equalum社の特別の許可を得て実施しています。この貴重な機会を設定して頂いたEqualum社に対して感謝の意を表すると共に、本内容とEqualum社の公式ホームページで公開されている内容等が異なる場合は、Equalum社の情報が優先する事をご了解ください。