新年の初夢。。そうだ、不死身のDBを作ってみよう・・・・・
Equalumのターゲット(同期先)側の設定が選べる・・・・
今回の検証は、Equalumのノーコード即時同期FLOWを作る際に、ターゲット側の属性設定で「Append:追記」タイプを選択した場合に、データの同期がどの様に行われるか?を確認したいと思います。
取り敢えず、どんな感じで動くのか・・・
検証ツール自体は、標準的なPython環境で作成されていますので(後ほど参考情報として添付しておきます)、もしも「これ、面白い!」という事で、より高度な仕組みをJava等で作り込まれる場合も、特に大きな壁もなく作業して頂けるかと思いますし、学習系AI処理を絡めた「データのライブ監査処理」的なアイディアも面白いかもしれません。
既に妄想だけはどんどん大きくなっているのですが、今回はシンプルに「オリジナル側で発生しているインサート処理、アップデート処理等の通常DB活動結果を、EqualumのCDC即時同期のプロセス内で強制的に追記処理に変更して処理を続行する」の基本動作に絞って検証を進めていく事にします。
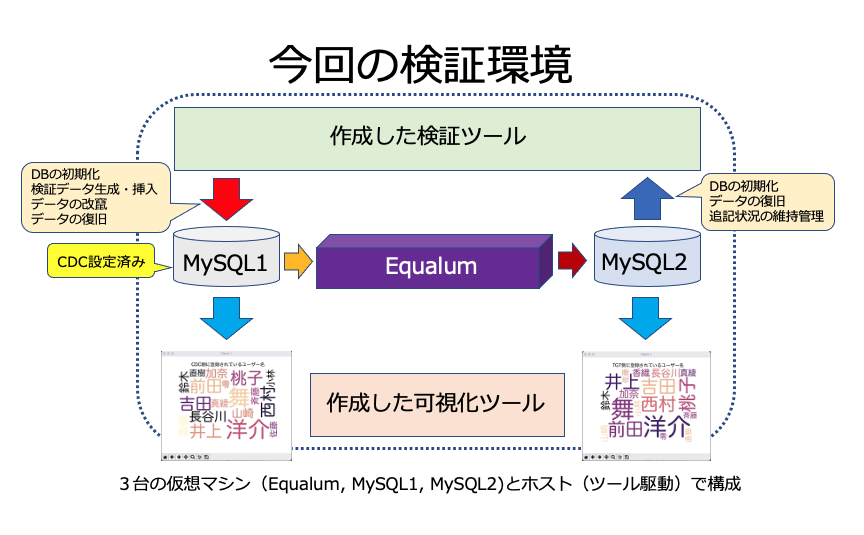
今回の検証環境を実行した際の動画から・・・
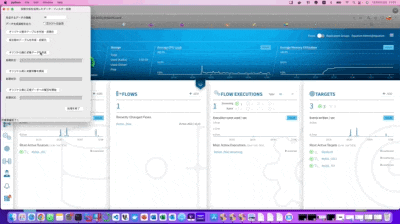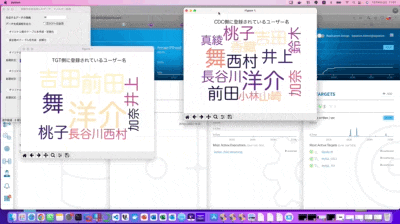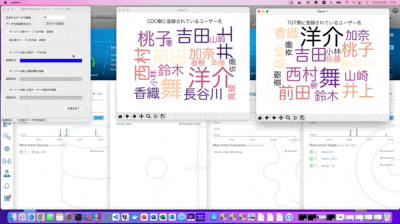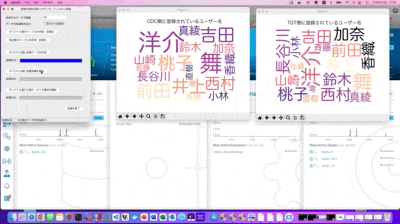
CDCと表記されているワードクラウドが、検証用のデータを最初にSQLで連続インサート処理している側のDBテーブル状況を可視化しています。また同様にTGTと表記されているワードクラウドがEqualumの即時同期によりAppend処理を行っている側のDBテーブルの状況になります。
自動挿入されているデータ・カラムは複数ありますが、可視化対象はFakerが生成した「なんちゃって住所録の名前カラム」としています。
即時同期の状況は、見て頂いた通りに力任せで一気書きしたPythonで構成された状況下でも、非常に高速に2つの異なるDB上でテーブルが即時同期していることが確認出来るかと思います。
次に、オリジナルのDB側テーブルに対してSQLのアップデート処理を使って、検証用のデータ改竄処理を行なってみます。
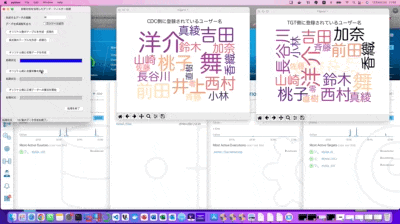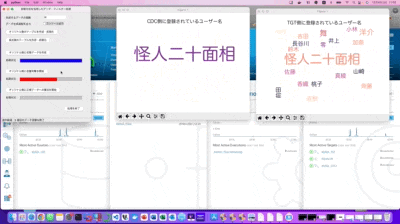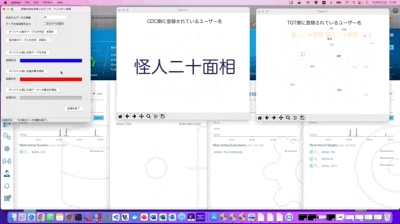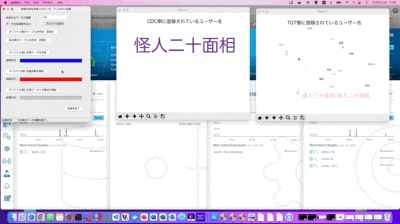
CDC側のワードクラウドが突然「怪人二十面相」の表記だけに変わりましたが、これは事前にSQLのインサート処理で作成したテーブル内の全てのデータをSQLのアップデート処理で書き換えた事により、それまで存在していたオリジナルデータが全て改竄された状況となり、そのプロセスを可視化している形になります。
ここで重要な点は、
Append設定されたTGT側のデータが想定通りに正常に残っているのか?
になります
自作のワードクラウド可視化ツールを見た限りでは、TGT側の表示に微かに初期の記録データが見えるので、データ的にはちゃんと正常に生き残っている様ですが、後で念の為にDBeaverで実際のテーブル状況を確認したいと思います。
次に、このターゲット側のデータを活用して、オリジナル側のデータを修復してみます。
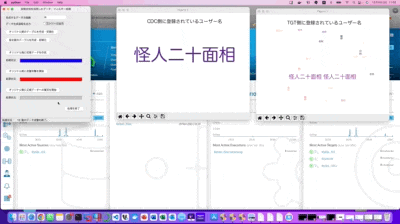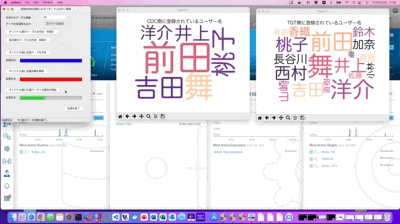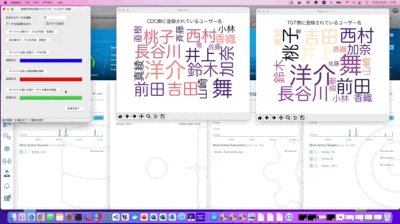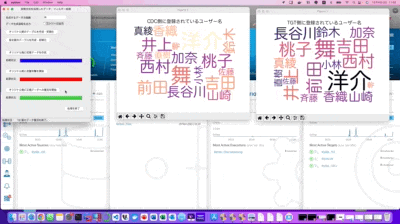
処理的には、検証環境の制限も有りますので、ロジック的にはシンプルな形で検証実験していますが、作業を開始すると即時にデータが復旧している事が分かるかと思います。
即時同期型のデータ処理は、明確な役割分担の下で適材適所・常時全量の処理が実行できる
実際にこの類の処理を想定した場合は、より高度なロジックを組んで(双方のテーブル設計などを含めて)、機械学習&AI処理等との連携等も考慮する必要がありますが、Equalumが持つExactly Onceの処理品質と、ターゲット側のテーブル属性を強制的にAppendモードで実行させる事による「セキュリティー系の監査ログ的な扱い」が、その応用次第で非常に面白い機能として有効活用出来る可能性が有る事が確認出来ました。
検証に使った道具達の紹介・・・
まずは、動作検証に使用するツールをサクッ!と作ってしまいます。
以前に使用したFakerを使った検証データ生成ツールを再利用して、必要な部分を切り出しながら修正して構成していきます。
出来た検証ツールがこちらです・・
検証データ生成ツール
書き方に関しては、個性の塊になっていますので、今回も恒例のNDA(ノン・ダメ出し・アグリーメント)ベースという事でお願い致します(苦笑)
##################################################
#
# Exactly Once & Allの動作検証
#
##################################################
import tkinter as tk
from tkinter import ttk
import re
import time
import datetime
import pymysql.cursors
import hashlib
import random
#
# グローバル変数の定義
ON = 1
OFF = 0
#
MySQL_CDC = 0
MySQL_TGT = 1
#
# 初期データの生成時間のリアル化
Real_Interval = OFF
#
# DB側のSQL処理待ち時間
Wait_Time = 3
#
# プログレッシブバーの更新で使用
Delay = 500
#
# 更新ステータスのカウント単位
Data_Count = 5
#
# 検証に使用するDBの接続パラメータ(今回はMySQLを使用)
CDC_Host = "ZZZ.ZZZ.ZZZ.ZZZ"
CDC_Port = 3306
CDC_User = "ZZZZZ"
CDC_Pass = "ZZZZZ"
CDC_DB = "ZZZZZ"
CDC_Char = "utf8mb4"
#
TGT_Host = "YYY.YYY.YYY.YYY"
TGT_Port = 3306
TGT_User = "YYYYY"
TGT_Pass = "YYYYY"
TGT_DB = "YYYYY"
TGT_Char = "utf8mb4"
#
# 検証に使うテーブル名
CDC_Table_Name = "Demo_CDC_Table"
TGT_Table_Name = "Demo_TGT_Table"
TGT_Tmp_Name = "TGT_tmp"
#
ID_Name = "Demo"
#
# 地域名ルックアップ情報(キーは都道府県名)
Area_Data = {'北海道':'北海道','青森県':'東北','岩手県':'東北','宮城県':'東北','秋田県':'東北','山形県':'東北','福島県':'東北',
'茨城県':'関東','栃木県':'関東','群馬県':'関東','埼玉県':'関東','千葉県':'関東','東京都':'関東','神奈川県':'関東',
'新潟県':'中部','富山県':'中部','石川県':'中部','福井県':'中部','山梨県':'中部','長野県':'中部','岐阜県':'中部','静岡県':'中部','愛知県':'中部',
'三重県':'近畿','滋賀県':'近畿','京都府':'近畿','大阪府':'近畿','兵庫県':'近畿','奈良県':'近畿','和歌山県':'近畿',
'鳥取県':'中国','島根県':'中国','岡山県':'中国','広島県':'中国','山口県':'中国',
'徳島県':'四国','香川県':'四国','愛媛県':'四国','高知県':'四国',
'福岡県':'九州・沖縄','佐賀県':'九州・沖縄','長崎県':'九州・沖縄','熊本県':'九州・沖縄','大分県':'九州・沖縄','宮崎県':'九州・沖縄','鹿児島県':'九州・沖縄','沖縄県':'九州・沖縄'}
取り急ぎ必要な設定などを定義します。
今回は、住所録的な情報テーブルをFakerでランダムに作成して検証を実施することにしました。
#
# 改竄に用いるデータ(処理負担軽減のため現状は固定:単純な置き換えアップデートで実行)
Attck_Data = {'User':'怪人二十面相',
'Zip':'000-0000',
'Address':'地球上の何処かだった記憶が・・・(^^;)',
'Tel':'999999999',
'Email':'!!!!!!!!@??????',
'Prefecture':'内緒!',
'Area':'忘れた',
'ID':'XXXXXXXX'}
Exactly Once & Allの動きを検証するために、データを別の内容に自動改竄するようにします。環境条件が良ければこの辺の設定を「よりリアルに近づける」事も出来るのですが、利用する検証環境の構成がMBP上に展開する仮想マシン数台になりますので、処理の過程で負荷があまり高くならない様に、非常にシンプルな「同一パターンでの書き換え」とすることにしました。
勿論、想定通りに動作するのであれば、即時同期されるターゲット側のMySQL上に展開されるデータに対して、より高度で効果的なロジックや機械学習&AI等の仕組みを導入し、一種の監査・検閲プロセス的に処理を行う構成も可能でしょう。(興味がある方は是非!)
#
# 検証に使うテーブルの設定
#
MY_CDC_DC0 = "id INT AUTO_INCREMENT, ts DATETIME(6) DEFAULT CURRENT_TIMESTAMP(6), PRIMARY KEY(id), " # CDC側にはDBのタイムスタンプとIDの自動付与とキーを設定
#
MY_Table_DC1 = "User VARCHAR(20), Zip VARCHAR(10), Prefecture VARCHAR(10), Address VARCHAR(60), Tel VARCHAR(15), Email VARCHAR(40), Area VARCHAR(10), "
MY_Table_DC2 = "HS VARCHAR(64), OP_id VARCHAR(10), OP_ts DATETIME(6)"
#
MY_Table_DL1 = "User, Zip, Prefecture, Address, Tel, Email, Area, "
MY_Table_DL2 = "HS, OP_id, OP_ts"
オリジナル側とターゲット側に作成するテーブルも、今回は必要最小限で行く事にしました。この辺もしっかりと想定して構成すれば、かなり戦闘力の高い処理が可能になるかと思います。
Equalum社の製品担当者に教えて貰ったポイントとしては、今回の処理設定の場合は「オリジナル側に発生する全てのインサート、アップデート等をターゲット側に強制的にインサート処理する・・」との事なので、ターゲット側でのプライマリーキーを含めたキー設定は行わない方向でテーブルを準備しています。
ただひたすらに、正しく、間違いなく、1回の処理を全て追記型でテーブル記録する・・・・か否かを確認できれば成功とします。
#
# Exactly Once & Allを活用したデータ復旧処理の検証
#
print("------------------------------------------------")
print("******************* 処理開始 *******************")
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "検証ツールを起動")
print("------------------------------------------------")
#
# Fakerの初期化
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "Fakerの初期化開始")
#
from faker import Faker
# 日本語データ
fakegen_jp = Faker('ja_JP')
Faker.seed(fakegen_jp.random_digit())
#
# GUI部分の初期化
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "GUIの初期化開始")
root = tk.Tk()
root.title("Exactly Once & Allを活用したデータ処理検証")
root.geometry("430x530")
#
# GUIスタイルの設定(この設定の場合、プログレスバーが太く表示される)
style = ttk.Style()
style.theme_use('default')
#
# プログレッシブバーの色を設定
# 初期データの作成状況
style.configure("Blue.Horizontal.TProgressbar", foreground='blue', background='blue')
#
# 改竄攻撃の進行状況
style.configure("Red.Horizontal.TProgressbar", foreground='red', background='red')
#
# 正規データへの復活状況
style.configure("Green.Horizontal.TProgressbar", foreground='limegreen', background='limegreen')
#
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "検証ツールの初期化完了")
この辺は、ほぼ毎度お馴染みの定番的な書き方になるかと思います。
#
# 内部利用関数定義
#
# 1行分のデータを文字列にしてSHA256でハッシュ値を計算して結果を返す
#
def Get_SHA256(Str_Data):
# 格納変数の初期化
sha256 = ''
# SHA256のハッシュ値
sha256 = hashlib.sha256(Str_Data.encode()).hexdigest()
# 算出結果を返す
return(sha256)
当初予定では、オリジナルデータ群を文字列化して「そのハッシュ値を識別用の情報として使う」という予定でしたので、簡単なハッシュ値を生成する関数を作成しました(今後の展開時に使えるように忘備録として残してあります)
#
# 初期値を作成する際に生成時刻をリアルにするための遅延間隔設定
#
def Jitter():
f = random.random()
r = random.randint(1,2)
return round(f+r, 3)
#
# 指定されたSQLを使ってデータ格納状況を確認して個数を戻す
#
def Check_ID_Number(db, Check_SQL):
# 作業リストの初期化
Tmp_Data = []
# idの数をクエリで抽出してTGT側のプログレスバーを処理する
with db.cursor() as cursor:
cursor.execute(Check_SQL)
db.commit()
for Query_Data in cursor.fetchall():
for item in Query_Data.values(): Tmp_Data.append(item)
# リストの1番最初にデータ数の情報が有るのでそれを戻す
return(Tmp_Data[0])
#
# TGT側の重複レコードを定番のSQLを使って整理する
#
def Duplicate_Removal(db, cursor):
cursor.execute("CREATE TEMPORARY TABLE " + TGT_Tmp_Name + " AS SELECT DISTINCT * FROM " + TGT_Table_Name)
cursor.execute("ALTER TABLE " + TGT_Table_Name)
cursor.execute("DELETE FROM " + TGT_Table_Name)
cursor.execute("INSERT INTO " + TGT_Table_Name + " SELECT * FROM " + TGT_Tmp_Name)
cursor.execute("DROP TEMPORARY TABLE " + TGT_Tmp_Name)
db.commit()
#
# アプリの終了とウインドウの消去
#
def Exit_Tool(): root.destroy()
#
#プログレスバーの更新
#
def var_start1(value_bar): progressbar1.configure(value=value_bar)
def var_start2(value_bar): progressbar2.configure(value=value_bar)
def var_start3(value_bar): progressbar3.configure(value=value_bar)
Exactly Once & Allが成立した場合、ターゲット側のテーブルに重複処理が発生しますので(オリジナル側で発生する全ての処理を確実に間違いなく1回全て実行して、その結果をシーケンシャルに全て追記していきます)、その無駄な部分を削除するSQLを最後に後処理として呼び出す用にしました。
この辺は、実際のケースに合わせて処理の内容を設定する所になりますが、今回は動作資源の関係で「一番シンプルで安直な方法」にしています。
#
# 改竄データのハッシュ値を算出(処理環境の都合で今回は固定値)
#
def Get_Attack_HS():
# 処理ログの書き込み
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "改竄データのハッシュ値計算開始")
# 改竄データのハッシュ対象データを作成
HS1 = Attck_Data.get("User") + Attck_Data.get("Zip") + Attck_Data.get("Prefecture")
HS2 = Attck_Data.get("Address") + Attck_Data.get("Tel") + Attck_Data.get("Email") + Attck_Data.get("Area")
# データを1行の文字列にしてハッシュ値を算出する
HS = str(Get_SHA256(HS1 + HS2))
# 処理ログの書き込み
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "改竄データのハッシュ値計算完了")
return(HS)
最初は、検証環境規模を考えずに、すべてのデータに関する異なるハッシュ値を別プロセスで維持監視し、そのデータを外部参照する形でデータの妥当性判断の一助とする・・・的な「非常に壮大なイメージ」が有り、ではハッシュ値を生成する機能を・・・という事で前述の機能切り出し等を行なったのですが、最終的には「今回は追記処理の基本動作検証」なので、この辺のリアルなメカニズムを組み込んだ作業は、また別途環境整備から計画して・・・という事にしました。
ですので、改竄のパターンも1個の固定型で今回は実施しています。
この辺の実装は、本当の意味で対改竄性の高い、不死身のDBを作る場合の基礎データ・デザインになる部分だと思いますので、興味がある方は独自の作成を練られると面白いかと思います(個人的には各種の学習系技術&AIに常時監視させてるのも面白いのでは?と妄想しています。勿論、同期先で発生するこの手の後出しトランザクションが、そのままドカン!とオリジナル側に被さる事は無い仕組みですし、以前に検証紹介しているSingleStore(旧MemSQL)のインメモリ超高速性能をフルに活用することで、最終的にAI監査済みの基準DBへ結果を書き出す形にしても(今回の検証範囲を、ある種のProxy的に利活用する)、意外に「ふーん、そんな高度な処理を裏で実行してるんだ・・・」的な感じに収まるのでは?・・と考えています。(MySQL→(CDC即時同期)→SingleStore→(データ駆動型DX)→MySQL的な流れでデータ利活用)
#
# データベースとの接続
#
def Open_DB(DB_Type):
if DB_Type == MySQL_CDC: DB_Name = "CDC側のMySQL"
else: DB_Name = "TGT側のMySQL"
# 処理ログの書き込み
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + DB_Name + "データベースの接続開始")
# ターゲットのデータベースに接続してポインタを取得
if DB_Type == MySQL_CDC:
db = pymysql.connect(host = CDC_Host, port = CDC_Port, user = CDC_User, password = CDC_Pass, db = CDC_DB, charset = CDC_Char, cursorclass = pymysql.cursors.DictCursor)
elif DB_Type == MySQL_TGT:
db = pymysql.connect(host = TGT_Host, port = TGT_Port, user = TGT_User, password = TGT_Pass, db = TGT_DB, charset = TGT_Char, cursorclass = pymysql.cursors.DictCursor)
# 処理ログの書き込み
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + DB_Name + "データベースの接続完了")
# データベース処理に必要なポインタを戻す
return(db)
#
# 指定されたDBにテーブルを作成
#
def Table_Setup(DB_Type):
# 処理ログの書き込み
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "指定されたDBのテーブル初期化開始")
# テーブル生成SQLの生成
if DB_Type == MySQL_CDC:
Init_SQL = "DROP TABLE IF EXISTS " + CDC_Table_Name
Create_SQL = "CREATE TABLE IF NOT EXISTS " + CDC_Table_Name + " (" + MY_CDC_DC0 + MY_Table_DC1 + MY_Table_DC2 + ")"
elif DB_Type == MySQL_TGT:
Init_SQL = "DROP TABLE IF EXISTS " + TGT_Table_Name
Create_SQL = "CREATE TABLE IF NOT EXISTS " + TGT_Table_Name + " (" + MY_Table_DC1 + MY_Table_DC2 + ")"
# データベースとの接続
db = Open_DB(DB_Type)
# 指定されたDB上に所定のテーブルを作成
with db.cursor() as cursor:
# 既存テーブルの初期化
cursor.execute(Init_SQL)
db.commit()
# 新規にテーブルを作成
cursor.execute(Create_SQL)
db.commit()
# データベースを切断
db.close()
# 処理ログの書き込み
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "指定されたDBのテーブル初期化完了")
#
# CDC側の初期テーブルを作成
#
def Make_CDC_Table():
# 処理ログの書き込み
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "CDC側のテーブル作成開始")
Table_Setup(MySQL_CDC)
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "CDC側のテーブル作成完了")
# 処理ログの書き込み
statusbar["text"] = " CDC側のテーブルを作成しました。"
#
# TGT側の初期テーブルを作成
#
def Make_TGT_Table():
# 処理ログの書き込み
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "TGT側のテーブル作成開始")
Table_Setup(MySQL_TGT)
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "TGT側のテーブル作成完了")
# 処理ログの書き込み
statusbar["text"] = " TGT側のテーブルを作成しました。"
この辺は、Python的に標準のデータベース関連処理になるかと。
今回は、途中の状況を出来るだけ細かく調べるために、各処理の開始・終了部分に時間データの出力処理を仕掛けています。
#
# 検証用のデータを生成
#
def Init_Data_Gen(Data_ID):
Display_SQL = int(checkbtn.get())
# 初期の擬似住所録情報を生成
User = fakegen_jp.name()
Zip = fakegen_jp.zipcode()
Address = fakegen_jp.address()
Tel = fakegen_jp.phone_number()
Email = fakegen_jp.ascii_email()
# 処理IDを生成
OP_id = ID_Name + str(Data_ID).zfill(4)
# 都道府県名の抽出
pattern = u"東京都|北海道|(?:京都|大阪)府|.{2,3}県"
m = re.match(pattern , Address)
if m: Prefecture = m.group()
# エリア名の設定
Area = Area_Data.get(Prefecture)
# データを1行の文字列にしてハッシュ値を算出する
HS = str(Get_SHA256(User + Zip + Prefecture + Address + Tel + str(Email) + Area))
# データの生成日時を確保
OP_ts = str(datetime.datetime.now())
# SQLデータの生成
Data = User + "','" + Zip + "','" + Prefecture + "','" + Address + "','" + Tel + "','" + str(Email) + "','" + Area + "','" + HS + "','" + OP_id + "','" + OP_ts
# デバッグモードがONの場合は算出結果をコンソールに表示する
if Display_SQL == ON: print(Data)
# SQLデータを戻す
return(Data)
ここは、Fakerの機能を使って、検証用のランダムな「それっぽいデータ」を生成し、SQL文で使うデータ列にしている部分になります。
#
# 初期データ作成のDB処理
#
def Init_Data_Insert():
# 処理ログの書き込み
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "データの生成と連続挿入を開始")
# 処理に必要な情報の取得
Loop_Count = int(Gen_Count.get("1.0", "end")) # 生成するデータの個数
Display_SQL = int(checkbtn.get()) # 処理状況をコンソール出力するか否か
# プログレッシブバーに処理する回数を設定
progressbar1.configure(maximum=Loop_Count)
# CDC側のMySQLと接続する
db = Open_DB(MySQL_CDC)
# 現在格納されているレコード数を確認
Rec_Count = Check_ID_Number(db, "SELECT COUNT(HS) FROM " + CDC_Table_Name)
# 必要回数の生成・挿入処理を行う
with db.cursor() as cursor:
# ループカウンターの初期化
Loop_Counter = 0
# データの生成
while Loop_Counter < Loop_Count:
# SQLで使用するデータ列の作成
SQL_Data = Init_Data_Gen(Rec_Count + 1)
SQL = "INSERT INTO " + CDC_Table_Name + " (" + MY_Table_DL1 + MY_Table_DL2 + ") VALUES ('" + SQL_Data + "')"
# オプションが選択されていればコンソールに生成データを表示
if Display_SQL == ON: print (SQL)
# データベースへの書き込み
cursor.execute(SQL)
db.commit()
# 次のデータ生成間隔を調整
if Real_Interval == ON: time.sleep(Jitter())
# ループカウンタの更新
Loop_Counter = Loop_Counter + 1
# データIDカウンタの更新
Rec_Count = Rec_Count + 1
# 初期データ作成プログレスバーの処理
progressbar1.after(Delay, var_start1(Loop_Counter))
progressbar1.update()
# 処理ステータスの更新表示
if (Loop_Counter % Data_Count) == 0:
statusbar["text"] = " 途中経過 : " + str(Loop_Counter) + " 個目のデータ作成を終了"
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : 途中経過 " + str(Loop_Counter) + " 個目のデータ作成を終了")
# DBを切断
db.close()
# 最終ステータスを表示
statusbar["text"] = " 処理状況: " + str(Loop_Counter) + " 個のデータ作成を終了。"
# 処理ログの書き込み
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "データの生成と連続挿入が完了")
ここは、CDC設定されたMySQL側(オリジナル側)のテーブルに、検証用に作成されたデータ列を順番に指定された数だけ挿入処理を行なっています。
#
# 改竄用データで上書き(UPDATE)を実施
#
def Attack_Data_Update():
# 処理ログの書き込み
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "ソースDB側のデータ改竄処理を開始")
# 処理に必要な情報の取得
Display_SQL = int(checkbtn.get())
# 改竄データのハッシュ値を算出
HS = Get_Attack_HS()
# 改竄用のSQLを作成
AS1 = " SET User = '" + Attck_Data.get("User") + "', Zip = '" + Attck_Data.get("Zip") + "', "
AS2 = "Prefecture = '" + Attck_Data.get("Prefecture") + "', Address = '" + Attck_Data.get("Address") + "', "
AS3 = "Tel = '" + Attck_Data.get("Tel") + "', Email = '" + Attck_Data.get("Email") + "', "
AS4 = "Area = '" + Attck_Data.get("Area") + "', HS = '" + HS + "', "
AS5 = "OP_id = '" + Attck_Data.get("ID") + "', OP_ts = CURRENT_TIMESTAMP"
Attack_SQL = "UPDATE " + CDC_Table_Name + AS1 + AS2 + AS3 + AS4 + AS5
# CDC側のMySQLと接続する
db = Open_DB(MySQL_CDC)
# CDC側のデータベースに登録されている行数を取得
Loop_Count = Check_ID_Number(db, "SELECT COUNT(HS) FROM " + CDC_Table_Name)
# プログレッシブバーに処理する回数を設定
progressbar2.configure(maximum=Loop_Count)
# 必要回数の生成・挿入処理を行う
with db.cursor() as cursor:
# ループカウンターの初期化
Loop_Counter = 0
# データの生成
while Loop_Counter < Loop_Count:
# データベースへの書き込み
cursor.execute(Attack_SQL)
db.commit()
# オプションが選択されていればコンソールに生成データを表示
if Display_SQL == ON: print (Attack_SQL)
# ループカウンタの更新
Loop_Counter = Loop_Counter + 1
# 初期データ作成プログレスバーの処理
progressbar2.after(Delay, var_start2(Loop_Counter))
progressbar2.update()
# 処理ステータスの更新
if (Loop_Counter % Data_Count) == 0:
statusbar["text"] = " 途中経過 : " + str(Loop_Counter) + " 個目のデータ改竄を終了"
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : 途中経過 " + str(Loop_Counter) + " 個目のデータ改竄処理を終了")
# DBを切断
db.close()
# 最終ステータスを表示
statusbar["text"] = " 処理状況: " + str(Loop_Counter) + " 個のデータ改竄を終了。"
# 処理ログの書き込み
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "ソースDB側のデータ改竄処理を完了")
ここで、オリジナル側に展開されているデータを全て固定データで改竄処理します。
現実的には条件がもっと厳しいかと思いますので、具体的に検討される場合は「より高度なパターンの改竄戦略」を実装された方が良いでしょう。
今回は、MBPという限定環境でしたので、メモリとCPUに優しい条件設定で検証しました(汗)
#
# TGT側のデータを使ってオリジナル状態へ復活
#
def Revival_Data_Update():
# 処理ログの書き込み
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "オリジナル側のデータ復活を開始")
# 処理に必要な情報の取得
Display_SQL = int(checkbtn.get())
# CDC側,TGT側のMySQLと接続する
db1 = Open_DB(MySQL_CDC)
db2 = Open_DB(MySQL_TGT)
# 必要回数の生成・挿入処理を行う
with db1.cursor() as cursor1, db2.cursor() as cursor2:
#
# TGT側から改竄データを削除する (この処理はたんサイクルバッチ化して機械学習&AIで自動化予定・・)
#
# 改竄対象のハッシュ値を取得
HS = Get_Attack_HS()
# 削除用のSQLを作成(この検証では単純化の為に固定のハッシュ値を使用)
SQL = "DELETE FROM " + TGT_Table_Name + " WHERE HS = '" + HS + "'"
# TGT側で処理を行い該当するデータを削除
cursor2.execute(SQL)
db2.commit()
# TGT側に残った削除対象ではないレコード数を取得(この回数分処理をループさせる)
Loop_Count = Check_ID_Number(db2, "SELECT COUNT(HS) FROM " + TGT_Table_Name)
# プログレッシブバーに処理する回数を設定
progressbar3.configure(maximum=Loop_Count)
# CDC側のテーブルを初期化
Table_Setup(MySQL_CDC)
# TGT側の対象となるIDを確認する
cursor2.execute("SELECT OP_id FROM " + TGT_Table_Name)
db2.commit()
# 修復対象のレコードID(OP_id)を取得する
Rec_ID = []
for Query_Data in cursor2.fetchall():
for item in Query_Data.values(): Rec_ID.append(item)
# ループカウンターの初期化
Loop_Counter = 0
# 順番にデータを復旧する
while Loop_Counter < Loop_Count:
# TGT側にID起点でデータを取得するSQLを作成
SQL = "SELECT * FROM " + TGT_Table_Name + " WHERE OP_id = '" + Rec_ID[Loop_Counter]+ "'"
# オプションが選択されていればコンソールに生成データを表示
if Display_SQL == ON: print (SQL)
# TGT側にSQLを投げる
cursor2.execute(SQL)
db2.commit()
# クエリ結果を取得して各カラムデータに分解する
Revival_Data = []
for Query_Data in cursor2.fetchall():
for item in Query_Data.values(): Revival_Data.append(item)
# 修復用のSQLを作成する
SQL_Data1 = Revival_Data[0] + "','" + Revival_Data[1] + "','" + Revival_Data[2] + "','" + Revival_Data[3] + "','" + Revival_Data[4] + "','"
SQL_Data2 = Revival_Data[5] + "','" + Revival_Data[6] + "','" + Revival_Data[7] + "','" + Revival_Data[8] + "','" + str(Revival_Data[9])
SQL = "INSERT INTO " + CDC_Table_Name + " (" + MY_Table_DL1 + MY_Table_DL2 + ") VALUES ('" + SQL_Data1 + SQL_Data2 + "')"
# データベースへの書き込み
cursor1.execute(SQL)
db1.commit()
# オプションが選択されていればコンソールに生成データを表示
if Display_SQL == ON: print (SQL)
# ループカウンタの更新
Loop_Counter = Loop_Counter + 1
# 初期データ作成プログレスバーの処理
progressbar3.after(Delay, var_start3(Loop_Counter))
progressbar3.update()
# 処理ステータスの更新
if (Loop_Counter % Data_Count) == 0:
statusbar["text"] = " 途中経過 : " + str(Loop_Counter) + " 個目のデータ復活を終了"
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : 途中経過 " + str(Loop_Counter) + " 個目のデータ復活処理を終了")
# TGT側のDB処理が完全に終了するまでの保険遅延時間
time.sleep(Wait_Time)
# 処理ログの書き込み
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "TGT側の重複排除処理を開始")
# TGT側の重複レコードを整理する
Duplicate_Removal(db2, cursor2)
# 処理ログの書き込み
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "TGT側の重複排除処理が完了")
# DBを切断
db2.close()
db1.close()
# 最終ステータスを表示
statusbar["text"] = " 処理状況: " + str(Loop_Counter) + " 個のデータ復活を終了。"
# 処理ログの書き込み
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "オリジナル側のデータ復活が完了")
ここで、GUI上の復活ボタンが押された際の処理を書いていますが、今回は稼働条件が厳しかったので「かなり手抜きなロジック」で一気にシンプル処理を行なっています。(その辺は・・・平にご容赦の程。検証のポイントはEqualumを経由してAppendモードで即時同期したターゲットDB上に、Exactly Once & Allでデータが維持されているのか?の確認・・ですので(汗))
#
# メインの処理
#
# 初期値として生成するデータの個数
label1 = tk.Label(root, text = "生成するデータの個数")
label1.place(x = 20, y = 15)
Gen_Count = tk.Text(root, width = 15, height = 1)
Gen_Count.place(x = 200, y = 15)
Gen_Count.insert(tk.END,"10")
#
# 生成過程のコンソール出力
label2 = tk.Label(root, text = "データ生成過程を出力")
label2.place(x = 20, y = 45)
checkbtn = tk.StringVar()
chk = ttk.Checkbutton(root, variable = checkbtn, text = "コンソール出力", onvalue = 1, offvalue = 0)
chk.place(x = 200, y = 45)
checkbtn.set(0)
#
# CDC側のテーブル処理ボタン
Init_CDC_button= tk.Button(root, text = "オリジナル側のテーブルを作成・初期化", command=Make_CDC_Table)
Init_CDC_button.place(x = 20, y = 80)
#
# TGT側のテーブル処理ボタン
Init_TGT_button = tk.Button(root, text = "保全側のテーブルを作成・初期化", command=Make_TGT_Table)
Init_TGT_button.place(x = 20, y = 120)
#
# CDC側への初期データ作成ボタン
Init_Data_button = tk.Button(root, text = "オリジナル側に初期データを作成", command=Init_Data_Insert)
Init_Data_button.place(x = 20, y = 180)
#
# 初期データ作成プログレスバー
label3 = tk.Label(root, text = "処理状況:")
label3.place(x = 20, y = 220)
progressbar1 = ttk.Progressbar(root, orient="horizontal", length=300, mode="determinate", style="Blue.Horizontal.TProgressbar")
progressbar1.pack()
maximum_bar = 20
value_bar = 0
div_bar = 1
progressbar1.configure(maximum=maximum_bar, value=value_bar)
progressbar1.place(x = 90, y = 225)
#
# CDC側への攻撃開始ボタン
Attack_Data_button = tk.Button(root, text = "オリジナル側に改竄攻撃を開始", command=Attack_Data_Update)
Attack_Data_button.place(x = 20, y = 270)
#
# 攻撃データ処理プログレスバー
label4 = tk.Label(root, text = "処理状況:")
label4.place(x = 20, y = 310)
progressbar2 = ttk.Progressbar(root, orient="horizontal", length=300, mode="determinate", style="Red.Horizontal.TProgressbar")
progressbar2.pack()
maximum_bar = 20
value_bar = 0
div_bar = 1
progressbar2.configure(maximum=maximum_bar, value=value_bar)
progressbar2.place(x = 90, y = 315)
#
# 復活のボタン
Revival_Data_button = tk.Button(root, text = "オリジナル側に正規データへの復活を開始", command=Revival_Data_Update)
Revival_Data_button.place(x = 20, y = 360)
#
# 復活処理プログレスバー
label6 = tk.Label(root, text = "処理状況:")
label6.place(x = 20, y = 400)
progressbar3 = ttk.Progressbar(root, orient="horizontal", length=300, mode="determinate", style="Green.Horizontal.TProgressbar")
progressbar3.pack()
maximum_bar = 20
value_bar = 0
div_bar = 1
progressbar3.configure(maximum=maximum_bar, value=value_bar)
progressbar3.place(x = 90, y = 405)
#
# 終了ボタン
exit_button = tk.Button(root, text = "処理を終了", command=Exit_Tool)
exit_button.place(x = 300, y = 450)
#
# ステータスバー設置 <---コードを修正
statusbar = tk.Label(root, text ="作業準備完了!", bd = 1, relief = tk.SUNKEN, anchor = tk.W)
statusbar.pack(side = tk.BOTTOM, fill = tk.X)
#
root.mainloop()
#
# GUIメインループ終了後の処理
print("------------------------------------------------")
print("******************* 処理終了 *******************")
print(datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") + " : " + "全ての処理が終了しました。")
print("------------------------------------------------")
#########################################################################################
ここは、一般的なPythonを用いてGUIアプリを作成する!系の書き方かと思います。
取り急ぎの試運転を・・・・
では、出来上がった検証ツールを動かして、オリジナル側のMySQL上に検証用の基礎データを生成してみます。

上手く生成出来ている様なので、次回は実際に検証ツールを段階的に動かしながら、「不死身のDB」が実際に実現できるのか?を検証してみたいと思います。
さて次回は・・・
今回の検証ツールを使って、実際のデータ状況をDBeaver上で順次確認して行きます。
また、余裕が有れば、今回の可視化検証で使用したツールも紹介させて頂く予定です(長くなる場合は、第3回にて)。
謝辞
本検証は、Equalum社の全面バックアップにより実施しています。この貴重な機会を提供して頂いたEqualum社に対して感謝の意を表すると共に、本内容とEqualum社の公式ホームページで公開されている内容等が異なる場合は、Equalum社の情報が優先する事をご了解ください。
EqualumのExactly Once & All動作検証(2)はこちら
EqualumのExactly Once & All動作検証(3)はこちら
[適材適所・常時全量のデータ処理を時系列透過で実現するコンセプト]
役割分担型データ・システムというアプローチはこちら